AI科普:全面了解LLM上下文工程(二):为什么要有上下文工程?
在上一篇文章中,我们聊了从提示词工程到上下文工程的发展过程,看到了大语言模型交互方式的逐步演化。
在上一篇文章中,我们聊了从提示词工程到上下文工程的发展过程,看到了大语言模型交互方式的逐步演化。
但问题来了:为什么我们还需要“上下文工程”? 模型不是已经越来越强了吗?上下文窗口不是已经越来越大了吗?
其实,正是这些“更大”“更强”的背后,隐藏着新的挑战。本篇文章,我们就来揭开“上下文工程”的必要性。以及,如果没有它,会发生什么。
构建现代上下文的结构化方式
随着提示词技术的不断演进,如今的上下文内容已经越来越“拥挤”:包括指令信息(instructions)、Few-Shot 示例、检索到的文档内容,还有工具定义等多种类型的信息。
如果我们只是把这些内容简单地拼接成一大段文字,问题就来了——模型很容易“看错重点”:可能会把一段检索文档误认为是指令,或者误把邮件里提到的函数名当作一个实际要调用的工具。
为了解决这种混乱,我们需要在上下文中引入清晰的结构。 一种非常有效的做法是:使用类似 XML 的标签来标记每一类内容。比如将不同的信息分别包裹在 <documents>、<tools>、<instruction> 等标签中,这样就能明确告诉模型:每一块信息的用途是什么。
下面是一个示例,展示了如何通过结构化的方式,让模型理解并调用一个名为 get_weather 的天气查询工具,通过这种结构化提示,不仅提升了上下文的可读性,也帮助模型更准确地理解不同内容的语义角色,从而做出更符合预期的响应。
<tools>
<tool_definition>
{
"name": "get_weather",
"description": "获取指定地点的当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市和州名,例如:San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
</tool_definition>
</tools>
<instruction>
请回答用户的问题。你可以使用已有工具。
</instruction>
<query>
旧金山现在的天气怎么样?
</query>
大语言模型(LLM)本身并不会直接执行函数。它所做的,是生成一段结构化的函数调用请求,例如下面这样的格式:
{
"tool_name": "get_weather",
"parameters": {
"location": "San Francisco, CA",
"unit": "fahrenheit"
}
}
真正执行这个函数的,是你应用程序中的代码。它需要负责解析这段 JSON,调用对应的函数,并将执行结果再传回模型,供模型生成最终的回答。
也就是说,模型负责“决定调用什么”,而你的程序负责“真正去做”。这种分工方式,让模型可以通过自然语言驱动工具执行,从而实现更强的动态交互能力。
---点击上方名片,关注AI拍档---
上下文工程存在的意义
超长上下文的隐藏代价
如今的大语言模型动辄拥有百万级 token 的上下文窗口,这让人很容易产生一种幻想:只要把整个数据库一股脑地喂给模型,它就能给出完美的答案。
但这种“填鸭式上下文”(context stuffing)的方法,实际上隐藏着不少代价和性能陷阱。
一味地扩大上下文,不仅不能保证效果,反而可能让模型的表现变得更不稳定、更低效。想要构建真正聪明、可靠的系统,靠“堆量”是远远不够的。更重要的,是如何聪明地构建、筛选和组织上下文。
上下文腐烂(Context Rot):当长上下文让模型“失灵”
在实际部署大语言模型时,一个令人担忧的新现象正在浮现——“上下文腐烂(Context Rot)”。
虽然现在很多模型宣称支持 10 万、甚至 100 万 token 的超长上下文窗口,但研究表明:模型的性能在输入仅达到几万 token 时,就开始明显下降,远未达到宣传中的理论上限。
Chroma 在 2025 年发布的一项综合研究,对市面上 18 款主流大模型进行了评估,涵盖 GPT-4.1、Claude 4、Gemini 2.5 和 Qwen3 等热门模型,测试内容包括多种长上下文任务。
结果很明确:模型处理长上下文的能力并不均衡。随着输入长度增加,即便是“重复词语”这类看似简单的任务,模型的输出也会越来越不稳定。
