TSCnet: A text-driven semantic-level controllable framework for customized low-light image enhanceme
基于深度学习的图像增强方法在降低噪声和改善低光照条件下的可见度方面显示出显著优势。这些方法通常基于一对一映射,模型学习从低光到特定增强图像的直接转换。因此,这些方法不够灵活,因为它们不允许高度个性化的映射,即使个人对光照的偏好本质上是个性化的。为了克服这些限制,我们提出了一种新的光照增强任务和一个新的框架,该框架通过提示驱动、语义级别和定量亮度调整提供定制化的光照控制。该框架首先利用大型语言模型(
【文献阅读】TSCnet: A text-driven semantic-level controllable framework for customized low-light image enhanceme
中文题目:TSCnet:一个文本驱动的语义级可控框架,用于自定义弱光图像增强

摘要
基于深度学习的图像增强方法在降低噪声和改善低光照条件下的可见度方面显示出显著优势。这些方法通常基于一对一映射,模型学习从低光到特定增强图像的直接转换。因此,这些方法不够灵活,因为它们不允许高度个性化的映射,即使个人对光照的偏好本质上是个性化的。为了克服这些限制,我们提出了一种新的光照增强任务和一个新的框架,该框架通过提示驱动、语义级别和定量亮度调整提供定制化的光照控制。该框架首先利用大型语言模型(LLM)来理解自然语言提示,使其能够识别出需要调整亮度的目标对象。为了定位这些目标对象,基于Retinex的推理分割(RRS)模块使用反射图像生成精确的目标定位掩码。随后,基于文本的亮度可控(TBC)模块根据生成的光照图调整亮度水平。最后,一个自适应上下文补偿(ACC)模块整合多模态输入并控制条件扩散模型以调整光照,确保准确无误地进行无缝且精确的增强。在基准数据集上的实验结果表明,我们的框架在提高可见度、保持自然色彩平衡以及放大细节而不产生伪影方面的性能更优。此外,其强大的泛化能力使得能够通过自然语言交互在各种开放世界环境中进行复杂的语义级光照调整。项目页面是 https://miaorain.github.io/lowlight09.github.io/。
1. 引言
许多现实世界的应用都需要使用低光图像增强(LLIE)技术,包括监控、交通监测和夜间驾驶。即使在昏暗的光照条件下,LLIE也能够产生清晰的图像,使用户能够更容易地识别潜在的危险以及重要的信息[1]。如图1所示,低光图像可以通过两种方式进行增强:全局级别增强和区域级别增强,分别对应于任务a和任务b。
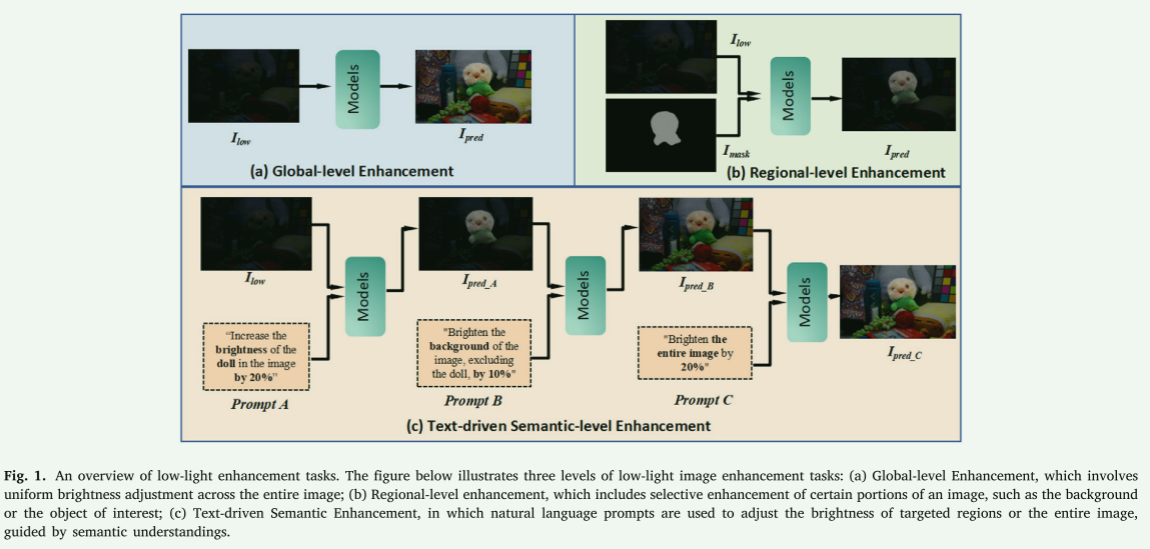
图1. 低光增强任务概述。下图展示了三个层次的低光图像增强任务:(a)全局级别增强,涉及对整个图像进行统一的亮度调整;(b)区域级别增强,包括选择性地增强图像的某些部分,如背景或感兴趣的对象;(c)文本驱动的语义增强,其中使用自然语言提示来调整目标区域或整个图像的亮度,这一过程由语义理解来引导。
研究人员提出了各种全局级别增强方法,包括曲线调整和直方图均衡化,以优化像素分布并产生更清晰、更突出的图像[2,3]。这些方法的问题在于它们未能捕捉到像素值的内在模式,这导致增强后的图像出现颜色失真和细节丢失。随着深度学习(DL)的发展,已经提出了大量的DL模型并且取得了显著的性能。基于Retinex理论,李等人[12]提出了LightenNet,这是一种旨在增强低光图像的卷积神经网络。然而,值得注意的是,LightenNet可能会放大真实场景中的噪声。此外,伽马校正是一种有效的技术,可以增强暗区域的像素强度并调整低光图像的对比度[13]。尽管上述深度学习方法可以提高亮度,但它们主要关注全局亮度调整。尽管如此,当光照条件复杂且不同人对光线的需求不同时,更大程度的区域照明调整是必要的。
为了实现区域级别增强,先前的研究开始将语义信息融入到低光增强任务中[14,15]。ReCoRo [14] 首次通过在增强模型中融入特定领域的增强技术来研究这一场景。尽管它们的增强是专门为人像图像设计的,但可能需要进行改进以适应不同种类的掩码。此外,尹等人采用了一种条件扩散模型,通过迭代细化的方式将图像特定区域的亮度增强到任意期望的水平。[15]
一般来说,全局级的光线增强方法采用一对一映射的方式,限制了根据个人偏好进行微调的灵活性。然而,区域级的光线增强算法可以在语义层面调整亮度,但这种控制仍然严重依赖于手动注释的掩码[14,15],这限制了其灵活性和可扩展性。此外,人们倾向于使用自然语言而不是手动点击来控制光线。因此,我们提出了一种新的文本驱动的语义级光线增强任务,在图1中被称为c任务,其主要目标是通过自然语言控制实现语义级的、量化的亮度调整,使用户能够“随口即调光”。
本工作的主要贡献概述如下:
