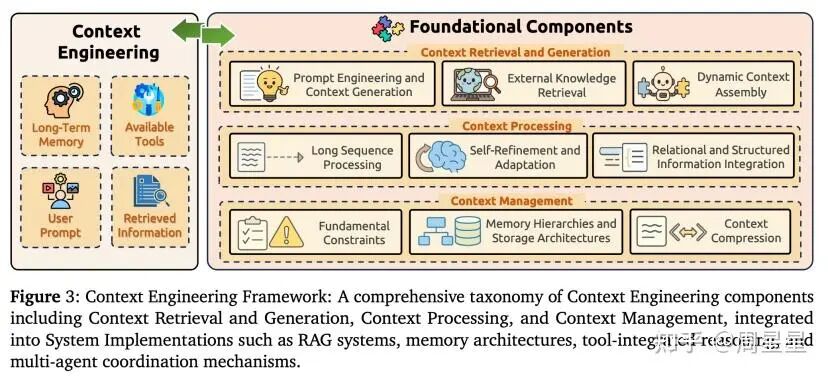
Context Engineering:大模型时代必学的4学分系统学科!!
Context Engineering是随着LLM和Agent技术发展而兴起的一门系统学科,主要解决如何在复杂Agent系统中有效组织和管理上下文的问题。它超越了传统Prompt Engineering,需要考虑如何在不同子Agent间传递信息、管理长上下文、选择和压缩相关内容等。文章详细介绍了Write、Select、Compress和Isolate四种上下文工程方法,并讨论了Single Ag
我认为 Context Engineering 是一门系统学科,内容量完全可以在大学开一门 4 学分的大课。
假如我是任课老师,我会这样安排:2周讲 Prompt、3周讲 RAG、3周讲 Memory、3周讲 Tools 和 MCP、2周介绍主流 Agent 框架、2周学习Agent评估,最后2周拆解实际案例(如 Claude Code/Deep Research)。
一段话说明什么是Context Enigneering:
假设你在设计一个Agent系统,下图每个绿色方框代表一个sub-Agent执行独立任务。当红色框的sub-Agent需要处理任务时,我们要考虑
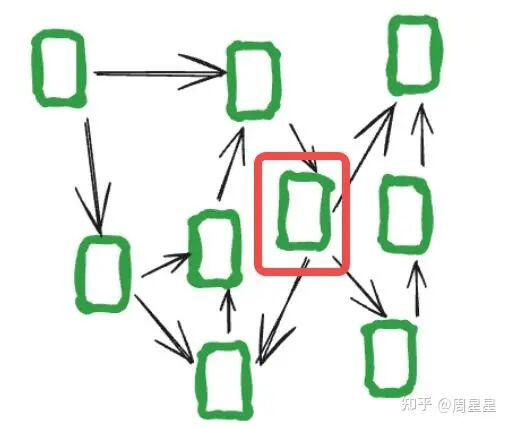
1.如何将其它sub-Agent 获取的信息有效地加入当前sub-Agent的上下文中。
2.如何根据当前sub-Agent要处理的任务,把合适的外部的知识库/记忆/工具用合理的格式放到当前sub-Agent的上下文中。
3.如果当前sub-Agent上下文过长,还需合理选择或压缩这些信息。
4.如何把当前 Agent 对其它子任务有帮助的信息保存下来,以便其它子 Agent 能利用这些信息更好地完成它们的任务。
5…
简单来说,Context Engineering 要从全局角度考虑如何组织和管理上下文,以最大化每个子任务的效果,从而提升整体任务的效果。
一、Context Engineering火起来的来龙去脉
随着LLM/Agent的发展必然的产物
最近Context Engineering很火,实际上是LLM和Agent技术高速发展的过程中的必然结果。 过去,人们主要把LLM用作ChatBotAI,交互相对简单,对上下文的依赖也有限。如下图所示

