OpenAI 发布 HealthBench:一个面向医疗问诊的大模型评估基准
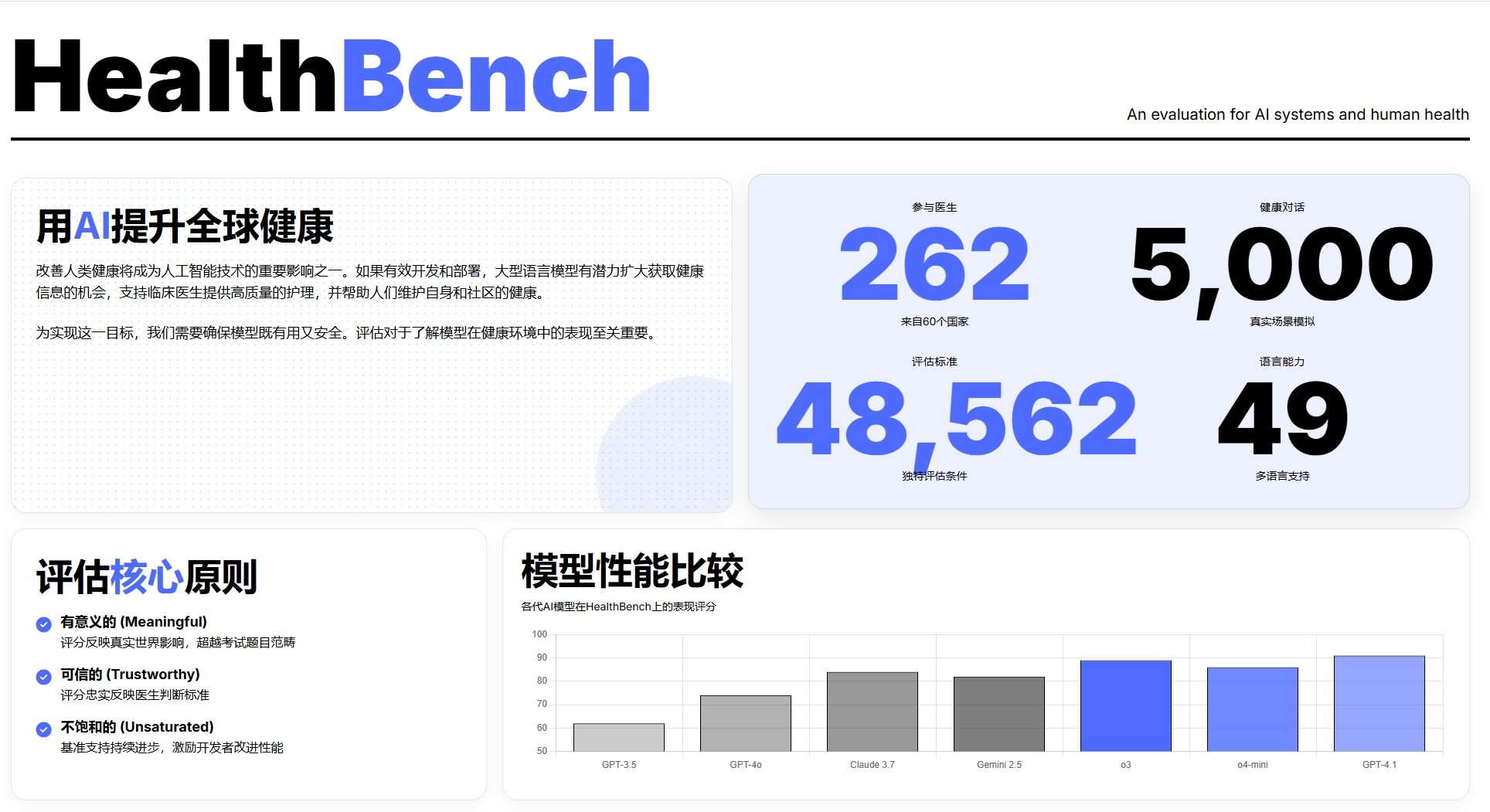
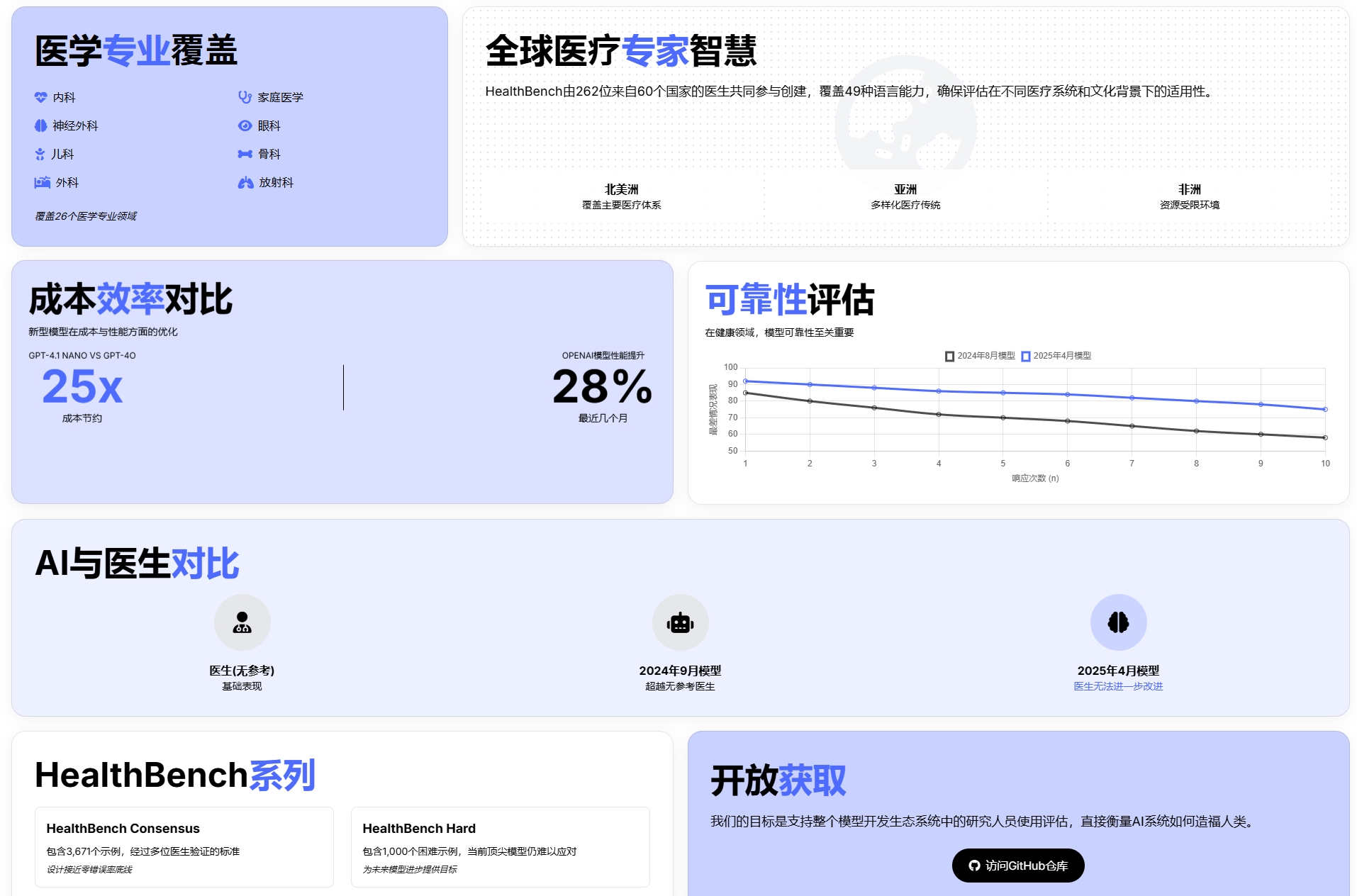
该基准由 262 位医生参与设计,涵盖 5000 个多轮对话场景,设置了超过 4.8 万个细致的评估维度。评估重点包括准确性、指令遵循、沟通能力等,场景涵盖急诊、临床数据转换、全球健康等。OpenAI 近日发布了开源评估基准 HealthBench,用于衡量大模型在医疗场景中的实际表现。对开发者和研究者而言,HealthBench 提供了一个高质量、可重复的测试框架,适合用于模型微调、评估和安全性
·
在大语言模型迅速发展的背景下,医疗领域的应用安全与可靠性亟需系统性评估。OpenAI 近日发布了开源评估基准 HealthBench,用于衡量大模型在医疗场景中的实际表现。
该基准由 262 位医生参与设计,涵盖 5000 个多轮对话场景,设置了超过 4.8 万个细致的评估维度。评估重点包括准确性、指令遵循、沟通能力等,场景涵盖急诊、临床数据转换、全球健康等。
对开发者和研究者而言,HealthBench 提供了一个高质量、可重复的测试框架,适合用于模型微调、评估和安全性验证。
原文链接:https://openai.com/index/healthbench/
步骤:
1-扩展程序飞书剪存存文档到飞书,飞书导出word文档
2-基于博主@歸藏的AI工具箱 的提示词+cluade 3.7输出了下面的这份HTML

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)