创建第一个AI短视频
视频生成的提示词构成(尽量使用英文),你使用哪个底座模型就去他们的社区或者官网上找到你想要做的风格的视频(sora能看到用户的提示词,wan可以去github看他们大量的示例视频也附上了提示词),去拿到他们公开的提示词,多拿几个丢给gpt让它总结提示词构成模板然后让gpt生成优化几个版本最后再丢到工作流或者api里去抽奖,以便抽奖一边微调。1.设计风格(最好是有一些知名度高的风格如迪士尼,猎魔人,
几个常识性问题:
1.目前的AI视频工具是无法做到短时间内就产出一个1分钟以上的连续性一致性较好的视频
2.在不考虑一致性的情况,分镜切分让每一段分镜都是一个独立场景然后拼接成故事的做法比起要做一个短视频连续剧来说简单很多(我主要是讲后者)(前者常使用的是每一个独立场景用sore1或2生成一个20s以内的短片段,然后进行剪辑再创作,这类影片入手简单,人物和场景一致性相对较差)
3.在要追求相对较高质量以及一致性的前提下,主体,背景,突出道具,片段几乎都需要大量抽奖+剪辑/ps 才能获得最好的效果
4.参考用时,借用b站Mega会玩up新一期视频真人化芙莉莲1分30s的视频用时84H(大佬精益求精,用时仅供参考)
5.最好能具备的环境: 可魔法,有google邮箱,可使用google AI Studio or grok or LMArena ; 4090+主机 ;有一定ps + 剪辑基础;
ps:这里强推一下LMArena 也就是大家常说的大模型竞技场,竞技场常客的大佬们请移步下文。大模型竞技场里你免费使用几乎所有的顶尖的文本生成以及图片生成模
注:本文里面包含了笔者尝试的各种实现方式,现在AI工具层出不穷,各有侧重点,大致流程确定的情况下,以快速便利实现为主。
以下是当时在尝试制作的流程里的随笔,整理成图文博客工作量有点大emmm偷个懒慢
完整流程
一、敲定视频风格
视频风格一般会出现在提示词的开端。常见的是两种限定方式:
1.给出专业名词如:日式动画,美式动画,清新漫画,3D卡通,国风卡通,纸艺风格,简易插画,国风水墨(出自百炼预设选择)。又或是一些公认度高的风格(易被模型识别)如吉卜力风格,迪士尼风格。
2.以出名的电影或导演为参考如:新海诚风,哈利波特风(欧美魔幻),指环王风(中世纪奇幻)等等。
风格筛选可以根据想要创作的内容去查找,也可以用直接的形容词如:二次元风,搞怪风,魔幻风,浪漫风来大致限定整体画面感。
二、生成主体对象
主体对象,大体来说就是人物或背景。
主体有两种使用方式:
1.如VIDUQ2,可以通过多视图来建立主体,在对首尾帧无强烈需求的情况下,可以使用多主体来达到很好的人物背景一致性。
ps:额外提一句截至2025.10.28支持通过三视图来建立主体的应该只有VIDUQ2。VIDUQ1.5的首尾帧+主体其中主体是通过文本进行强约束的。下图就是viduq2中主体创建必要一张主视图,可以添加多视图来加强一致性。白嫖VIDU积分请参考新用户白嫖1000积分

2.将生成的主体反丢给AI,让AI生成主体约束描述,这在使用首尾帧的情况下能够提高主体一致性的概率。(以viduq1.5为例,它提供了主体文本描述约束以及首尾帧,这里的文本描述就可以用AI反推出来文本填上去)
生成主体图片:
无非两条路文生图,图生文。可以在线生成或是本地部署。
在线生成:目前的文生图,图生图模型基本都能白嫖,推荐几个可以白嫖的网站。
需要魔法:1.google AI Studio 免费使用nano banana 2.大模型竞技场
无需魔法:1.即梦 2.豆包(效果一般)
本地部署:工作流常用WebUI,ComfyUI,底座模型 sd1.5,sdXL或者Flux等变体 3060+基本就能跑起来,可以去C站找对应的模型以及风格lora模型。自由度 高,可以批量抽,有一定的门槛,对硬件有刚需。配置高的可以用wan系列