简单的ChatBotAI对话
但到了 2025 年,更强大的SOTA模型出现(如gpt5、claude4.0、gemini2.5),以及越来越复杂的Agent架构投入实际使用,如下图所示,LLM逐渐走向真正的生产力阶段。
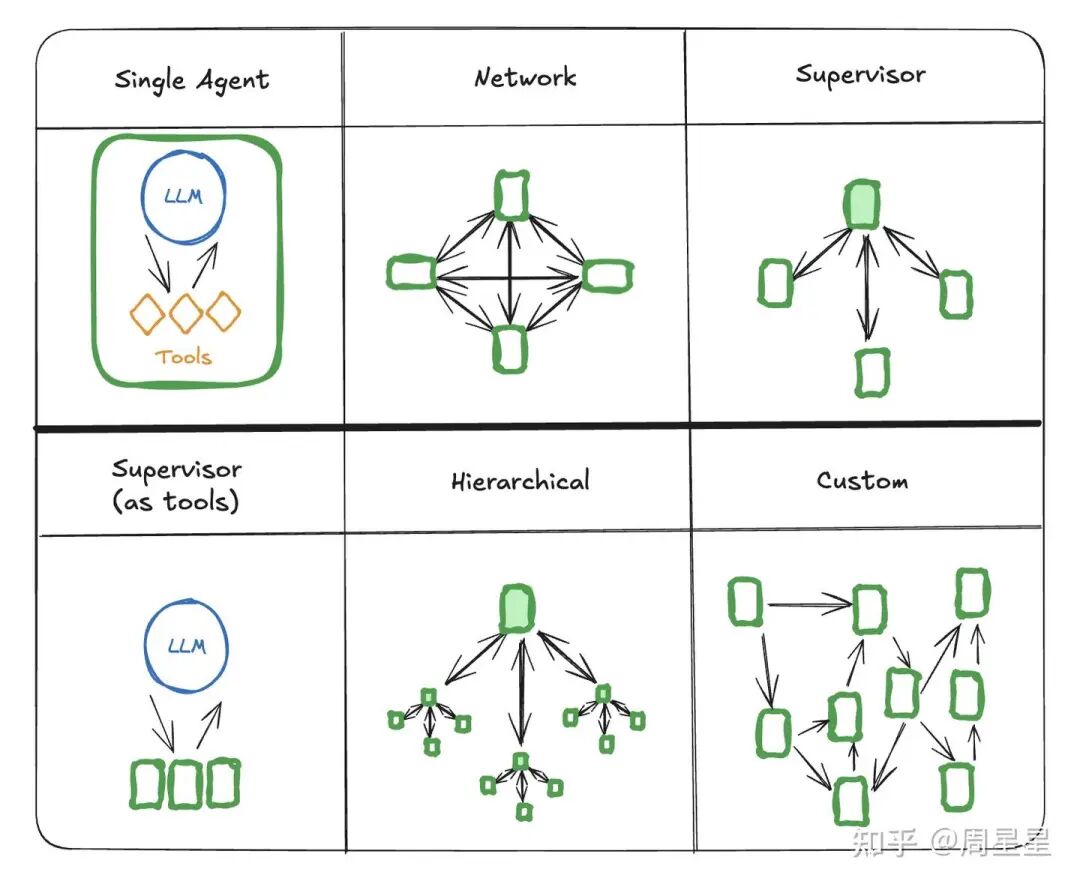
越来越多的Agent架构
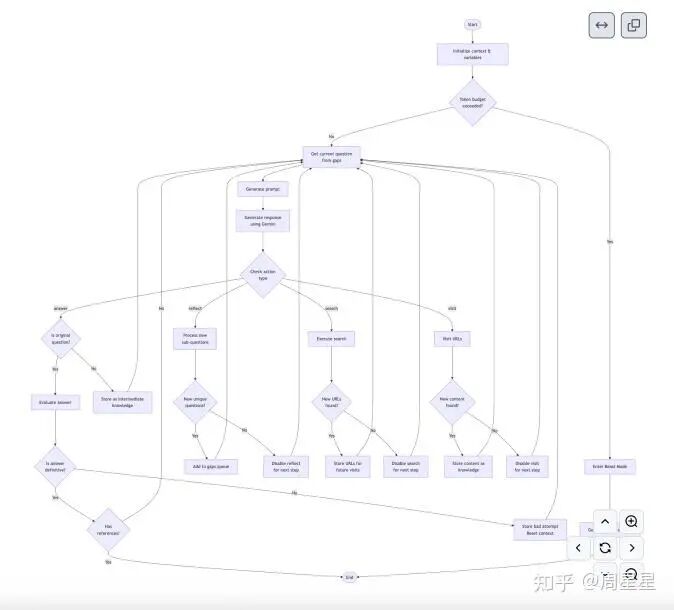
某个Deep Research的工作流
我相信,有很多开发者都会意识到, 大多数 Agent 的效果问题,并不是模型本身的性能问题,而在于未能向模型传达适当的上下文。
这种现象其实上边年就存在了,但过去缺乏一个清晰的概念来描述。随着技术的发展,人们不断发明新的抽象和术语,来帮助大家更容易地理解最佳实践和方法论。“Context Engineering” 正是这样一个抽象出来的概念。
知名人士的宣传
当然,火起来,离不开一些大佬的推动,例如Shopify CEO在今年6月19日推特上的一句话

