30、LangChain开发框架(七)-- LangChain RAG实战
在前面的博文中有详细介绍,下面做一个简单的回顾。假设现在我们有一个偌大的知识库,当想从该知识库中去检索最相关的内容时,最简单的方法是:接收到一个查询(Query),就直接在知识库中进行搜索。假设提问的Query的答案出现在一篇文章中,去知识库中找到一篇与用户输入相关的文章是很容易的,但是我们将检索到的这整篇文章直接放入Prompt中并不是最优的选择,因为其中一定会包含非常多无关的信息,而无效信息越
一、RAG理论介绍
在前面的博文中有详细介绍,下面做一个简单的回顾。
假设现在我们有一个偌大的知识库,当想从该知识库中去检索最相关的内容时,最简单的方法是:接收到一个查询(Query),就直接在知识库中进行搜索。这种做法其实是可行的,但存在两个关键的问题:
- 假设提问的Query的答案出现在一篇文章中,去知识库中找到一篇与用户输入相关的文章是很容易的,但是我们将检索到的这整篇文章直接放入Prompt中并不是最优的选择,因为其中一定会包含非常多无关的信息,而无效信息越多,对大模型后续的推理影响越大。
- 任何一个大模型都存在最大输入的Token限制,一个流程中可能涉及多次检索,每次检索都会产生相应的上下文,无法容纳如此多的信息。
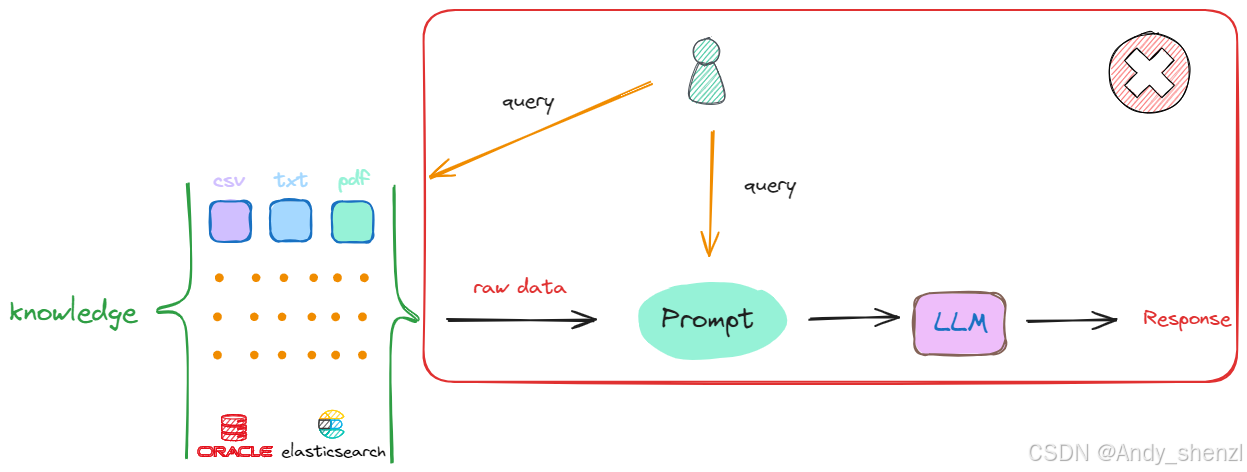
解决上述两个问题的方式是:把存放着原始数据的知识库(Knowledge)中的每一个raw data,切分成一个一个的小块,这些小块可以是一个段落,也可以是数据库中某个索引对应的值。这个切分过程被称为“分块”(chunking),如下述流程所示:
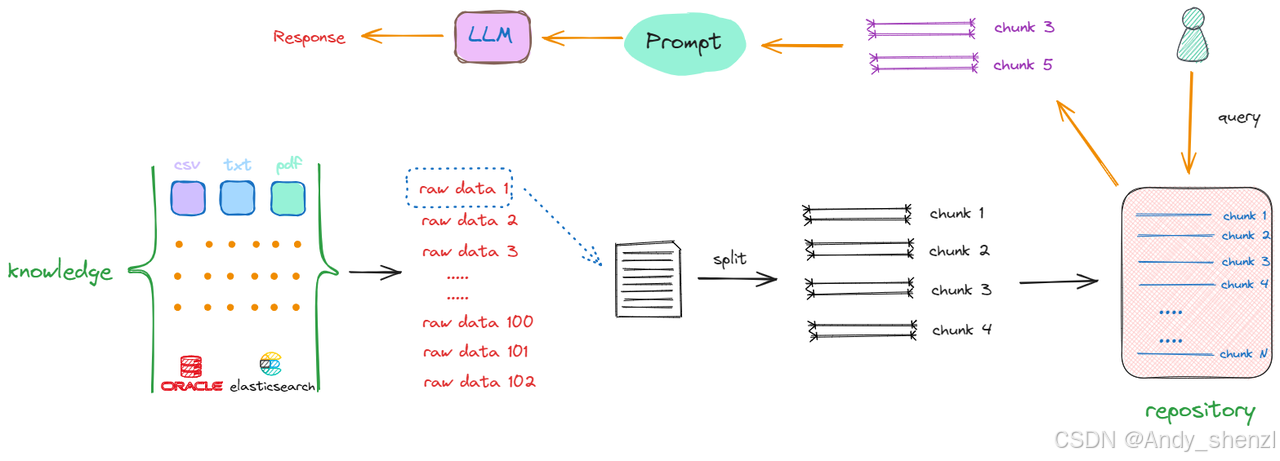
以第一个原始数据为例(raw data 1),通过一些特定的方法进行切分,一个完整的内容会被分割成 chunk1 ~ chunk4。采取相同的方法,继续对raw data 2、raw data 3直至raw data n进行切分。完成这一过程后,我们最终得到的是一个充满分块数据(chunks)的新的知识库(repository),其中每一项都是一个单独的chunk。例如,如果原始文档共有10个,那么经过切分,可能会产生出100个chunks。
