yolov13学习笔记
yolov13学习笔记
文章目录
介绍
YOLO模型以其高效的实时检测能力和出色的准确性赢得了众多研究者和开发者的青睐,特别是目标检测。
YOLOv13 系列包括四种变体:Nano、Small、Large 和 X-Large。
安装依赖
# 下载
git clone https://github.com/iMoonLab/yolov13.git
cd yolov13
# 创建虚拟环境(Python 3.11)
conda create -n yolov13_env python=3.11
conda activate yolov13_env
# 安装 PyTorch(以 CUDA 11.8 为例),没有就直接安装就可以了
pip install torch==2.2.0+cu118 torchvision==0.17.0+cu118 torchaudio==2.2.0 --extra-index-url https://download.pytorch.org/whl/cu118
# 下载 FlashAttention(以 Linux + CUDA 11.8 为例)
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu118torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
# 安装 FlashAttention
pip install flash_attn-2.7.3+cu118torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
# 使用国内镜像加速安装(推荐)
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
训练预测导入
# 注意提前把依赖下好pip install -r requirements.txt
# 训练
from ultralytics import YOLO
model = YOLO('yolov13n.yaml')
model.load('yolov13n.pt') # 权重,和上面对应
# 训练模型
results = model.train(
data='coco.yaml', # 数据集配置文件的路径
"""
train: f:/VOCdevkit/train/images # train images (relative to 'path') 128 images
val: f:/VOCdevkit/val/images # val images (relative to 'path') 128 images
test: f:/VOCdevkit/test/images
nc: 2 # Classes个数
# Classes
names: ['hat','nohat']
"""
epochs=600, # 训练轮次总数
batch=256, # 批量大小,即单次输入多少图片训练
imgsz=640, # 训练图像尺寸
workers=8, # 加载数据的工作线程数
optimizer='SGD', #训练使用优化器,可选 auto,SGD,Adam,AdamW 等
scale=0.5, # S:0.9; L:0.9; X:0.9
mosaic=1.0,
mixup=0.0, # S:0.05; L:0.15; X:0.2
copy_paste=0.1, # S:0.15; L:0.5; X:0.6
device="0,1,2,3", # 指定训练的计算设备
amp= True, #True 或者 False, 解释为:自动混合精度(AMP) 训练
cache=False # True 在内存中缓存数据集图像,服务器推荐开启
)
# 评估验证集上的模型性能
metrics = model.val('coco.yaml')
# 对图像执行对象检测
results = model("test1.jpg")
results[0].show()
# 预测
from ultralytics import YOLO
# 加载预训练模型
model = YOLO('yolov13x.pt')
# 执行目标检测
results = model.predict(
source='test1.jpg',
conf=0.30, # 降低置信度阈值提高小目标检出率
imgsz=1536, # 增大输入分辨率
iou=0.2, # 调整IOU阈值
augment=True, # 测试时增强
save=True,
show=True,
line_width=1, # 细线框
save_conf=True # 保存置信度
)
# 导出
from ultralytics import YOLO
model = YOLO('yolov13{n/s/l/x}.pt') # 替换为所需的模型比例
model.export(format="engine", half=True) # 或格式format="onnx"
yaml和pt
- .yaml是 YOLO 模型的配置文件,定义了模型的结构(如层数、参数、输入输出等)。
- 一个已经训练好的 YOLO 模型(
yolov13n.pt是预训练权重文件)。
方式 从头创建(YAML) 加载预训练模型(PT) 模型初始化 完全随机初始化权重 使用预训练权重初始化 训练需求 需要从头训练(耗时长) 可直接推理或微调(训练更快、效果更好) 适用场景 自定义模型结构、研究新架构 快速部署、微调已有模型 文件类型 .yaml(配置文件).pt(权重文件)
ultralytics
Ultralytics YOLO 是一个开源的计算机视觉库,专注于实时目标检测、实例分割、姿态估计和分类任务。它是 YOLO (You Only Look Once) 算法的现代化实现,提供简单易用的接口和卓越的性能。
# 最简单的方法
pip install ultralytics
# 从 GitHub 安装最新版本
pip install git+https://github.com/ultralytics/ultralytics.git@main
# Conda 安装
conda install -c conda-forge ultralytics
from ultralytics import YOLO
# 加载预训练模型
model = YOLO("yolov13n.pt")
# 训练
results = model.train(
data="coco8.yaml",
epochs=100,
imgsz=640,
device="cpu"
)
# 推理
results = model("image.jpg")
results[0].show()
# 导出
path = model.export(format="onnx")
model模型方法
- model.train:训练,用于在自定义数据集上训练YOLO模型。例如data、epochs、imgsz、device、batch等。
- model.val:验证,在验证集上评估模型性能。
- model.predict:推理,在新图像或视频上进行预测。
- model.track:多目标跟踪,在视频流中实时跟踪检测到的对象。默认是BoT-SORT算法(基于Transformer的跟踪),ByteTrack高效的目标跟踪算法。
