TAMO:通过多模态观测数据的工具辅助LLM代理实现细粒度根本原因分析
随着分布式系统的不断发展,微服务和云原生技术已成为现代企业软件开发的核心。尽管这些技术带来了显著的优势,但也增加了系统复杂性和运维挑战。传统的根本原因分析(RCA)难以实现自动化的故障响应,严重依赖人工干预。近年来,大型语言模型(LLMs)在上下文推理和领域知识整合方面取得了突破性进展,为运维中的AI(AIOps)提供了新的解决方案。然而,现有的基于LLM的方法面临三个关键挑战:文本输入限制、动态
王琦,张晓,李明毅,袁媛,肖梦白,庄福振,余东晓
摘要
随着分布式系统的不断发展,微服务和云原生技术已成为现代企业软件开发的核心。尽管这些技术带来了显著的优势,但也增加了系统复杂性和运维挑战。传统的根本原因分析(RCA)难以实现自动化的故障响应,严重依赖人工干预。近年来,大型语言模型(LLMs)在上下文推理和领域知识整合方面取得了突破性进展,为运维中的AI(AIOps)提供了新的解决方案。然而,现有的基于LLM的方法面临三个关键挑战:文本输入限制、动态服务依赖幻觉以及上下文窗口限制。为了解决这些问题,我们提出了一种结合多模态观测数据的工具辅助LLM代理,即TAMO,用于细粒度的根本原因分析。它将多模态观测数据统一为时间对齐的表示形式以提取一致特征,并使用专门的根本原因定位和故障分类工具感知环境上下文。这种方法克服了LLM在处理实时变化的服务依赖关系和原始观测数据方面的局限性,并通过将关键信息结构化为提示符,引导LLM生成与系统上下文一致的修复策略。实验结果表明,TAMO在处理具有异构性和常见故障类型的公共数据集时,在根本原因分析方面表现良好,证明了其有效性。
索引术语-根本原因分析,工具辅助LLM代理,云原生系统,多模态数据,扩散。
I. 引言
近年来,微服务架构和云原生技术已成为现代企业软件开发的基础元素,推动了分布式系统的快速发展。[28],[32],[39]。微服务将传统的单体应用程序分解为独立的分布式服务,而云原生技术则利用容器化和容器编排[21]来增强灵活资源分配、动态扩展和持续交付的能力[30]。在企业
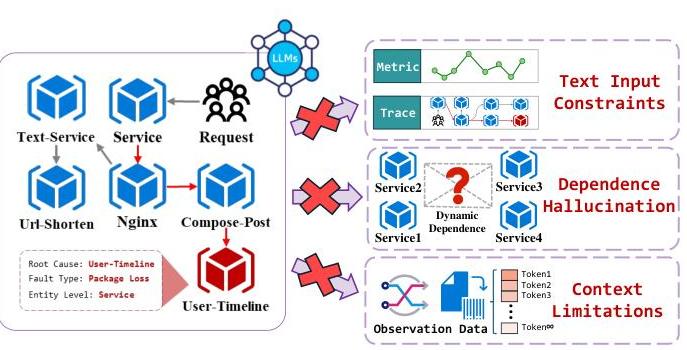
图1. 一个云原生系统中的故障案例,展示了在直接使用LLM进行根本原因分析时面临的三大主要挑战。
生产环境中,微服务系统由众多独立的服务和容器化实体组成[45],这显著增加了系统复杂性。这些系统具有复杂的跨服务依赖关系和通信模式,其中任何组件的故障(例如网络资源损坏)都可能引发级联效应,危及整体系统稳定性,甚至导致重大经济损失[2]。如何在复杂的分布式系统中实现准确的根本原因识别和解决,已成为降低生产风险和最小化损失的关键因素。
根本原因分析旨在快速关联多个相关实体特征,识别根本原因并确定相应的故障类型,提供可行的解决方案,从而实现自动故障响应机制并尽量减少人为干预[42]。如何在分布式环境中进行准确且高效的根本原因分析已成为重要的研究方向。传统RCA方法通常依赖于基于规则的异常检测或统计相关性分析(例如因果图[24])来定位故障。这些方法难以联合分析异构数据模态(例如非结构化日志和结构化指标),往往导致信息碎片化和频繁误检。基于深度学习的RCA方法尝试结合多模态特征融合和依赖敏感的图神经网络(GNNs)[23][44]以实现准确的故障定位。尽管这些方法在特定任务(如复杂系统中的故障定位)中表现出良好的性能,但在实时分析和故障可解释性方面仍面临重大挑战,严重依赖工程师的专业知识来完成根本原因分析和修复过程。最近,大型语言模型在自动化根本原因分析方面展现了革命性的能力,为AIOps开辟了新途径[9],[12]。LLM可以结合系统故障与当前系统上下文生成可行的故障诊断报告,正如RCACopilot[6]等原型所证明的那样。近期的研究如RCAgent[35]和mABC[43]开发了基于LLM的自动化RCA框架,能够实现准确的故障定位并提供合理的修复建议,进一步推动了自动化运维的发展。
然而,尽管现有的基于LLM的方法显著减轻了传统基于DL方法对专业知识的依赖,它们在实际分布式系统环境中仍面临以下三个关键挑战:
- 上下文限制:受限于固定长度的上下文窗口,LLM无法有效实时处理大量上下文监控数据。这种约束通常在分析过程中导致数据截断或压缩,难以利用历史信息检测系统组件中的异常趋势,从而影响根本原因分析的合理性和准确性。因此,如何从复杂的系统上下文中提取有用信息并将其输入到上下文受限的LLM中是一个关键挑战。
-
- 文本输入限制:现有的大型语言模型如ChatGPT[1]、DeepSeek[27]、Qwen[3]等,要么仅支持文本数据作为输入,要么通过将不同模态特征映射到统一的文本语义空间来启用模态输入。然而,由于时间序列和文本之间缺乏明显的相关性,这一转换过程往往会导致关键特征信息的重大损失,严重阻碍LLM的分析和推理能力。因此,如何高效地统一多种观察数据模态以协助LLM提供准确的根本原因分析结果是一个关键挑战。
-
- 动态依赖幻觉:LLM基于静态的预训练知识,这使得它难以建模系统中的服务依赖关系。它只能通过文本提示模拟简单的图结构。正如[34]所述,LLM在复杂图上的推理能力较弱,这限制了其有效捕捉服务依赖关系的能力。此外,系统中服务调用链的动态特性意味着演变的依赖关系可能导致LLM生成与实际依赖关系相矛盾的幻觉,从而导致不准确的根本原因分析。因此,如何协助LLM通过调用链关系建模故障传播路径以实现细粒度的根本原因定位是一个关键挑战。
- 为了解决这些限制,我们提出了一个基于领域特定感知模型的工具辅助LLM代理框架。该框架通过使用专用的观察数据分析工具(T1−T3)\left(\mathcal{T}_{1}-\mathcal{T}_{3}\right)(T1−T3)将LLM与原始观察数据解耦,解决了文本输入和LLM上下文限制的问题。这些专用模型工具用于感知环境上下文,其结果形成结构化的文本输入反馈给RCA专家代理进行进一步分析,生成准确的根本原因分析结果和合理的维护建议。具体来说,为了解决多模态数据对齐问题,我们提出了一种双分支扩散模型作为数据特征观察工具(T1)\left(\mathcal{T}_{1}\right)(T1),它将多模态可观测性数据(日志、跟踪、指标)统一为时间一致的表示形式。为了解决动态依赖问题,根本原因定位工具(T2)\left(\mathcal{T}_{2}\right)(T2)对实体特征和调用拓扑进行联合分析,建模故障传播链,并通过频域注意力驱动的时间因果分析识别根本原因。随后,故障分类工具(T3)\left(\mathcal{T}_{3}\right)(T3)进一步分析故障并将症状映射到预定义的故障类型。主要贡献总结如下:
-
- 我们提出了一种工具辅助LLM代理框架,它将领域特定模型工具与LLM集成用于微服务的根本原因分析。此框架使LLM能够通过调用感知工具实时分析系统状态,将代理与原始观察数据解耦,使其能够生成准确的根本原因分析结果和合理的维护建议。
-
- 我们提出了一种双分支协同扩散工具,它捕获不同模态之间的潜在一致性模式,并通过条件导向的协同重建为下游分析任务提供统一的时间序列表示。
-
- 我们设计了一种基于频域注意力机制的根本原因定位工具,它通过过滤低频噪声识别频域特征中的因果依赖模式,实现精确的根本原因定位。
-
- 实验结果表明,TAMO在两个基准数据集上优于所有比较方法,包括最先进的(SOTA)方法和衍生基线。消融实验和案例研究进一步验证了框架的有效性。
II. 相关工作
在现代云原生系统中,随着微服务架构和动态基础设施的广泛采用,确保高系统可用性和快速故障恢复变得尤为重要,使根本原因分析(RCA)成为运维中的关键部分。因此,已经开发了各种RCA方法以保证系统可靠性,包括传统RCA方法、多模态RCA方法和基于LLM的RCA方法。
传统RCA方法:传统RCA方法主要基于统计相关性分析技术,例如基于预定义规则的异常检测[37]和基于因果发现的根本原因定位策略[7]。虽然这些方法在静态环境中表现良好,但它们难以适应云原生环境中的动态服务依赖关系。
随着深度学习的迅速发展,用于实时系统数据分析的基于神经网络的方法不断涌现。DeepLog[11]通过长短期记忆网络对日志特征进行建模;GDN[10]和GTA[8]使用指标数据构建图神经网络以捕获故障传播路径;Sage[13]利用因果贝叶斯网络和跟踪数据进行根本原因定位。然而,这些方法主要关注单一模态数据,未能充分利用跨模态的互补关系。
多模态RCA方法:基于多模态的方法通过全面考虑来自不同模态的系统观测数据显著降低了漏检率。由于模态之间的差异,提取不同数据之间的相关特征至关重要。PDiagnose[18]将不同模态的数据作为独立实体进行分析,并使用投票机制识别根本原因实体。虽然这种方法成功利用了来自多个模态的数据,但它忽略了来自不同模态的特征之间的一致性关系。Eadro[23]对从不同模态提取的特征进行门控融合,并使用图神经网络在服务级别融合嵌入特征以进行根本原因定位。HolisticRCA[14]相比Eadro,充分考虑了微服务系统的异质性,并使用组装构建块策略标准化不同模态数据的嵌入,结合掩码嵌入进行整体根本原因分析。与直接使用原始数据进行根本原因定位相比,Nezha[40]和DiagFusion[42]将异构多模态数据转换为同质事件表示,通过事件图进行联合分析以实现根本原因定位。CoE[38]进一步支持站点可靠性工程师的操作经验作为事件图的输入,增强了事件的理解和可解释性。虽然这些方法通过多模态融合和综合系统分析显著提高了根本原因定位的准确性,但其根本原因分析过程仍然依赖于工程师的人工干预。
