ML-Agents:智能体(四)
使用在决策之间累积奖励。使用覆盖决策之间累积的任何先前奖励。为了确保更稳定的学习过程,任何给定奖励的幅度通常不应大于 1.0。正向奖励通常比负向奖励更有助于塑造智能体所期望的行为。过多的负向奖励可能会导致智能体无法学习任何有意义的行为。对于移动任务,通常会为向前速度设置一个较小的正奖励(0.1)。如果您希望智能体快速完成任务,那么在智能体未完成任务的每一步(-0.05)内提供小额惩罚通常会很有帮助
注:本文章为官方文档翻译,如有侵权行为请联系作者删除
Agent - Unity ML-Agents Toolkit–原文链接>
ML-Agents:智能体(一)
ML-Agents:智能体(二)
ML-Agents:智能体(三)
ML-Agents:智能体(四)
奖励
在强化学习中,奖励是智能体做对了某件事的信号。PPO 强化学习算法的工作原理是优化智能体所做的选择,以便智能体随着时间的推移获得最高的累积奖励。奖励机制越好,智能体的学习效果就越好。
注意: 智能体使用训练模型进行推理时不会使用奖励,模仿学习时也不会使用奖励。
建议先从简单的做起,仅在必要时再增加复杂性。在 一般来说,您应当奖励结果,而非您认为会带来期望结果的行为。您甚至可以利用智能体启发法来控制智能体,同时观察其如何累积奖励。
通过调用智能体上的AddReward()或SetReward() 方法将奖励分配给智能体。每次决策之间分配的奖励应在 [-1,1] 范围内。超出此范围的值可能会导致训练不稳定。 当智能体收到新的决策时, reward 的值将重置为零。如果针对单个智能体决策有多个对 AddReward() 的调用,那么奖励将会累加起来,以评估之前的决策效果如何。这 SetReward() 将会覆盖自上次决策以来给予代理的所有先前奖励。
示例
您可以查看示例环境OnActionReceived()中定义的函数, 了解这些项目如何分配奖励。
在“ GridWorld”示例中, GridAgent 类使用了一个非常简单的奖励系统:
Collider[] hitObjects = Physics.OverlapBox(trueAgent.transform.position,
new Vector3(0.3f, 0.3f, 0.3f));
if (hitObjects.Where(col => col.gameObject.tag == "goal").ToArray().Length == 1)
{
AddReward(1.0f);
EndEpisode();
}
else if (hitObjects.Where(col => col.gameObject.tag == "pit").ToArray().Length == 1)
{
AddReward(-1f);
EndEpisode();
}
当智能体达到目标时,它会获得正奖励,而当它掉进坑里时,它会获得负奖励。否则,它得不到任何奖励。这是一个 sparse(稀疏) 奖励系统的例子。智能体必须进行大量探索才能找到不常见的奖励。
相比之下,Area 示例中的 AreaAgent智能体每走一步都会获得少量的负奖励。为了获得最大奖励,智能体必须尽快完成到达目标方格的任务:
AddReward( -0.005f);
MoveAgent(act);
if (gameObject.transform.position.y < 0.0f ||
Mathf.Abs(gameObject.transform.position.x - area.transform.position.x) > 8f ||
Mathf.Abs(gameObject.transform.position.z + 5 - area.transform.position.z) > 8)
{
AddReward(-1f);
EndEpisode();
}
如果智能体从比赛场地上掉下来,还会受到更大的负面惩罚。
3DBall中的Ball3DAgent智能体采用了类似的方法,但只要智能体保持球的平衡,就会分配少量的正奖励。智能体可以通过将球保持在平台上来最大化其奖励:
SetReward(0.1f);
// When ball falls mark Agent as finished and give a negative penalty