- 首先,我们提出了一个新的任务,即文本驱动的语义级低光照图像增强任务。随后,我们引入了一种名为TSCnet的新方法,它利用大型语言模型将语言指令分解为两个不同的任务:目标定位和亮度增强。为了实现这一目标,我们提出了两个模块。首先,基于Retinex的推理分割(RRS)模块无需手动注释即可生成掩码图像。其次,基于文本的亮度可控(TBC)模块引入照明图像来指导局部照明调整,确保局部一致性。
- 为了将照明信息无缝地与目标对象集成,我们还引入了自适应上下文补偿(ACC)模块,该模块采用交叉注意力机制和通道适应,将照明信息无缝地与目标对象集成。此外,ACC通过有效地协调额外数据,提高了整体增强过程。
- 我们在几个基准数据集上进行了全面实验,以证明我们的方法优于现有的最先进技术。我们展示了我们方法的泛化能力和使用自然语言进行个性化照明调整的能力。此外,为了验证我们提出的架构的有效性,我们进行了消融研究。
2. 相关工作
2.1.全局级微光图像增强
在全局级增强领域,LLIE(低光照图像增强)中出现了许多专为低光环境设计的架构,例如降噪和细节保留。例如,DMPH-Net架构[16]集成了多尺度金字塔结构与注意力机制,以在增强低光图像的同时最大限度地减少噪声。特别是,EnlightenGAN [22] 和 LEGAN [23] 作为利用生成对抗网络(GANs)将低光图像映射到其改进版本的模型而脱颖而出。由于它们能够处理典型的低光伪影和噪声,这些架构在提高图像质量方面表现出了卓越的性能。此外,通过引入有针对性的损失函数和创新的训练方法,LLIE模型的性能得到了提升。例如,[21] 引入了一种受Retinex理论启发的深度学习技术,通过学习如何将光照映射到自身来提高图像质量,同时集成了一个超分辨率过程以提高输出质量[24]。
2.2. 区域级低光图像增强
对于区域级低光增强[14,15],ReCoRo [14] 集成了一个控制机制,允许用户定义要增强的区域和所需的光照水平。然而,缺乏客观指标和成对的标注使得不准确的用户掩码难以获得美观的结果,这是该模型旨在解决但尚未完全解决的问题。此外,CLE Diffusion [15] 引入了一种新的扩散方法用于可控的光增强,它允许在推理过程中无缝地控制亮度,并结合了Segment-Anything Model (SAM),通过单击即可轻松进行区域特定的增强。然而,这种方法需要手动掩码注释,这并不用户友好,也不允许进行精确的定量光线调整。
2.3 扩散模型在低光增强中的应用
在扩散模型中,通过逐渐向数据添加噪声并训练神经网络来逆转这一过程,从而有效地对数据进行去噪。因此,由于其能够捕捉复杂的模式和结构,它对于增强低光图像非常有效。例如,Nguyen等人[25]应用了一种带有迭代潜在变量细化(ILVR)的级联技术,即使在低光条件下也能实现高水平的重建质量和一致性。Jiang等人[26]的研究结合了一个高频恢复模块(HFRM),通过用垂直和水平数据补充对角特征来增强细粒度细节重建。此外,Shang等人[27]引入了空间和频域信息以增强低光成像,这允许捕获更精确和详细的信息。在[28]中,提出了一种用于基于扩散框架的全局结构感知正则化策略。该策略促进了增强图像相似区域之间的结构和内容连贯性,提高了它们的自然性和审美质量,同时保持了细节和纹理。此外,根据Wang等人[29],提出了一种根据信噪比调整去噪方法的动态残差层,这在中间输出充分曝光时有效地减少了迭代增强过程中的副作用。总的来说,优化扩散架构和整合额外信息对于改善低光增强至关重要。
3. 提出的方法
3.1. 问题表述与总体架构
在实践中,不同人对光线调整的需求差异很大。此外,由于自然语言直观且用户友好的特性,通常比手动注释[15]更受青睐用于控制语义级视觉任务。然而,自然语言固有的模糊性和抽象性使得将其转化为精确行动变得复杂。因此,要实现文本驱动的语义级可控光增强,必须解决两个关键挑战:
- 如何将自然语言指令有效地转换为可执行且定制化的定量条件。
- 如何基于上述条件实施定制化的光照控制。
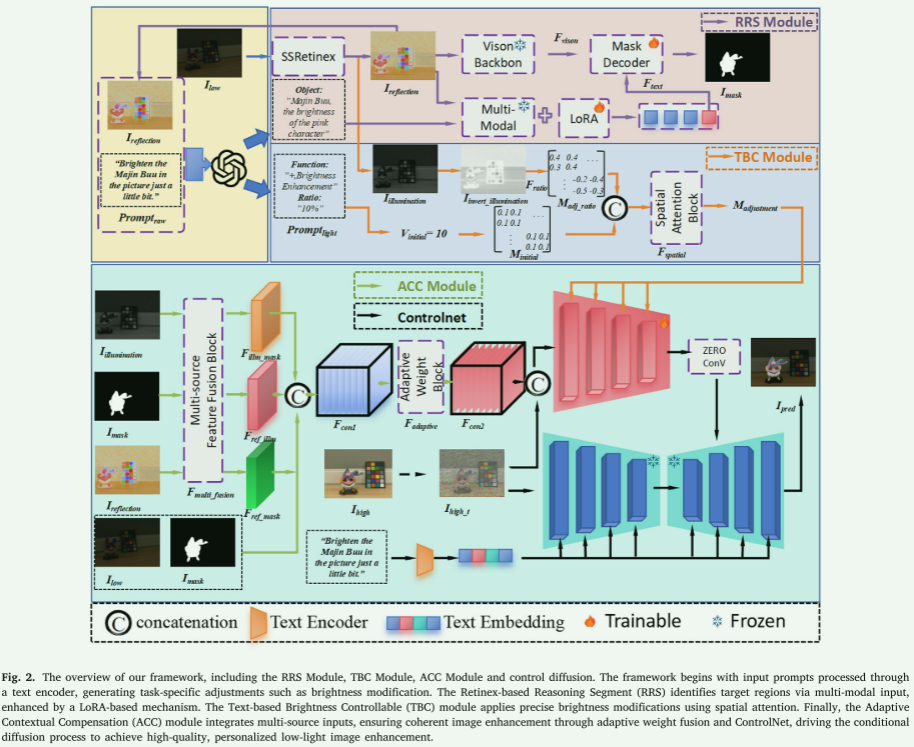
为应对这些挑战,我们创新性地引入了一个大型语言模型(LLM),用于解释自然语言命令中抽象和模糊的概念,准确识别增强目标对象及可量化的亮度水平。然后,利用基于Retinex的推理分割(RRS)模块实现语义级目标定位( I m a s k I_{mask} Imask),接着通过基于文本的亮度可控(TBC)模块估计定量的光线调整( M a d j u s t m e n t M_{adjustment} Madjustment)。最后,自适应上下文补偿(ACC)模块将( I m a s k I_{mask} Imask)和( M a d j u s t m e n t M_{adjustment} Madjustment)作为额外的定制化条件自适应地整合到控制扩散模型中,以实现上下文感知、语义级的基于扩散的光增强(见图2)。