他形容“Context Enigneering”是一门为LLM提供能使其合理解决任务所需的所有上下文信息的艺术。
随后,Andrej Karpathy 6月25日跟进点评(大家也知道Andrej Karpathy在AI界的江湖地位,例如Software 2.0、vibe coding等热词)。

下图是Google Trends上,关于Prompt Engineering和Context Engineering的趋势图,可以看到今年6月份发生了突升的讨论。
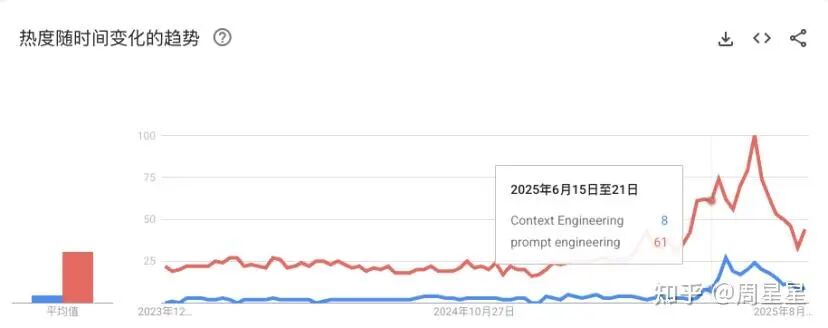
当前的Context Engineering是只有真正深入的Agent开发者才懂的东西,prompt engineering是context engineering的一个子集,后面会说到。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