基于LLM的RCA方法:由于大型语言模型具备先进的推理能力和上下文理解能力,基于LLM的RCA方法在自动根本原因分析方面取得了重要进展。目前,基于LLM的RCA方法仍处于早期发展阶段。RCAgent[35]通过工具增强代理框架处理异常,而mABC[43]则使用基于区块链的多代理系统进行根本原因投票和解决方案制定。然而,直接将LLM应用于RCA存在几个关键挑战:LLM的有限上下文窗口限制了大规模观测数据的处理,由于文本输入限制,它们无法有效处理时间序列数据(如指标),导致重要特征信息的丢失。此外,另一个关键问题是如何使用大模型实时捕获和建模云原生系统中的动态依赖关系,而不引入误导或错误结论。这些挑战突显了进一步创新将LLM与多模态和异构数据源集成以实现更准确根本原因分析的必要性。
III. 方法论
为了充分利用云原生系统的多模态可观测性数据并整合先验领域知识,我们提出了TAMO,一种结合多模态观测数据的工具辅助LLM代理,以应对大规模系统运维中的根本原因实体定位和故障分类问题。该工作流程利用由双分支协同扩散模型组成的观测工具,有效提取和整合来自不同实体的多模态数据。此外,任务专用工具明确建模实体间的复杂依赖关系,通过因果图中的特征传播实现准确的根本原因分析。此外,为了充分整合领域知识,我们采用具有运维专长的大型语言模型(LLM)作为专家代理。专家代理A\mathcal{A}A将先前工具T2−T3\mathcal{T}_{2}-\mathcal{T}_{3}T2−T3的输出与系统的上下文知识相结合,为人类工程师提供全面的故障分析和推荐解决方案。如图2所示,所提出的流程包括三个工具和一个代理,T1−T3\mathcal{T}_{1}-\mathcal{T}_{3}T1−T3和A\mathcal{A}A,每个工具负责根本原因分析过程中的特定任务:
- 数据特征观察工具(T1)\left(\mathcal{T}_{1}\right)(T1):该工具采用双分支协同扩散模型来整合多模态特征。它根据条件指导重构和融合文本数据特征(如日志)为时间序列数据;
- 根本原因定位工具(T2)\left(\mathcal{T}_{2}\right)(T2):利用增强的多模态时间序列数据作为输入,该工具通过频域自注意力模块建模实体间的因果关系,实现准确的故障根本原因定位;
- 故障分类工具(T3)\left(\mathcal{T}_{3}\right)(T3):基于实体间的因果关系和调用链结构,该工具对故障类型进行分类;
- RCA专家代理(A)(\mathcal{A})(A):利用大型语言模型(LLM)的专长,该代理综合前序工具的输出与系统环境上下文,为站点可靠性工程师(SREs)提供全面的故障分析和推荐解决方案。
A. 数据特征观察工具(T1)\left(\mathcal{T}_{1}\right)(T1)
扩散模型是一类基于马尔可夫过程的生成模型,已在图像[19]、语音[31]和时间序列[41]等多个领域的数据生成中展现出卓越性能。其核心思想是通过前向去噪(forward diffusion)过程逐步向数据中添加噪声,将原始数据分布转化为近似高斯分布。在反向去噪过程中,模型学习如何逐步去除噪声以生成所需数据。在此工具中,我们使用日志模式和时间特征作为两个扩散分支的控制条件。在去噪过程中,两个分支协作以从受噪声干扰的原始数据中生成具有多模态特征的时间序列数据。具体来说,在前向扩散过程中,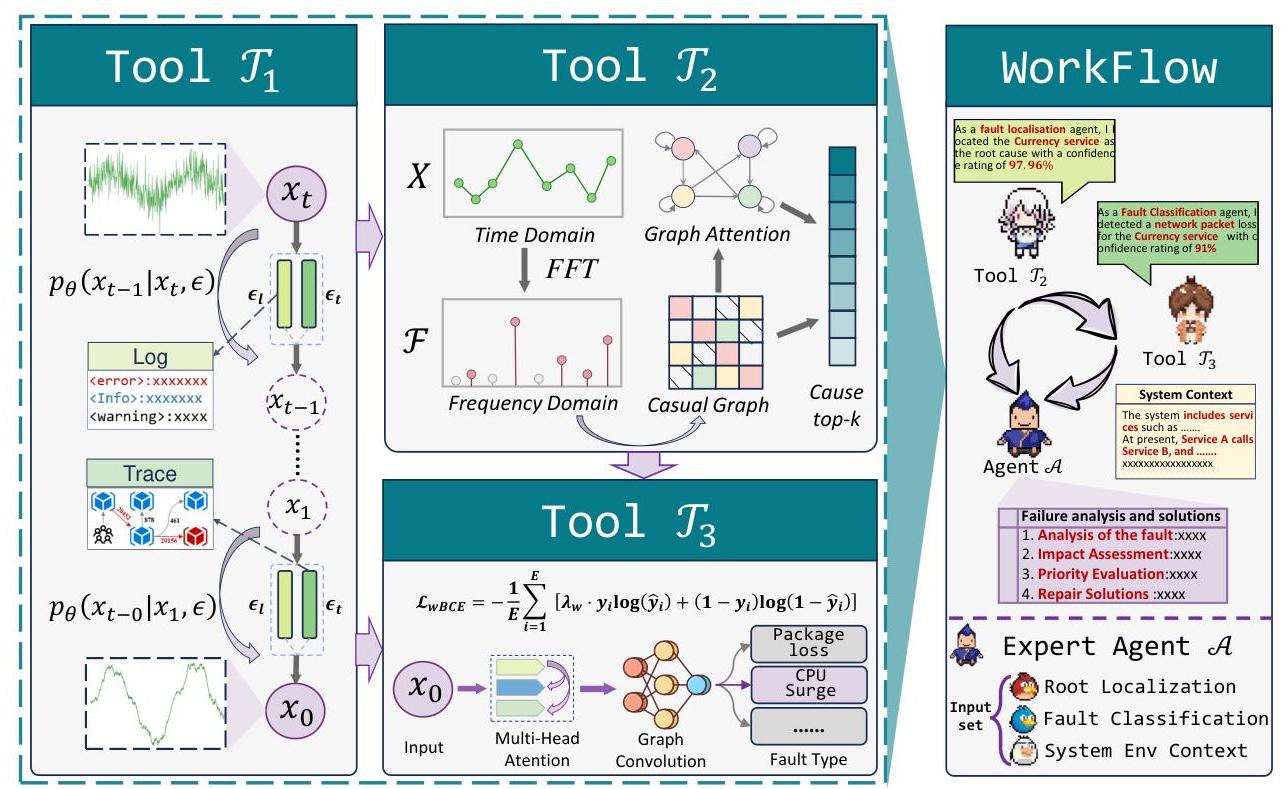
图2. 提出的TAMO框架包括数据特征观察工具(T1)\left(\mathcal{T}_{1}\right)(T1)、根本原因定位工具(T2)\left(\mathcal{T}_{2}\right)(T2)、故障分类工具(T3)\left(\mathcal{T}_{3}\right)(T3)和RCA专家代理(A)(\mathcal{A})(A)。在框架中,代理A\mathcal{A}A调用工具T1−T3\mathcal{T}_{1}-\mathcal{T}_{3}T1−T3作为感知工具以实时分析系统上下文观测数据。这些感知结果被结构化为文本输入反馈到代理中。通过分析感知结果,专家代理将提供相应根本原因分析和修复建议。
原始数据x0∼q(x0)∈RE×m×lx_{0} \sim q\left(x_{0}\right) \in \mathbb{R}^{E \times m \times l}x0∼q(x0)∈RE×m×l由EEE个实体、mmm个通道和长度为lll的时间序列组成。此过程可以表达为:
q(x1,⋯ ,xT∣x0):=∏t=1Tq(xt∣xt−1) q\left(x_{1}, \cdots, x_{T} \mid x_{0}\right):=\prod_{t=1}^{T} q\left(x_{t} \mid x_{t-1}\right) q(x1,⋯,xT∣x0):=t=1∏Tq(xt∣xt−1)
如果αt∈(0,1)\alpha_{t} \in(0,1)αt∈(0,1)是预先定义的噪声缩放因子,决定保留多少来自前一步的信息,则公式1的每一步为:
q(xt∣xt−1)=N(xt;αtxt−1,(1−αt)I) q\left(\mathbf{x}_{t} \mid \mathbf{x}_{t-1}\right)=\mathcal{N}\left(\mathbf{x}_{t} ; \sqrt{\alpha_{t}} \mathbf{x}_{t-1},\left(1-\alpha_{t}\right) \mathbf{I}\right) q(xt∣xt−1)=N(xt;αtxt−1,(1−αt)I)
经过TTT步噪声添加后,xTx_{T}xT收敛到随机噪声xT∼N(0,I)x_{T} \sim \mathcal{N}(0, I)xT∼N(0,I),接近高斯分布。
随后,我们使用双分支条件机制对噪声数据进行逐步去噪。参数化的条件转移分布可以表达为:
pθ(xt−1∣xt,C)=N(xt−1;μθ(xt,t,C),Σθ(xt,t,C))pθ(x0:T,C)=p(xT)∏t=1Tpθ(xt−1∣xt,C) \begin{aligned} p_{\theta}\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}, \mathcal{C}\right) & =\mathcal{N}\left(\mathbf{x}_{t-1} ; \boldsymbol{\mu}_{\theta}\left(\mathbf{x}_{t}, t, \mathcal{C}\right), \boldsymbol{\Sigma}_{\theta}\left(\mathbf{x}_{t}, t, \mathcal{C}\right)\right) \\ p_{\theta}\left(\mathbf{x}_{0: T}, \mathcal{C}\right) & =p\left(\mathbf{x}_{T}\right) \prod_{t=1}^{T} p_{\theta}\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}, \mathcal{C}\right) \end{aligned} pθ(xt−1∣xt,C)pθ(x0:T,C)=N(xt−1;μθ(xt,t,C),Σθ(xt,t,C))=p(xT)t=1∏Tpθ(xt−1∣xt,C)
其中C={clog ,ctime }\mathcal{C}=\left\{c_{\text {log }}, c_{\text {time }}\right\}C={clog ,ctime }代表控制条件集合,clog c_{\text {log }}clog 和ctime c_{\text {time }}ctime 分别对应日志分支和时间序列分支。这些条件引导去噪过程,确保生成的数据具有多模态特征,通过利用基于日志的模式和时间特征。
对于生成的日志条件变量clog c_{\text {log }}clog ,由于非结构化日志表示难以提取高质量特征,受之前工作的启发[14] [23],我们使用Drain[16]从原始日志中提取事件模式E\mathcal{E}E和关键词W\mathcal{W}W,并通过计算TF-IDF得分选择最高得分的模式-关键词对作为条件变量clog c_{\text {log }}clog 。
clog={argmaxe∈ETF−IDF(e)}∪{argmaxw∈WTF−IDF(w)} c_{l o g}=\left\{\arg \max _{e \in \mathcal{E}} \operatorname{TF}-\operatorname{IDF}(e)\right\} \cup\left\{\arg \max _{w \in \mathcal{W}} \operatorname{TF}-\operatorname{IDF}(w)\right\} clog={arge∈EmaxTF−IDF(e)}∪{argw∈WmaxTF−IDF(w)}
