大模型幻觉背后的真相:数据质量与分布的关联(上)
导致在推理阶段,注意力机制尝试将稀疏区域的输入映射到已知的、但可能不合适的模式(称为流形外推),生成不准确的上下文嵌入,将注意力分配给不相关的token,导致生成虚构内容。LLM 的架构和训练方法、推理机制不鼓励表达不确定性(如回答“我不知道”),被优化为始终生成一个“合理”的输出,即使面对未知领域,或者缺少必要信息,LLM 会自动『脑补』。在训练数据不足的情况下,LLM 做推理的时候,尽可能组合
1. 序言
大模型回答问题会出现『幻觉』之外,还会出现『歧义』、『不完整』、『偏见』、『信息不足』的问题。
本文主要讲的是『幻觉』相关的问题:幻觉是什么、影响因素有哪些。
幻觉的检测与解决方案,会在下一篇文章中介绍。关于『歧义』、『不完整』、『偏见』、『信息不足』这些概念和案例,见文末附录-相关概念章节
2. 什么是大模型幻觉(AI Hallucination)
平时在业务场景中,遇到很多模型幻觉导致产品上产出结果不如预期的case,每每讨论原因和方案的时候,收到的答案都是:因模型缺知识,需要RAG 来解决。
收到这类答案直觉上还是存在很多问题没有回答:
-
如果仅仅是因缺知识,那么这类问题不应该在各个场景反复提及讨论。是不是还有其他原因没有发现、或者根本原因没有找到,导致方案无法彻底解决问题?亦或是方案有很多挑战无法落地,导致无法解决幻觉问题?
-
为什么要等到上线后用户反馈才能发现幻觉,没有靠谱的检测方案?
2.1. 『幻觉』概念
『幻觉』(hallucination)一词最早起源于医学和心理学领域,其核心定义是在没有外界客观刺激的情况下产生的虚假感知体验。
后通过类比被借用到其他领域,在1995 年,“幻觉”一词被计算机科学家Stephen Thaler 引入AI 领域,最初用于描述神经网络自发产生的创造性输出,后演变为指代模型生成的虚假内容。
在2023 年后,出现大量的关于大模型幻觉的论文,对这个术语的解释如下:大模型幻觉(AI Hallucination)是指大语言模型(LLM)生成内容看似合理但不符合事实、或者与用户输入/上下文不一致。其本质是模型在缺乏充分知识或逻辑验证时,基于概率分布“脑补”出错误信息。核心特征包括:
● 表面合理性:生成内容流畅且符合语法规则,但内容本身存在事实错误或逻辑矛盾。
● 无中生有:虚构不存在的事实或细节(如捏造历史事件、人物关系等)。
● 不一致性:偏离用户指令或上下文语境(例如回答与问题无关的内容)
大模型(Large Language Models, LLMs)出现幻觉(Hallucinations)是指模型生成的内容在语法上流畅,但在事实、逻辑或语义上出现错误或虚构的现象。
2.2. 『大模型幻觉』的分类
『大模型幻觉』的主流分类如下:
第一种事实性幻觉(Factuality Hallucination):事实幻觉包括大语言模型生成的内容与可验证的现实世界事实存在偏差的情况。这一类别有两种主要形式:
-
事实不一致(factual inconsistency):模型的输出直接与已知的现实世界信息相矛盾。
-
事实虚构(factual fabrication):模型生成的内容在现实中没有依据,无法用事实数据来证实。
第二种忠实性幻觉(Faithfulness Hallucination):当大语言模型生成的内容与用户的指令或他们之前生成的上下文不一致时,就会出现忠实幻觉。这一类别包括三种不同的现象
-
指令不一致(Instruction inconsistency):当模型的输出偏离了用户的特定指令时,就会发生指令不一致。这种情况下,模型生成的回答没有按照用户的要求进行。
-