完成这一转化后,当再次接收到一个查询(Query)时,就会在更新后的知识库(repository)中进行搜索,这时检索的范围就不再是某个完整的文档,而是其中的某一个部分,返回的是一个或多个特定的chunk,这样返回的信息量就会更小且更精确。随后,这些被检索到的chunk会被加入到Prompt中,作为上下文信息与用户原始的Query共同输入到大模型进行处理,以生成最终的回答。
在上述将原始数据(raw data)转化为chunk的过程中,就会包含构建RAG的第一部分开发工作:这包括如果做数据清洗,如去除停用词、标点符号等。此外,还涉及如何选择合适的split方法来进行数据切分的一系列技术。
接下来面临的问题是,尽管所有数据已经被切割成一个个chunk,其存储形式还是以字符串形式存在,如果想从repository中匹配到与输入的query相关的chunks,比较两句话是否相似,看一句话中相同字有几个,这显然是行不通的。我们需要获取的是句子所蕴含的深层含义,而非仅仅是表面的字面相似度。因此,大家也能想到,在NLP中去计算文本相似度的有效的方法就是Embedding,即将这些chunks转换成向量(vector)形式。所以流程会丰富如下:
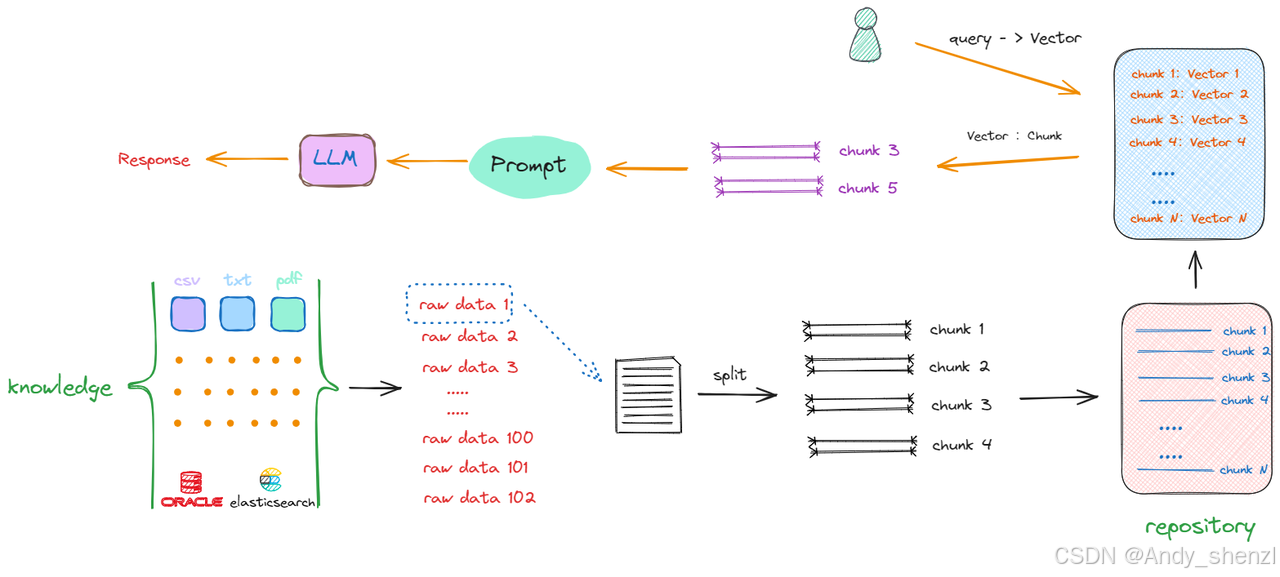
如上所示,解决搜索效率和计算相似度优化算法的答案就是:向量数据库。同时也产生了构建RAG的第三部分工作:我们要去了解和学习如何选择、使用向量数据库。
最终整体流程就如上图所示,一个基础的RAG架构会只要包含以下几方面的开发工作:
- 如何将原始数据转化成chunks;
- 如何将chunks转化成Vector;
- 如何选择计算向量相似度的算法;
- 如何利用向量数据库提升搜索效率;
- 如何把找到的chunks与原始query拼接在一起,产生最终的Prompt;
而上述流程,其实更像是一个自由拼接的结果,比如不同的文档类型可以选择不同的文档解析器,也可以选择不同的Vector数据库,甚至可以自由选择Embedding模型和Vector数据库的组合。其自由程度非常高,如下图所示:
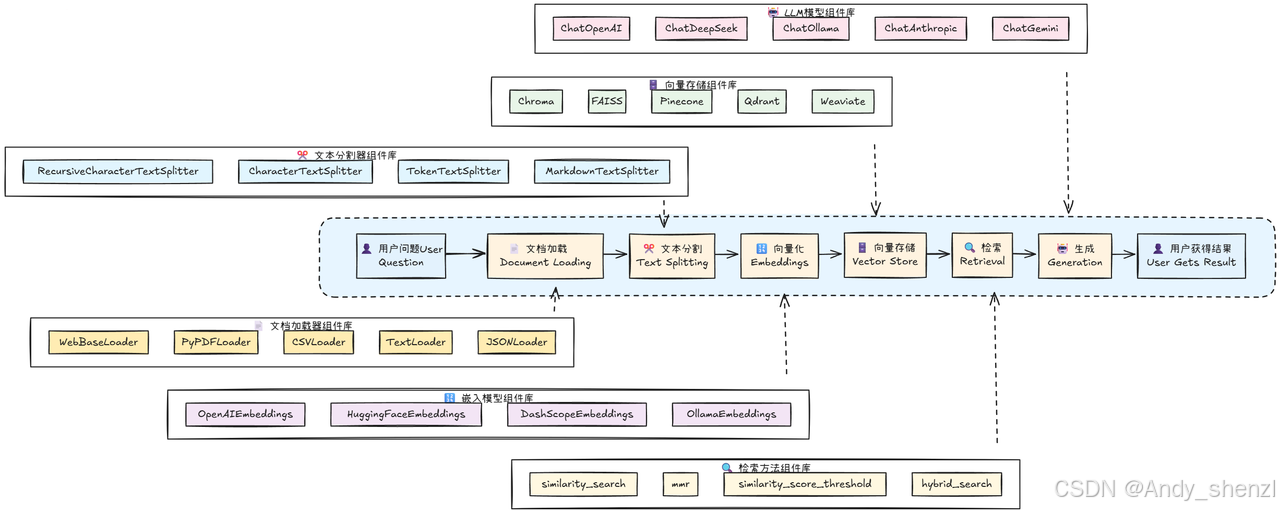
二、从零到一搭建小型RAG系统
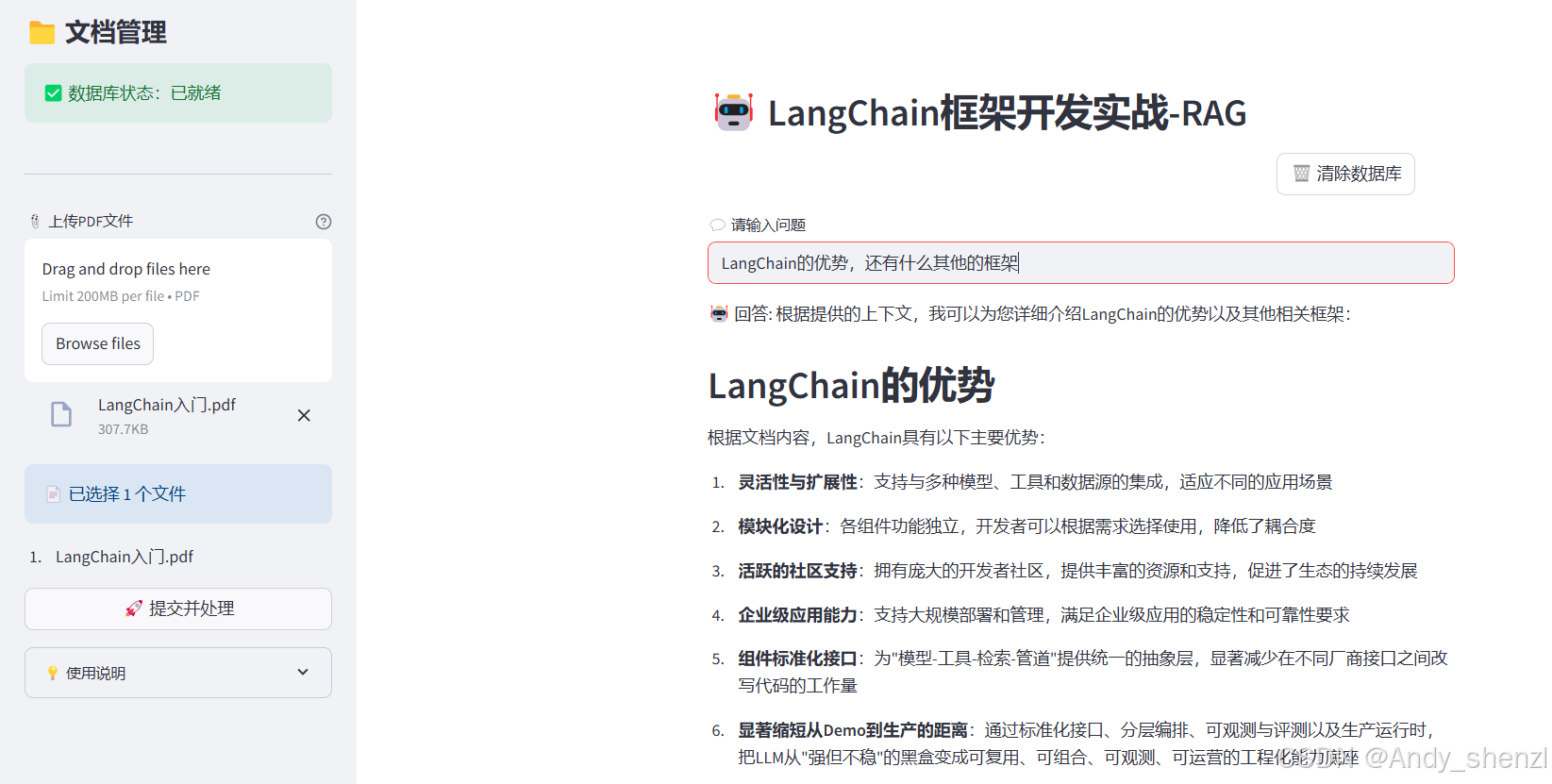
理解了在LangChain中构建RAG的基本原理后,我们就可以开始动手实践了。接下来的案例中,我们通过 Streamlit 前端界面,结合 LangChain 框架 与 DashScope 向量嵌入服务,实现了一个轻量化的 RAG(Retrieval-Augmented Generation) 智能问答系统,支持上传多个 PDF 文档,系统将自动完成文本提取、分块、向量化,并构建基于 FAISS 的检索数据库。用户随后可以在页面中输入任意问题,系统会调用大语言模型(如 DeepSeek-Chat)对 PDF 内容进行语义理解和回答生成。
2.1 导入库 & 环境初始化
import streamlit as st
from PyPDF2 import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.vectorstores import FAISS
from langchain.tools.retriever import create_retriever_tool
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain_community.embeddings import DashScopeEmbeddings
from langchain.chat_models import init_chat_model
import os
from dotenv import load_dotenv
load_dotenv(override=True)
DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")
dashscope_api_key = os.getenv("dashscope_api_key")
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