Context Engineering 与 Prompt Engineering 的异同
Prompt Enineering是Context Enigneering的一个子集。
我们常看到prompt的组成,包括有
- • 系统提示/指令(System Prompt/Instructions)
- • 用户输入(User Input)
- • 短期记忆或聊天历史(Short-term Memory or Chat History)
- • 长期记忆(Long-term Memory)
- • 从知识库中检索的信息(Information Retrieved from a Knowledge Base / RAG)
- • 工具及其定义(Tools and their Definitions)
Context Engineering 要解决的是动态问题 —— 不只是写一个 prompt,就像我在开头写的:
假设你在设计一个Agent系统,下图每个绿色方框代表一个sub-Agent执行独立任务。当红色框的sub-Agent需要处理任务时,我们要考虑
1.如何将其它sub-Agent 获取的信息有效地加入当前sub-Agent的上下文中。
2.如何根据当前sub-Agent要处理的任务,把合适的外部的知识库/记忆/工具用合理的格式放到当前sub-Agent中。
3.如果当前sub-Agent上下文过长,还需合理选择或压缩这些信息。
4.如何把当前 Agent 对其它子任务有帮助的信息保存下来,以便其它子 Agent 能利用这些信息更好地完成它们的任务。
5…
(重复了一遍开头的话,重要的事情重复都几次嘛)
例如,在电商客服场景中,一个中枢 Agent 会协调多个子 Agent(个性化、网页浏览、数据库查询、代码执行、回答、质检等),每sub-Agent 都需要不同的上下文,我们要从更系统更整体的角度去考虑怎么组织这些context。
所以,Context Engineering当然不等同Prompt Engineering了。咱们也没见多哪个Prompt Enigneering的教程会教你怎管理memory吧。
LangChain 的博客《The rise of “context engineering[1]”》指出,Context Engineering 的核心在于构建动态系统,能够在合适的时间以合适的方式提供信息和工具,从而让 LLM 比较好完成任务。
二、为什么需要上下文工程Why Context Engineering
Context Engineering 要解决的痛点在于:上下文太长或太短都会出问题,本质是信噪比的平衡。
长度太长不行
有人可能说,为啥要组织,直接一把梭,把当前sub-agent之前所有上游agent的输出,用messages的方式拼接作为当前sub-agent的上下文不就完事了吗?
但实际上,这种简单粗暴的方法会效果爆炸。
本人的经验,现在很多模型号称支持百万级上下文,但实际表现并不好。24年时,我做个一个观点聚类的任务,把成千上万调条网民评论放到 Kimi 里让它总结网民观点。输入不超过32K时,效果很不错,归纳提炼效果很棒;但一旦超过 32K,就明显退化,例如前面的十条观点会被过度关注后面的观点被忽略,总结的提炼程度降低。超过 100K 甚至直接出现乱码、重复。
现在长上下文的测评,主要还是用 perplexity、大海捞针任务,或者合成的 LongEval 数据来评估。但这些测试过于理想化、难度低,无法真正反映复杂场景下长上下文的挑战。
更进一步,在《How Long Contexts Fail[2]》里提到四种上下文损坏的情况。
- • Context Poisoning: When a hallucination makes it into the context
- • Context Distraction: When the context overwhelms the training
- • Context Confusion: When superfluous context influences the response
- • Context Clash: When parts of the context disagree
这里分别举一个Context Distraction和Context Clash的例子让大家代入:
Context Distraction(上下文干扰):模型被一堆历史信息拖住,忽视新的目标。
例子:我平时用 Cursor/Trae 这类 AI 工具写代码时,经常遇到一个问题:当对话里积累了太多历史报错记录,模型就会被干扰。比如,我只是问个简单问题:“写个数组反转函数”,它却仍然沉迷在之前的报错修复里,回答完全跑题,大部分原因是模型误以为新问题依旧和那些报错修复相关,结果回答时跑题,模型会纠结这个简单的query是不是跟之前的报错有关系。
现在我的经验是,只要连续出现 3 次以上报错,我就会直接新开一个对话,否则继续在原窗口聊,代码质量会明显下降。这就是 Context Distraction——无关的噪音上下文拖住了模型,让它无法专注新任务。# 实战/哲学/理念
Context Clash(上下文冲突):上下文里有矛盾信息,模型不知道听谁。
例子:家装顾问对话里,用户一开始说“我喜欢北欧极简风,最好白色为主,线条干净。”,后来又说“喜欢中式红木家具,古色古香的那种”。AI 此时会非常矛盾,这两条信息在同一上下文里互相冲突,模型不知道该听谁的,结果很可能生成一个四不像的设计。
长度太短不行
太长不行,那就做减法呗。但做加法容易,做减法难啊~
例如开发一个自动回复邮件的agent,有人发邮件问:“明天有空快速聊一下吗?”
- • 一个过度减法的agent:只有用户请求,没有额外上下文。于是机械式回复:“明天可以。请问几点?”
- • 一个优秀的agent:有丰富上下文,能访问日历(显示你已排满)、能访问过往邮件(决定语气要随意)、能访问通讯录(确认对方是重要合作伙伴)、有发邮件的工具(可直接发邀请)。于是它能生成更自然的回复:“嘿 Jim!我明天排满了,周四早上有空,已经发了邀请,看看是否合适?”。
太长不行,太短有不行,因为我们需要有一个系统的方法去设计我们Agent的context设计。
三、Context Eningeering实战:体系/哲学/理念
接下来,我会用一些自己的case、工业界的经验教训来说明这个问题。
Lance Martin (LangChain、LangGraph的一位很核心很核心的开发者) 在6月23日的博客里《Context Enigneering for Agents[3]》里,他把 Context Engineering 分为四个模块:Write Context、Select Context、Compress Context、Isolate Context。
当然,这只是其中一种划分方式。比如近期那篇热门论文《A Survey of Context Engineering for Large Language Models[4]》就提出了另一种分类体系。
10月21日(周二)晚8点,青稞Talk 第80期,清华大学博士生张开颜,将对该篇论文进行直播分享,主题为《RL for LRMs:探讨面向推理模型的 RL 最新研究》。
本质上,不同的分类只是不同作者做的一种抽象,大家看到有不同的分类体系时,不要太焦虑也不要太纠结。 我选择引用Lance Martin的分类,只是因为它提出得更早,更简洁。
回到context engineering在设计什么。设想你在设计一个Agent系统,下图每个绿色方框代表一个sub-Agent执行独立任务。当红色框的sub-Agent需要处理任务时我们要考虑
1.如何将其它sub-Agent 获取的信息有效地加入当前sub-Agent的上下文中。
2.如何根据当前sub-Agent要处理的任务,把适的外部的知识库/记忆/工具用合理的格式放到当前sub-Agent中。
3.如果当前sub-Agent上下文过长,还需合理选择或压缩这些信息。
4.如何把当前 Agent 对其它子任务有帮助的信息保存下来,以便其它子 Agent 能利用这些信息更好地完成它们的任务。
5…
(这句话已经出现第三次了哦)
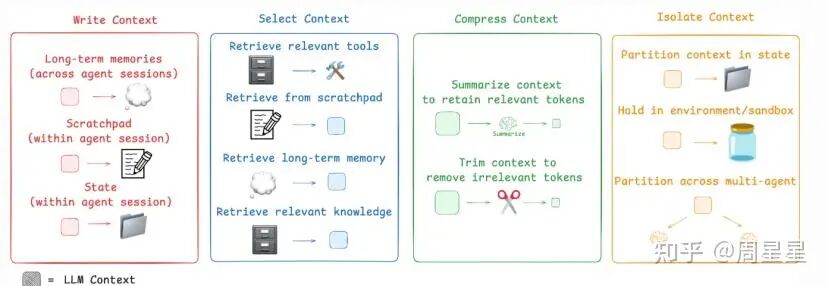
Write Context
写作上下文指的是把当前上下文保存到上下文窗口之外,以帮助其它agent更好地执行任务。
这里提到了Long-term memories、Scratchpad、State三种模式,这里介绍下
Long-term memories
这里用Openai的例子来说明。OpenAI 在 2024 年推出了memory 功能[5],能够基于用户的聊天记录回答问题。这点很有意思,我日常常把 GPT 当作一个零散的知识库,随时记录和讨论一些琐碎的问题。有时候,我会直接让它帮我做一些过去一段时间零散思维的提炼归纳,比如问:“上周我都问过你什么?” 这正是 长期记忆(Long-term memory) 的价值。