- model.export:导出,将模型导出为不同格式用于部署。
- model.benchmark:性能基准测,比较不同导出格式的性能 。
- model.predict:支持多种数据源和输出格式。
from ultralytics import YOLO
import cv2
model = YOLO("yolov13n.pt")
# 使用流模式处理视频
results = model.predict("test.mp4", stream=True)
for result in results: # 🔥 逐个处理每个帧的结果
annotated_frame = result.plot() # ✅ 正确:在单个 Results 对象上调用 plot()
# 显示带标注的帧
cv2.imshow("YOLO Detection", annotated_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# from ultralytics import YOLO
# import cv2
# # 1. 加载模型
# model = YOLO("yolov13n.pt")
# # 2. 训练模型
# results = model.train(data="coco8.yaml", epochs=100)
# # 3. 验证模型性能
# results = model.val()
# # 4. 实时检测与跟踪
# cap = cv2.VideoCapture(0)
# while True:
# ret, frame = cap.read()
# if not ret:
# break
# # 5. 单帧预测
# results = model.predict(frame)
# # 6. 跟踪预测
# results = model.track(frame, persist=True, tracker="bytetrack.yaml")
# # 7. 可视化结果
# annotated_frame = results.plot()
# cv2.imshow("YOLO Detection", annotated_frame)
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
# cap.release()
# cv2.destroyAllWindows()
# # 8. 导出模型用于部署
# model.export(format="onnx")
yolo返回结果results
- boxes对象:存储检测到的边界框信息
.xyxy: 形状为(N, 4)的张量,表示每个边界框的[x1, y1, x2, y2]坐标(左上角到右下角).conf: 形状为(N,)的张量,表示每个边界框的置信度.cls: 形状为(N,)的张量,表示每个边界框的类别索引(0~类别总数-1).id: 如果启用了track=True(目标跟踪),返回目标 ID- masks对象::存储实例分割的掩码(仅在分割任务中存在)
- Keypoints 对象:存储关键点检测结果(仅在姿态估计任务中存在)
- probs对象:存储分类任务的类别概率(仅在分类任务中存在)
- orig_shape:tupl类型,输入图像的原始尺寸
(height, width)- path:str类型,输入图像的路径(如果是从文件或目录加载的)输入图像的路径(如果是从文件或目录加载的)
from ultralytics import YOLO
import cv2
model = YOLO("yolov13n.pt")
image_path = 'ultralytics/assets/zidane.jpg'
results = model.predict(
source=image_path, # 图片路径
conf=0.30, # 置信度阈值
imgsz=1536, # 图片尺寸
iou=0.2, # IOU阈值:检测时,两个框的IOU小于阈值则认为两个框是同一个目标
augment=True, # 测试时增强
# save=True, # 保存图片
show=True, # 显示图片
line_width=1, # 线框宽度
save_conf=True # 保存置信度
)
cv2.waitKey(0)
for result in results:
boxes = result.boxes # 获取边界框对象
coords = boxes.xyxy.cpu().numpy() # 转换为 numpy 数组
confidences = boxes.conf.cpu().numpy()
class_ids = boxes.cls.cpu().numpy()
for i in range(len(coords)):
x1, y1, x2, y2 = coords[i]
print(f"检测到类别 {int(class_ids[i])},置信度 {confidences[i]:.2f},坐标: 左上右下角({int(x1)}, {int(y1)})-({int(x2)}, {int(y2)})")
REST API 服务器
在examples\YOLOv13-FastAPI-REST-API\yolov13_fastapi_api.py,使用 YOLOv13 AI 模型检测图像中的对象。上传图像,获取带有边界框和置信度分数的检测结果。
主要优点:
- 实时检测(使用 YOLOv13n 时为 ~6.9 FPS)
- 多个 YOLO 模型支持(YOLOv13、YOLOv8)
- 简单的 REST API 接口
- 具有错误处理功能的生产就绪型
服务器运行位置:http://localhost:8000
API 文档:http://localhost:8000/docs可用型号
- YOLOv13: yolov13n, yolov13s, yolov13m, yolov13l, yolov13x
- YOLOv8: yolov8n, yolov8s, yolov8m, yolov8l, yolov8x
实时推荐:yolov13n(最快)
数据集制作
在目标检测领域,COCO数据集堪称YOLO系列模型的「黄金搭档」。每当开发者验证新发布的YOLO版本性能时,总会优先选择其80类目标作为核心测试基准。
数据集是必不可少的部分,数据集的优劣直接影响训练效果。一般来说,一个完整的数据集应该包括训练集、测试集和验证集。
模型的建立需要收集图片并且进行标注。YOLOv8标注的文件格式如下:
其中,每一行通常包含五个数字,分别是类别标签和四个坐标值。这四个坐标值的含义如下:
类别标签(Class Label):第一个数字表示目标对象的类别。例如,如果数据集中有多个类别,每个类别会被分配一个唯一的整数标签。
中心点的x坐标(Center x):第二个数字表示目标框中心点的x坐标,该坐标是相对于图像宽度的比例值,范围在0到1之间。
中心点的y坐标(Center y):第三个数字表示目标框中心点的y坐标,该坐标是相对于图像高度的比例值,范围在0到1之间。
宽度(Width):第四个数字表示目标框的宽度,也是相对于图像宽度的比例值,范围在0到1之间。
高度(Height):第五个数字表示目标框的高度,是相对于图像高度的比例值,范围在0到1之间。

labelimg