对于生成的时间条件变量ctime c_{\text {time }}ctime ,我们从跟踪文件中提取关键性能指标(KPIs),如延迟和持续时间。这些KPIs xkpix_{k p i}xkpi然后通过多层感知机(MLP)网络嵌入到潜在空间中,使模型能够有效地将时间特征纳入去噪过程。
ctime =Embedding(xkpi)∈Rhtime \mathbf{c}_{\text {time }}=\operatorname{Embedding}\left(x_{k p i}\right) \in \mathbb{R}^{h_{\text {time }}} ctime =Embedding(xkpi)∈Rhtime
在训练过程中,我们使用双分支网络学习反向扩散过程,逐步对噪声数据进行去噪。在此过程中,每一步估计的噪声项由两个分支协同生成。
Xt−1=1αt(Xt−1−αt1−αˉtϵθ(Xt,t,C))+σtzz∼N(0,I) \begin{gathered} \mathbf{X}_{t-1}=\frac{1}{\sqrt{\alpha_{t}}}\left(\mathbf{X}_{t}-\frac{1-\alpha_{t}}{\sqrt{1-\bar{\alpha}_{t}}} \epsilon_{\theta}\left(\mathbf{X}_{t}, t, \mathcal{C}\right)\right)+\sigma_{t} \mathbf{z} \\ \mathbf{z} \sim \mathcal{N}(0, \mathbf{I}) \end{gathered} Xt−1=αt1(Xt−1−αˉt1−αtϵθ(Xt,t,C))+σtzz∼N(0,I)
其中,αˉt=∏s=1tαs\bar{\alpha}_{t}=\prod_{s=1}^{t} \alpha_{s}αˉt=∏s=1tαs表示噪声缩放因子αs\alpha_{s}αs的累积乘积,ϵθ\epsilon_{\theta}ϵθ表示模型预测的噪声项,基于日志分支ϵlog \epsilon_{\text {log }}ϵlog 和时间序列分支ϵtime \epsilon_{\text {time }}ϵtime 的计算联合生成。超参数μ\muμ用作混合系数以平衡两个分支的贡献。
ϵθ(xt,t,C)=μϵlog(xt,t,clog)+(1−μ)ϵtime (xt,t,ctime )\epsilon_{\theta}\left(\mathbf{x}_{t}, t, \mathcal{C}\right)=\mu \epsilon_{\log }\left(\mathbf{x}_{t}, t, \mathbf{c}_{\log }\right)+(1-\mu) \epsilon_{\text {time }}\left(\mathbf{x}_{t}, t, \mathbf{c}_{\text {time }}\right)ϵθ(xt,t,C)=μϵlog(xt,t,clog)+(1−μ)ϵtime (xt,t,ctime ),
原始去噪扩散模型采用U-Net作为去噪骨干[17]。然而,考虑到时间序列数据的特性,我们采用基于补丁的Transformer网络[29]作为每个分支的骨干,以便更好地捕获时间序列子序列的表示。该模型的训练目标是最小化分布ppp和qqq之间的KL散度。根据[17],目标推导如下:
Ldiff =Ex0,ϵ[∥ϵ−ϵθ(xt,t,C)∥22] \mathcal{L}_{\text {diff }}=\mathbb{E}_{\mathbf{x}_{0}, \boldsymbol{\epsilon}}\left[\left\|\boldsymbol{\epsilon}-\boldsymbol{\epsilon}_{\theta}\left(x_{t}, t, \mathcal{C}\right)\right\|_{2}^{2}\right] Ldiff =Ex0,ϵ[∥ϵ−ϵθ(xt,t,C)∥22]
B. 根本原因定位工具(T2)\left(\mathcal{T}_{2}\right)(T2)
通过工具T1\mathcal{T}_{1}T1的双分支扩散模型,我们获得了整合多模态特征的时间序列数据。然而,由于此过程在系统资源实体层面操作,生成的时间序列xent ′∈RL×dent x_{\text {ent }}^{\prime} \in \mathbb{R}^{L \times d_{\text {ent }}}xent ′∈RL×dent 保持与原始资源实体相同的维度,其中ent表示对应的资源实体,LLL表示时间窗口长度,dent d_{\text {ent }}dent 表示与每个实体相关的特征维度。由于云原生系统中不同资源实体的可观测性数据具有异质性,它们之间存在不一致性,这阻碍了模型中的统一学习。为了解决这个问题,我们首先对不同实体的特征进行数据嵌入,将它们映射到统一的维度空间以实现一致性:
Hent = DataEmbedding (xent ′)∈RL×dmodel H^{\text {ent }}=\text { DataEmbedding }\left(x_{\text {ent }}^{\prime}\right) \in \mathbb{R}^{L \times d_{\text {model }}} Hent = DataEmbedding (xent ′)∈RL×dmodel
其中dmodel d_{\text {model }}dmodel 表示统一的嵌入维度。在将所有实体特征映射到潜在空间后,我们将输出结果连接起来以获得嵌入向量Hemb∈RE×L×dmodet H^{e m b} \in \mathbb{R}^{E \times L \times d_{\text {modet }}}Hemb∈RE×L×dmodet 。
在获得统一的嵌入向量HembH^{e m b}Hemb之后,我们考虑到根本原因定位任务通常需要检测和识别系统实体中的短期异常或扰动信号。这些瞬态特征可能会被时间域中的平滑趋势掩盖。为了解决这个问题,我们应用快速傅里叶变换(FFT)将数据从时间域转换到频率域。正式地,转换可以表达为:
F(Hemb)=FFT(Hemb)=∑i=0L−1Hiembe−j2πki/K \mathcal{F}\left(H^{e m b}\right)=\operatorname{FFT}\left(H^{e m b}\right)=\sum_{i=0}^{L-1} H_{i}^{e m b} e^{-j 2 \pi k i / K} F(Hemb)=FFT(Hemb)=i=0∑L−1Hiembe−j2πki/K
其中e−j2πki/Ne^{-j 2 \pi k i / N}e−j2πki/N是复指数傅里叶基函数,HiembH_{i}^{e m b}Hiemb表示对应时间步iii的时间序列值,k=0,1,…,N−1k=0,1, \ldots, N-1k=0,1,…,N−1。
考虑到根本原因定位的实时需求,模型需要关注观察数据中的短期波动。为此,我们在频率域数据上应用高通滤波器,保留前kkk个高频分量,有助于放大数据中的异常信号。正式地,这可以表达为:
KaTeX parse error: Expected 'EOF', got '_' at position 128: … k=\text { freq_̲topk }\right) \…
由于云原生系统中微服务之间的交互可以用依赖图描述,为了充分考虑系统中实体之间的关系并捕捉潜在的故障传播路径,我们使用自注意力机制在频率域构造因果依赖图。此过程可以定义为:
A=Softmax(Attention(Ffiltered WQ,Ffiltered WK)) A=\operatorname{Softmax}\left(\operatorname{Attention}\left(\mathcal{F}_{\text {filtered }} W^{Q}, \mathcal{F}_{\text {filtered }} W^{K}\right)\right) A=Softmax(Attention(Ffiltered WQ,Ffiltered WK))
其中WQ,WKW^{Q}, W^{K}WQ,WK分别是查询和键矩阵。随后,为了减少无关实体的影响并去除冗余关系,我们在图生成过程中引入拓扑约束。这些约束可以定义为:
Amuske =A⊙(I−IE)⊙TopkMask(⋅,k= topk ) \mathbf{A}_{\text {muske }}=\mathbf{A} \odot\left(\mathbf{I}-\mathbf{I}_{E}\right) \odot \operatorname{TopkMask}(\cdot, k=\text { topk }) Amuske =A⊙(I−IE)⊙TopkMask(⋅,k= topk )
其中IE\mathbf{I}_{E}IE是避免自环的实体对角矩阵,TopkMask保留每个实体的前kkk个最重要的依赖关系。然后,我们应用图神经网络进行根本原因推理和定位。具体来说,我们选择图注意力网络(GAT)[4]作为聚合系统实体间邻域特征信息的骨干,以模拟故障传播过程如下:
His+1=Relu(αiiWHjs+∑j∈N(i)αijWHjs) \mathcal{H}_{i}^{s+1}=\operatorname{Relu}\left(\alpha_{i i} W \mathcal{H}_{j}^{s}+\sum_{j \in N(i)} \alpha_{i j} W \mathcal{H}_{j}^{s}\right) His+1=Relu αiiWHjs+j∈N(i)∑αijWHjs
其中N(i)={j∣Amask [i,j]=1},HisN(i)=\left\{j \mid A_{\text {mask }}[i, j]=1\right\}, \mathcal{H}_{i}^{s}N(i)={j∣Amask [i,j]=1},His是在第sss层中实体iii的表示,Hi0=Ffiltered ,αi,j\mathcal{H}_{i}^{0}=\mathcal{F}_{\text {filtered }}, \alpha_{i, j}Hi0=Ffiltered ,αi,j是系统实体iii与其相关实体jjj之间的注意力系数,可以通过以下公式计算:
ξ(i,j)=LeakyRelu(aT(Ws⋅his⊕Ws⋅hjs))αij=exp(ξ(i,j))∑p∈Ni∪{i}exp(ξ(i,p)) \begin{gathered} \xi(i, j)=\operatorname{LeakyRelu}\left(a^{T}\left(W^{s} \cdot h_{i}^{s} \oplus W^{s} \cdot h_{j}^{s}\right)\right) \\ \alpha_{i j}=\frac{\exp (\xi(i, j))}{\sum_{p \in N_{i} \cup\{i\}} \exp (\xi(i, p))} \end{gathered} ξ(i,j)=LeakyRelu(aT(Ws⋅his⊕Ws⋅hjs))αij=∑p∈Ni∪{i}exp(ξ(i,p))exp(ξ(i,j))
其中⊕\oplus⊕表示连接操作,aTa^{T}aT表示注意力参数向量,WsW^{s}Ws是第sss层的权重矩阵。最后,我们使用最大池化层聚合实例的重要性,从而获得系统实体的根本原因概率:
y^=MaxPool(HS)∈RE×1 \hat{y}=\operatorname{MaxPool}\left(\mathbf{H}^{S}\right) \in \mathbb{R}^{E \times 1} y^=MaxPool(HS)∈RE×1
考虑到在同一时间段内可能存在多个类型的实体同时发生故障,这意味着
根本原因实体可能不是唯一的,我们使用二元交叉熵(BCE)作为损失函数来优化模型。具体来说,对于每个标签yiy_{i}yi和模型预测值y^i\hat{y}_{i}y^i(其中i∈{0,1,…,E−1}i \in\{0,1, \ldots, E-1\}i∈{0,1,…,E−1},EEE表示系统实体的总数),损失函数定义为:
LBCE=−1E∑i=1E[yilog(y^i)+(1−yi)log(1−y^i)] \mathcal{L}_{B C E}=-\frac{1}{E} \sum_{i=1}^{E}\left[y_{i} \log \left(\hat{y}_{i}\right)+\left(1-y_{i}\right) \log \left(1-\hat{y}_{i}\right)\right] LBCE=−E1i=1∑E[yilog(y^i)+(1−yi)log(1−y^i)]
C. 故障分类工具(T3)\left(\mathcal{T}_{3}\right)(T3)
在工具T2\mathcal{T}_{2}T2完成根本原因实体定位后,故障诊断过程通常需要进一步识别根本原因实体的具体故障类型(例如硬件过载、资源泄漏或配置错误),以指导精确的修复策略。虽然根本原因定位缩小了故障分析的范围(即确定“哪里”发生异常),但在实际操作场景中,不同的故障类型往往对应不同的处理策略(例如内存泄漏需要重启服务,而CPU竞争需要资源扩展)。因此,此工具使用工具T1\mathcal{T}_{1}T1生成的时间序列数据xent ′x_{\text {ent }}^{\prime}xent ′(为简单起见,记为zzz)来训练故障分类模型。
为了建模输入时间序列数据zzz中的潜在时间依赖性,我们使用Transformer模型[33]作为编码网络。其单头自注意力机制的输出由以下公式给出:
Attention = softmax (zWQ⋅zWKTdk)zWV \text { Attention }=\text { softmax }\left(\frac{z W^{Q} \cdot z W^{K^{T}}}{\sqrt{d_{k}}}\right) z W^{V} Attention = softmax (dkzWQ⋅zWKT)zWV
其中WQ,WK,WVW^{Q}, W^{K}, W^{V}WQ,WK,WV是线性投影矩阵。随后,我们将多头注意力的结果连接起来以获得潜在向量表示:
V=MultiHead(zWQ,zWK,zWV) V=\operatorname{MultiHead}\left(z W^{Q}, z W^{K}, z W^{V}\right) V=MultiHead(zWQ,zWK,zWV)
在捕捉时间序列数据的内部时间依赖性之后,我们使用GAT模型捕捉时间步之间的空间依赖性。根据公式Eq.16-Eq.18,我们在潜在向量表示上执行特征传播。通过聚合相邻实体的加权特征获得每个实体的表示:
Z′=ELU(GATConv(X,A)) Z^{\prime}=\operatorname{ELU}(\operatorname{GATConv}(X, A)) Z′=ELU(GATConv(X,A))
其中ELU是激活函数,A∈RE×EA \in \mathbb{R}^{E \times E}A∈RE×E是实体之间的依赖关系。随后,我们使用MLP网络输出对应实体的故障类型。考虑到故障分类任务中多类重叠和类别不平衡的问题,我们采用带类别权重系数λ\lambdaλ的加权二元交叉熵(wBCE)损失函数作为模型的训练目标:
LwBCE=−1E∑i=1E[λw⋅yilog(y^i)+(1−yi)log(1−y^i)] \mathcal{L}_{w B C E}=-\frac{1}{E} \sum_{i=1}^{E}\left[\lambda_{w} \cdot y_{i} \log \left(\hat{y}_{i}\right)+\left(1-y_{i}\right) \log \left(1-\hat{y}_{i}\right)\right] LwBCE=−E1i=1∑E[λw⋅yilog(y^i)+(1−yi)log(1−y^i)]
其中λw\lambda_{w}λw表示每种类别故障样本中正负样本的比例,用于增强样本的损失贡献。此外,为了防止过拟合,我们在损失函数中包含了一个L2权重衰减项。最终的损失函数可以表示为:
L=LwBCE+β∥W∥22 \mathcal{L}=\mathcal{L}_{w B C E}+\beta\|\mathbf{W}\|_{2}^{2} L=LwBCE+β∥W∥22
其中β\betaβ是一个预定义的超参数,W\mathbf{W}W是模型权重。
D. RCA专家代理(A\mathcal{A}A)
在三个工具T1−T3\mathcal{T}_{1}-\mathcal{T}_{3}T1−T3完成数据特征对齐、根本原因定位和故障分类等任务后,工作流已对故障有了相对深入的理解。然而,仅仅依赖这些输出很难提供全面和准确的故障分析和修复计划。因此,为进一步提高故障响应和系统恢复效率,我们引入了RCA专家代理A\mathcal{A}A。使用大型语言模型(LLM),此代理综合了前序工具的预测结果,并结合云原生微服务架构的当前上下文,为站点可靠性工程师提供更全面和准确的故障诊断和解决方案。
具体来说,我们使用GPT-4[1]作为专家模型,该模型收集前序工具的输出作为背景知识,包括:
- 根本原因定位结果(来自T2\mathcal{T}_{2}T2):识别故障的根本原因位置及其相关系统组件。
-
- 故障分类结果(来自T3\mathcal{T}_{3}T3):提供具体的故障类型,例如网络故障、硬件故障、配置错误等。
-
- 系统上下文信息:包括系统微服务架构、服务之间的依赖关系、调用链、资源使用及其他相关细节,这些为故障诊断提供了必要的上下文。
- 在实践中,我们按照图3所示格式准备提示符作为模型输入,预期输出是一个详细的故障分析报告及相应的解决方案建议。此类输出帮助SRE团队快速理解根本原因、影响范围,并采取针对性的修复行动,从而提高系统可靠性和响应效率。
IV. 评估
A. 研究问题
本节回答以下研究问题:
- RQ1: TAMO在根本原因定位方面的有效性如何?
-
- RQ2: TAMO在故障分类方面的有效性如何?
-
- RQ3: 在对TAMO的各种组件进行消融研究时,TAMO的表现如何?
-
- RQ4: TAMO在真实世界案例研究和故障场景中的表现如何?