图2:图概述了我们的框架,包括RRS模块、TBC模块、ACC模块和控制扩散。该框架从通过文本编码器处理的输入提示开始,生成特定于任务的调整,例如亮度修改。基于视黄醇的推理段(RRS)通过多模态输入识别目标区域,并通过基于lora的机制进行增强。基于文本的亮度控制(TBC)模块使用空间注意力进行精确的亮度修改。最后,自适应上下文补偿(ACC)模块集成了多源输入,通过自适应权重融合和ControlNet确保相干图像增强,驱动条件扩散过程,实现高质量、个性化的低光图像增强。
3.2 第一阶段:目标对象定位与定量亮度估计
预处理工作流程。预处理始于大型语言模型(LLM),具体为GPT-4o,它处理诸如“把这张照片里的魔人布欧稍微调亮一点”这样的自然语言输入提示 Prompt r a w \text{Prompt}_{raw} Promptraw。LLM识别出目标对象(e.g. Majin Buu; the pink character)和所需的操作(10% brightening)。
基于Retinex的推理分割(RRS)模块。为实现语义级的光线调整,获取准确的语义信息至关重要。现有研究表明,ReCoRo [14]和CLE [15]这两种方法都依赖于人工注释,这不仅耗时耗力且资源需求大,而且还限制了与任务的有效交互。为应对这一挑战,受[21,30-32]的启发,本研究采用了一种推理分割技术,该技术直接利用自然语言处理技术识别并获取目标对象的精确图像。此外,由于在低光照条件下拍摄的图像往往会丢失细节[33-35],导致分割粗糙,本研究利用了Retinex理论[19]提出的分解网络来掩码包含丰富纹理信息的反射图像[19,36-38],从而生成更加精细和准确的目标对象图像。具体步骤如下:
Retinex 基础的推理分割(RRS)模块通过将低光照图像 𝐼 low 𝐼_{\text{low}} Ilow 分解为光照和反射成分,实现了目标对象的精确定位与增强。
I low = I illumination × I reflection I_{\text{low}} = I_{\text{illumination}} \times I_{\text{reflection}} Ilow=Iillumination×Ireflection
解析的自然语言描述(例如“Majin Buu,他的粉色角色的亮度”)然后通过一个多模态块进行处理,该块在[31]中被称为 F text F_{\text{text}} Ftext,并将文本特征与从 I reflection I_{\text{reflection}} Ireflection中提取的视觉特征融合,形成由视觉主干提取的视觉特征:请参见[30]以进一步讨论此过程。
F fusion = concat ( F vision , F text ) F_{\text{fusion}} = \text{concat}(F_{\text{vision}}, F_{\text{text}}) Ffusion=concat(Fvision,Ftext)
这种视觉特征和文本特征的融合随后被输入到掩码解码器[31]中,该解码器预测分割掩码 I mask I_{\text{mask}} Imask:
I mask = F decoder ( F fusion ) I_{\text{mask}} = F_{\text{decoder}}(F_{\text{fusion}}) Imask=Fdecoder(Ffusion)
这一过程确保了像素级分割的准确掩码生成,从而基于自然语言输入实现详细的低光增强。
基于文本的亮度可控模块(TBC)。考虑到个人照明需求的多样性,精确控制光线量非常重要。之前的研究方法以不同的方式解决了这一挑战:ReCoRo [14] 仅支持二进制亮度调整;Zero-DCE [39] 通过不同的连续迭代来优化增强曲线;CLE [15] 要求指定具体的数值用于亮度调节。实际上,当人们表达他们对个性化照明的需求时,往往无法提供精确的定量参数,而倾向于使用模糊的语言,如“稍微增加亮度”。然而,这些方法难以满足此类需求。因此,我们使用语言模型从模糊指令中解析具体的定量参数,并利用从 Retinex 理论 [40,41] 中得出的照明图作为引导图,以实现语言驱动、更精确、区域一致的照明调整,更好地满足个性化需求。具体内容如下。
基于文本的亮度可控模块(TBC)基于自然语言输入 P r o m p t bright Prompt_{\text{bright}} Promptbright 作为基准,并以 I illumination I_{\text{illumination}} Iillumination 作为不同亮度级别的基础,用作空间一致性引导图。具体实现如下。 I illumination I_{\text{illumination}} Iillumination:反转、裁剪、计算均值和归一化。通过利用空间注意力机制 [42],我们得出:
M adjustment = F spatial ( M initial , M adj_ratio ) M_{\text{adjustment}} = F_{\text{spatial}}(M_{\text{initial}}, M_{\text{adj\_ratio}}) Madjustment=Fspatial(Minitial,Madj_ratio)
总的来说,TBC 模块的结构使复杂的局部亮度调整能够在照明图的指导下进行,从而产生与用户需求紧密一致的结果。
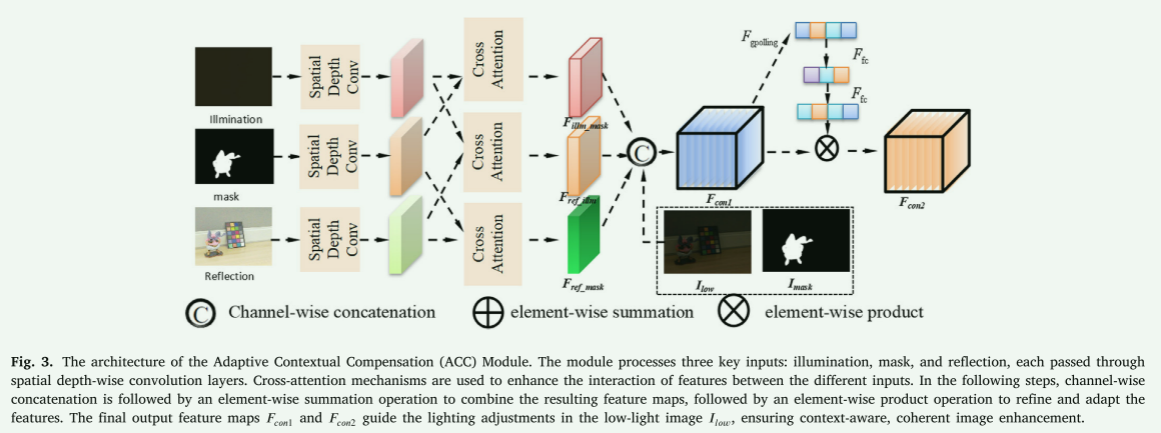
图3. 自适应上下文补偿(ACC)模块的架构。该模块处理三个关键输入:照明、掩码和反射,每个输入都通过空间深度卷积层进行处理。交叉注意力机制用于增强不同输入之间特征的交互。接下来,通道级拼接后跟逐元素求和操作,以组合生成的特征图,随后是逐元素乘法操作,以细化和适应这些特征。最终输出特征图 F con1 F_{\text{con1}} Fcon1和 F con2 F_{\text{con2}} Fcon2指导低光照图像 I low I_{\text{low}} Ilow中的光照调整,确保上下文感知、一致的图像增强。
3.3 第二阶段:自适应上下文补偿和可控去噪过程
Adaptive Contextual Compensation (ACC) Module.
将额外信息融入扩散模型 [43-47] 对于提升任务性能非常重要。与之前仅添加或拼接多种信息源的方法 [45,48] 不同,本研究结合了交叉注意力模块 [49] 和全局通道模块 [42],以促进多模态资源的自适应融合。在此模块中,模型被增强以有效解释各种输入数据并优化权重分布,从而使模型能够生成更精确的光照动态并增强图像亮度。这些特征图通过多模态融合函数 F multi_fusion F_{\text{multi\_fusion}} Fmulti_fusion生成最终的特征图( F con2 F_{\text{con2}} Fcon2),见图3:
F illm_mask , F ref_illum , F ref_mask = F multi_fusion ( F illum , F mask , I reflection ) F_{\text{illm\_mask}}, F_{\text{ref\_illum}}, F_{\text{ref\_mask}} = F_{\text{multi\_fusion}}(F_{\text{illum}}, F_{\text{mask}}, I_{\text{reflection}}) Fillm_mask,Fref_illum,Fref_mask=Fmulti_fusion(Fillum,Fmask,Ireflection)
F con2 = F adaptive ( F illm_mask , F ref_illum , F ref_mask , I low , I mask ) F_{\text{con2}} = F_{\text{adaptive}}(F_{\text{illm\_mask}}, F_{\text{ref\_illum}}, F_{\text{ref\_mask}}, I_{\text{low}}, I_{\text{mask}}) Fcon2=Fadaptive(Fillm_mask,Fref_illum,Fref_mask,Ilow,Imask)
这种结合了原始提示 P r o m p t raw Prompt_{\text{raw}} Promptraw和调整矩阵 M adjustment M_{\text{adjustment}} Madjustment的特征图,随后通过一系列卷积层进行处理,包括自适应交叉注意力 [49-51] 和控制网络 [43,45],从而预测高质量图像 I pred I_{\text{pred}} Ipred:
I pred = F ( x ; Θ ) + Z ( F ( x + Z ( c ; Θ z 1 ) ; Θ c ) ; Θ z 2 ) I_{\text{pred}} = F(x; \Theta) + Z \left( F \left( x + Z \left( c; \Theta_{z1} \right); \Theta_c \right); \Theta_{z2} \right) Ipred=F(x;Θ)+Z(F(x+Z(c;Θz1);Θc);Θz2)
c = ( F con2 , M adjustment , P r o m p t raw ) c = (F_{\text{con2}}, M_{\text{adjustment}}, Prompt_{\text{raw}}) c=(Fcon2,Madjustment,Promptraw)