labelimg是一款开源的图像标注工具,标签可用于分类和目标检测,它是用python写的,并使用Qt作为其图形界面,简单好用(虽然是英文版的)。其注释以 PASCAL VOC格式保存为XML文件,这是ImageNet使用的格式。此外,它还支持 COCO数据集格式。
安装pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple后直接输入运行labelimg [图片位置] [标签类型.txt]
常用快捷键如下:
- A:切换到上一张图片
- D:切换到下一张图片
- W:调出标注十字架
- del :删除标注框框
- Ctrl+u:选择标注的图片文件夹
- Ctrl+r:选择标注好的label标签存在的文件夹
注意一下格式哦,一般yolo格式

Opencv
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和机器学习库,包含超过2500种优化算法,涵盖图像处理、视频分析、物体检测、人脸识别、3D重建等核心领域。它支持C++、Python、Java等多种语言,可在Windows、Linux、macOS、Android等平台上运行。
OpenCV 在 YOLO 目标检测流程中扮演着预处理、后处理和可视化的核心角色。
# 1.图像预处理:YOLO输入要求:尺寸缩放、归一化、通道转换
import cv2
import numpy as np
# 读取图像
image = cv2.imread("test.jpg")
# 预处理步骤
def preprocess(image, target_size=(640, 640)):
# 调整尺寸 (保持长宽比)
h, w = image.shape[:2]
scale = min(target_size[0] / w, target_size[1] / h)
new_w, new_h = int(w * scale), int(h * scale)
# 缩放 + 填充 (letterbox)
resized = cv2.resize(image, (new_w, new_h))
canvas = np.full((target_size[1], target_size[0], 3), 114, dtype=np.uint8)
canvas[:new_h, :new_w] = resized
# 归一化 + 转置维度 (HWC -> CHW)
blob = cv2.dnn.blobFromImage(
canvas,
scalefactor=1/255.0,
size=target_size,
swapRB=True # BGR转RGB
)
return blob, (scale, new_w, new_h)
blob, params = preprocess(image)
# 2.后处理-非极大值抑制 (NMS):消除重叠检测框
def nms(boxes, scores, iou_threshold=0.5):
indices = cv2.dnn.NMSBoxes(
boxes,
scores,
score_threshold=0.25,
nms_threshold=iou_threshold
)
return np.array(indices).flatten()
# 示例用法
boxes = [[100, 100, 200, 200], [110, 110, 210, 210]]
scores = [0.9, 0.8]
keep = nms(boxes, scores)
filtered_boxes = [boxes[i] for i in keep]
# 3.结果可视化:绘制检测框和标签
def draw_detections(image, boxes, scores, class_ids, classes):
for box, score, class_id in zip(boxes, scores, class_ids):
x1, y1, x2, y2 = box.astype(int)
# 画框
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 标签文本
label = f"{classes[class_id]}: {score:.2f}"
(tw, th), _ = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.6, 2)
# 文本背景
cv2.rectangle(
image,
(x1, y1 - 20),
(x1 + tw, y1),
(0, 255, 0),
-1
)
# 文本
cv2.putText(
image, label,
(x1, y1 - 5),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 0), 2
)
return image
# 示例调用
classes = ["person", "car", "dog"]
output_img = draw_detections(image, filtered_boxes, scores, class_ids, classes)
cv2.imwrite("result.jpg", output_img)
# 4.视频流实时处理:YOLO 应用于摄像头/视频
cap = cv2.VideoCapture(0) # 摄像头
while True:
ret, frame = cap.read()
if not ret: break
# 预处理
blob, params = preprocess(frame)
# → 在此处将 blob 输入 YOLO 模型推理
# 后处理 + 绘制结果
processed_frame = draw_detections(frame, boxes, scores, class_ids, classes)
cv2.imshow("YOLO Detection", processed_frame)
if cv2.waitKey(1) == 27: # ESC退出
break
cap.release()
cv2.destroyAllWindows()
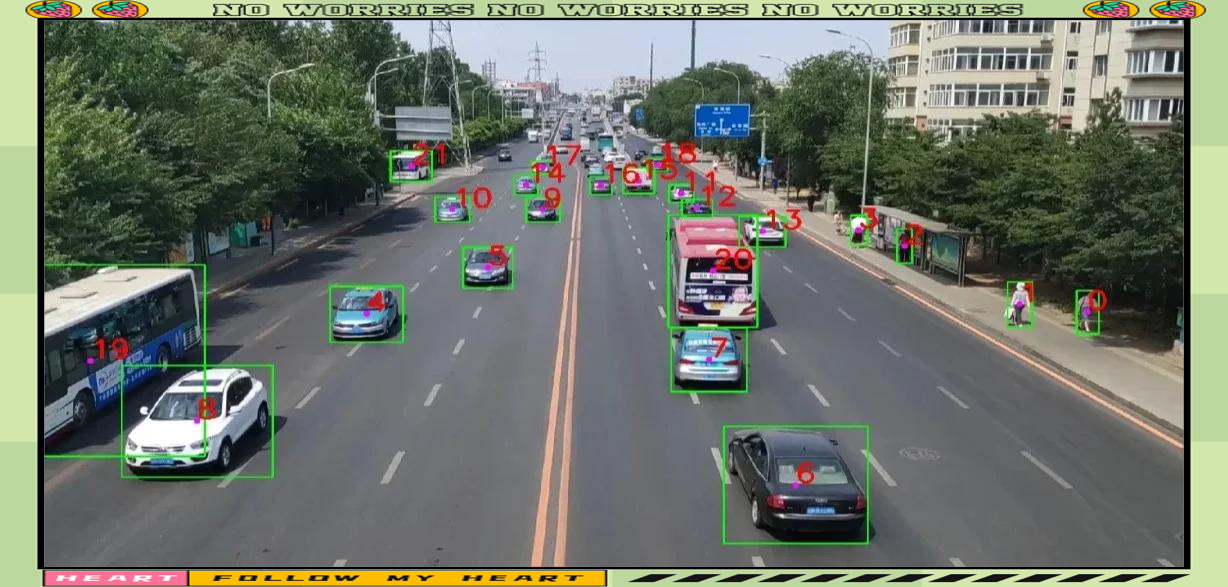
目标检测
目标检测(Object Detection)是计算机视觉领域的重要任务之一,旨在识别图像或视频中的特定目标并将其位置标记出来。
YOLO(You Only Look Once )是继RCNN,fast-RCNN和faster-RCNN之后,Ross Girshick针对DL目标检测速度问题提出的另一种框架,其核心思想是生成RoI+目标检测两阶段(two-stage)算法用一套网络的一阶段(one-stage)算法替代,直接在输出层回归bounding box的位置和所属类别。
- YOLO模型推理对象检测
- 对象分类
- 置信度筛选保留有效检测
- 边界框坐标计算(x1,y1,x2,y2)
- 并查集群组算法距离阈值分析(计算对象间距离、合并相近对象、生成群组边界框)
计数
from ultralytics import YOLO
from collections import defaultdict
# 加载预训练模型
model = YOLO('yolov13x.pt')