embeddings = DashScopeEmbeddings(
model="text-embedding-v1", dashscope_api_key=dashscope_api_key
)
-
os.environ[“KMP_DUPLICATE_LIB_OK”]=“TRUE”):
设置了一个环境变量,用于在多线程环境中避免因重复加载库而导致的冲突,通常出现在运行一些多线程或并行计算的系统中。 -
Streamlit是一个用来创建交互式Web应用的库。在这里,它被用来创建应用的用户界面,可能是用于展示处理结果或与用户互动。
-
PyPDF2是一个用于读取和操作PDF文件的库。PdfReader用于读取PDF文档,这可能是用来处理上传的文档内容。
-
并加载相关的密钥,dashscope_api_key 用阿里云 DashScope 提供的 text-embedding-v1 将文本转为向量表示,用于相似度搜索。也可替换成其他在线的embedding 模型。
2.2 处理 PDF 文本与向量化逻辑
def pdf_read(pdf_doc):
text = ""
for pdf in pdf_doc:
pdf_reader = PdfReader(pdf)
for page in pdf_reader.pages:
text += page.extract_text()
return text
def get_chunks(text):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_text(text)
return chunks
def vector_store(text_chunks):
vector_store = FAISS.from_texts(text_chunks, embedding=embeddings)
vector_store.save_local("faiss_db")
- pdf_read(pdf_doc) 函数用于读取PDF文件并提取其中的文本内容。