虽然这里展示的是 ChatBotAI 的应用形式,但在 Agent 中同样适用。涉及的技术点,怎么把当前的上下文保存成记忆,让其它对话能用上这个记忆了,这背后涉及大量研究。就像开头提到的,如果把 Context Engineering 当成一门课程,光是 memory 就足以讲三周
Scratchpads
Long-term memory 是跨会话使用的,而 Scratchpads 和 State 则是作用于单一 Agent 会话中的。Scratchpads这个词我真的很喜欢,因为它很直观到位,这个词在agent时代常常提到,翻译成中文叫做“草稿本”。
Manus在7月份的博客里就提到。
《AI代理的上下文工程:构建Manus的经验教训》https://manus.im/zh-cn/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
系统一开始会写一个计划(并把这个计划写下来成todo.md),在后续执行过程中不断重写调整。这与人类处理复杂任务的方式类似:人们先将计划写在草稿纸上,在执行任务时再进行修改。这个 todo.md 不一定固定在messages中,而是根据需求导入,可以通过 RAG 检索本地文件,也可以预定义工具(如 Retrieve_plan)读取 todo.md 文件。

State
假如用API调过LLM的同学们都知道,传入的是 messages,这是我们与 LLM 对话的主线。
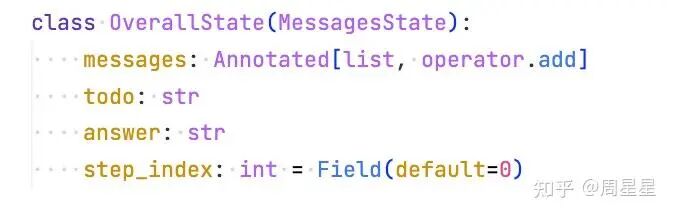
State是在 LangGraph 框架里的一种抽象,State(状态)的理念是:我们完全可以把Agent运行过程中一些有价值的中间变量写下来保存为贯穿整个 Agent 内部工作流的一些变量。
例如,我们可以定义一个名为 todo的 State 变量,在整个 Agent 系统中流转,按需更新或在某些sub-Agent中纳入其到当前messages中使用。这些变量,与主线对话消息message是独立的。其他框架,如 LlamaIndex 和 Smolagents,也可以实现类似的机制,只是名称可能不同(例如不叫 State)。
Select Context
选择上下文意味着在某些时刻,召回内外部的信息拉入当前LLM的上下文窗口中,以帮助当前的agent更好执行当前的任务。
Retrieve relevant tools
大家做过tools调用的时候,可能就对以下的经历感同身受了。在工具调用中,当工具数量不多且功能明确时,模型的调用效果较好。但一旦工具增多,问题便会放大。尤其是随着MCP的涌现,很多工具的参数和描述不够严谨,容易导致混乱。例如,多个工具都使用“date”作为变量名,但期望的格式不同:tool1期望“2025年9月19日”,tool2期望“20250919”。这种情况容易造成上下文混乱(Context Confusion)。
解决方法相对直观:
- • 使用RAG召回与当前消息相关的前10个工具。
- • 也可以像 Manus 提到的,建立统一命名体系,例如浏览器相关工具以browser_开头,命令行工具以shell_开头。这样模型可以在正确的工具组中选择,而不依赖复杂的logits控制。