# 执行目标检测
results = model.predict(
source='test1.jpg',
conf=0.30,
imgsz=1536,
iou=0.2,
augment=True,
save=True,
show=True,
line_width=1,
save_conf=True
)
# 获取图片的结果
result = results[0]
# 初始化计数字典
class_counts = defaultdict(int)
# 遍历所有检测到的对象并计数
for box, conf, cls_id in zip(result.boxes.xyxy, result.boxes.conf, result.boxes.cls):
# 解析坐标信息
x1, y1, x2, y2 = map(int, box[:4])
# 获取类别信息
class_name = result.names[int(cls_id)]
confidence = float(conf)
# 更新类别计数
class_counts[class_name] += 1
# 打印坐标和检测信息
print(f"检测到 {class_name}: 置信度 {confidence:.2f}, 坐标: [{x1}, {y1}, {x2}, {y2}]")
# 输出总的检测数量
total_objects = sum(class_counts.values())
print(f"检测完成! 共发现 {len(class_counts)} 类物体,总计 {total_objects} 个对象")
print("各类别统计:")
for class_name, count in class_counts.items():
print(f" {class_name}: {count}")
群组
群组识别(如人群、车辆群组等),通常涉及目标检测后对结果进行聚类或分组分析。
import cv2
import numpy as np
from ultralytics import YOLO
from sklearn.cluster import DBSCAN
from collections import defaultdict
# 加载YOLOv13模型
model = YOLO("yolov13n.pt")
def detect_people(image) :
"""使用YOLOv13检测图像中的人"""
results = model(image, verbose=False) # 关闭详细输出
detections = []
# 解析检测结果 (新版YOLO格式)
for result in results :
boxes = result.boxes.cpu().numpy()
for box in boxes :
# 只处理'person'类 (class 0)
if box.cls == 0 :
x1, y1, x2, y2 = box.xyxy[0].astype(int)
conf = box.conf[0]
detections.append([x1, y1, x2, y2, conf])
return np.array(detections)
def get_centroids(bboxes) :
"""计算边界框的中心点"""
return np.array([[(x1 + x2) / 2, (y1 + y2) / 2] for x1, y1, x2, y2, _ in bboxes])
def cluster_groups(centroids, eps=150, min_samples=2) :
"""使用DBSCAN聚类算法分组"""
clustering = DBSCAN(eps=eps, min_samples=min_samples).fit(centroids)
return clustering.labels_
def draw_results(image, bboxes, group_labels) :
"""在图像上绘制检测结果和群组"""
group_colors = defaultdict(lambda : (
np.random.randint(0, 255),
np.random.randint(0, 255),
np.random.randint(0, 255)
))
# 绘制个体边界框
for bbox, label in zip(bboxes, group_labels) :
x1, y1, x2, y2, conf = bbox
color = group_colors[label]
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), color, 2)
if label != -1 : # 忽略噪点
cv2.putText(image, f'Group {label}', (int(x1), int(y1) - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, color, 2)
# 绘制群组边界框
for group_id in set(group_labels) :
if group_id == -1 : # 跳过未分组个体
continue
group_bboxes = [bboxes[i] for i, lbl in enumerate(group_labels) if lbl == group_id]
x_min = min(bbox[0] for bbox in group_bboxes)
y_min = min(bbox[1] for bbox in group_bboxes)
x_max = max(bbox[2] for bbox in group_bboxes)
y_max = max(bbox[3] for bbox in group_bboxes)
# 扩展群组边界框
padding = 15
cv2.rectangle(image,
(int(x_min - padding), int(y_min - padding)),
(int(x_max + padding), int(y_max + padding)),
group_colors[group_id], 3)
# 添加群组计数
cv2.putText(image, f'Group {group_id}: {len(group_bboxes)} people',
(int(x_min - padding), int(y_min - padding - 10)),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, group_colors[group_id], 2)
return image
def process_image(image_path, output_path='output.jpg') :
"""处理图像并保存结果"""
# 读取图像
image = cv2.imread(image_path)
# 检测人物
bboxes = detect_people(image)
if len(bboxes) == 0:
print("没有检测到人物")
cv2.imwrite(output_path, image)
return