- get_chunks(text) 函数将一个大的文本字符串分割成多个较小的文本块。使用RecursiveCharacterTextSplitter类来分割文本。它将文本分割成最大为1000个字符的小块,并且每个块之间有200个字符的重叠部分
- vector_store(text_chunks) 函数将文本块转化为向量,并将这些向量存储在FAISS数据库中。
2.3 Agent对话链 + 工具调用(核心 RAG)
def get_conversational_chain(tools, ques):
llm = init_chat_model("deepseek-chat", model_provider="deepseek")
prompt = ChatPromptTemplate.from_messages([
(
"system",
"""你是AI助手,请根据提供的上下文回答问题,确保提供所有细节,如果答案不在上下文中,请说"答案不在上下文中",不要提供错误的答案""",
),
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
])
tool = [tools]
agent = create_tool_calling_agent(llm, tool, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tool, verbose=True)
response = agent_executor.invoke({"input": ques})
print(response)
st.write("🤖 回答: ", response['output'])
def check_database_exists():
"""检查FAISS数据库是否存在"""
return os.path.exists("faiss_db") and os.path.exists("faiss_db/index.faiss")
def user_input(user_question):
# 检查数据库是否存在
if not check_database_exists():
st.error("❌ 请先上传PDF文件并点击'Submit & Process'按钮来处理文档!")
