DataLab: A Unified Platform for LLM-Powered Business Intelligence 论文解读
DataLab通过系统化的模块设计与实验验证,展示了LLM在统一BI平台中的潜力。其核心价值在于。
DataLab组成:LLM代理框架+计算笔记本界面
包含三个关键模块:领域知识整合模块+代理间通信模块+基于单元的上下文管理模块
1. 研究背景与动机
现代企业的商业智能(BI)工作流涉及数据收集、存储、准备、分析和可视化等多个阶段,需多角色协作(如数据工程师、科学家、分析师)。然而,现有工具(如Power BI、Tableau)和基于LLM的代理通常聚焦单一任务(如NL2SQL、NL2VIS),导致流程碎片化、信息共享低效和迭代成本高昂。论文提出DataLab,旨在通过统一的LLM代理框架和增强的计算笔记本界面,整合多任务与多角色协作,解决以下核心挑战:
-
C1:缺乏领域知识整合,导致LLM对业务数据的理解不足。
-
C2:代理间信息共享不足,阻碍跨任务协作。
-
C3:LLM上下文管理低效,影响系统性能和成本。
2. 核心架构与模块设计
(1)领域知识整合模块
-
目标:通过自动化生成企业特定的知识(元数据、业务逻辑、行业术语),提升LLM对业务数据的理解。
-
实现:
-
知识生成:利用历史脚本(SQL/Python)和数据谱系信息,通过Map-Reduce流程和自校准机制生成知识组件(如描述、用途、标签)。
-
知识组织:构建树状知识图谱(节点类型:数据库、表、列、值、术语),支持基于Elasticsearch和StarRocks的混合检索(词法与语义匹配)。
-
知识利用:通过查询重写、知识检索和DSL转换(如JSON结构),将自然语言查询转化为结构化领域语言(DSL),供下游任务(如NL2SQL)使用。
-
-
创新点:自校准机制减少LLM幻觉,动态索引提升检索效率,数据剖析模块应对知识稀疏场景。
(2)代理间通信模块
-
目标:通过结构化信息流和有限状态机(FSM),实现多代理高效协作。
-
实现:
-
信息格式:设计六元组信息单元(数据源、角色、动作、描述、内容、时间戳),覆盖SQL、代码、图表等多样化输出。
-
共享缓冲区:异步存储代理输出,支持动态扩容与过期清理。
-
选择性检索:基于FSM控制信息流向,代理仅在特定状态(等待、执行、完成)接收相关上下文,避免信息过载。
-
-
创新点:结构化信息单元增强语义一致性,FSM优化通信流程,降低冗余计算。
(3)基于单元的上下文管理模块
-
目标:动态管理笔记本中多语言单元(SQL、Python、图表)的依赖关系,高效提取相关上下文。
-
实现:
-
DAG构建:通过变量追踪(Python AST、SQL输出)构建单元依赖图,支持实时更新。
-
上下文检索:基于任务类型(如NL2DSCode仅需Python单元)剪枝依赖图,结合嵌入相似度筛选Markdown内容。
-
-
创新点:DAG实现最小上下文集合,降低LLM的Token成本(实验显示节省61.65%)。
3. 实验与评估
论文在公共基准(Spider、DS-1000、VisEval等)和腾讯真实数据集上验证了DataLab的性能:
(1)端到端性能
-
任务覆盖:NL2SQL、NL2DSCode、NL2VIS、NL2Insight等。
-
结果:DataLab在多个任务上超越SOTA基线(如BIRD准确率提升58.58%),尤其在复杂任务(如NL2Insight)中因结构化通信机制表现突出。
(2)模块有效性
-
领域知识整合:Schema Linking的Recall@5提升38.47%,NL2DSL准确率提升58.58%,验证知识生成与检索的有效性。
-
代理间通信:引入FSM后,复杂任务成功率提升19%,准确率提升28%。
-
上下文管理:DAG剪枝减少61.65%的Token成本,仅牺牲4.67%的准确率。