Retrieve from scratchpad / long-term memory
scratchpad和memory都是write context中保存的有价值的内部内容。其实这就联系上了,把其它agent有用的信息保存下来,召回给到当前agent用。
比如,当用户要求“推荐菜单”时,如果在记忆中发现用户是“素食主义者”,就应该召回这一信息。
Retrieve relevant knowledge
大家最常见的Rag,Rag都说烂了。
例如,现在用搜索API根据query召回合适的内容做grounding
可以使用以下因素进行筛选: 频率因子(用不同query搜索,URL多次出现得分更高)、域名因子(频繁出现的host name加权更高)、路径因子(常见路径得分更高)、语义重排序因子(embedding粗排精排那套)。黑名单/白名单要做好大概率要有,还能开发很多小模型例如(水文模型)过滤。
Compress Context
压缩上下文涉及当上下文过长时,仅保留执行当前任务所需的标记。
跟之前说的,虽然现在很多大模型号称能处理一百万token,单当任务一复杂,可能100K token效果就爆炸了。
Summarize context
这里以Claude Code举例,上下文窗口满了/接近满时,Claude Code 会 自动压缩(summarize / “compact” 对话历史),以释放空间。 官方提到:当上下文用量达到 95% 时,会自动触发压缩功能。
Trim context remove irrelevant tokens
最简单的裁剪方法是 直接截掉对话轮数,例如已有 10 轮消息,就丢弃一部分。更精细的方式如 Provence(Pruning and Reranking Of retrieVEd relevaNt ContExts),会在原文中去除语气词和无关词,只保留与任务相关的核心内容,这同样是一种 trim,如下。

Isolate Context
隔离上下文涉及将其拆分,以帮助当前agent更好执行任务。
Partition context in state
跟之前的write context的state对应。除了主线的 messages,我们还能保存一系列 状态变量,供不同的 subagent 使用,而不要一股脑把什么东西都塞到与大模型直接交互的message里。
Hold in environment/sanbox
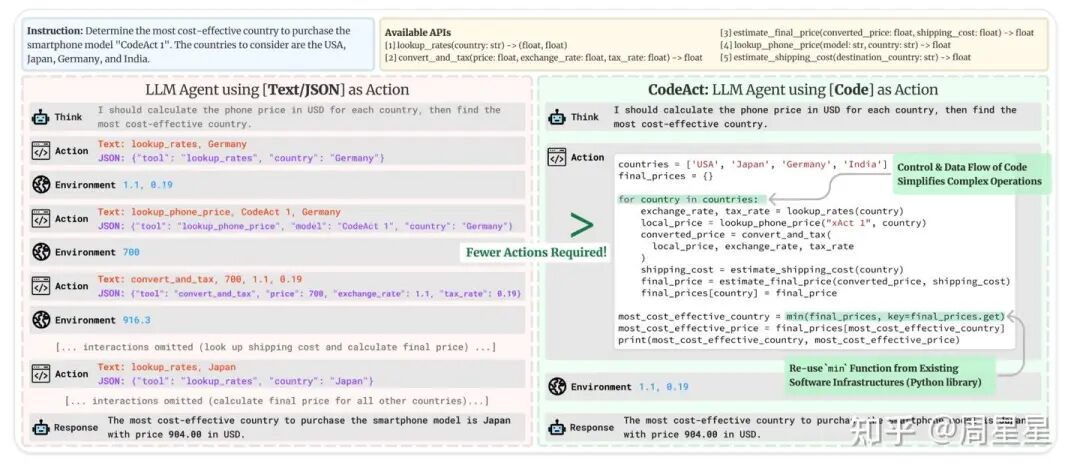
在这里提到Huggingface的Smolagents这个框架。每个框架都有其设计的哲学,这个框架的核心理念是Code Agent优先,如下图官网所示。

Smolagents把Code agent 作为默认形式,直接生成 Python 调用来完成动作。这样操作既高效又简洁,往往一段代码就能搞定,否则在传统 Agent 流程里可能需要反复多轮调用工具。 下图是官网的例子,比如要计算各国手机换算成美元的价格找到最便宜的,用传统的agent可能需要很多很多次调用(下图左边),用 CodeAct 能在一个 sandbox 中一次完成(下图右边),而不是像普通 agent 一样走很多轮。虽然官网没提到isolate,但其实这个例子处处体现着Isolate的思想:把任务隔离在一个沙箱里,用完就丢,避免冗长、容易失败的链式调用。秒啊~ !
Partition across multi-agent
Multi-agent天然就要开发者考虑isolate的问题。
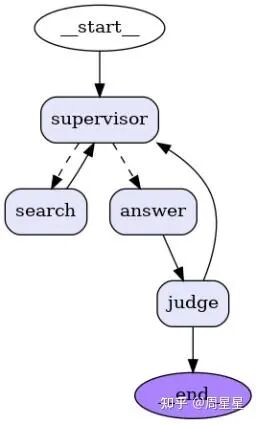
例如我这里设计一个检索每天新闻大事的agent,由一个管理者supervisor控制怎么流转,里面有搜索agent,回答agent,回答agent后一定要经过一个做评估的judge agent。假如不通过eval,就回到supervisor中,要是通过,就结束。当我们流转到judge时,这时候,你还要输入前面所有的搜索信息吗? 当然是不需要的,这只会干扰它当前完成eval这个任务的效果,你只需要输入当前模型的回答,以及你的评估标准。就是Parition across multi-agent。
细节来了,judge后的输出怎么write context,给到supervisor作为有效信息呢?十分灵活,可以是
- • 方法一:全部放到system prompt里。这样supervisor就变成全是单轮对话了。