print(f"检测到{len(bboxes)}人")
# 获取中心点并聚类
centroids = get_centroids(bboxes)
group_labels = cluster_groups(centroids)
# 计算分组统计
unique_labels = set(group_labels)
group_counts = {label : np.sum(group_labels == label) for label in unique_labels}
print(f"检测到的总人数: {len(bboxes)}")
print("组发布:")
for group_id, count in group_counts.items() :
if group_id != -1 :
print(f"第{group_id+1}组:{count}人")
if -1 in group_counts :
print(f"未分组的个人:{group_counts[-1]}")
# 绘制结果
result_image = draw_results(image.copy(), bboxes, group_labels)
# 保存结果
cv2.imwrite(output_path, result_image)
print(f"结果保存到:{output_path}")
# 显示结果
cv2.imshow('Group Detection', result_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 使用示例
if __name__ == "__main__" :
process_image(r'ultralytics/assets/bus.jpg')
轨迹
轨迹识别是计算机视觉和人工智能领域的重要研究方向,其核心目标是通过分析物体或生物体的运动轨迹,提取特征并实现分类、预测或行为分析。
import cv2
import numpy as np
from collections import deque
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator, colors
# 初始化模型
model = YOLO("yolov13n.pt")
# 创建字典存储轨迹点和类别
track_history = {} # 存储每个目标的轨迹点
track_class = {} # 存储每个目标的类别
# 视频路径
video_path = "test.mp4"
# 创建视频捕获对象
cap = cv2.VideoCapture(video_path)
# 获取视频原始尺寸
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
# 创建视频保存对象(可选)
output_path = "output_track.mp4"
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_path, fourcc, fps, (frame_width, frame_height))
# 创建视频显示窗口
cv2.namedWindow("Object Tracking", cv2.WINDOW_NORMAL)
cv2.resizeWindow("Object Tracking", frame_width, frame_height) # 设置窗口尺寸
# 设置轨迹点的最大数量(控制轨迹线的长度)
MAX_TRAIL_LENGTH = 30
while cap.isOpened() :
success, frame = cap.read()
if not success :
break
# 使用track方法进行目标跟踪
results = model.track(
frame,
persist=True, # 保持跟踪ID在帧间一致
tracker="bytetrack.yaml", # 使用ByteTrack跟踪算法
conf=0.4, # 置信度阈值
verbose=False # 关闭详细输出
)
# 获取检测结果
boxes = results[0].boxes.xyxy.cpu() if results[0].boxes is not None else []
track_ids = results[0].boxes.id.int().cpu().tolist() if results[0].boxes.id is not None else []
clss = results[0].boxes.cls.cpu().tolist() if results[0].boxes.cls is not None else []
# 可视化结果
annotator = Annotator(frame, line_width=2)
for i, box in enumerate(boxes) :
if i < len(track_ids) :
track_id = track_ids[i]
cls = int(clss[i]) if i < len(clss) else 0
# 获取类别名称
class_name = model.names[cls] if cls < len(model.names) else f"cls{cls}"
# 计算目标中心点
x1, y1, x2, y2 = map(int, box)
center_x = int((x1 + x2) / 2)
center_y = int((y1 + y2) / 2)
# 更新轨迹历史
if track_id not in track_history :
track_history[track_id] = deque(maxlen=MAX_TRAIL_LENGTH)
track_class[track_id] = class_name
track_history[track_id].append((center_x, center_y))
# 绘制轨迹线
if len(track_history[track_id]) > 1 :
points = np.array([(p[0], p[1]) for p in track_history[track_id]], dtype=np.int32)
points = points.reshape((-1, 1, 2))
cv2.polylines(
frame,
[points],
False,
(255, 255, 0), # 轨迹线颜色
2 # 线宽
)
# 创建包含类型和ID的标签
label = f"{class_name} ID:{track_id}"
# 获取颜色(根据track_id生成)
color = colors(track_id)
# 绘制边界框和标签
annotator.box_label(box, label, color=color)
# 显示带跟踪结果的帧
annotated_frame = annotator.result()
cv2.imshow("Object Tracking", annotated_frame)
out.write(annotated_frame) # 保存结果视频
# 按'q'退出
if cv2.waitKey(1) & 0xFF == ord("q") :