(3)鲁棒性分析
-
LLM敏感性:闭源模型(GPT-4)表现最佳,开源模型(Qwen-2.5、LLaMA-3)在代码生成任务中性能下降,但DataLab通过数据剖析和通信机制仍保持稳定。
4. 创新与贡献
-
统一平台设计:首个整合多任务、多角色BI工作流的LLM代理框架,支持SQL/Python/Markdown/图表单元的协作。
-
领域知识自动化:通过脚本分析和知识图谱,解决企业数据语义模糊问题。
-
结构化通信协议:FSM与信息单元设计,优化多代理协作效率。
-
动态上下文管理:DAG依赖追踪与剪枝策略,平衡性能与成本。
5. 局限与改进方向
-
依赖历史脚本:若企业缺乏脚本或数据谱系信息,知识生成可能受限。改进方向:结合弱监督学习或外部知识库。
-
FSM复杂度:复杂任务可能导致状态爆炸。改进方向:引入分层FSM或强化学习优化状态转移。
-
上下文检索偏差:依赖嵌入相似度可能遗漏关键Markdown内容。改进方向:结合语法分析与语义检索。
6. 总结
DataLab通过系统化的模块设计与实验验证,展示了LLM在统一BI平台中的潜力。其核心价值在于降低跨角色协作成本、提升复杂任务自动化水平,并为企业级BI应用提供了可扩展的解决方案。未来工作可进一步探索稀疏数据适应、通信协议优化及更智能的上下文管理策略。
【论文大框】
DataLab: A Unified Platform for LLM-Powered Business Intelligence
引言
介绍BI
BI挑战(缺乏领域知识整合,任务间信息共享不足,对适应性LLM上下文管理的需求)
针对挑战做出的改进/解决方案(领域知识整合模块,agent间通信模块,基于单元的上下文管理模块)
总结贡献
相关知识
BI工作流
(工作流包括数据收集、存储、准备、分析和可视化;数据角色包括数据工程师、科学家和分析师)
基于llm的BI代理
(介绍 + 列出了基于llm的代理在每个BI阶段可以简化的一些典型任务:
•数据收集:表生成,表增强,表汇总
•数据存储:数据仓库,数据集成,数据编排
•数据准备:NL2SQL , NL2DSCode
•数据分析:NL2Insight,表Q&A
•数据可视化:NL2VIS,图表问答)
概述
体系结构概述
(两个主要组件:基于llm的Agent Framework和Computational Notebook Interface)
领域知识整合
知识的生成(检索增强生成)
知识组织(知识图)
知识利用(Q重写→知识检索(粗/精检)→转换成DSL)
代理间通信
信息格式结构(信息单元包括数据源、角色、动作、描述、内容和时间戳6个字段)
信息共享协议(共享信息缓冲区,给予FSM的选择性检索)
基于单元的上下文管理
(将笔记本中的单元依赖关系建模变为基于变量引用的DAG(结构):确定新的变量+查找引用的单元格)
实验
端到端性能比较
(使用两个基准(Spider和BIRD),并与两个基线(daily - sql和DIN-SQL)进行比较(评估指标:EX指标))(效果得益于领域知识整合模块生成的中间DSL规范)
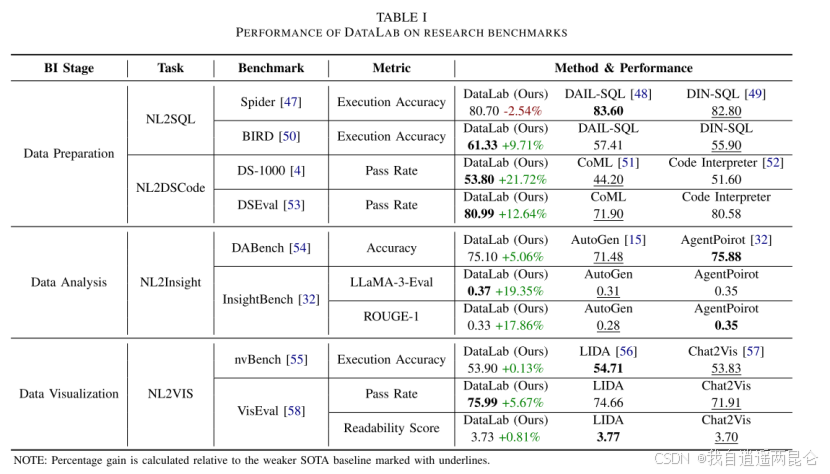
敏感性分析
(使用GPT-4, Qwen-2.5, LLaMA-3.1)
领域知识整合评估(消融实验)
S1(无知识);S2 (partial knowledge);S3 (all knowledge)

代理间通信评估(消融实验)
S1 (无FSM):取消基于FSM的信息共享协议
S2(无信息格式):该设置去除信息格式结构,采用纯自然语言进行agent间通信。
S3 :都有

基于单元的上下文管理评估(消融实验)
(消融研究:S1(无DAG)和S2(无DAG))(评估指标:响应时间)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)