- • 方法二:放到messages里进行管理

- • 方法三:写出到外部文件,后续按需rag。

怎么选择:选择的标准很多,
- • 用测试集效果来决定,哪种方法在测试集效果好就用哪种。
- • 从训练的角度来考虑,假如方法一能拿到75分,方法二能拿到70分,但从训练来说,方法二的格式更好训,那选方法二未尝不可。
- • Manus的围绕KV缓存进行设计[6]。这是Manus博客的第一个教训,可以理解Manus的出发点,假如我是投资人,第一轮投资了manus,后续是否跟进投资,我一定会看它的单次输出成本是否下降,因此manus内部应该会有很多工程师围绕着KV cache来改进他们的架构。PS:假如围绕KV cache来设计,他们就肯定不会选择方法一,是吧。

四、番外篇:Single Agent & Multi-Agent 之争
这里留个番外篇,我对Single Agent和Multi Agent的思考,因为这跟context engineering密切相关。这里围绕一些资料讨论
Anthropic《How we built our multi-agent research system》https://www.anthropic.com/engineering/multi-agent-research-system
6月13日的博客
- • 它们认为multi-agent更适合广度优先任务。
我们的内部评估显示,多智能体研究系统在处理需要同时探索多个独立方向的广度优先型查询时表现尤为出色。我们发现,当以 Claude Opus 4 作为主导代理,并配合 Claude Sonnet 4 作为子代理时,该多智能体系统的表现比单一的 Claude Opus 4 提升了 90.2%。
Our internal evaluations show that multi-agent research systems excel especially for breadth-first queries that involve pursuing multiple independent directions simultaneously. We found that a multi-agent system with Claude Opus 4 as the lead agent and Claude Sonnet 4 subagents outperformed single-agent Claude Opus 4 by 90.2% on our internal research eval.
- • Multi-agent效果好,主要原因是能消耗更多的token(scaling law还是那个真理啊!)
多智能体系统之所以有效,主要原因在于它们能够花费足够的 tokens 来解决问题。我们的分析显示,在 BrowseComp 评测(用于测试浏览型智能体寻找难以获取信息的能力)中,有三个因素可以解释 95% 的性能差异。其中,token 使用量单独就能解释 80% 的差异,另外两个解释因素分别是 工具调用次数 和 模型选择。
Multi-agent systems work mainly because they help spend enough tokens to solve the problem. In our analysis, three factors explained 95% of the performance variance in the BrowseComp evaluation (which tests the ability of browsing agents to locate hard-to-find information). We found that token usage by itself explains 80% of the variance, with the number of tool calls and the model choice as the two other explanatory factors.
但我觉得,这句话感觉写得有点不清晰,我自己的理解是,multi-agent 的优势不在于能“花掉更多 token”,而在于能把 token 更合理地分配和消耗,从而避免长上下文的性能损耗,从而更有效地消耗token。
举个例子,在单一 Agent 架构下,即使你给它 20 万 token 的预算,也常常因为上下文过长而导致效果下降。相比之下,多 Agent 架构能够把总预算拆分:比如主 Agent 分配 10 万 token,每个子 Agent 各自分配 2 万 token。这样每个子任务都在相对合适的上下文长度中完成,整体能更有效地利用 token 资源。
Cognition《Don't Build Multi-Agents》https://cognition.ai/blog/dont-build-multi-agents
Cognition(Devin的母公司),6月12日在anthropic的前一天写了一篇标题看起来激进的博客,标题是 《Don’t Build Multi-Agents》,博客里举了一些例子说明
例子一:假如任务是“做一个 Flappy Bird ”游戏,主智能体把它拆成两个子任务:一个负责构建带绿色管道的背景,另一个负责实现会上下移动的小鸟。结果,子智能体1可能误解成在做马里奥风格的背景,子智能体2的小鸟外观和移动方式也不像 Fappy Bird,最后拼在一起完全不搭。即使你把完整任务上下文给了两个子智能体,由于它们看不到彼此的成果,背景和小鸟的风格也可能南辕北辙,最终导致整体失败。
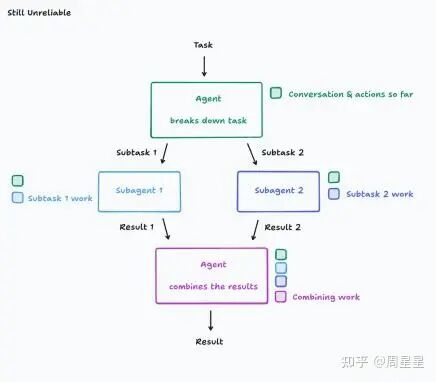
例子二:Claude Code 的子智能体: Claude Code 虽然使用子任务,但它不让Code智能体并行工作,并且子任务智能体通常只负责回答问题,而不编写代码。这是因为子任务智能体缺乏主智能体的完整上下文,如果它们并行运行并进行更复杂的操作(如编写代码),可能会产生冲突的响应,导致可靠性问题。可以类比成两个人同时改代码,大概率需要解决代码冲突才能正常合并。
我观察的技术趋势变化
一开始只有 single-agent,后来随着 R1 爆火等,multi-agent 被炒起来。但最近又出现"回归单个Agent”的声音"——比如 上面Cognition 的这篇文章、Kimi 提出的端到端 deep research[7],以及 OpenAI发布了Agent SDK后,8月份红杉资本采访谈到单个强大的agent才是未来[8],都强调单agent 是最终形态。
从端到端RL训练角度来说,确实单agent更直接到位,multi-agent的RL训练范式目前还没有统一的最佳实践。
很明显, 像Kimi、OpenAI这种搞基模的公司,内部愿景是相信scaling law,相信总有一天有一个超级无敌强的大模型一统天下,它们肯定就不愿意搞multi-agent这种偏工程向的东西了,直接一把梭端到端训练一个超级无敌模型做单agent就完事了。