break
# 释放资源
cap.release()
out.release()
cv2.destroyAllWindows()
速度
YOLO速度识别主要通过目标检测 + 多目标跟踪 + 坐标变换来实现,核心原理是利用已知距离和时间计算速度。x
https://github.com/levan92/deep_sort_realtime/archive/refs/heads/master.zip下载DeepSort算法
进入目录pip install .导入python包
# 可以用yolo自己的SpeedEstimator,这里重新写了
import cv2
import numpy as np
from shapely.geometry import LineString
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator, colors
import time
class SpeedEstimator :
"""
物体速度估计类,基于物体在视频中的轨迹计算速度
参数:
names (list): 类别名称列表
region (list, optional): 速度测量区域的点列表 [(x1,y1), (x2,y2)],默认为None
line_width (int, optional): 绘图线宽,默认为2
pixels_per_meter (float, optional): 像素到米的转换比例,默认为100.0
min_speed_distance (int, optional): 速度计算的最小移动距离(像素),默认为10
"""
def __init__(self, names, region=None, line_width=2, pixels_per_meter=100.0, min_speed_distance=10) :
self.names = names
self.region = region
self.line_width = line_width
self.pixels_per_meter = pixels_per_meter
self.min_speed_distance = min_speed_distance
# 速度计算相关数据结构
self.spd = {} # 存储物体ID和对应速度
self.active_tracks = {} # 存储物体ID和上次时间戳及位置
self.tracks_history = {} # 存储物体轨迹历史
# 创建测量区域的LineString对象(如果有)
if region and len(region) >= 2 :
self.r_s = LineString(region)
else :
self.r_s = None
def estimate_speed(self, boxes, track_ids, clss, im0) :
"""
估计物体速度并绘制结果
参数:
boxes (np.ndarray): 检测框数组 [x1,y1,x2,y2]
track_ids (np.ndarray): 物体跟踪ID数组
clss (np.ndarray): 物体类别数组
im0 (np.ndarray): 原始图像
返回:
np.ndarray: 绘制了结果后的图像
"""
# 初始化注释器
self.annotator = Annotator(im0, line_width=self.line_width)
# 绘制速度测量区域(如果有)
if self.region :
self.annotator.draw_region(
reg_pts=self.region, color=(104, 0, 123), thickness=self.line_width * 2
)
# 处理每个检测到的物体
for box, track_id, cls in zip(boxes, track_ids, clss) :
# 计算物体中心点
center = ((box[0] + box[2]) / 2, (box[1] + box[3]) / 2)
# 初始化轨迹历史
if track_id not in self.tracks_history :
self.tracks_history[track_id] = []
self.active_tracks[track_id] = {
'last_time' : time.time(),
'last_pos' : center
}
# 更新轨迹历史
self.tracks_history[track_id].append(center)
if len(self.tracks_history[track_id]) > 30 :
self.tracks_history[track_id].pop(0)
# 获取当前物体的轨迹
track_line = self.tracks_history[track_id]
# 计算时间差和移动距离
current_time = time.time()
time_difference = current_time - self.active_tracks[track_id]['last_time']
dx = center[0] - self.active_tracks[track_id]['last_pos'][0]
dy = center[1] - self.active_tracks[track_id]['last_pos'][1]
distance_px = np.sqrt(dx ** 2 + dy ** 2)
# 只有在移动距离足够大时才计算速度
if distance_px > self.min_speed_distance and time_difference > 0 :
# 如果设置了测量区域,检查是否穿过该区域
calculate_speed = True
if self.r_s :
move_line = LineString([self.active_tracks[track_id]['last_pos'], center])
calculate_speed = move_line.intersects(self.r_s)
if calculate_speed :
# 转换距离为米
distance_m = distance_px / self.pixels_per_meter
# 计算速度(米/秒 -> 公里/小时)
speed_mps = distance_m / time_difference
speed_kmh = speed_mps * 3.6
# 存储速度
self.spd[track_id] = speed_kmh
# 更新物体的位置和时间
self.active_tracks[track_id]['last_time'] = current_time
self.active_tracks[track_id]['last_pos'] = center
# 准备标签(显示速度或类别)
if track_id in self.spd :
speed_label = f"{self.spd[track_id]:.1f} km/h"
color = (0, 0, 0)
else :
speed_label = f"{self.names[int(cls)]} (?)"