三个关键输入,包括 F illumination F_{\text{illumination}} Fillumination、 F mask F_{\text{mask}} Fmask和 F reflection F_{\text{reflection}} Freflection,首先通过空间深度卷积层进行处理,以提取每个输入的空间和深度增强特征。随后,应用交叉注意力机制来增强输入之间的关系,提高上下文理解,并利用其他输入作为互补资源来补偿单个输入的不足。在交叉注意力过程之后,增强的特征图与 I low I_{\text{low}} Ilow和 I mask I_{\text{mask}} Imask通过通道级拼接结合,形成精炼的特征图( F con1 F_{\text{con1}} Fcon1),然后将其输入全局通道注意力作为自适应引导。
可控去噪模块
扩散模型 [52] 是生成模型,通过逐步逆向多步噪声添加过程来重建数据,通常将此过程建模为马尔可夫链。以DDPM模型 [53] 为例,该模型执行前向和反向过程,在前向过程中,高斯噪声逐渐插入到干净图像中。这在数学上表示为:
q ( y t ∣ y t − 1 ) = N ( y t ; 1 − β t y t − 1 , β t I ) q(y_t | y_{t-1}) = \mathcal{N}(y_t; \sqrt{1 - \beta_t} y_{t-1}, \beta_t \mathbf{I}) q(yt∣yt−1)=N(yt;1−βtyt−1,βtI)
然而,这种噪声添加计算过程需要逐步进行,计算效率相对较低。在这种情况下,可以使用条件高斯分布的计算技术来直接从 y 0 y_0 y0一步计算出任何时间点的 y t y_t yt。
y t ∼ N ( α ˉ t y 0 , ( 1 − α ˉ t ) I ) , α ˉ t = ∏ i = 1 t 1 − β i y_t \sim \mathcal{N}\left(\sqrt{\bar{\alpha}_t} y_0, (1 - \bar{\alpha}_t) \mathbf{I}\right), \bar{\alpha}_t = \prod_{i=1}^t 1 - \beta_i yt∼N(αˉty0,(1−αˉt)I),αˉt=i=1∏t1−βi
为了加速采样过程,DDIM [54] 引入了一种确定性方法,如下所示:
y t − 1 = α t − 1 ( y t − 1 − α t ε θ ( y t , t ) α t ) + y_{t-1} = \sqrt{\alpha_{t-1}} \left( \frac{y_t - \sqrt{1 - \alpha_t} \varepsilon_\theta(y_t, t)}{\sqrt{\alpha_t}} \right) + yt−1=αt−1(αtyt−1−αtεθ(yt,t))+
1 − α t − 1 − σ t 2 ⋅ ε θ ( y t , t ) + σ t ε t \sqrt{1 - \alpha_{t-1} - \sigma_t^2} \cdot \varepsilon_\theta(y_t, t) + \sigma_t \varepsilon_t 1−αt−1−σt2⋅εθ(yt,t)+σtεt
其中, σ t 2 = η ⋅ β t \sigma_t^2 = \eta \cdot \beta_t σt2=η⋅βt。这里, ε θ \varepsilon_\theta εθ 通常使用U-Net架构 [55] 实现,用于估计噪声图像中的噪声。推理从 y T ∼ N ( 0 , I ) y_T \sim \mathcal{N}(0, \mathbf{I}) yT∼N(0,I) 开始采样,直到最终返回到其“干净图像 y 0 y_0 y0”。
ControlNet 作为核心模型用于生成满足我们要求的图像,通常通过最小化其负对数似然损失函数进行训练(见此处简化的形式):
L simple = E y 0 , t , c , ε [ ∥ ε − ε θ ( α ˉ t y 0 + 1 − α ˉ t ε , t , c ) ∥ 2 ] \mathcal{L}_{\text{simple}} = \mathbb{E}_{y_0, t, c, \varepsilon} \left[ \left\| \varepsilon - \varepsilon_\theta \left( \sqrt{\bar{\alpha}_t} y_0 + \sqrt{1 - \bar{\alpha}_t} \varepsilon, t, c \right) \right\|^2 \right] Lsimple=Ey0,t,c,ε[ ε−εθ(αˉty0+1−αˉtε,t,c) 2]