Kimi明确提出multi-agent的局限性
我的预测
并不存在唯一最优解,技术还在演进。
举一个目前multi-agent的缺点:拿写文章打比方,如果所有同事在同一个文档里协作,整体风格和结构更统一;但若各自分开写,再拼接就容易出现格式混乱、观点矛盾。我们可以看到,大多数 deep research 系统在写作阶段只保留一个写作 agent,很少拆成多个写作 agent 并行。
但未来或许会不一样。如果像 Google 的 A2A 协议成熟,不同 agent 在各自执行任务时能实时共享状态,那么跨 agent 的割裂可能被缓解,这时候multi-agent的缺点就解决了。
但目前来看,正如 Anthropic 所说,subagent 更适合处理广度优先的任务。
从 RL 角度来看,单Agent训练更直接,直接端到端完事了,且对 context engineering 的依赖较少(当前的 context engineering 过于依赖人工设计,这不符合 scaling law 的理念,其实不一定是好事,可能只是Agent发展中的一个中间产物)。
因此,我认为最理想的模式是向单Agent发展,同时保留一些简洁的 sub-agent,专门用于广度优先任务。举例,
- • Single-Agent,一个超级无敌模型,一个人能调用50个tools。
- • multi-Agent,10个sub-agent,每个能调用5个tools。
- • 最终我的预期是,1个超级无敌模型,一个人能调用45个tools,两个sub-agent分别能调用2-3个tools,而且这两个sub-agent是完成广度优先任务的。
五、结尾
回到我们最开始的话题,我们说context engineering是一门系统的学科,设计一个agent时,如下问题都是context engineering的需要考虑的问题。
1.如何将其它sub-Agent 获取的信息有效地加入当前sub-Agent的上下文中。
2.如何根据当前sub-Agent要处理的任务,把合适的外部的知识库/记忆/工具用合理的格式放到当前sub-Agent中。
3.如果当前sub-Agent上下文过长,还需合理选择或压缩这些信息。
4.如何把当前 Agent 对其它子任务有帮助的信息保存下来,以便其它子 Agent 能利用这些信息更好地完成它们的任务。
5…
并用一个分类体系+例子来加深大家对这些概念的理解。完结~
六、如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献725条内容
已为社区贡献725条内容

所有评论(0)