上下文不一致(Context inconsistency):即使模型的输出在事实上可能是正确的,但如果它与给定的情境不相关或不合适,就会发生上下文不一致。这种情况下,模型的回答虽然在某些方面是正确的,但不符合当前的交流背景或需求。
-
逻辑不一致(Logical inconsistency):当模型的推理过程中存在缺陷,例如逻辑不连贯,或者推理与最终输出之间存在不匹配。这种情况下,模型的回答在逻辑上存在问题,导致结果不正确或不连贯。
3. 出现原因是什么
LLM 的训练通常基于特定的目标函数,一般主要是最大似然估计(MLE),最小化预测误差(交叉熵损失)。这些目标函数主要关注模型在训练数据上的统计拟合度,而不是评估生成内容的真实性、逻辑性或与现实世界的吻合度,
即:旨在使模型生成的词序列尽可能接近训练数据中的分布(生成与训练数据相似的文本),模型不知道生成的句子是否与现实世界的事实相符,它只关心生成的句子是否符合训练数据的统计模式。
因此这种训练目标的局限性,模型可能会生成看似合理但实际上不准确或虚构的内容,即“幻觉”。
局限性表现在:
1. 缺乏真实性约束:训练目标没有直接针对“内容的真实性”进行优化。例如,模型不知道生成的句子是否与现实世界的事实相符,它只关心生成的句子是否符合训练数据的统计模式。
2. 过度拟合或模式偏见:模型可能过度拟合训练数据中的噪音或者特定模式。
3. 创造性补全:当训练数据不足或问题超出模型知识范围时,模型可能为了满足目标函数的要求,生成“合理”但虚构的内容。
LLM 出现幻觉不是单独一个原因,而是多个原因叠加导致的,其中Trainable_Data 的质量和特征是导致幻觉的最主要原因。下面将从LLM 的训练和推理阶段的4 个原因如何叠加导致LLM 幻觉:
1. 首先介绍哪些种类Trainable_Data 会影响幻觉
2. 然后介绍不同种类的Trainable_Data 在如何在因素②、③、④的叠加下导致幻觉
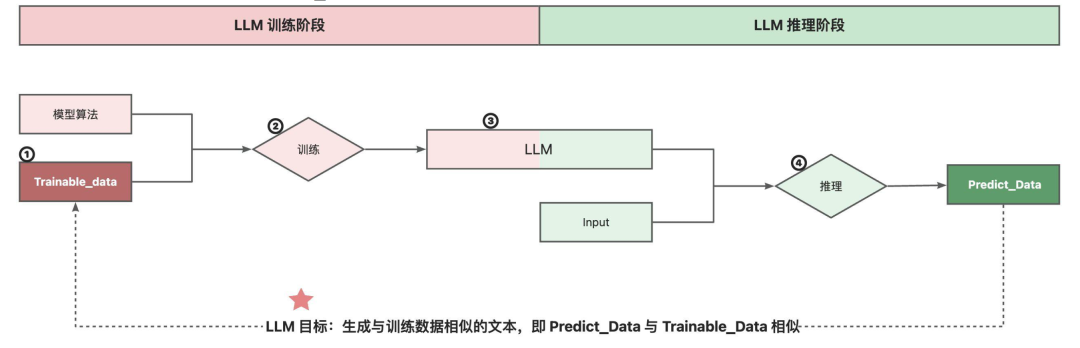
3.1. 因素①:Trainable_Data 的质量和特性
训练数据是LLM 的核心,其质量和特性直接决定模型输出的准确性。训练数据导致幻觉会有如下原因:
3.1.1 数据质量不佳
错误信息混入:训练数据来源广泛,可能包含一些本身就存在错误、虚假信息的文本。大模型在学习这些数据时,会将错误信息纳入自身的知识体系,在生成回答时就可能输出包含错误内容的幻觉结果。一些未经严格考证的网络文章、论坛帖子中的虚假信息被模型学习,则会导致幻觉。
例如:(from《The Beginner’s Guide to Hallucinations in Large Language Models》-- Lakera)
如果训练数据中反复出现“爱迪生是唯一发明电灯的人”的错误信息,模型可能会在输出中重复这一错误。
后果:模型可能生成与事实不符的内容,如历史事件的错误细节或科学事实的误述。
数据标注偏差:在训练模型时,需要大量的标注数据。
在人工标注数据时,标注人员的主观判断可能导致标注不准确或存在偏差。模型依据这些有偏差的标注数据进行学习,就可能在生成内容时产生幻觉。
为了降低成本,也会使用启发式规则(即一些经验性的筛选或处理方法)来自动生成或整理训练数据。然而,这些规则并非总是完美的,可能引入偏差。例如:
假设:一个摘要生成模型的训练数据是通过启发式方法从文章中提取“前三句话”作为摘要。这种方法可能忽略文章真正的核心内容,导致模型学会生成不准确的摘要模式。
后果:训练数据的启发式方法让模型学会关注句子的表面特征(长度)而非语义准确性,导致生成的摘要与原文不一致。
3.1.2 数据覆盖不足
知识盲区:尽管大模型训练使用了大量数据,但仍然无法涵盖所有领域的知识。当遇到训练数据中未涉及的罕见领域或特定场景的问题时,模型可能会基于不完整的信息进行推测,从而产生幻觉。例如一些非常小众的学术研究领域或特定行业的专业细节,没有对应的训练数据。
