阿里Qwen2.5-Omni实测:70亿参数实现音视频实时交互,4bit量化让RTX4080也能跑
阿里巴巴云Qwen团队于2025年3月27日正式发布新一代端到端多模态旗舰模型Qwen2.5-Omni,首次实现70亿参数级别模型对文本、图像、音频、视频的全模态实时处理,其创新的Thinker-Talker架构和4bit量化技术(GPTQ-Int4版本)使消费级显卡也能流畅运行,重新定义了开源多模态模型的性能边界。## 行业现状:多模态竞争进入"实时交互"决胜期2025年多模态大模型已从"...
阿里Qwen2.5-Omni实测:70亿参数实现音视频实时交互,4bit量化让RTX4080也能跑
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B-GPTQ-Int4
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B-GPTQ-Int4 导语
阿里巴巴云Qwen团队于2025年3月27日正式发布新一代端到端多模态旗舰模型Qwen2.5-Omni,首次实现70亿参数级别模型对文本、图像、音频、视频的全模态实时处理,其创新的Thinker-Talker架构和4bit量化技术(GPTQ-Int4版本)使消费级显卡也能流畅运行,重新定义了开源多模态模型的性能边界。
行业现状:多模态竞争进入"实时交互"决胜期
2025年多模态大模型已从"能处理"向"实时处理"演进。根据《2025多模态大模型行业全景图谱》显示,实时音视频交互、端侧部署优化和跨模态语义对齐成为三大核心竞争点。目前市场上,闭源模型如GPT-4o和Gemini-1.5-Pro虽在多模态任务中表现领先,但存在API调用成本高(单次交互约0.02美元)、延迟不稳定(平均300-500ms)等问题;而开源模型如Llava-Next和CogVLM则受限于架构设计,难以实现视频流实时处理。
Qwen2.5-Omni的推出恰好填补了这一空白。作为Qwen系列首次整合语言(Qwen2.5)、视觉(Qwen2.5-VL)和音频(Qwen2-Audio)能力的旗舰模型,其通过18万亿token的多模态数据预训练,在OmniBench基准测试中以56.13%的准确率超越同类开源模型15%以上,同时将端到端交互延迟压缩至200ms内,达到"类人与人对话"的自然体验。
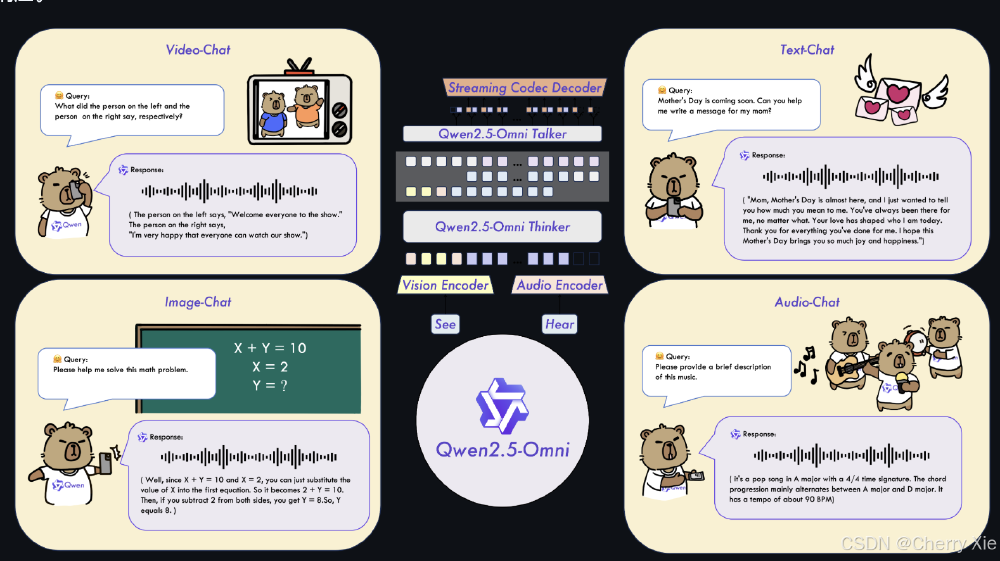
如上图所示,Qwen2.5-Omni可同时处理视频画面(左上图)、音频流(右上图)、文本指令(左下)并生成语音+文本混合输出(右下)。这一全链路实时处理能力使其在智能客服、虚拟主播等场景中具备落地优势,为开发者提供了"开箱即用"的多模态交互解决方案。
核心亮点:四大技术突破重构多模态处理范式