- 表一
- 不同方法在根本原因定位和故障分类任务上的实验结果。
| 数据 | 方法 | RE 定位 | | | 故障类型分类 | | | | | |
| :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: |
| | | AC@1 | AC@3 | AC@5 | MiPr | MaPr | MiRe | MaRe | MiF1 | MaF1 |
| | HolisticRCA | 65.62%‾\underline{65.62 \%}65.62% | 76.33%‾\underline{76.33 \%}76.33% | 81.69%‾\underline{81.69 \%}81.69% | 0.6355‾\underline{0.6355}0.6355 | 0.7130 | 0.7728 | 0.8037 | 0.6974 | 0.7507 |
| | TimesNet | 14.81%14.81 \%14.81% | 32.10%32.10 \%32.10% | 61.72%61.72 \%61.72% | | - | - | - | - | |
| | Eadro | 13.58%13.58 \%13.58% | 37.03%37.03 \%37.03% | 45.68%45.68 \%45.68% | 0.1887 | 0.0770 | 0.1235 | 0.1046 | 0.1493 | 0.0758 |
| | SegRNN | 14.81%14.81 \%14.81% | 40.75%40.75 \%40.75% | 60.49%60.49 \%60.49% | | - | - | - | - | - |
| AsA_{s}As | DejaVu | 62.50%62.50 \%62.50% | 65.62%65.62 \%65.62% | 78.13%78.13 \%78.13% | - | - | - | - | - | - |
| | LightGBM | - | - | - | 0.1967 | 0.1536 | 0.2000 | 0.2282 | 0.1983 | 0.1707 |
| | Transformer | 16.22%16.22 \%16.22% | 37.84%37.84 \%37.84% | 56.76%56.76 \%56.76% | 0.0114 | 0.0123 | 0.1892 | 0.1932 | 0.0214 | 0.0230 |
| | TAMO | 71.87%71.87 \%71.87% | 82.14%82.14 \%82.14% | 88.83%88.83 \%88.83% | 0.7164 | 0.6671‾\underline{0.6671}0.6671 | 0.6486‾\underline{0.6486}0.6486 | 0.6149‾\underline{0.6149}0.6149 | 0.6809‾\underline{0.6809}0.6809 | 0.6299‾\underline{0.6299}0.6299 |
| | HolisticRCA | 65.62%65.62 \%65.62% | 80.80%80.80 \%80.80% | 86.60%‾\underline{86.60 \%}86.60% | 0.5913 | 0.6682 | 0.7534 | 0.7598 | 0.6626 | 0.7008 |
| | TimesNet | 10.71%10.71 \%10.71% | 22.14%22.14 \%22.14% | 32.14%32.14 \%32.14% | 13.13%13.13 \%13.13% | 15.63%15.63 \%15.63% | 0.3901 | 0.3344 | 0.4665 | 0.4792 | 0.4249 | 0.3761 |
| | Eadro | 9.38%9.38 \%9.38% | SegRNN | 18.75%18.75 \%18.75% | 56.25%56.25 \%56.25% | 84.38%84.38 \%84.38% | - | - | - | - | - | - |
| | DejaVu | 18.75%18.75 \%18.75% | 21.88%21.88 \%21.88% | 28.13%28.13 \%28.13% | - | - | - | - | - | - |
| ApA_{p}Ap | LightGBM | - | - | - | 0.6849‾\underline{0.6849}0.6849 | 0.6450 | 0.6792 | 0.6808 | 0.6820‾\underline{0.6820}0.6820 | 0.6583‾\underline{0.6583}0.6583 |
| | Transformer | 10.71%10.71 \%10.71% | 19.29%19.29 \%19.29% | 24.29%24.29 \%24.29% | 0.0106 | 0.0106 | 0.4254 | 0.4439 | 0.0207 | 0.0208 |
| | TAMO | 64.28%‾\underline{64.28 \%}64.28% | 80.36%‾\underline{80.36 \%}80.36% | 87.50%87.50 \%87.50% | 0.7182 | 0.6597‾\underline{0.6597}0.6597 | 0.6840‾\underline{0.6840}0.6840 | 0.6642‾\underline{0.6642}0.6642 | 0.7007 | 0.6445 |
| | HolisticRCA | 73.66%73.66 \%73.66% | 75.89%75.89 \%75.89% | 79.01%79.01 \%79.01% | 0.6219‾\underline{0.6219}0.6219 | 0.6437‾\underline{0.6437}0.6437 | 0.7612 | 0.7322 | 0.6846‾\underline{0.6846}0.6846 | 0.6717‾\underline{0.6717}0.6717 |
| | TimesNet | 21.15%21.15 \%21.15% | 48.07%48.07 \%48.07% | 78.85%78.85 \%78.85% | | - | - | - | - | - |
| | Eadro | 17.18%17.18 \%17.18% | 28.13%28.13 \%28.13% | 42.19%42.19 \%42.19% | 0.5426 | 0.6003 | 0.7969 | 0.8145 | 0.6456 | 0.6575 |
| | SegRNN | 7.50%7.50 \%7.50% | 20.63%20.63 \%20.63% | 23.75%23.75 \%23.75% | - | - | - | - | - | - |
| | DejaVu | 81.25%‾\underline{81.25 \%}81.25% | 90.63%‾\underline{90.63 \%}90.63% | 100.00% | | - | - | - | - | - |
| AnA_{n}An | LightGBM | - | - | - | 0.5208 | 0.5491 | 0.8333‾\underline{0.8333}0.8333 | 0.8178‾\underline{0.8178}0.8178 | 0.6410 | 0.6406 |
| | Transformer | 13.46%13.46 \%13.46% | 48.08%48.08 \%48.08% | 78.85%78.85 \%78.85% | 0.1415 | 0.1423 | 0.5577 | 0.5207 | 0.2257 | 0.2212 |
| | TAMO | 84.37%84.37 \%84.37% | 91.96%91.96 \%91.96% | 97.77%‾\underline{97.77 \%}97.77% | 0.8718 | 0.8869 | 0.8947 | 0.8681 | 0.8831 | 0.8706 |
| | HolisticRCA | 61.11%‾\underline{61.11 \%}61.11% | 75.00%‾\underline{75.00 \%}75.00% | 77.78%‾\underline{77.78 \%}77.78% | 0.5000 | 0.5936 | 0.8056 | 0.8056 | 0.6170‾\underline{0.6170}0.6170 | 0.6636 |
| | Timesnet | 15.62%15.62 \%15.62% | 25.00%25.00 \%25.00% | 40.63%40.63 \%40.63% | 0.4893 | 0.5789 | 0.7187 | 0.7398 | 0.5823 | 0.6394 |
| | Eadro | 40.62%40.62 \%40.62% | 56.25%56.25 \%56.25% | 71.87%71.87 \%71.87% | 0.4167 | 0.5211 | 0.6250 | 0.6516 | 0.5000 | 0.5694 |
| | SegRNN | 18.75%18.75 \%18.75% | 43.75%43.75 \%43.75% | 62.50%62.50 \%62.50% | 0.1496 | 0.2359 | 0.5937 | 0.6287 | 0.2389 | 0.3296 |
| | DejaVu | 15.62%15.62 \%15.62% | 34.38%34.38 \%34.38% | 50.00%50.00 \%50.00% | - | - | - | - | - | - |
| BBB | LightGBM | - | - | - | 0.7832‾\underline{0.7832}0.7832 | 0.6434‾\underline{0.6434}0.6434 | 0.4186 | 0.3860 | 0.4687 | 0.4122 |
| | Transformer | 46.88%46.88 \%46.88% | 68.75%68.75 \%68.75% | 84.38%84.38 \%84.38% | 0.4464 | 0.5664 | 0.7813‾\underline{0.7813}0.7813 | 0.7955‾\underline{0.7955}0.7955 | 0.5682 | 0.6406 |
| | TAMO | 72.22%72.22 \%72.22% | 80.55%80.55 \%80.55% | 86.11%86.11 \%86.11% | 0.8500 | 0.8750 | 0.5313 | 0.5682 | 0.6538 | 0.6421‾\underline{0.6421}0.6421 |