color = colors(track_id, True)
# 绘制边界框和标签
self.annotator.box_label(box, label=speed_label, color=color)
# 绘制物体轨迹
if len(track_line) > 1 :
self.annotator.draw_centroid_and_tracks(
track_line, color=colors(int(track_id), True), track_thickness=self.line_width
)
# 清理不活跃的轨迹
inactive_ids = [tid for tid in self.active_tracks
if (current_time - self.active_tracks[tid]['last_time']) > 5.0]
for tid in inactive_ids :
if tid in self.active_tracks :
del self.active_tracks[tid]
if tid in self.tracks_history :
del self.tracks_history[tid]
return self.annotator.result()
def main() :
# 初始化YOLOv13模型
model = YOLO("yolov13n.pt") # 使用nano模型
# 创建速度估计器(region参数现在是可选的)
estimator = SpeedEstimator(
names=model.names,
region=None, # 可以设置为None表示不使用特定区域
line_width=2,
pixels_per_meter=10.0, # 像素每米,DPI*0.0254
min_speed_distance=10 # 最小移动距离(像素)
)
# 如果需要使用特定测量区域,可以这样设置:
# estimator = SpeedEstimator(
# names=model.names,
# region=[(100, 800), (1800, 800)], # 水平线
# line_width=2,
# pixels_per_meter=100.0
# )
# 打开视频文件或摄像头
cap = cv2.VideoCapture("test.mp4") # 替换为你的视频路径
# cap = cv2.VideoCapture(0) # 使用摄像头
while cap.isOpened() :
# 读取一帧
success, frame = cap.read()
if not success :
break
# 使用YOLOv13进行物体跟踪
results = model.track(frame, persist=True, verbose=False)
# 获取检测结果
if results[0].boxes.id is not None :
boxes = results[0].boxes.xyxy.cpu().numpy()
track_ids = results[0].boxes.id.cpu().numpy().astype(int)
clss = results[0].boxes.cls.cpu().numpy()
else :
boxes = np.zeros((0, 4))
track_ids = np.array([], dtype=int)
clss = np.array([])
# 估计速度并绘制结果
frame = estimator.estimate_speed(boxes, track_ids, clss, frame)
# 显示结果
cv2.namedWindow("Speed Estimation", cv2.WINDOW_NORMAL) # 允许调整窗口大小
cv2.imshow("Speed Estimation", frame)
# 退出条件
if cv2.waitKey(1) & 0xFF == ord("q") :
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__" :
main()
import cv2
import numpy as np
from ultralytics import YOLO
from deep_sort_realtime.deepsort_tracker import DeepSort
# 配置参数
FPS = 30 # 视频帧率
PIXEL_TO_METER = 0.05 # 像素到米的转换系数 (需要根据无人机高度调整)
MIN_SPEED_CALC_POINTS = 5 # 速度计算所需的最小轨迹点数
TRACK_HISTORY_DURATION = 2.0 # 轨迹历史持续时间(秒)
# 初始化模型
print("正在加载YOLOv13模型...")
yolo_model = YOLO('yolov13n.pt')
print("正在初始化DeepSORT跟踪器...")