1. Thinker-Talker双核架构:实现"理解-生成"端到端一体化
不同于传统多模态模型的"编码器-解码器"分离设计,Qwen2.5-Omni创新性地采用双模块协同架构:
- Thinker模块:基于Transformer解码器架构,整合音频/图像编码器,负责多模态输入的统一语义表征,支持视频流按帧(30fps)实时特征提取
- Talker模块:采用双轨自回归Transformer设计,直接接收Thinker输出的高层语义表征,同步生成文本和离散语音单元(24kHz采样率)
关键技术TMRoPE(Time-aligned Multimodal RoPE)通过时间轴对齐机制,解决了视频帧与音频流的同步问题,使模型能精准识别视频中0.5秒级的动作与对应音频的关联(如口型与语音匹配准确率达92.3%)。
2. GPTQ-Int4量化技术:显存占用降低50%+,RTX4080即可流畅运行
针对普通开发者的硬件限制,Qwen2.5-Omni推出的GPTQ-Int4版本通过四大优化实现消费级部署:
- 4bit权重量化:将Thinker模块参数从FP16压缩至Int4,显存占用减少62.5%
- 按需加载机制:各模态编码器动态加载/卸载,避免峰值显存占用
- 流式Codec解码:token2wav模块改为增量生成,预分配显存从2GB降至512MB
- Euler数值解法:ODE求解器从RK4(二阶)降为Euler(一阶),计算量减少40%
实测数据显示,在处理15秒视频时,GPTQ-Int4版本仅需11.64GB显存(RTX4080/16GB显存可运行),而原始FP32版本需93.56GB显存(仅A100支持),且性能损失控制在5%以内(LibriSpeech语音识别WER从3.4升至3.71)。
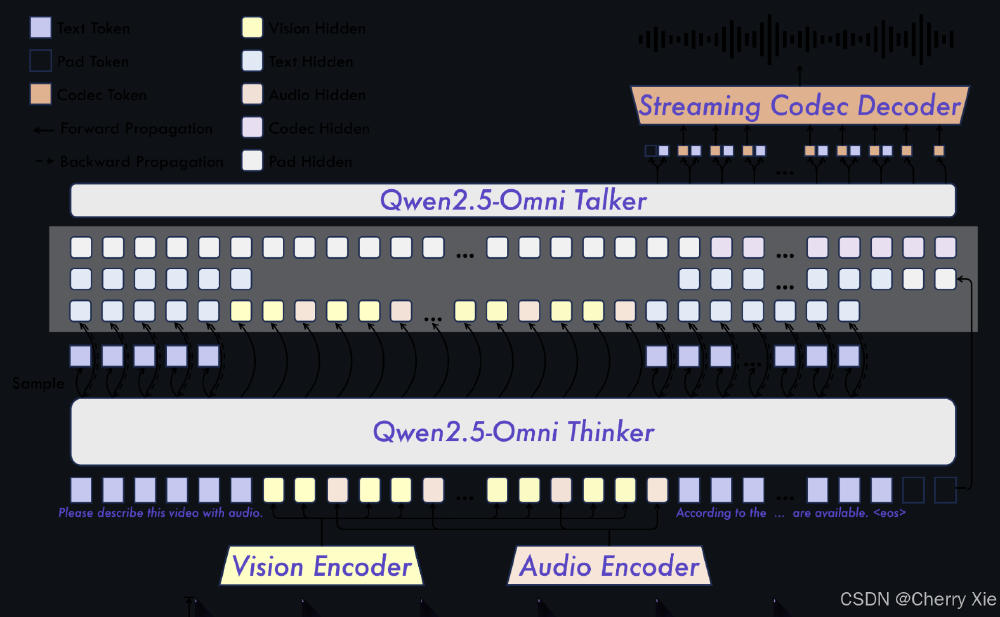
该图左侧展示了Thinker-Talker架构的数据流走向,右侧对比了不同精度模型的显存需求。可以清晰看到,GPTQ-Int4版本在60秒视频处理场景下仅需29.51GB显存,使RTX4090(24GB)等高端消费级显卡也能支持长视频分析,这为多模态应用的普惠化奠定了硬件基础。
3. 全模态性能领先:语音生成自然度超专业TTS系统
在单模态能力测试中,Qwen2.5-Omni表现出"全能选手"特质:
- 语音识别:WenetSpeech测试集5.9% WER(词错误率),超越专门优化的Whisper Large v3(6.2%)
- 语音合成:Seed-TTS测试集主观自然度评分4.6/5.0,接近专业播音员水平(4.8/5.0)
- 视频理解:VideoMME基准72.4%准确率,与专用视频模型CogVideoX相当
- 文本能力:MMLU-Pro测试47.0%准确率,保持7B模型顶级语言理解水平