3.4. 辅助损失函数
为了提高生成模型的敏感性,我们引入了辅助损失 [15] 来直接监督去噪估计。形式上,辅助损失函数可以表示为:
L aux = L base + W col L col + W ssim L ssim \mathcal{L}_{\text{aux}} = \mathcal{L}_{\text{base}} + W_{\text{col}} \mathcal{L}_{\text{col}} + W_{\text{ssim}} \mathcal{L}_{\text{ssim}} Laux=Lbase+WcolLcol+WssimLssim
其中 L col \mathcal{L}_{\text{col}} Lcol 是角颜色损失 [56], L ssim \mathcal{L}_{\text{ssim}} Lssim 是结构相似性损失 (SSIM) [57], W col W_{\text{col}} Wcol 和 W ssim W_{\text{ssim}} Wssim 是加权因子。
颜色损失可以表示为:
L col = ∑ i ∠ ( y ^ 0 i , y i ) , \mathcal{L}_{\text{col}} = \sum_i \angle(\hat{y}_{0i}, y_i), Lcol=i∑∠(y^0i,yi),
其中 i i i 表示像素位置, ∠ ( , ) \angle(,) ∠(,) 确定 RGB 颜色空间中代表颜色的两个三维向量之间的角度差异。
SSIM 损失可以表示如下:
L ssim = ( 2 μ y μ y ^ 0 + c 1 ) ( 2 σ y y ^ 0 + c 2 ) ( μ y 2 + μ y ^ 0 2 + c 1 ) ( σ y 2 + σ y ^ 0 2 + c 2 ) , \mathcal{L}_{\text{ssim}} = \frac{(2\mu_y \mu_{\hat{y}_0} + c_1)(2\sigma_{y\hat{y}_0} + c_2)}{(\mu_y^2 + \mu_{\hat{y}_0}^2 + c_1)(\sigma_y^2 + \sigma_{\hat{y}_0}^2 + c_2)}, Lssim=(μy2+μy^02+c1)(σy2+σy^02+c2)(2μyμy^0+c1)(2σyy^0+c2),
其中 μ y \mu_y μy 和 μ y ^ 0 \mu_{\hat{y}_0} μy^0 是像素值的平均值, σ y \sigma_y σy 和 σ y ^ 0 \sigma_{\hat{y}_0} σy^0 是方差, σ y y ^ 0 \sigma_{y\hat{y}_0} σyy^0 是协方差, c 1 c_1 c1 和 c 2 c_2 c2 是用于数值稳定的常数。
4. 实验结果
4.1. 实验设置
实验分为两个阶段进行:在第一个RRS模块阶段,我们使用AdamW优化器对预训练的U-Net进行了微调,学习率为0.0003,不使用权重衰减,批量大小为6。在第二个控制网络阶段,应用了Adam优化器(初始学习率为 1 × 1 0 − 4 1 \times 10^{-4} 1×10−4,通过余弦退火衰减至 1 × 1 0 − 6 1 \times 10^{-6} 1×10−6),批量大小为8,权重衰减为 1 × 1 0 − 5 1 \times 10^{-5} 1×10−5,总共进行了1000个epoch。
4.2. 数据集和指标
我们在两个常用基准数据集上评估我们的模型:LOL [58] 和MIT-Adobe FiveK [59]。LOL数据集包含485对用于训练的图像和15对用于测试的图像,每一对包括一个低光照图像和一个对应的标准光照图像。在第一个RRS模块中,基于LOL数据集生成了420对带掩码的数据对用于训练。在第二个ControlNet中,为了执行定量任务,我们首先使用Retinex算法 [60] 将低光照图像分解为照明图像( L o w illumination Low_{\text{illumination}} Lowillumination)和反射图像( L o w reflection Low_{\text{reflection}} Lowreflection)。同样的过程应用于高光照图像,得到 H i g h illumination High_{\text{illumination}} Highillumination和 H i g h reflection High_{\text{reflection}} Highreflection。接下来,我们将 L o w illumination Low_{\text{illumination}} Lowillumination调整到十个级别,并与 H i g h reflection High_{\text{reflection}} Highreflection结合生成地面真实图像。MIT-Adobe FiveK数据集包含由五位专家使用Adobe Lightroom编辑的5000张图像。遵循先前的工作 [61,62],我们使用4500对图像进行训练,并保留500对图像用于测试。为了评估输出图像的质量,我们使用SSIM [63]、LI-LPIPS [64]、LPIPS [64] 和 PSNR [65] 指标。