Ps:AI生图很难一次性完美,抽出一张小瑕疵的图后可以丢给AI让它们微调,当然依然存在怎么调都不太行的情况,尤其是一些重要的小细节如佩戴手链等等,此时请祭出万能的PS大法。
三、生成分镜(抽卡大头)
说是分镜,其实实质上就是关键帧,这也是生成超过20s连续的场景和故事必需品。(像sora1.5的storyboard就能实现类似的续写功能,当然依然要提供关键帧或是首尾帧)
一般来说非付费用户可以免费生成的基本都在10s以内,sora2是10s但是只能360p,1080p如viduq2只能4-5s,我们在生成一个90s的视频就需要至少10-15张图乃至更多。
每一组首尾帧最好都能完整的包含一个动作或是一次场景切换。所以漫改,小说改,或是动漫真人化相对实现简单。以动漫真人化为例,我们可以一帧一帧的去做分镜切割,去找到动作或场景的重要起始和结束帧,并截取帧使用图生图的方式来获取我们的关键帧组。小说可以直接丢给AI然AI帮你切分分镜,然后将对应的分镜再交由AI生成相对的关键帧图。(让AI生成生图提示词一定要给出提示词示例。示例可以再官网或者C站等地方找)
这是我让AI自己完善后的切分小说关键帧的提示词可以参考使用。将文件保存为json文件,上传给AI,然后贴上小说片段即可。输出是json格式的切片分段。随后将文本内容再次上传给AI,告知AI你使用的是哪款文生图模型,让AI直接生成提示词,最后在根据出图效果让AI进行相应的提示词修改即可。
{
"role": "你是一名专业的影视视觉导演兼AI提示词工程师,擅长将文字剧情转化为影像关键帧。",
"task": "将输入的小说片段拆解为若干关键帧(Keyframes),每个关键帧代表剧情或情绪的重要节点。",
"requirements": {
"output_format": "JSON数组",
"rules": [
"每个关键帧应能独立成为一个具有明确视觉内容的画面",
"关键帧之间保持时间与情绪的连贯性",
"关键帧数量取决于小说内容的节奏与变化,不强行平均分割",
"每个关键帧用于生成静态图像,因此要具备完整的视觉构图要素(人物、场景、光线、氛围)",
"主要人物字段用于强化人物外观一致性"
],
"output_fields": {
"id": "关键帧编号,从1开始",
"moment_summary": "简要描述该关键帧的剧情/情绪节点",
"main_characters": "主要人物外貌、发色、服装、性格特征等,用于保持视频中人物一致性",
"visual_description": "画面中可见的场景、人物、姿态、光线、氛围、构图",
"prompt_en": "为Nano Banana生成的英文提示词(聚焦于画面、氛围、风格)"
},
"output_relation": "相邻关键帧(id与id+1)即为一个视频片段的首尾帧"
},
"example_output": [
{
"id": 1,
"moment_summary": "少女在雨夜街头独自行走。",
"main_characters": "少女,黑色及肩长发,白色连衣裙,清秀面容,忧郁神情。",
"visual_description": "夜色笼罩的城市街道,霓虹反射在湿润地面上。少女撑着透明伞,缓慢走过路灯下的湿地面。",
"prompt_en": "A cinematic still frame of a young girl with black shoulder-length hair, wearing a white dress, walking alone under neon lights on a rainy street, holding a transparent umbrella, soft reflections on wet asphalt, moody lighting, realistic film style."
