PP-YOLOE-SOD
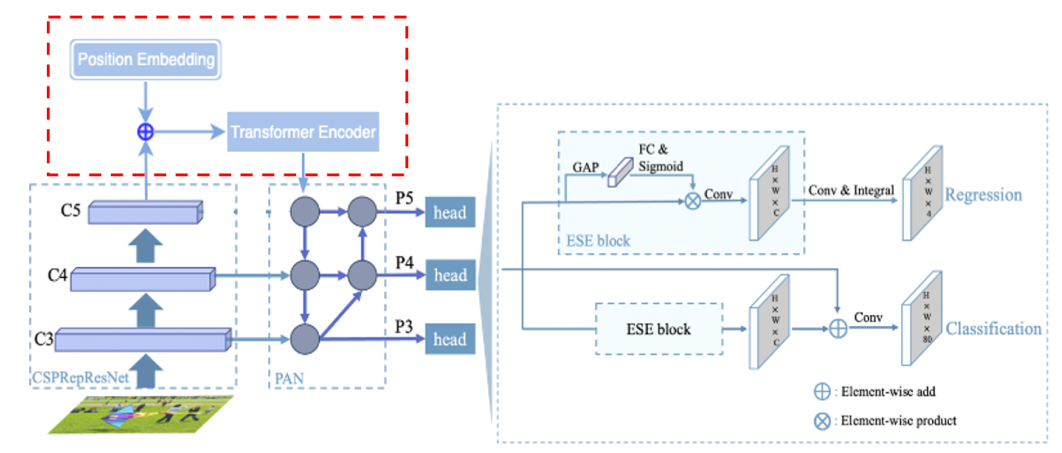
相比PP-YOLOE模型,PP-YOLOE-SOD改进点主要包括在neck中引入 Transformer全局注意力机制 以及在回归分支中使用 基于向量的DFL。Transformer在CV中的应用是目前研究较为火热的一个方向。最早的ViT直接将图像分为多个Patch并加入位置Embedding送入Transformer Encoder中,加上相应的分类或者检测头即可实现较好的效果。这里类似,主要加
相比PP-YOLOE模型,PP-YOLOE-SOD改进点主要包括在neck中引入 Transformer全局注意力机制 以及在回归分支中使用 基于向量的DFL 。
引入Transformer全局注意力机制
Transformer在CV中的应用是目前研究较为火热的一个方向。最早的ViT直接将图像分为多个Patch并加入位置Embedding送入Transformer Encoder中,加上相应的分类或者检测头即可实现较好的效果。
这里类似,主要加入了Position Embedding和Encoder两个模块,不同的是输入是最后一层特征图。
PP-YOLOE网络结构
官方文档:PaddleDetection/blob/release/2.8.1/configs/ppyoloe/README_cn.md
论文:PP-YOLOE: An evolved version of YOLO 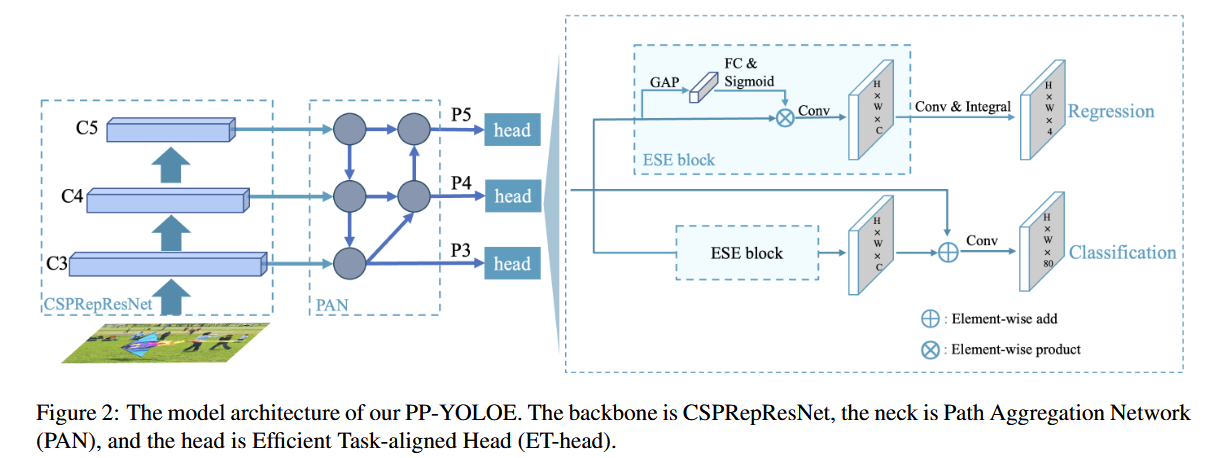