4.3. 比较实验
定性比较。图4至图11展示了各种方法的有效性,包括LLFlow [66]、GSAD [28]、EnlightenGAN [22]、Zero-DCE [67]、KinD++ [60]、CLE [15]、Retinex-Mamba [68]、DiffLL [26]、Retinex-Net [58] 和我们的方法。我们展示了我们的方法在低光照条件下提高可见性的有效性。研究表明,我们的方法在对比度、亮度和细节保留方面有显著改进,而不会产生不自然的伪影。相比之下,其他方法如GSAD [28] 和 EnlightenGAN [22] 要么过度曝光要么曝光不足某些区域,尤其是在复杂照明场景下,如DICM [69] 和 LIME [70]。这些结果表明,我们的方法在处理低光照图像时具有更好的鲁棒性和一致性,能够有效提升图像质量,同时避免了其他方法中常见的过度或不足曝光问题。
图12展示了自然语言如何成功地应用于控制图像中复杂的照明调整精度和灵活性。根据提示输入,框架会调整物体(如玩偶、圆圈或机器)的亮度,按照指定的百分比进行调整。此外,我们的框架不仅改变了目标物体的照明条件,还改变了背景或整个图像的照明条件。这些样本清楚地展示了我们的框架成功实现了文本驱动的语义级光线控制。

图4. 在LOL上与其他先进方法的视觉比较。
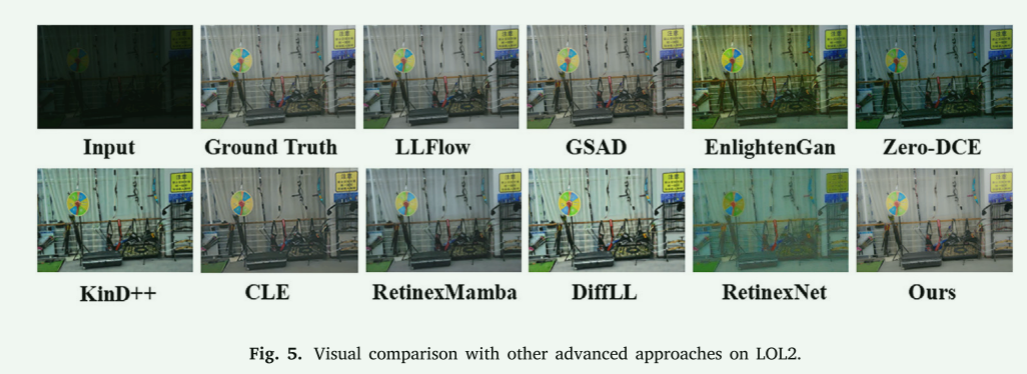
图5. 在LOL2上与其他先进方法的视觉比较。
图6. 在LOM上与其他先进方法的视觉比较。


图7. 在DICM上与其他先进方法的视觉比较。
图8. 在LIME上与其他高级方法的视觉比较。
图9. 在NPE上与其他高级方法的视觉比较。
图10. 在MEF上与其他高级方法的视觉比较。
图11. 在REAL上与其他高级方法的视觉比较。
图12. 使用不同提示进行低光照图像处理的对象特定和通用亮度调整比较。在每个任务中,使用自然语言指令来提亮目标或背景照明,所有这些都由自然语言提示驱动。




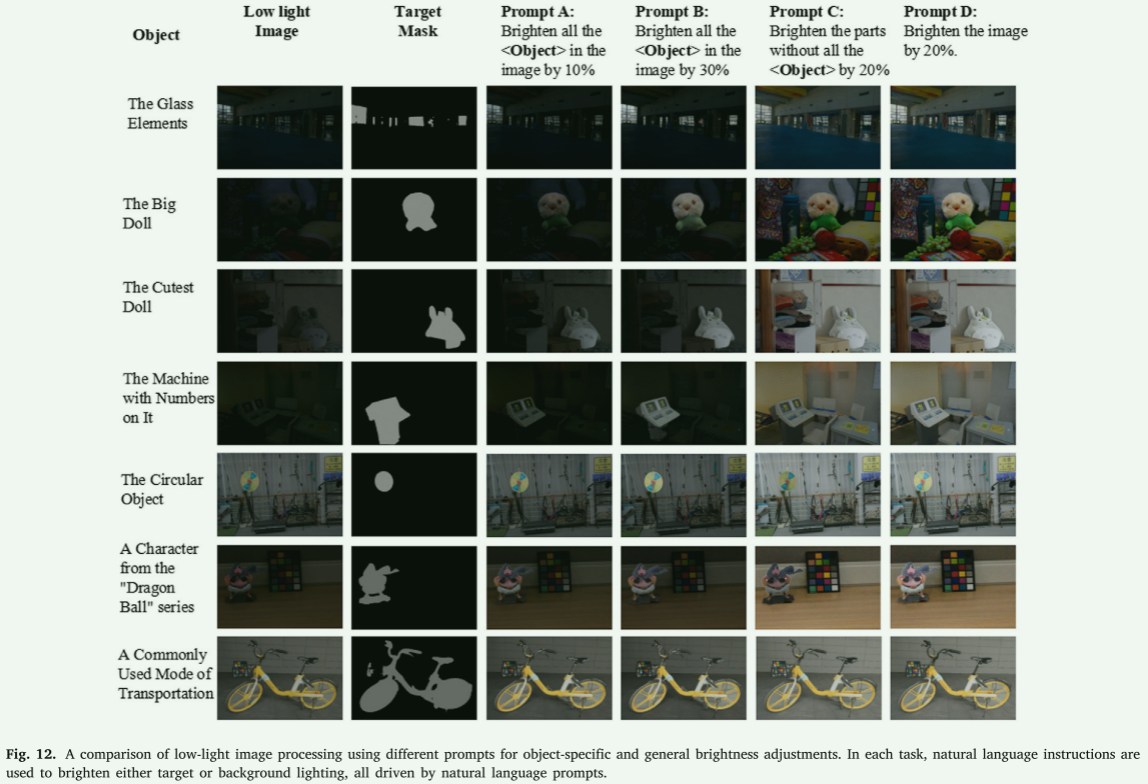
定量比较。表1提供了在LOL数据集[58]上测试的最新方法的比较。该表格使用关键指标(如PSNR)对每种方法进行了比较。我们的方法在LOL数据集的测试中表现卓越,实现了所有竞争模型中的最高PSNR分数,达到了25.78,优于其他如LLFlow(25.19)和CLE(25.51)等模型。同时,我们的模型在SSIM指标上获得了0.94的高分,仅以微小差距落后于MAXIM的0.96,这表明了我们在增强图像时具有强大的结构保留能力。此外,我们的模型在LPIPS(衡量感知相似性)方面也取得了与LLFlow相媲美的结果,两者均达到0.15的感知质量分数。这些关键指标包括 P S N R PSNR PSNR (峰值信噪比), S S I M SSIM SSIM (结构相似性指数测量), 和 L P I P S LPIPS LPIPS (学习到的感知图像块相似性),共同证明了我们方法在提升图像质量和保持结构信息方面的优越性能。
表 1 在 LOL 数据集上的比较。最佳结果以粗体表示,而次佳结果则以下划线标出。
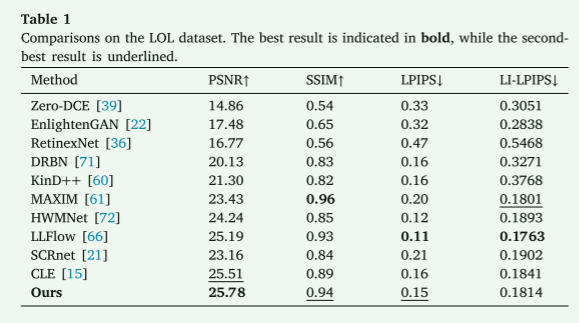
表2展示了在MIT-Adobe FiveK数据集上对几种高级方法的比较,使用两个关键指标进行评估:PSNR和SSIM。TSCnet表现出最佳性能,PSNR为29.92,超过CLE,后者以29.81位居第二。其他值得注意的表现包括HWMNet(26.29)和MAXIM(26.15)。CLE获得了最高的SSIM值0.97,而我们的方法和HWMNet共享第二高的分数0.96。这表明我们的方法在保持结构相似性方面表现得非常出色。
表2 在MIT-Adobe FiveK数据集上的比较。最佳结果以粗体表示,而次佳结果则以下划线标出。
我们还在未配对的现实世界低光照图像上进行了实验,包括DICM [69]、LIME [70]、MEF [76]、NPE和VV,并使用NIQE指标进行图像质量评估。表3展示了我们评估的定量结果,其中我们的方法在各种数据集上始终达到有竞争力的NIQE分数。对于DICM,我们的模型表现最佳,得分为3.68,在LIME上,我们达到4.14,仅次于DiffLL。
4.4 消融实验