if ((ball.transform.position.y - gameObject.transform.position.y) < -2f ||
Mathf.Abs(ball.transform.position.x - gameObject.transform.position.x) > 3f ||
Mathf.Abs(ball.transform.position.z - gameObject.transform.position.z) > 3f)
{
SetReward(-1f);
EndEpisode();
}
当球从平台上掉落时, Ball3DAgent 也会受到一个负惩罚。
请注意,所有这些环境都使用了 EndEpisode() 方法,该方法在达到终止条件时手动结束一个回合。这可以独立于 Max Step 属性进行调用。
总结
- 使用
AddReward()在决策之间累积奖励。使用SetReward()覆盖决策之间累积的任何先前奖励。 - 为了确保更稳定的学习过程,任何给定奖励的幅度通常不应大于 1.0。
- 正向奖励通常比负向奖励更有助于塑造智能体所期望的行为。过多的负向奖励可能会导致智能体无法学习任何有意义的行为。
- 对于移动任务,通常会为向前速度设置一个较小的正奖励(0.1)。
- 如果您希望智能体快速完成任务,那么在智能体未完成任务的每一步(-0.05)内提供小额惩罚通常会很有帮助。在这种情况下,当智能体达成目标时,任务的完成也应与回合的结束相一致,此时应调用智能体上的
EndEpisode()。
智能体(Agent)属性
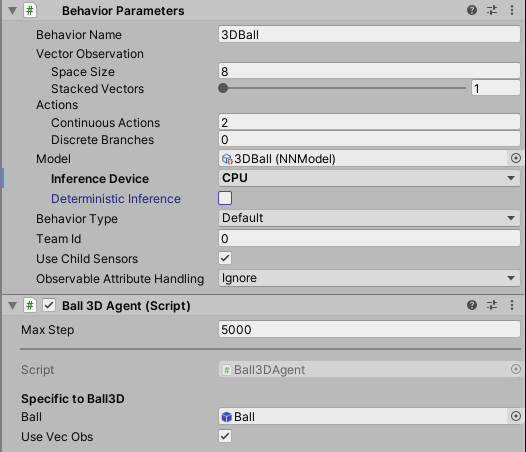
Behavior Parameters- 决定智能体将接收什么策略的参数。Behavior Name- 行为的标识符。具有相同行为名称的智能体将学习相同的策略。Vector ObservationSpace Size- 智能体的矢量观测的长度。Stacked Vectors- 将被堆叠并共同用于决策的先前向量观测的数量。这导致传递给策略的向量观测的有效大小为: 空间大小_x_堆叠向量。
ActionsContinuous Actions- A智能体可以采取的并发连续操作的数量。Discrete Branches- 一个整数数组,定义多个并发的离散动作。数组中的值Discrete Branches对应于每个动作分支可能的离散值的数量。
Model- 用于推理的神经网络模型(训练后获得)Inference Device- 推理时是否使用 CPU 或 GPU 来运行模型。注 3.0版本并没有这个选项Behavior Type- 确定智能体是否进行训练、推理或使用其Heuristic()方法:Default- 如果智能体连接到 Python 训练器,它将进行训练,否则它将进行推理。Heuristic Only- 智能体将始终使用该Heuristic()方法。Inference Only- 智能体将始终进行推理。
Team ID- 用于定义自我对战的队伍Use Child Sensors- 是否使用附加到此智能体的子游戏对象的所有传感器组件。Max Step- 每个智能体的最大步数。一旦达到此数字,智能体将被重置。
销毁智能体
您可以在模拟过程中销毁智能体游戏对象。请确保始终至少有一个智能体在训练,方法是每次销毁一个智能体时生成一个新的智能体,或者在环境重置时重新生成新的智能体。
定义多智能体场景
对抗场景下的团队
通过在训练器配置中包含自对战超参数层次结构来触发自对战。为了区分对立的智能体,请在智能体预制件上的行为参数脚本中将团队 ID 设置为不同的整数值。
![![[team_id.png]]](https://i-blog.csdnimg.cn/direct/15e8143941794eb39f2fdaad89c29160.png)
团队 ID 必须是大于等于0的整数。
在对称游戏中,由于所有智能体(即使是对立团队中的智能体)都将共享相同的策略,因此它们的行为参数脚本中应该具有相同的“行为名称”。在非对称游戏中,它们的行为参数脚本中应该具有不同的行为名称。请注意,在非对称游戏中,智能体必须同时具有不同的“行为名称”和不同的队伍 ID!