st.info("💡 步骤:1️⃣ 上传PDF → 2️⃣ 点击处理 → 3️⃣ 开始提问")
return
try:
# 加载FAISS数据库
new_db = FAISS.load_local("faiss_db", embeddings, allow_dangerous_deserialization=True)
retriever = new_db.as_retriever()
retrieval_chain = create_retriever_tool(retriever, "pdf_extractor", "This tool is to give answer to queries from the pdf")
get_conversational_chain(retrieval_chain, user_question)
except Exception as e:
st.error(f"❌ 加载数据库时出错: {str(e)}")
st.info("请重新处理PDF文件")
- get_conversational_chain(tools, ques) 函数负责创建一个基于deepseek-chat模型的对话链,并通过提供的工具回答用户问题。
- check_database_exists() 函数检查本地是否存在FAISS数据库文件。
- user_input(user_question) 函数处理用户输入的问题,并根据数据库的存在与否进行相应的处理。
2.4 主界面逻辑(Streamlit)
def main():
st.set_page_config("🤖 LangChain框架开发实战")
st.header("🤖 LangChain框架开发实战-RAG")
# 显示数据库状态
col1, col2 = st.columns([3, 1])
with col1:
if check_database_exists():
pass
else:
st.warning("⚠️ 请先上传并处理PDF文件")
with col2:
if st.button("🗑️ 清除数据库"):
try:
import shutil
if os.path.exists("faiss_db"):
shutil.rmtree("faiss_db")
st.success("数据库已清除")
st.rerun()
except Exception as e:
st.error(f"清除失败: {e}")
# 用户问题输入
user_question = st.text_input("💬 请输入问题",
placeholder="例如:这个文档的主要内容是什么?",
disabled=not check_database_exists())
if user_question:
if check_database_exists():
with st.spinner("🤔 AI正在分析文档..."):
user_input(user_question)
else:
st.error("❌ 请先上传并处理PDF文件!")
# 侧边栏
with st.sidebar:
st.title("📁 文档管理")
# 显示当前状态
if check_database_exists():
st.success("✅ 数据库状态:已就绪")
else:
st.info("📝 状态:等待上传PDF")
st.markdown("---")
# 文件上传
pdf_doc = st.file_uploader(
"📎 上传PDF文件",
accept_multiple_files=True,
type=['pdf'],
help="支持上传多个PDF文件"
)
if pdf_doc:
st.info(f"📄 已选择 {len(pdf_doc)} 个文件")
for i, pdf in enumerate(pdf_doc, 1):
st.write(f"{i}. {pdf.name}")
# 处理按钮
process_button = st.button(
"🚀 提交并处理",
disabled=not pdf_doc,
use_container_width=True
)
if process_button:
if pdf_doc:
with st.spinner("📊 正在处理PDF文件..."):
try:
# 读取PDF内容
raw_text = pdf_read(pdf_doc)
if not raw_text.strip():
st.error("❌ 无法从PDF中提取文本,请检查文件是否有效")
return
# 分割文本
text_chunks = get_chunks(raw_text)
st.info(f"📝 文本已分割为 {len(text_chunks)} 个片段")
# 创建向量数据库
vector_store(text_chunks)
st.success("✅ PDF处理完成!现在可以开始提问了")
st.balloons()
st.rerun()
except Exception as e:
st.error(f"❌ 处理PDF时出错: {str(e)}")
else:
st.warning("⚠️ 请先选择PDF文件")
# 使用说明
with st.expander("💡 使用说明"):
st.markdown("""
**步骤:**
1. 📎 上传一个或多个PDF文件
2. 🚀 点击"Submit & Process"处理文档
3. 💬 在主页面输入您的问题
4. 🤖 AI将基于PDF内容回答问题
**提示:**
- 支持多个PDF文件同时上传
- 处理大文件可能需要一些时间
- 可以随时清除数据库重新开始
""")
if __name__ == "__main__":
main()
- 侧边栏:提供文件上传和状态信息,用户可以在这里上传PDF文件,并查看数据库的状态。
- st.columns([3, 1]):定义两个列布局,左边占3格,右边占1格。
- 左侧列:如果数据库存在,什么也不显示;否则显示警告,提示用户先上传并处理PDF文件。
- 右侧列:提供一个按钮用于清除数据库。如果点击按钮,尝试删除faiss_db目录,清除本地存储的数据库。
- 用户输入:提供一个文本框,让用户输入问题。文本框只有在数据库已准备好时才可用。
- 问题提交:如果用户输入问题,且数据库已准备好,则显示“AI正在分析文档”的加载提示,并调用user_input函数来处理问题。如果数据库未准备好,则提示用户先上传PDF文件。
- 处理按钮逻辑:如果点击了“提交并处理”按钮,首先读取PDF文件的内容,如果无法提取文本则显示错误信息。如果提取成功,则分割文本并创建向量数据库,最后显示处理成功的提示并重新加载页面。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)