模块架构的消融。图13展示了使用RRS模块在掩码生成质量上的改进。为了评估每个模块的有效性和相互作用对网络整体性能的影响,我们在LOL数据集上进行了消融研究,通过系统地移除每个模块(RRS、TBC和ACC)并分析其对性能的影响。
图13. 无RRS模块和有RRS模块的掩码生成比较。

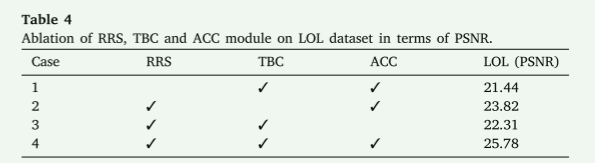
结果如表4所示,以PSNR的形式展示了每个模块对网络整体性能的贡献。在不包含任何模块的情况下(案例1),PSNR为21.44作为基线。在案例2中,仅引入RRS模块将PSNR提高到23.82,突显了其在增强语义级目标定位中的作用。在案例3中,添加TBC和RRS模块进一步将PSNR提高到22.31,展示了其在实现定量亮度调整方面的有效性。最后,在案例4中,通过整合包括ACC模块在内的三个模块,实现了最高的PSNR(25.78)。这表明这些交互的组合显著增强了网络的情境感知、语义级光线增强能力。总之,本节强调了这些模块的互补贡献及其在实现良好整体性能方面的重要性。
表4 在LOL数据集上RRS、TBC和ACC模块的消融研究,以PSNR为指标。
4.5. 使用提示在开放世界场景中进行灵活的照明调整
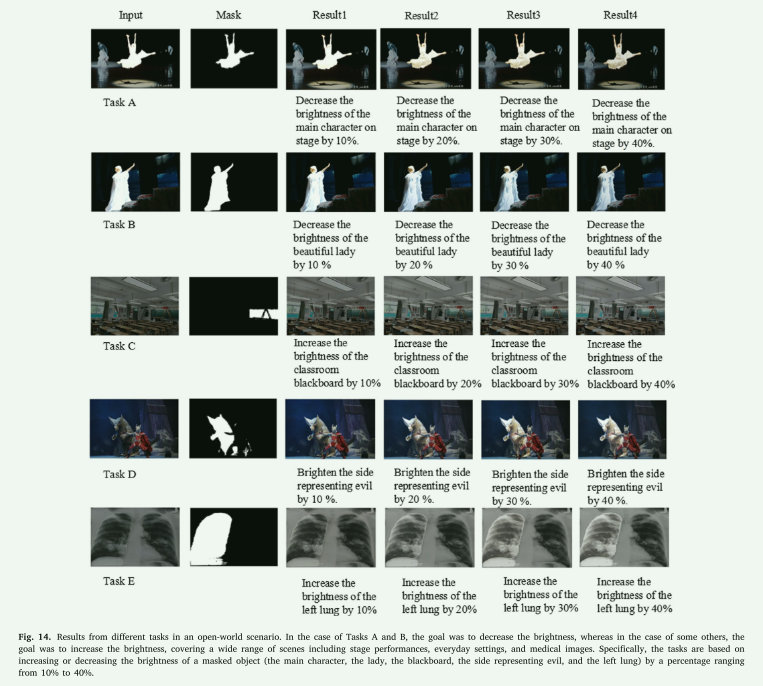
利用LLM、RRS、TBC和Diffusion的高级功能,我们能够通过自然语言的使用,将整体图像亮度调节到定义的水平,同时对目标区域进行精确调整。在图14中,展示了开放世界场景中的五个不同任务,每个任务都专注于改变特定区域的亮度。对于任务A,舞台上主要角色的亮度逐渐降低10%至40%。同样,在任务B中,图像中女士的亮度以相同的增量减少。任务C侧重于增加教室黑板的亮度,而任务D则在幻想场景中照亮代表邪恶的一侧。最后,在任务E中,通过逐步增加,医学图像中左肺的亮度得到增强。这些结果清楚地展示了该方法在局部亮度调整方面的精确度,即使在复杂提示和开放世界场景下也是如此。通过正确解释这些命令,系统可以调整选定区域或对象的亮度。这样,目标和背景照明可以同时进行调整。因此,该系统能够完全使用自然语言描述执行复杂的照明任务。这不仅展示了将语言模型融入图像处理的灵活性,还展示了动态、现实世界照明控制应用的潜力。
图14. 开放场景下不同任务的结果。在任务A和B的情况下,目标是降低亮度,而在其他一些情况下,目标是增加亮度,涵盖了从舞台表演、日常环境到医学图像的广泛场景。具体来说,这些任务基于将一个被遮罩对象(主角、女士、黑板、代表邪恶的一侧以及左肺)的亮度增加或减少,百分比范围从10%到40%。
4.6. 低光人脸检测
在本节中,图15示出了各种低光图像增强方法在应用为低光环境中的面部检测的预处理时的性能。开始,该研究使用DARK FACE数据集[77],然后与广泛认可的面部检测器DSFD [78]进行比较。如图15所示,精度-召回(PR)曲线证明了“我们的+DSFD”方法的上级性能,其实现了0.394的最高平均精度(AP)。相比之下,其他方法,如ZeroDCE,Uformer和EnlightenGAN,在PR曲线上表现较低。此外,如右图所示,DSFD结合不同的增强方法用于在具有挑战性的低光环境中检测人脸。总体而言,“Ours + DSFD”方法始终比KinD++,LLflow和ZeroDCE等替代方案产生更准确,更清晰的人脸检测结果。因此,我们的方法成功地提高了低光图像的可见度,从而使DSFD检测器在这些条件下更有效地工作。
图15展示了不同方法在低光条件下的面部检测性能。左侧的图表显示了精度-召回率(PR)曲线,其中“Ours + DSFD”达到了最高的精度。“Ours + DSFD”与原始输入、EnlightenGAN、KinD++、LLflow和ZeroDCE相比,在右侧图表中提供了最清晰和最准确的结果。
5. 结论
这项工作介绍了一种新的任务和基于扩散的方法,用于使用自然语言增强低光图像,以改善图像增强的语义和定量方面。我们的框架集成了先进的模块,如基于retex的推理段(RRS),用于精确的目标定位,基于文本的亮度可控(TBC)模块,用于自然语言驱动的亮度调节,以及自适应上下文补偿(ACC)模块,用于无缝集成跨域的外部条件。实验结果表明,我们的方法在PSNR、SSIM和LPIPS指标方面优于LOL和MIT-Adobe FiveK数据集上最先进的方法,同时也展示了其在开放世界数据集上使用复杂文本驱动提示进行光增强的语义级可控性。然而,该框架的有效性在很大程度上取决于大型语言模型(Large Language Model, LLM)准确解释自然语言指令并将其转换为可执行的定量条件的能力,语言歧义给目标定位和亮度估计带来了挑战。虽然这个项目不涉及色彩校正,但未来的工作将探索自然语言如何生成美观的图像。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)