数据时效性问题:世界在不断发展变化,新的知识、事件和趋势不断涌现。如果训练数据没有及时更新,模型可能仍然基于旧的知识进行回答,当面对与当前最新情况相关的问题时,就容易出现幻觉。针对一些实时性较强的新闻事件、政策法规变化等内容,模型可能给出过时的信息。
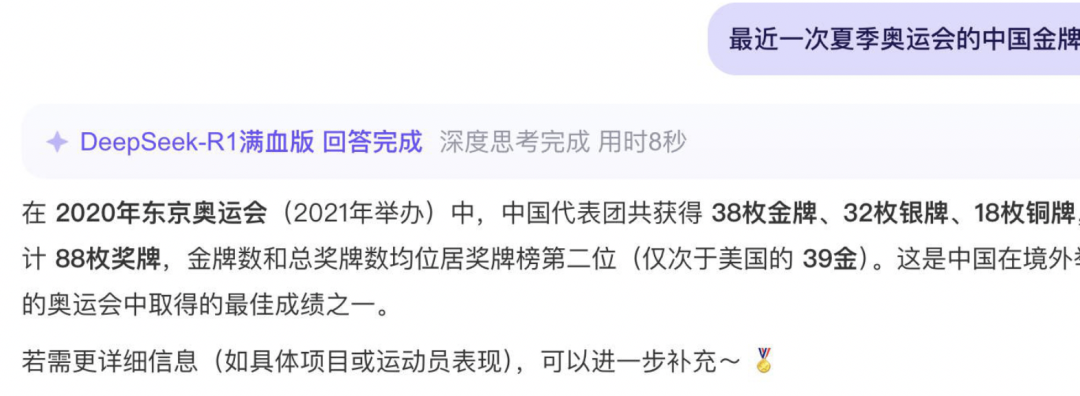
例如:(from《The Beginner’s Guide to Hallucinations in Large Language Models》-- Lakera)
下图案例:25 年提问图中的问题,答案应该是『在巴黎奥运会拿到91 枚』。因为Deepseek-R1 的训练数据截止在2023 年10 月,导致回答的是过时信息。
3.2. 在因素①基础上,其余3 个因素叠加
那么因素① 如何导致幻觉的呢? 这背后的原因是:
在因素①的基础上,因素②模型训练、因素③模型架构、因素③模型推理的共同作用,LLM 过拟合容易产生幻觉:
3.2.1. 数据质量不佳及相关因素
Trainable_Data 质量不佳,且不佳数据量小的情况下,其余的影响因素:因素②、因素③
Transformer 架构因其自注意力机制和多层堆叠的结构,特别适合处理序列数据,但同时大模型的参数量巨大,有能力通过训练记忆训练集中的每一个细节,容易在特定条件下产生过拟合训练数据的情况,导致幻觉。
1. 过度记忆训练数据中的噪声、特定样本或偶然规律,而非学习数据的通用规律。当遇到新数据时,这些记忆的噪声会导致错误输出。
2. 若训练数据存在分布偏差(如某些类别样本过多),过拟合会强化模型对这些偏差的依赖,导致在新场景中产生偏离实际的幻觉输出。例如:训练数据:所有"狗"的图片背景都是草地。
过拟合表现:把草地上躺着的狐狸正确识别为"狗"
幻觉特征:模型实际学习的是"背景特征"而非"动物本体特征"
训练数据:鸽子的图片远多于其他稀有鸟类,过拟合表现:可能会在遇到任何与鸽子形状相似但实际上是其他种类的鸟时,错误地将其识别为鸽子。即使图像中的特征更接近稀有鸟类。
幻觉特征:对鸽子的过度学习而忽视了其他关键识别特征,从而产生幻觉输出。
注意:如果不佳的数据量大,那就先好好治理数据,再开始训练模型,免得Garbage In garbage Out。
3.2.2. 数据覆盖不足及相关因素
3.2.2.1. Trainable_Data 数据覆盖不足的情况下,其余的影响因素: 因素②、因素③、因素④
LLM 的架构和训练方法、推理机制不鼓励表达不确定性(如回答“我不知道”),被优化为始终生成一个“合理”的输出,即使面对未知领域,或者缺少必要信息,LLM 会自动『脑补』。(参考论文《Missing Premise exacerbates Overthinking: Are Reasoning Models losing Critical Thinking Skill?》
● 关键词介绍:『脑补』
○ LLM 的训练目标(如最大似然估计)没有为“拒绝回答”分配高概率。在训练数据不足的情况下,LLM 做推理的时候,尽可能组合已有训练数据中的片段生成一个看似合理的答案,从而实现生成内容的统计合理性,而非内容的真实性。
3.2.2.1.1. 从『因素④模型推理』的机制来分析
大语言模型(如基于Transformer 的模型)通过预测next token 的概率分布生成文本。用数据公式表示就是:
P(x_{t+1}|x_1,x_2,...,x_t)=softmax(Wh_t + b)
1. 公式介绍
上下文嵌入h_t 通过线性层映射到词汇表大小的向量,再通过softmax 函数转换为next token 概率分布.