},
{
"id": 2,
"moment_summary": "她停下脚步,注视手中的信封。",
"main_characters": "少女保持前一帧外貌和服装,神情紧张,手指微微颤抖。",
"visual_description": "少女站在路灯下,微风掀起她的头发,雨水顺着伞沿滑落。她手中握着一封微湿的信。",
"prompt_en": "A cinematic still frame of the same girl standing under a streetlight, holding a wet letter, hair slightly lifted by soft wind, rain dripping from the umbrella edge, soft yellow lighting, emotional tone, shallow depth of field."
},
{
"id": 3,
"moment_summary": "她抬头望向远处的霓虹灯,眼中闪着泪光。",
"main_characters": "少女保持前一帧外貌和服装,眼中带泪光,神情略带希望。",
"visual_description": "镜头特写少女的面庞,眼角闪烁泪光,远处模糊的霓虹倒映在瞳孔中。",
"prompt_en": "A cinematic close-up of the same girl looking toward neon lights in the distance, raindrops and tears on her face, glowing reflections in her eyes, dramatic soft lighting, realistic film style."
}
]
}
最后输出的viduQ1的提示词,需要上传主体图片,我这里只传了萧炎的图,如果对试炼石形象有需求,也可以将试炼石主体上传。
斜侧镜头,一位身穿深色训练服的沮丧黑发少年@萧炎,正对着一座巍峨发光的古老测验魔石碑。石碑的正面完全朝向少年,其上“斗之力,三段”的字符发出刺眼的强光。少年侧对镜头,清秀的侧脸上是心碎的绝望与苦涩的自嘲,紧握的双拳因用力过猛而渗出鲜血,从掌心滴落。魔法石碑的光芒作为主光源,从他侧前方打来,在他脸上投下强烈的戏剧性阴影,清晰地勾勒出他痛苦的表情。背景是广阔古老的演武场,以及一片模糊的、正在嘲讽他的人群。超写实奇幻风格,电影级氛围,阴郁的冷色调与石碑的魔法蓝光形成对比,光线中尘埃飞舞,8K分辨率,超高细节,大师级作品。ViduQ1下载是有水印的,这种简单的水印可以直接丢到nano banana让AI直接去掉。然后文本内容这块目前生图模型都很差,提供两种解决思路:1.在建立主体的时候主视图就将文字刻在主体上。2.PS大法