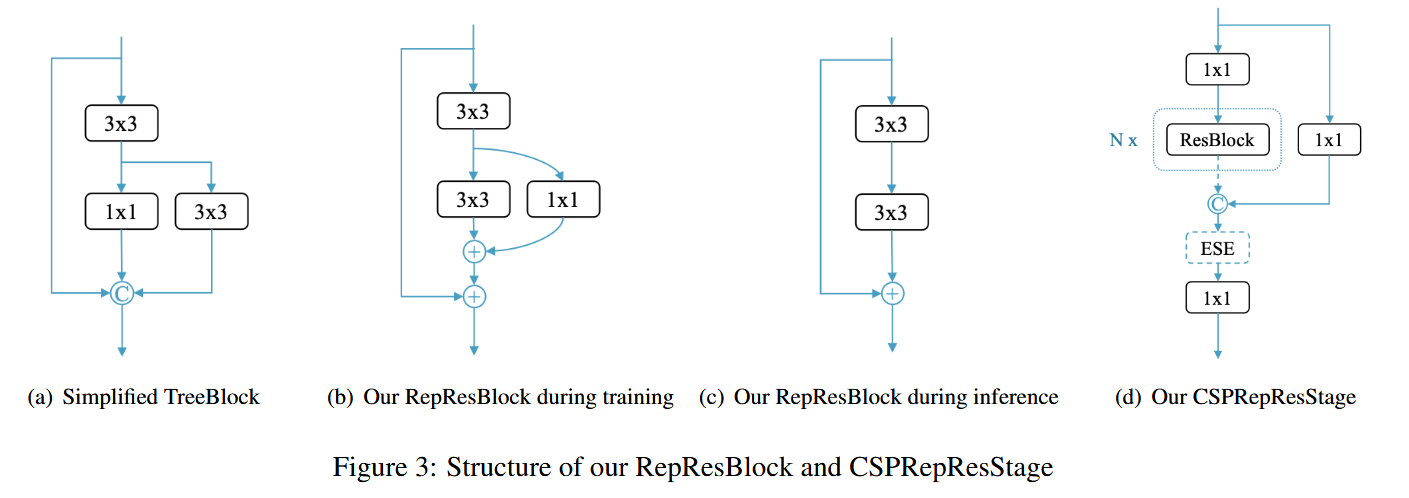
PP-YOLOE-SOD
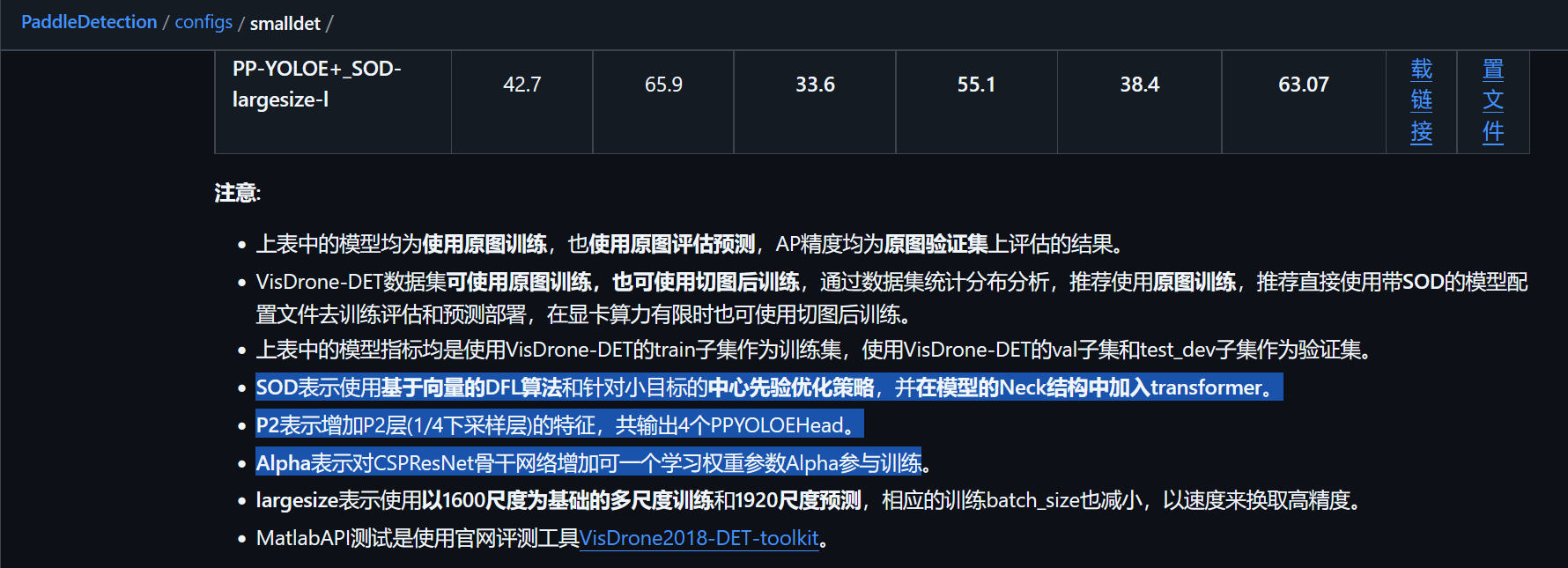
官方文档PaddleDetection/tree/release/2.8.1/configs/smalldet
VisDrone-DET 小目标检测模型 为例:
- PP-YOLOE-s
- PP-YOLOE-P2-Alpha-s
- PP-YOLOE±SOD-s
- PP-YOLOE-l
- PP-YOLOE-P2-Alpha-l
- PP-YOLOE±SOD-l
- PP-YOLOE-Alpha-largesize-l
- PP-YOLOE-P2-Alpha-largesize-l
- PP-YOLOE±largesize-l
- PP-YOLOE±SOD-largesize-l
核心改进点
PP-YOLOE-SOD 是PaddleDetection团队自研的小目标检测特色模型,核心改进点:
- 数据集分布相关的基于向量的DFL算法
- 针对小目标优化的中心先验优化策略
- 在模型的Neck(FPN)结构中加入Transformer模块
- 结合增加P2层
- 使用large size等策略
- 切图策略
最终在多个小目标数据集上达到极高的精度
网络结构:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)