B. 实验设置
- 数据集:我们在两个公共数据集上进行了广泛的实验:
- 数据集 AAA. AAA 是来自AIOps Challenge 1{ }^{1}1的大规模公共数据集,通过在实际部署的微服务系统HipsterShop 2{ }^{2}2中注入故障收集而成。该数据集主要包含三种类型的数据:指标、日志和跟踪。系统使用动态部署架构,由10个服务组成,每个服务有4个Pod,总共40个Pod动态部署在6个节点上。数据集包含15种故障类型。其中,9种故障类型与Kubernetes (K8s)容器中的服务和Pod相关,而节点故障包括6种类型:突然的内存压力、磁盘空间耗尽、磁盘读写问题、CPU压力和缓慢的CPU增长。
-
- 数据集 B.BB . BB.B 是从[23]中的广播式SocialNetwork系统收集的公共数据集3{ }^{3}3,仅包含服务级别的实体。它包括21个微服务,并且也由三种类型的数据组成:指标、
- 日志和跟踪。该数据集是通过使用Chaosblade向系统注入故障生成的,产生的数据包括三种类型的故障:CPU资源耗尽、网络延迟和丢包。
- 基线方法:我们将TAMO与最受欢迎的集成多模态方法及其衍生方法(来自时间序列领域)进行了比较。具体来说,我们选择了两种最先进的集成多模态根本原因分析方法,Eadro [23] 和 HolisticRCA [14],以及四种单模态时间序列分析方法(即TimesNet [36]、SegRNN [26]、DejaVu [25]、Transformer [33])。这些方法使用其公开可用且可重现的开源代码实现,并调整了数据格式以匹配所需的输入。此外,由于我们的研究任务相对较新,包括故障定位和分类,我们将TAMO中使用的相同故障分类器引入到不原生实现故障分类的方法中(如方法[36]、[23]、[33]等)进行比较。此外,我们引入了LightGBM [20],一种专为故障分类任务设计的方法,作为基准来评估TAMO的性能。
- 评估指标:TAMO专注于定位根本原因实例并识别故障类型。基于之前的研究工作[14]、[23]、[42]、[15],我们选择了不同的评估指标来评估模型对
1{ }^{1}1 https://competition.AIOps-challenge.com/home/competition/ 1496398526429724760
2{ }^{2}2 https://github.com/GoogleCloudPlatform/microservices-demo
3{ }^{3}3 https://doi.org/10.5281/zenodo. 7615393
表二
在我们提出的TAMO框架上进行消融研究的实验结果。
| 模型 | RE 定位 | 故障类型分类 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| AC@1 | AC@3 | AC@5 | MiPr | MaPr | MiRe | MaRe | MiF1 | MaF1 | |
| TAMO w/o _{\text {w/o }}w/o | 43.75% | 56.25% | 68.75% | 0.5909 | 0.5556 | 0.4063 | 0.4453 | 0.4815 | 0.4911 |
| TAMO w/o branch _{\text {w/o branch }}w/o branch | 59.38% | 68.75% | 71.87% | 0.7200 | 0.7350 | 0.5625 | 0.6010 | 0.6316 | 0.6167 |
| TAMO w/o_{w / o}w/o FFT | 53.13% | 68.75% | 78.13% | 0.8000 | 0.7639 | 0.5000 | 0.5404 | 0.6154 | 0.5977 |
| TAMO | 72.22% | 80.55% | 86.11% | 0.8500 | 0.8750 | 0.5313 | 0.5682 | 0.6538 | 0.6421 |
RCA专家提示
您是一位负责基于云原生、微服务架构复杂系统故障分析和诊断的RCA专家。您可以访问详细的故障报告、系统性能数据和历史故障模式。您根据以下结构化输入提供详细分析,其中包括根本原因信息、故障分类、系统架构上下文、历史故障数据及其他系统状态细节。您需要应用高级推理方法,结合系统架构知识、历史故障模式和行业最佳实践,提供全面、实用的解决方案,以提高系统可靠性和最小化停机时间。
[故障根本原因定位]
- 根本实体:<从T2>\mathcal{T}_{2}>T2>得出的定位结果>
-
- 相关实体:<相关的调用实体>
- [故障分类]
-
- 故障类型:<从T3>\mathcal{T}_{3}>T3>得出的分类结果>
-
- 症状:<详细症状描述>
- [系统架构背景]
-
- 架构:<微服务功能>
-
- 上下文:<相关日志和跟踪信息>
- [任务目标]
- 根据上述信息,请分析故障的根本原因、影响范围及建议解决方案,并提供以下内容:
- 故障根本原因分析。
- 故障类型和级别分析。
- 修复方案和预防措施。
图3. 此RCA专家代理的提示模板。
这两个任务。具体来说,对于根本原因定位任务,我们使用前k准确率(AC@K)作为评估指标,表示真实根本原因实体出现在方法生成的前k结果中的概率。这里,我们设置k={1,3,5}k=\{1,3,5\}k={1,3,5}。给定故障集合SSS,真实根本原因是RCRCRC,模型生成的前k根本原因是rc[k]rc[k]rc[k]。因此,AC@K可以定义如下:
AC@k=1∣S∣∑i∈SS∫{1, if RCi∈rci[k]0, otherwise A C @ k=\frac{1}{|S|} \sum_{i \in S}^{S} \int \begin{cases}1, & \text { if } R C_{i} \in r c_{i}[k] \\ 0, & \text { otherwise }\end{cases} AC@k=∣S∣1i∈S∑S∫{1,0, if RCi∈rci[k] otherwise
对于故障分类任务,我们使用精度(Pre)、召回率(Rec)和F1得分(F1)来评估性能。给定真正例(TP)、假正例(FP)和假反例(FN),这些指标的公式如下:Pre=TPTP+FP,Rec=TPTP+FN,F1=3⋅Prc⋅RecPr+Rec\operatorname{Pre}=\frac{T P}{T P+F P}, \operatorname{Rec}=\frac{T P}{T P+F N}, F 1=\frac{3 \cdot \operatorname{Pr} c \cdot \operatorname{Rec}}{\operatorname{Pr}+R e c}Pre=TP+FPTP,Rec=TP+FNTP,F1=Pr+Rec3⋅Prc⋅Rec。考虑到这是一个多标签分类问题,我们采用微观和宏观指标进行全面评估。微观指标汇总所有标签的性能,将所有实例平等对待,这在类别分布不平衡时很有用。相比之下,宏观指标独立计算每个标签的指标然后平均结果,无论频率如何给予每个标签相同的权重。因此,最终性能使用微观精度(MiPr)、宏观精度(MaPr)、微观召回率(MiRe)、宏观召回率(MaRe)、微观F1得分(MiF1)和宏观F1得分(MaF1)来衡量。
4) 实现:我们使用Python torch 2.4.0和CUDA 12.1实现了TAMO。实验是在配备NVIDIA GeForce RTX 3090 GPU的Linux服务器上进行的,使用Python 3.8。模型使用Adam优化器[22]进行训练,所有实验都使用固定的随机种子。对于超参数,我们设置批次大小为32,μ\muμ为0.5,β\betaβ为0.001,初始学习率为0.001。此外,由于数据集AAA中系统实体的异质性,包括三个层次:Pod、Service和Node,收集的数据特征在这几个层次上有所不同,使得某些基线难以统一训练。对于这样的基线,我们将数据集AAA划分为由不同类型实体组成的子集(例如,Ap,AsA_{p}, A_{s}Ap,As和AnA_{n}An),并对每个子集分别进行训练和测试以评估其性能。
C. RQ1: 根本原因定位的有效性
表一展示了根本原因定位的结果。实验数据显示,我们提出的TAMO模型在所有数据集上均取得了最佳或次优性能。具体来说,在AsA_{s}As数据集上,TAMO的得分超过第二佳得分至少6%6 \%6%,即使在第二佳性能的情况下,与最佳结果的差距也保持在3%以内,明显优于其他竞争对手。此外,我们观察到在B数据集上表现良好的Eadro和Transformer模型在异构数据集(如AsA_{s}As、ApA_{p}Ap和AnA_{n}An)上的性能显著下降。这是因为这两种方法只能处理同质实体特征(例如,在数据集B中,只有一种服务实体类型)。当面对需要单独处理的异构实体特征时,由于缺乏实体间相关性信息,其性能显著下降。相比之下,HolisticRCA和我们的方法以统一方式建模异构实体,在数据集A上仍保持强劲性能。与HolisticRCA相比,我们将多模态信息映射为时间序列特征,并通过时空建模进一步优化,从而在根本原因定位任务中取得更好的性能。
D. RQ2: 故障分类的有效性
在故障分类任务中,如表2所示,TAMO在两项关键指标——微观精度(MiPr)和宏观F1(MaF1)——上表现出显著优势。特别是在AnA_{n}An数据集上,TAMO的MaPr达到0.8869,MaF1达到0.8706,分别比第二佳模型(HolisticRCA)提高了24.32%24.32 \%24.32%和19.85%19.85 \%19.85%。TAMO在各项指标如精度、召回率和F1上均表现出色。此外,它在节点级别的复杂故障类型分类中表现出色。另外,TAMO在精度指标上表现出色,MiPr在AsA_{s}As和ApA_{p}Ap上分别达到0.7164和0.7182,比最佳基线模型高出8.09%8.09 \%8.09%和12.69%12.69 \%12.69%,显著降低了误分类的风险。尽管在较小的数据集BBB上MiPr低于基线模型LightGBM,TAMO在MaPr和F1指标上仍优于LightGBM。这表明TAMO在不同类别的表现更加均衡,对少数样本的类别取得了更好的分类结果。
E. RQ3: 消融研究
为了探索我们TAMO框架中每个组件的有效性,我们设计了三个变体模型并进行了消融实验。这些变体模型如下:
- TAMOw/oT1\mathrm{TAMO}_{w / o \mathcal{T}_{1}}TAMOw/oT1 :为了研究工具T1\mathcal{T}_{1}T1在融合多模态特征时所使用的扩散方法的有效性,在此变体中我们移除了工具T1\mathcal{T}_{1}T1,直接使用原始时间序列数据作为输入以评估变体性能。
-
- TAMOw/o branch \mathrm{TAMO}_{w / o \text { branch }}TAMOw/o branch :为了研究工具T1\mathcal{T}_{1}T1中双分支扩散模型的有效性,我们在这一变体中移除了负责维持时间特征的分支ϵtime \epsilon_{\text {time }}ϵtime 。仅在扩散重建过程中使用日志分支ϵlog \epsilon_{\text {log }}ϵlog 。然后使用重建的数据进行故障分类以评估变体性能。