有空再改剩下的
5.拿到分镜原图后处理方式:
o1.本地 3060+ 16G+ 可以用comfyui 找一些图片生成工作流抽,优点:免费,国美就能跑,可大量抽奖,可以去c站或者镜像站找特定风格微调的sora或底座模型(底座一般是sd1.5) 缺点:鉴于底座模型性能极限,细致的场面如添加戒指,背景一致性难以保证,可能需要大量抽奖+ps修图,二次元sora或底座比较多,真人效果一般
o2.可以魔法,AI Studio里白嫖nanobanana,Grok直接生图也行,还有万能的大模型竞技场(几乎所有nb的模型都能找到,但有一点概率掉智商?不过不影响毕竟基本都是要大量抽奖的)。除了需要Google账号几乎没有缺点。当然国内可以去白嫖即梦(好像有限制?不太记得了)
o3.ps/美术大佬直接上手完美无瑕
6.首尾帧+主体+背景生成切片短片
截至2025.10.28 暂时没有同时支持使用多视图建立主体 + 首尾帧生成的
这里主要有几个参考
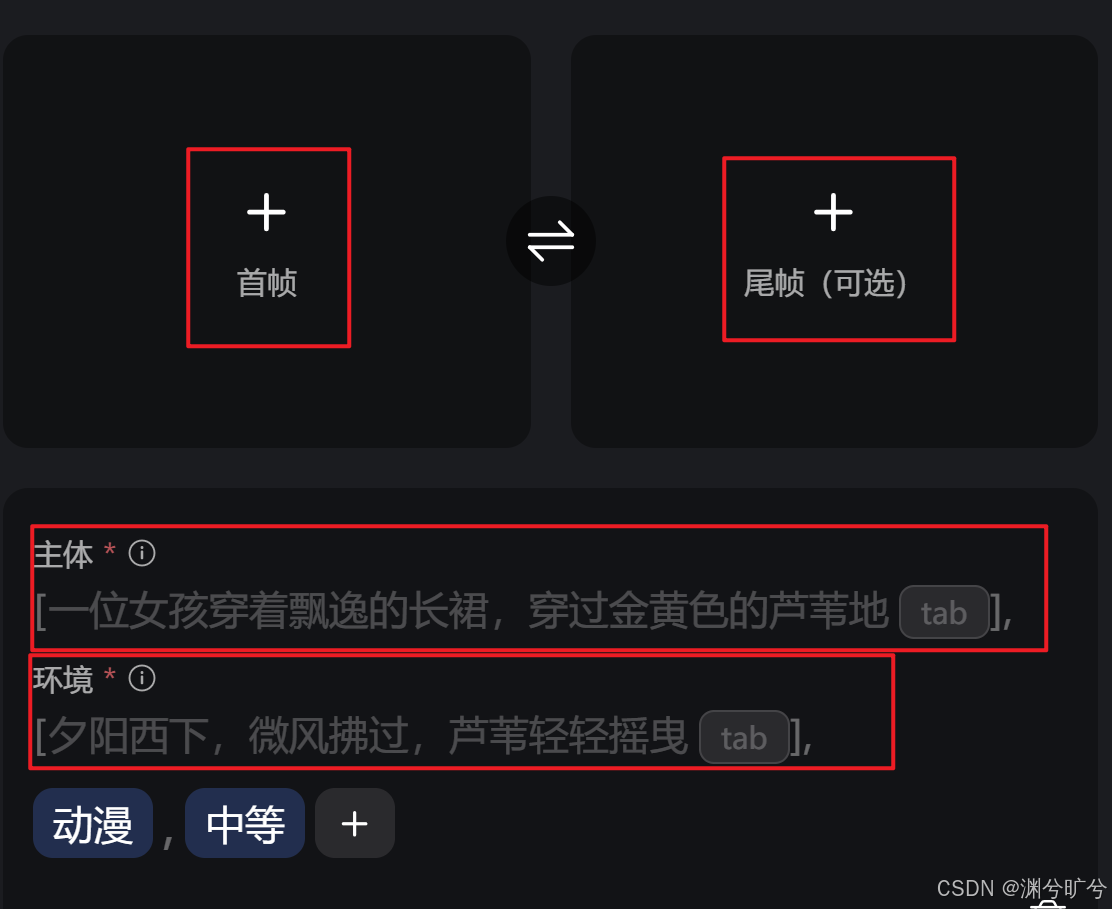
vidu2.0/1.5 支持首尾帧或使用主体 一般来说我们为了保证场景一致性 基本都会选择使用首尾帧,之前做的三视图并非无用,将三视图上传给gpt,grok等等,反推出主体的提示词,用来做主体约束(确定好主体角色之后每一个切片分镜下的主体描述都要一致 ps:即使做了约束依然不可避免的要疯狂抽奖。。。)
wan2.2 开源可本地部署4090 or 5090 可以大量抽卡,可挂载lora(适配wan1.5的风格lora),有比较成熟的工作流,且社区有nsfw和sfw版本(请自行度娘两者差别) 4090应该可以无压力141帧左右
视频生成的提示词构成(尽量使用英文),你使用哪个底座模型就去他们的社区或者官网上找到你想要做的风格的视频(sora能看到用户的提示词,wan可以去github看他们大量的示例视频也附上了提示词),去拿到他们公开的提示词,多拿几个丢给gpt让它总结提示词构成模板然后让gpt生成优化几个版本最后再丢到工作流或者api里去抽奖,以便抽奖一边微调

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)