tracker = DeepSort(max_age=30, n_init=3) # 目标跟踪器
# 运动补偿相关变量
prev_gray = None
H_accumulated = np.eye(3) # 累计单应矩阵
orb = cv2.ORB_create(nfeatures=1000) # ORB特征检测器
matcher = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=False) # 特征匹配器
# 轨迹历史记录
track_history = {}
frame_count = 0
def motion_compensation(current_frame) :
"""使用特征匹配和单应性矩阵估计进行运动补偿"""
global prev_gray, H_accumulated
gray = cv2.cvtColor(current_frame, cv2.COLOR_BGR2GRAY)
# 第一帧初始化
if prev_gray is None :
prev_gray = gray
return current_frame.copy(), H_accumulated
# 检测关键点和描述符
kp1, des1 = orb.detectAndCompute(prev_gray, None)
kp2, des2 = orb.detectAndCompute(gray, None)
# 确保有足够的关键点
if des1 is None or des2 is None or len(des1) < 10 or len(des2) < 10 :
prev_gray = gray
return current_frame.copy(), H_accumulated
# 特征匹配
matches = matcher.knnMatch(des1, des2, k=2)
# 筛选优质匹配
good = []
for m, n in matches :
if m.distance < 0.7 * n.distance :
good.append(m)
# 需要至少4个匹配点来计算单应性矩阵
if len(good) < 10 :
prev_gray = gray
return current_frame.copy(), H_accumulated
# 准备匹配点
src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2)
# 使用RANSAC计算单应性矩阵
H, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
if H is not None :
# 累积单应性矩阵
H_accumulated = H @ H_accumulated
# 应用单应性矩阵进行运动补偿
height, width = current_frame.shape[:2]
compensated_frame = cv2.warpPerspective(current_frame, H_accumulated, (width, height))
# 更新前一帧
prev_gray = gray.copy()
return compensated_frame, H_accumulated
prev_gray = gray.copy()
return current_frame.copy(), np.eye(3)
def detect_and_track(frame) :
"""使用YOLOv13检测目标并用DeepSORT跟踪"""
# YOLO检测
results = yolo_model(frame, classes=[2, 3, 5, 7], verbose=False) # 车辆类: car,motorcycle,bus,truck
detections = []
for box in results[0].boxes :
x1, y1, x2, y2 = map(int, box.xyxy[0].tolist())
conf = box.conf.item()
cls_id = int(box.cls.item())
# 只保留高置信度检测
if conf > 0.5 :
detections.append(([x1, y1, x2 - x1, y2 - y1], conf, cls_id))
# DeepSORT跟踪
tracks = tracker.update_tracks(detections, frame=frame)
return tracks
def calculate_speed(tracks, frame_time) :
"""计算每个跟踪目标的速度"""
global track_history
speeds = {}
for track in tracks :
if not track.is_confirmed() or track.time_since_update > 1 :
continue
track_id = track.track_id
ltrb = track.to_ltrb()
x, y = (ltrb[0] + ltrb[2]) / 2, ltrb[3] # 使用底部中心点(更接近地面)
# 初始化轨迹历史
if track_id not in track_history :
track_history[track_id] = []
# 添加当前点
track_history[track_id].append((x, y, frame_time))
# 移除过时的轨迹点
track_history[track_id] = [p for p in track_history[track_id]
if frame_time - p[2] <= TRACK_HISTORY_DURATION]
# 计算速度 (需要足够的数据点)
if len(track_history[track_id]) >= MIN_SPEED_CALC_POINTS :
# 获取轨迹点
points = np.array([(p[0], p[1]) for p in track_history[track_id]])
times = np.array([p[2] for p in track_history[track_id]])
# 计算位移向量
displacement = points[-1] - points[0]
time_elapsed = times[-1] - times[0]
# 计算速度 (像素/秒)
speed_px = np.linalg.norm(displacement) / time_elapsed
# 转换为实际速度 (m/s)
speed_mps = speed_px * PIXEL_TO_METER
# 转换为km/h
speed_kmh = speed_mps * 3.6
# 保存速度值
speeds[track_id] = speed_kmh
return speeds
def main(video_path) :
"""主处理函数"""
global frame_count
cap = cv2.VideoCapture(video_path)
if not cap.isOpened() :
print(f"无法打开视频: {video_path}")
return
# 创建输出视频
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('output.avi', fourcc, FPS, (width, height))
print("开始处理视频...")
while cap.isOpened() :
ret, frame = cap.read()
if not ret :
break
frame_count += 1
frame_time = frame_count / FPS
# 运动补偿
compensated_frame, _ = motion_compensation(frame)
# 目标检测与跟踪
tracks = detect_and_track(compensated_frame)
# 计算速度
speeds = calculate_speed(tracks, frame_time)
# 可视化结果
for track in tracks :
if not track.is_confirmed() :
continue
track_id = track.track_id
ltrb = track.to_ltrb()
x1, y1, x2, y2 = map(int, ltrb)
# 绘制边界框
color = (0, 255, 0) # 绿色
cv2.rectangle(frame, (x1, y1), (x2, y2), color, 2)
# 显示速度和ID
if track_id in speeds :
speed_text = f"ID:{track_id} {speeds[track_id]:.1f}km/h"
cv2.putText(frame, speed_text, (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, color, 2)
else :
id_text = f"ID:{track_id}"
cv2.putText(frame, id_text, (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
# 显示帧计数
cv2.putText(frame, f"Frame: {frame_count}", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 255), 2)
# 显示和保存结果
cv2.namedWindow('Drone Speed Detection', cv2.WINDOW_NORMAL)
cv2.imshow('Drone Speed Detection', frame)
out.write(frame)
# 退出条件
if cv2.waitKey(1) & 0xFF == ord('q') :
break
# 清理资源
cap.release()
out.release()
cv2.destroyAllWindows()
print("处理完成! 结果已保存到 output.avi")
if __name__ == "__main__" :
# 使用示例视频或摄像头
video_path = "test.mp4" # 替换为你的视频路径
# video_path = 0 # 使用摄像头
# 重要提示:在实际应用中需要校准PIXEL_TO_METER
# 可以通过已知尺寸的物体或无人机高度计算
print(f"当前像素到米转换系数: {PIXEL_TO_METER} (需要根据实际情况校准)")
main(video_path)

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)