-
- TAMOw/oFFT\mathrm{TAMO}_{w / o F F T}TAMOw/oFFT :为了研究为工具T2\mathcal{T}_{2}T2提出的基于频域的根本原因定位方法的有效性,我们在这一变体中移除了傅里叶过程。相反,直接使用原始时间域数据进行后续因果图生成和图卷积过程。然后输出根本原因定位结果以评估变体性能。
- 表二展示了消融实验的结果,从中可以看出,移除TAMO中的任何组件都会导致性能下降。这表明TAMO中的每个组件都有重要作用。特别是,没有工具T1\mathcal{T}_{1}T1的TAMO变体表现出显著的性能下降。这是因为变体TAMOw/oT1\mathrm{TAMO}_{w / o \mathcal{T}_{1}}TAMOw/oT1缺乏扩散模型融合多模态信息的能力,从而退化为仅学习单一模态特征。这种关键特征信息的缺失使得准确的根本原因分析变得困难。类似地,移除时间分支ϵtime \epsilon_{\text {time }}ϵtime 导致两个任务的性能明显下降,表明时间序列特征对于准确的故障定位和分类至关重要。消除FFT过程导致RE定位指标大幅退化,表明频域分析对于精确的根本原因定位至关重要。
F. RQ4: 案例研究
为了验证TAMO在云原生生态系统中的根本原因分析能力,本研究使用来自HipsterShop的真实世界故障数据进行案例调查。如图4所示,微服务系统使用Kubernetes (K8s)架构部署,服务组件使用多种编程语言开发。系统入口通过Frontend服务管理,每个服务节点配置了三个Pod副本。在服务和Pod级别设置了监控数据采集点。实验数据显示,TAMO在当前故障场景中展示了精确的根本原因识别:Currency Service的根本原因定位置信度达到97.96%(服务级别),而CheckoutPod0的置信度为82.39%82.39 \%82.39%(Pod级别)。值得注意的是,虽然整体Checkout服务运行正常,但仅Pod0出现问题。相比之下,Currency服务在服务级别遭受全局故障,导致Pods 0-2出现异常。这个对比案例表明,TAMO有效地整合了多实体特征和拓扑因果关系,实现了跨多个层次的精确根本原因诊断。在故障分类任务中,我们对异常服务/Pods的观测数据进行可视化分析:CheckoutPod0因“CPU Usage Second”等核心指标显著激增被准确分类为CPU过载故障。Currency服务表现出服务级别响应时间增加和服务请求成功率下降的相关性,而其Pod级别的接收数据包计数持续下降。TAMO通过多维时间序列模式分析成功识别出网络数据包丢失故障。
随后,我们将模型推理结果和系统上下文信息输入RCA专家LLM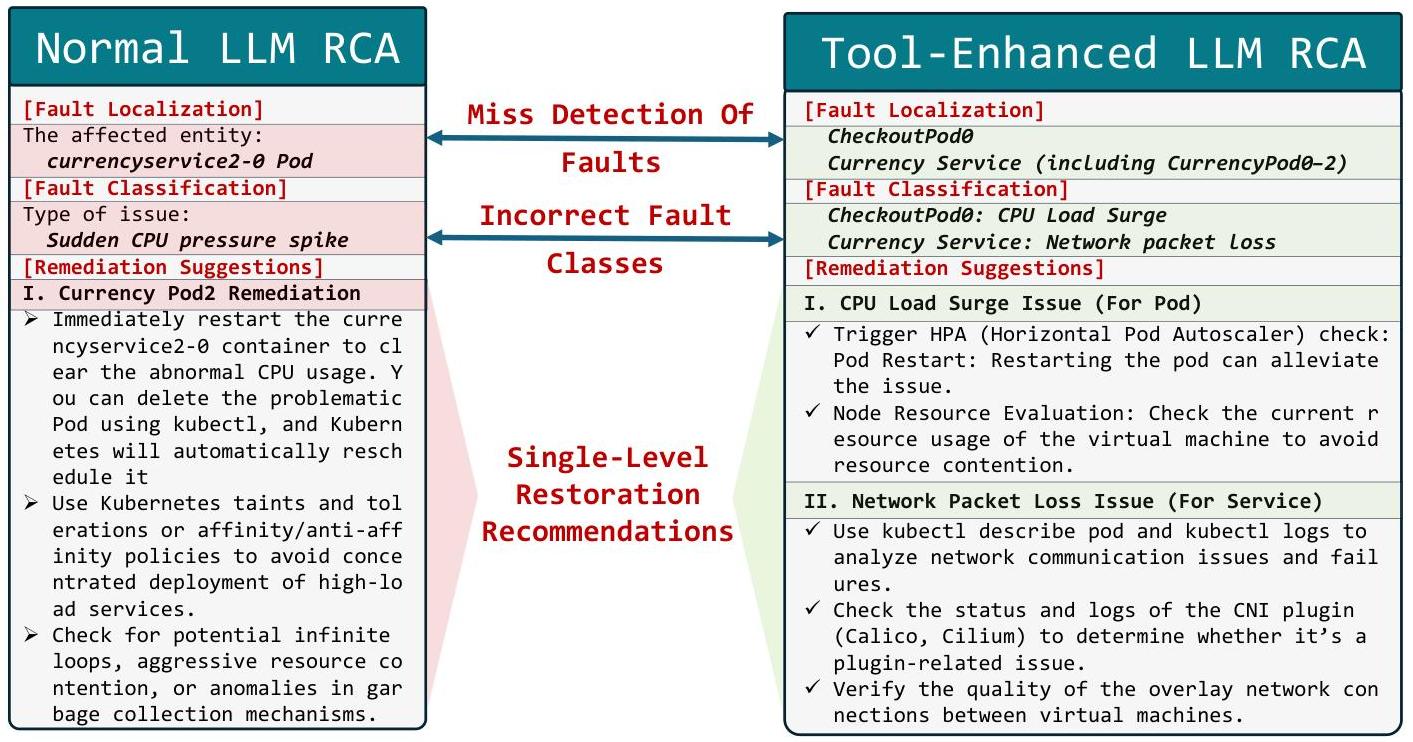
图5. TAMO工具增强的Agent AAA的LLM结果与直接对原始数据进行根本原因分析的比较
并与直接使用原始数据的LLM输出进行比较,如图5所示。该框架利用工具信息和领域专业知识准确分析当前系统故障并提供合理的修复建议。相比之下,仅使用原始数据的普通LLM由于严重的上下文限制难以处理大量观测数据,导致根本原因识别和故障分类中的重大遗漏和误判,以及相应的修复建议错误。
V. 结论
本文介绍了一种创新的工具辅助LLM代理框架TAMO,以解决云原生微服务环境中复杂的根本原因分析挑战。通过将领域特定工具与大型语言模型集成,TAMO有效处理高维、多模态云原生可观测性数据,并在动态变化的服务依赖关系中准确识别故障根源。该方法不仅克服了将原始可观测性数据转换为适合LLM处理格式时的信息丢失问题,还解决了静态预训练知识难以适应服务依赖关系实时变化的挑战。此外,通过结构化和提炼关键结果,它引导LLM生成上下文适当的修复策略,从而避免固定长度上下文窗口带来的限制。我们的研究表明,使用双分支协同扩散模型能够捕捉不同数据模态之间的一致模式,为下游分析任务提供统一的时间表示。此外,基于频域
注意力机制的根本原因定位方法增强了识别因果依赖模式的准确性,同时有效过滤低频噪声,实现精确的故障定位。实验结果显示,与现有的先进方法和基准相比,TAMO在两个标准数据集上的表现显著更好,突显了其提高故障诊断效率和准确性的潜力。进一步的消融研究和案例分析也验证了框架各组成部分的有效性和其协作工作的优越性能。然而,随着系统规模和复杂性的不断增长,如何更高效地处理更大体积的数据流并进一步增强实时解释性和跨模态语义对齐仍然是未来研究的关键领域。
参考文献
[1] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4技术报告。arXiv预印本arXiv:2303.08774, 2023.
[2] Aynau Amin, Lars Grunske, and Alan Colman. 基于时间序列建模的软件可靠性预测方法。Journal of Systems and Software, 86(7):1923-1932, 2013.
[3] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen技术报告。arXiv预印本arXiv:2309.16609, 2023.
[4] Shaked Brody, Uri Alon, and Eran Yahav. 图注意力网络有多注意?arXiv预印本arXiv:2105.14491, 2021.
[5] Brendan Burns, Brian Grant, David Oppenheimer, Eric Brewer, and John Wilkes. Borg, Omega, 和 Kubernetes。Communications of the ACM, 59(5):50-57, 2016.
[6] Yinfang Chen, Huaibing Xie, Minghua Ma, Yu Kang, Xin Gao, Liu Shi, Yunjie Cao, Xuedong Gao, Hao Fan, Ming Wen, Jun Zeng, Supriyo Ghosh, Xuchao Zhang, Chaoyun Zhang, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, and Tianyin Xu. 通过大型语言模型自动进行云事件的根本原因分析,2023.
[7] Yujun Chen, Xian Yang, Qingwei Lin, Hongyu Zhang, Feng Gao, Zhangwei Xu, Yingnong Dang, Dongmei Zhang, Hang Dong, Yong Xu, et al. 云服务系统的停机预测和诊断。In The world wide web conference, pages 2659-2665, 2019.
[8] Zekai Chen, Dingshuo Chen, Xiao Zhang, Zixuan Yuan, and Xiuzhen Cheng. 使用Transformer学习物联网中多变量时间序列异常检测的图结构。IEEE Internet of Things Journal, 9(12):9179−9189,20219(12): 9179-9189,20219(12):9179−9189,2021.
[9] Qian Cheng, Doyen Sahoo, Amrita Saha, Wenzhuo Yang, Chenghao Liu, Gerald Woo, Manpreet Singh, Silvio Saverese, and Steven CH Hoi. 云平台上的IT运维AI(AIOps):综述、机遇与挑战。arXiv预印本arXiv:2304.04661, 2023.
[10] Ailin Deng and Bryan Hooi. 基于图神经网络的多变量时间序列异常检测。In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 4027-4035, 2021.
[11] Min Du, Feifei Li, Guineng Zheng, and Vivek Srikumar. Deeplog: 通过深度学习从系统日志中进行异常检测和诊断。In Proceedings of the 2017 ACM SIGSAC conference on computer and communications security, pages 1285-1298, 2017.
[12] Angela Fan, Belir Dokkaya, Mark Harman, Mitya Lyubarskiy, Shubho Sengupta, Shin Yoo, and Jie M Zhang. 软件工程中的大型语言模型:调查与开放问题。In 2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE), pages 31-53. IEEE, 2023.
[13] Yu Gan, Mingyu Liang, Sundar Dev, David Lo, and Christina Delimitrou. Sage: 微服务中实用且可扩展的ML驱动性能调试。In Proceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, pages 135-151, 2021.
[14] Yongqi Han, Qingfeng Du, Ying Huang, Pengsheng Li, Xiaonan Shi, Jiaqi Wu, Pei Fang, Fufong Tian, and Cheng He. 通过可观测性数据对云原生系统中的故障进行整体根本原因分析。IEEE Transactions on Services Computing, 2024.
[15] Yongqi Han, Qingfeng Du, Ying Huang, Jiaqi Wu, Fufong Tian, and Cheng He. 一次性故障根本原因分析的潜力:大语言模型和小分类器的合作。In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, pages 931-943, 2024.
[16] Pingia He, Jieming Zhu, Zibin Zheng, and Michael R Lyu. Drain: 一种具有固定深度树的在线日志解析方法。In 2017 IEEE国际网络服务会议(ICWS),pages 33-40. IEEE, 2017.
[17] Jonathan Ho, Ajay Jain, and Pieter Abbeel. 去噪扩散概率模型。Advances in neural information processing systems, 33:6840-6851, 2020.