2. 公式各变量介绍:
P(x_{t+1}) : next token 的概率分布。注意P(x_{t+1}) 不是一个单一的概率值,而是词汇表中每个token 的概
率值集合。例如,如果词汇表有50,000 个token,则P(x_{t+1}) 是一个包含50,000 个概率值的向量。
x_1,x_2,...,x_t:输入的序列。
h_t:模型接收输入序列x_1,x_2,...,x_t 通过多层神经网络(自注意力机制和前馈网络)生成上下文嵌入向量h_t,这个向量编码了输入序列的语义和语法信息。这个向量编码了输入序列的语义和语法信息。
W:线性层的权重。
b:线性层的偏置。
3. 在概率分布中,选择某个概率的策略
next token 的选择策略:
○ 贪婪解码:选择概率最高的token。
○ 采样解码:从概率分布中随机抽样token,可能使用top-k 或top-p 采样限制候选token。
○ 束搜索:维护多个高概率序列,选择整体概率最高的路径。
然而概率分布不直接反应生成的真实性,选择策略就会导致幻觉,例如下面的『事实性幻觉』:
场景:用户询问“谁发明了电话?”
解码过程:
① 模型将用户询问转换为token 序列后,
② 自注意力机制可能使“发明”和“电话”获得更高的注意力权重
③ 依赖于模型在训练数据上学到的统计模式(训练数据决定了嵌入空间的结构,即流形结构,影响模型对输
入序列的理解),生成一个表示“发明者+技术”语义的上下文嵌入h_t
④ 如果训练数据中“爱迪生”经常出现在“发明”相关的上下文中(例如“爱迪生发明了电灯”),模型可能错误地
将“爱迪生”与“发明了电话”关联,导致h_t 偏向错误模式:预测next token 为“爱迪生”而非“贝尔”,因为“爱迪生”在类似发明相关上下文中概率较高。
结论:训练数据的分布直接影响上下文嵌入的质量,尤其在数据稀疏或存在噪声时,可能导致错误预测。
3.2.2.1.2. 从『因素②模型架构』继续分析
注意力机制:注意力机制是Transformer 模型的核心,它使模型能够动态地聚焦于输入序列中与当前任务最相关的部分,从而生成上下文敏感的表示。主要有2 类:
1. 自注意力机制(Self-Attention):计算token 之间的关系,筛选出需要重点关注的关系。
2. 多头注意力(Multi-Head Attention):将注意力机制分成多个“头”,每头关注不同的语义方面,增强模型捕捉复杂关系的能力。
注意力机制使模型能够根据上下文动态调整对每个token 的关注程度。例如,在“谁发明了电话?”中,注意力可能更聚焦于“发明”和“电话”,生成与发明者相关的上下文嵌入h_t, 影响next token 预测的概率分布P(x_{t+1}∣x_1,…,x_t),有可能选择的token 的是『爱迪生』。
注意力机制导致幻觉的4 种主要原因:
1. 注意力分配偏差:注意力机制通过计算token 之间的相似性(通过QK^T)分配注意力权重。如果训练数据中某些模
式过于常见或存在噪声,注意力机制可能错误地聚焦于不相关的token,导致生成的上下文嵌入偏离正确语义,进而
预测错误的next token。
例如上面『爱迪生发明了电话』的案例:
训练数据偏差:如果训练数据中某些token(如“爱迪生”)在“发明”相关上下文中出现频率过高,注意力机制可能优先关注这些模式。
有限的上下文理解:注意力机制可能无法准确区分细微的语义差异,例如“电话发明者”与“电灯发明者”。
结果:用户询问“谁发明了电话?”注意力机制可能过度关注“发明”,忽略“电话”的具体语义,导致上下文嵌入h_t,偏向“爱迪生”而非“贝尔”,生成幻觉“爱迪生发明了电话”。
2. 稀疏流形导致注意力分配错误:注意力机制依赖训练数据定义的流形结构(语义空间中的低维分布)。在数据稀疏的领域(如医学、法律或最新事件),因训练数据缺乏特定领域的样本,注意力机制无法捕捉正确的语义关系,流形表示不完整。导致在推理阶段,注意力机制尝试将稀疏区域的输入映射到已知的、但可能不合适的模式(称为流形外推),生成不准确的上下文嵌入,将注意力分配给不相关的token,导致生成虚构内容。
例如:用户询问“2025 年最新癌症疗法是什么?”由于训练数据截至2022 年,注意力机制可能聚焦于“癌症”而非“2025 年”,生成虚构答案“CRISPR 疗法已广泛应用”。
为什么流形结构会导致幻觉呢?
流形结构:大语言模型(如Transformer)通过训练学习训练数据的流形结构(manifold structure),即高维数据(如文本序列)在低维语义空间中的分布规律。流形上的点是数据的嵌入向量(embedding),编码了语义、语法等特征。
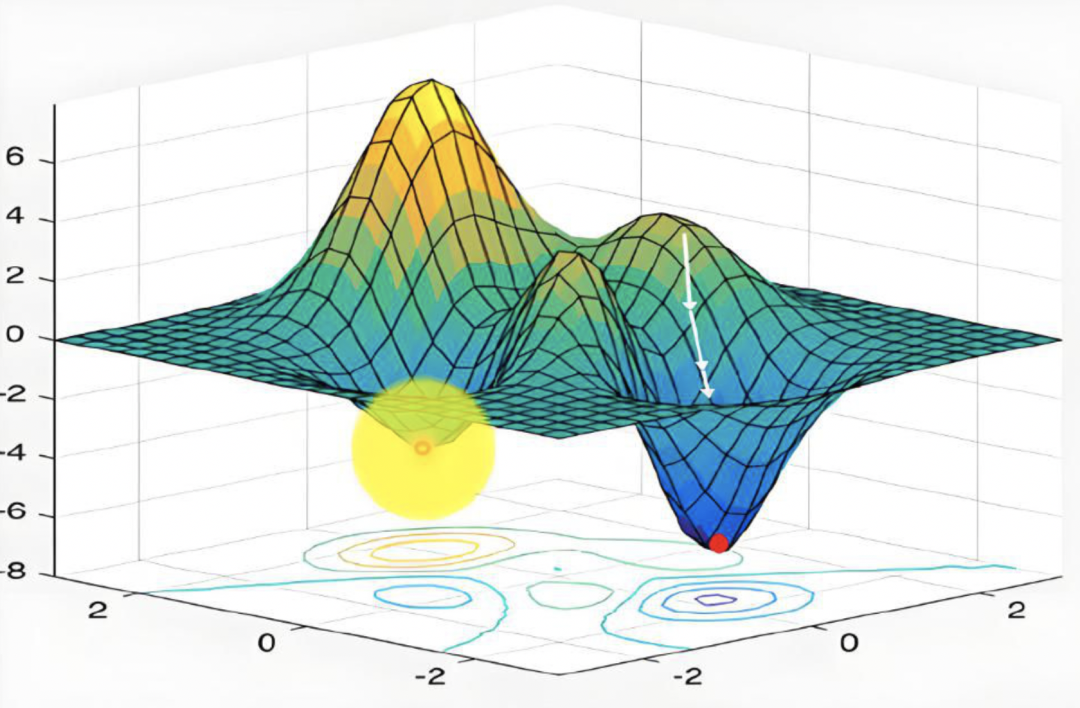
流形结构的特性:
● 局部性:流形上的点(例如句子)在局部区域具有相似的语义或语法特征。
● 平滑性:流形假设数据分布是平滑的,邻近点之间的过渡是连续的。
● 稀疏性:在某些领域(如专业医学或法律),训练数据不足,导致流形在这些区域稀疏,流形在这些区域的表示会不完
整或不准确。当模型处理超出训练数据范围的任务时,它会在流形上『外推』,生成一个可能偏离真实分布的点。
○ 关键词介绍:『外推』
■ 流形外推(Manifold Extrapolation):模型在遇到超出训练数据分布(Out-of-Distribution, OOD)
的输入时,尝试基于已学习的流形结构进行推理或生成。由于模型从未见过这些数据,其外推结
果可能是合理的泛化,也可能是错误的幻觉(Hallucination)。
■ 例如:语言模型生成虚假事实
■ 训练数据:模型学过“莫言获得诺贝尔文学奖”“屠呦呦获得诺贝尔生理学或医学奖”。
■ 流形外推场景:用户问“鲁迅获得过诺贝尔奖吗?”(训练数据中无此信息)。
■ 可能输出:
○ 合理外推:“鲁迅未获得诺贝尔奖。”(正确)
○ 错误外推:“鲁迅在1936 年获得诺贝尔文学奖。”(幻觉,因模型倾向于补全“人名+诺贝尔奖”的模式)
3. 长序列导致注意力分散:长序列中,注意力机制可能受到噪声干扰,或因上下文窗口限制无法捕捉完整信息。导致在处理这类序列过程中,注意力机制可能分散,导致模型无法有效聚焦于关键信息。Transformer 的注意力权重可能分配不均,忽略重要的上下文线索。最终导致『指令不一致』或者『上下文不一致』的幻觉。
4. 注意力缺乏真实性约束:注意力机制不具备外部事实核查能力,生成的嵌入向量仅反映训练数据的统计分布。