这意味着:上下文越长,模型越“健忘”,不仅准确率下降,还可能出现误解、遗漏、甚至“编造”内容的情况。 在设计长上下文交互系统时,不能盲目依赖模型的“token 容量”,更应关注上下文质量与结构化设计。
该研究揭示了关于“上下文腐烂(Context Rot)”的一些关键发现:
1.性能下降并不均匀
模型在长上下文中不是逐渐“优雅地衰减”,而是呈现出各种不稳定行为: 有的模型开始生成随机内容,有的则直接拒绝执行任务,还有很多模型在信心满满地输出却给出错误答案。
2.不同模型家族表现差异明显
OpenAI 的 GPT 系列表现最不稳定,容易出现“飘忽输出”或幻觉内容;
Claude 系列则相对保守,在不确定时宁愿选择不回答,也不会乱编答案。 这种差异提示我们,长上下文任务不仅受上下文长度影响,也强烈依赖模型架构本身的特性。
3.简单任务也变得不可靠
即使是像“复制一段重复文本,并在中间插入一个不同单词”这样简单的任务, 一旦输入超过 10,000 个词,多数模型就开始“迷失方向”——要么输出重复内容、要么输出中断、甚至胡乱生成。
这些发现清晰地表明: 上下文窗口的长度并不等于可用的有效信息容量。 与其盲目塞入更多上下文,不如构建更聪明、更结构化的上下文管理策略。这正是“上下文工程”所要解决的问题核心之一。
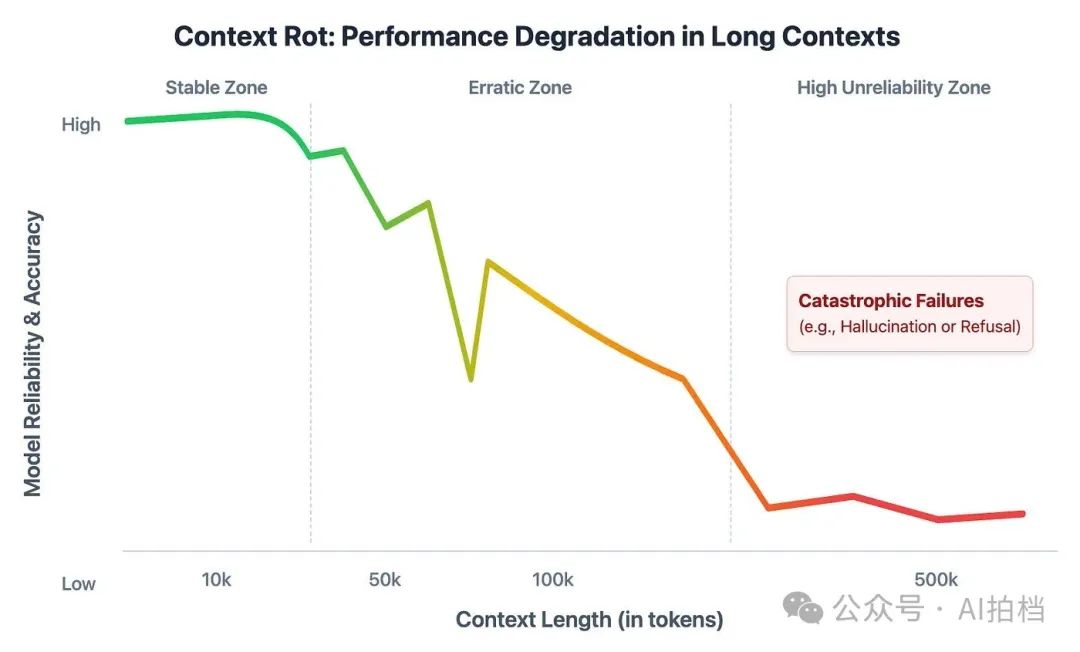
图表标题:《Context Rot:长上下文中的性能衰减曲线》
这张图直观展示了大语言模型在面对超长上下文时,性能是如何衰减的。横轴(X 轴)表示上下文长度(单位:千个 token),标记有 10k、50k、100k 和 500k;纵轴(Y 轴)表示模型的可靠性与准确性,从“低”到“高”。图中有一条代表真实模型表现的动态折线:
绿色部分:Stable Zone(稳定区):在 20k token 以内,折线平稳、高位,颜色为绿色,代表模型性能表现稳定、准确率高。
黄色部分:Erratic Zone(波动区):超过 20k 后,折线开始变得锯齿状,逐渐下滑,颜色从绿色转为黄色再变为橙色,表示模型开始出现不可预测的行为,例如:输出内容混乱;拒绝执行任务;自信地生成错误回答;图中某一处陡然下跌的位置被特别标注为:“Catastrophic Failure(灾难性失败,如胡乱回答或拒答)”
红色部分: High Unreliability Zone(高度不可靠区):当上下文进一步拉长至 100k、500k 时,折线彻底跌入低位,颜色变为红色且波动剧烈,表示模型性能已严重下降,完全无法依赖。
这张图发出的信号非常明确: 模型的“上下文极限”远不如它们声称的那么可用。 即使支持百万 token 的窗口,也不能盲目往里塞——性能早在“极限值”之前就已经开始失控。
如果我们希望构建更稳定、更智能的大模型系统,必须关注的不只是“上下文能装多少”,而是:如何科学地组织上下文,让每一个 token 都有意义。
这,正是“上下文工程”存在的真正理由。
这类研究建立在此前的一些重要成果之上,其中包括奠定基础的那篇论文:《When Transformers Know but Don’t Tell》。该研究发现,大语言模型常常在其隐藏表示中准确编码了目标信息的位置,但在生成回答时却没有真正利用这些信息。这就是所谓的“知道但不说”现象。
围绕长上下文退化的问题,还有许多其他维度的研究正在进行。 比如,关于 KV 缓存压缩(KV cache compression)的方法研究表明:在上下文长度和模型准确率之间,存在不可回避的权衡。 又如,另一些研究则探讨了上下文能力与推理能力之间的关系,指出当前模型架构本身可能就对“长上下文推理”存在结构性限制。
这些发现对真实应用场景具有深远影响。 虽然有研究显示,通过“信息密集型训练”可以在一定程度上让模型更充分地利用上下文,但核心问题依然存在:
-
上下文更长,不等于模型更聪明。
-
所谓“百万 token 上下文窗口”的承诺,可能更多是一种市场宣传,而非现实中的稳定能力。
对于工程实践者来说,这意味着我们需要从“追求最大上下文”转向“设计最有效上下文”。这正是上下文工程的精髓所在。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
第一不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献470条内容
已为社区贡献470条内容

所有评论(0)