[18] Chuanjia Hou, Tong Jia, Yifan Wu, Ying Li, and Jing Han. 在微服务中使用异构数据源诊断性能问题。In 2021 IEEE国际并行与分布式处理应用、大数据与云计算、可持续计算与通信、社会计算与网络会议(ISPA/BDCloud/SocialCom/SustainCom),pages 493-500. IEEE, 2021.
[19] Ziqi Huang, Kelvin C. K. Chan, Yuming Jiang, and Ziwei Liu. 协作扩散用于多模态人脸生成和编辑,2023.
[20] Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: 高效的梯度提升决策树。Advances in neural information processing systems, 30, 2017.
[21] Asif Khan. 启用现代应用的关键特性:容器编排平台。IEEE Cloud Computing, 4(5):42-48, 2017.
[22] Diederik P Kingma. Adam: 一种随机优化方法。arXiv预印本arXiv:1412.6980, 2014.
[23] Cheryl Lee, Tianyi Yang, Zhuangbin Chen, Yuxin Su, and Michael R Lyu. Eadro: 一种基于多源数据的微服务端到端故障排除框架。In 2023 IEEE/ACM第45届国际软件工程会议(ICSE),pages 1750-1762. IEEE, 2023.
[24] Peiwen Li, Xin Wang, Zeyang Zhang, Yuan Meng, Fang Shen, Yue Li, Jialong Wang, Yang Li, and Wenwu Zhu. Realtcd: 使用大语言模型从干预数据中发现时间因果关系。In Proceedings of the 33rd ACM国际信息和知识管理会议,pages 4669-4677, 2024.
[25] Zeyan Li, Nengwen Zhao, Mingjie Li, Xianglin Lu, Lixin Wang, Dongdong Chang, Xiaohui Nie, Li Cao, Wenchi Zhang, Kaixin Sui, et al. 在线服务系统中可操作且可解释的重复故障定位。In Proceedings of the 30th ACM欧洲软件工程联合会议和软件工程基础研讨会,pages 996-1008, 2022.
[26] Shengsheng Lin, Weiwei Lin, Wentai Wu, Feiyu Zhao, Raichao Mo, and Haotong Zhang. Segrnn: 用于长期时间序列预测的段循环神经网络。arXiv预印本arXiv:2308.11200, 2023.
[27] Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3技术报告。arXiv预印本arXiv:2412.19437, 2024.
[28] Shutian Luo, Huanle Xu, Chengzhi Lu, Kejiang Ye, Guoyao Xu, Liping Zhang, Yu Ding, Jian He, and Chengzhong Xu. 表征微服务依赖和性能:阿里巴巴追踪分析。In Proceedings of the ACM Symposium on Cloud Computing, pages 412426, 2021.
[29] Yogi Nie, Nam H. Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. 时间序列值64个单词:使用Transformer进行长期预测,2023.
[30] Jannatan Noor, MD Badsha Faysal, MD Sheikh Amin, Bushra Tabasum, Tamim Raiyan Khan, and Tanvir Rahman. 异构UM架构上的Kubernetes应用性能基准测试:实验回顾。High-Confidence Computing, 5(1):100276, 2025.
[31] Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasmina Sadekova, Mikhail Kudinov, and Jiansheng Wei. 基于扩散的语音转换与快速最大似然采样方案。arXiv预印本arXiv:2109.13821, 2021.
[32] Jacopo Soldani, Damian Andrew Tamburri, and Willem-Jan Van Den Heuvel. 微服务的痛苦与收获:系统灰色文献综述。Journal of Systems and Software, 146:215-232, 2018.
[33] A Vaswani. 注意力就是你所需要的。Advances in Neural Information Processing Systems, 2017.
[34] Heng Wang, Shangbin Feng, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, and Yulia Tsvetkov. 语言模型能否解决自然语言中的图问题?Advances in Neural Information Processing Systems, 36:30840-30861, 2023.
[35] Zefan Wang, Zichuan Liu, Yingying Zhang, Aoxiao Zhong, Jihong Wang, Fengbin Yin, Lunting Fan, Lingfei Wu, and Qingsong Wen. Rcagent: 使用工具增强的大语言模型进行云根本原因分析。In Proceedings of the 33rd ACM国际信息和知识管理会议,pages 4966-4974, 2024.
[36] Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. Timesnet: 通用时间序列分析的二维时间变化建模。arXiv预印本arXiv:2210.02186, 2022.
[37] Meixia Yang and Ming Huang. 基于微服务的OpenStack监控工具。In 2019 IEEE第十届国际软件工程与服务科学会议(ICSESS),pages 706-709. IEEE, 2019.
[38] Zhenhe Yao, Changhua Pei, Wenxiao Chen, Hanzhang Wang, Liangfei Su, Huai Jiang, Zhe Xie, Xiaohui Nie, and Dan Pei. Chain-of-event: 通过自动学习加权事件因果图实现微服务的可解释根本原因分析。In Companion Proceedings of the 32nd ACM国际软件工程基础会议,pages 50-61, 2024. [39] Dongxiao Yu, Zhenzhen Xie, Yuan Yuan, Shuzhen Chen, Jing Qiao, Yangyang Wang, Yong Yu, Yifei Zou, and Xiao Zhang. 可信的去中心化协作学习以支持边缘智能:综述。High-Confidence Computing, 3(3):100150,2023.
[40] Guangba Yu, Pengfei Chen, Yufeng Li, Hongyang Chen, Xiaoyun Li, and Zibin Zheng. Nezha: 在多模态可观测性数据上可解释的细粒度根本原因分析。In Proceedings of the 31st ACM联合欧洲软件工程会议和软件工程基础研讨会,pages 553-565, 2023.
[41] Xinyu Yuan and Yan Qiao. Diffusion-ts: 针对通用时间序列生成的可解释扩散模型,2024.
[42] Shenglin Zhang, Pengxiang Jin, Zihan Lin, Yongqian Sun, Bicheng Zhang, Sibo Xia, Zhengdan Li, Zhenyu Zhong, Minghua Ma, Wa Jin, et al. 通过多模态数据实现微服务系统稳健的故障诊断。IEEE Transactions on Services Computing, 16(6):38513864, 2023.
[43] Wei Zhang, Hongcheng Guo, Jian Yang, Zhoujin Tian, Yi Zhang, Chaoran Yan, Zhoujun Li, Tongliang Li, Xu Shi, Liangfan Zheng, et al. mabc: 微服务架构中基于多代理区块链启发的协作进行根本原因分析。arXiv预印本arXiv:2404.12135, 2024.
[44] Xiao Zhang, Shuqing Xu, Huashan Chen, Zekai Chen, Fuzhen Zhuang, Hui Xiong, and Dongxiao Yu. 重新思考稳健的多变量时间序列异常检测:分层时空变分视角。IEEE Transactions on Knowledge and Data Engineering, 2024.
[45] Xiang Zhou, Xin Peng, Tao Xie, Jun Sun, Chao Ji, Wenhai Li, and Dan Ding. 微服务系统的故障分析与调试:工业调查、基准系统与实证研究。IEEE Transactions on Software Engineering, 47(2):243-260, 2018.

王琦是山东大学计算机科学与技术学院的医学博士生。他于山东大学获得理学学士学位。他的当前研究兴趣包括时间序列和预测维护。
张晓目前是山东大学计算机科学与技术学院的副教授。他的研究兴趣包括数据挖掘、分布式学习和联邦学习。他在享有盛誉的期刊和会议记录中发表了30多篇论文,如IEEE Transactions on Knowledge and Data Engineering, IEEE Transactions on Mobile Computing, NeurIPS, SIGKDD, SIGIR, UBICOMP, INFOCOM, ACM MULTIMEDIA, IJCAI, 和 AAAI。
李明毅目前是山东大学计算机科学与技术学院的医学博士生。她在山东大学获得理学学士学位。她的研究兴趣包括分布式协同学习和分布式算法的理论优化。
袁媛于2016年在山西大学数学科学学院获得理学学士学位,并于2021年在中国青岛山东大学计算机科学与技术学院获得博士学位。她目前是山东大学-南洋理工大学国际人工智能联合研究中心的博士后研究员。她的研究兴趣包括分布式计算和分布式机器学习。
肖梦海,博士,是中国山东大学计算机科学与技术学院的教授。他于2018年在美国乔治梅森大学获得计算机科学博士学位,于2011年在中国科学技术大学获得软件工程硕士学位。他曾是俄亥俄州立大学HPCS实验室的博士后研究员。他的研究兴趣包括多媒体系统和平行分布式系统。他在享有盛誉的会议上发表了论文,如USENIX ATC, ACM Multimedia, IEEE ICDE, IEEE ICDCS, IEEE INFOCOM。
庄福振于2011年在北京中国科学院计算技术研究所获得博士学位。他是北京航空航天大学人工智能研究院的全职教授。他在一些享有盛誉的期刊和会议记录中发表了超过150篇论文,例如Nature Communications, IEEE Transactions on Knowledge and Data Engineering, IEEE Transactions on Cybernetics, IEEE Transactions on Neural Networks and Learning Systems, ACM Transactions on Knowledge Discovery from Data, ACM Transactions on Intelligent Systems and Technology, Information Sciences, Neural Networks, SIGKDD, IJCAI, AAAI, TheWebConf, ACL, SIGIR, ICDE, ACM CIKM, ACM WSDM, SIAM SDM, 和 IEEE ICDM。他的研究兴趣包括迁移学习、机器学习、数据挖掘、多任务学习、知识图谱和推荐系统。他是CCF的高级会员。他于2013年获得了CAAI杰出博士论文奖。
余东晓于2006年在山东大学数学学院获得理学学士学位,并于2014年在香港大学计算机科学系获得博士学位。他于2016年成为华中科技大学计算机科学与技术学院的副教授。他目前是山东大学计算机科学与技术学院的教授。他的研究兴趣包括边缘智能、分布式计算和数据挖掘。
参考论文:https://arxiv.org/pdf/2504.20462

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)