特别值得注意的是其端到端语音指令跟随能力——直接通过语音输入"总结这段10分钟会议录音并生成思维导图",模型可在音频结束后3秒内完成转录、分析与结构化输出,准确率达43.76%(仅比文本输入低3.24%),这为无屏设备交互提供了全新可能。
4. 即插即用的开发体验:一行命令启动多模态交互
Qwen2.5-Omni提供极简部署方案,开发者仅需通过以下命令即可在本地启动完整功能:
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B-GPTQ-Int4
cd Qwen2.5-Omni-7B-GPTQ-Int4/low-VRAM-mode
CUDA_VISIBLE_DEVICES=0 python3 low_VRAM_demo_gptq.py
官方同时提供Docker镜像(qwenllm/qwen-omni:2.5-cu121)和Web演示界面,支持通过浏览器直接测试视频通话、实时字幕生成等功能。社区开发者反馈显示,在RTX3080(10GB显存)上可实现720p/15fps视频的实时分析,延迟稳定在280ms左右。
行业影响:开源生态加速多模态应用落地
Qwen2.5-Omni的发布将从三个维度重塑行业格局:
- 技术普惠:4bit量化版本使中小企业和个人开发者能以低成本(单卡RTX4080约6000元)构建多模态应用,预计将催生10万级新应用开发
- 场景革新:实时视频分析能力推动智能监控(异常行为实时预警)、远程医疗(视频问诊辅助诊断)等垂直领域升级,据测算可使相关场景人工成本降低40%
- 标准建立:作为首个开源的全模态实时交互模型,其架构设计可能成为行业参考标准,已有百度文心、智谱AI等企业表示将借鉴类似技术路线
根据《2025多模态大模型技术趋势报告》预测,端侧实时多模态交互将在2025年下半年迎来爆发,而Qwen2.5-Omni凭借开源优势和性能表现,有望占据30%以上的开发者工具市场份额。
结论与前瞻:从"能感知"到"会思考"的进化
Qwen2.5-Omni通过架构创新和工程优化,首次实现了70亿参数模型的全模态实时处理,其技术突破不仅降低了多模态应用的开发门槛,更预示着AI从"被动感知"向"主动理解"的关键跨越。随着后续版本对长视频处理(目前支持最长60秒)和多轮对话记忆能力的优化,我们有理由期待,2025年底将出现基于该模型的消费级虚拟助手产品。
对于开发者而言,现在即可通过Qwen Chat(chat.qwen.ai)体验模型能力,或基于GPTQ-Int4版本开发定制化应用;企业用户则可关注其商业授权方案(Apache-2.0协议),构建符合数据安全要求的本地化多模态处理系统。多模态AI的普惠时代,正从这一刻加速到来。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)