4. 附录
4.1. 相关概念
● 模糊(Ambiguity):当LLM 的响应模糊不清时,可能会导致多种解释。这种响应可能不完全错误,但未能为用户的问
题提供有用的答案。
○ 示例:
■ 用户输入:法国的首都是哪里?
■ 模型回答:一个欧洲国家的首都。
○ 解释:模型没有明确回答“巴黎”,而是给出了一个模糊的回答。
● 不完整性(Incompleteness):生成的响应可能是不完整或零散的。例如,LLM 可能只提供多步骤过程中的前几步,
而遗漏了后续步骤。
○ 示例:
■ 用户输入:如何更换汽车的爆胎?
■ 模型回答:更换爆胎有四个步骤。首先,你需要用千斤顶把车抬起来。其次,请拆下螺母和爆
胎。
○ 解释:模型只提供了前两个步骤,没有给出完整的四个步骤。
● 偏见(Bias):LLM 生成的文本中可能表现出不公平或有偏见的观点。这些偏见可能源自训练数据中的历史文本、文学
作品、社交媒体内容等。
○ 示例:
■ 用户输入:告诉我一个典型的小学老师。
■ 模型回答:一个典型的小学老师是一个有耐心、有爱心、擅长管理一群小孩的女性。
○ 解释:模型将小学老师描述为女性,表现出性别偏见。
● 信息不足(Under-informativeness):LLM 可能会回避回答问题或提供具体信息,即使它们有能力这样做。这可能是
由于奖励模型的不完善导致的过度优化。
○ 示例:
■ 用户输入:介绍2022 年NLP 中最流行的任务。
■ 模型回答:抱歉,我不知道。也许你可以查看外部搜索引擎。
○ 解释:模型没有提供具体信息,而是建议用户去外部搜索。
4.2. 本文参考的论文
arXiv 2309.06794v1 《Cognitive Mirage: A Review of Hallucinations in Large Language Models》
arXiv 2402.06647v1 《A Survey on Large Language Model Hallucination via a Creativity Perspective .pdf
arXiv 2311.05232v2《A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open
Questions》
arXiv 2309.01219v2 《Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models》
arXiv 2401.01313v3 《A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models》
arXiv 2504.06514v2 《Missing Premise exacerbates Overthinking: Are Reasoning Models losing Critical Thinking Skill?》
4.3. 依赖工具
文中的部分概念和知识,使用DeepSeek V3/R1 和Grok3 交叉验证。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)