有关如何使用此功能的示例,您可以查看Tennis和Soccer环境的训练器配置和智能体预制件。Tennis和Soccer提供了对称游戏的示例。要训练非对称游戏,请为每个行为名称指定训练器配置,并在两者中包括自玩超参数层次结构。
合作场景群组
在 ML-Agents 中,可以通过在环境控制器或类似脚本中实例化一个 SimpleMultiAgentGroup 来启用合作行为,并使用 RegisterAgent(Agent agent) 方法向其中添加智能体。请注意,添加到同一 SimpleMultiAgentGroup 中的所有智能体必须具有相同的名称和行为参数。使用 SimpleMultiAgentGroup 可以使组内的智能体学会如何协同工作以实现共同目标(即最大化组给定的奖励),即使在回合结束前移除一个或多个组成员也是如此。然后,您可以使用 AddGroupReward() 、 SetGroupReward() 、 EndGroupEpisode() 和 GroupEpisodeInterrupted() 方法在组级别添加/设置奖励、结束或中断回合。例如:
// Create a Multi Agent Group in Start() or Initialize()
m_AgentGroup = new SimpleMultiAgentGroup();
// Register agents in group at the beginning of an episode
for (var agent in AgentList)
{
m_AgentGroup.RegisterAgent(agent);
}
// if the team scores a goal
m_AgentGroup.AddGroupReward(rewardForGoal);
// If the goal is reached and the episode is over
m_AgentGroup.EndGroupEpisode();
ResetScene();
// If time ran out and we need to interrupt the episode
m_AgentGroup.GroupEpisodeInterrupted();
ResetScene();
多智能体组应与 MA-POCA 训练器一起使用,该训练器专门用于训练合作环境。可以使用poca训练器启用此功能,有关配置 MA-POCA 的更多信息,请参阅 训练配置文档。使用 MA-POCA 时,在情节中被停用或从场景中移除的智能体仍将学习为该组的长期奖励做出贡献,即使它们没有在场景中活跃以体验这些奖励。
请参阅Cooperative Push Block环境中如何使用多智能体组的示例, 请参阅Dungeon Escape环境中如何使用多智能体组与在情节中途从场景中移除的智能体一起使用的示例。
注意:组与团队(用于竞争性设置)的区别如下:一起工作的智能体应该添加到同一个组中,而互相对抗的智能体应该被赋予不同的团队 ID。如果场景中有一个运动场和两个团队,那么应该有两个组,每个团队一个,并且每个团队应该分配一个不同的团队 ID。如果这个运动场在场景中重复多次(例如为了加速训练),每个运动场应该有两个组, 整个场景应该有两个唯一的团队 ID 。在同时配置了组和团队 ID 的环境中,MA-POCA 和自玩可以一起用于训练。在下图中,每个团队有两个智能体,两个运动场上团队相互对抗。所有蓝色智能体应该共享一个团队 ID(橙色智能体应该使用不同的 ID),并且应该有四名组长,每对智能体一名。
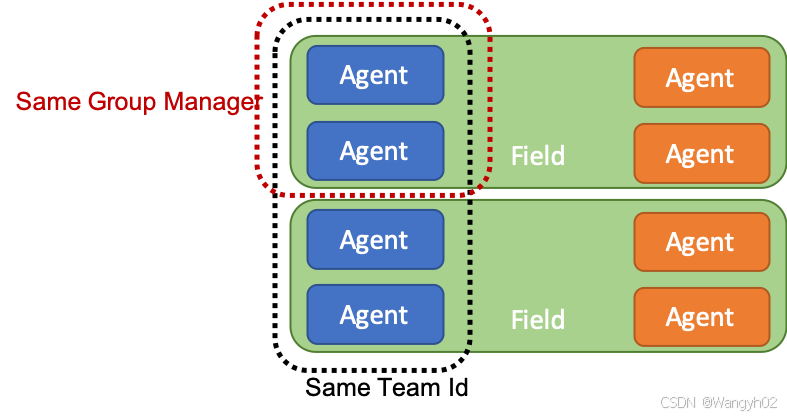
请参阅SoccerTwos环境作为示例。
总结
-
一个智能体一次只能注册到一个 MultiAgentGroup。如果您想要将智能体从一个组重新分配到另一个组,您必须先将其从当前组中取消注册。
-
不支持同一组中具有不同行为名称的智能体。
-
组内的智能体应始终将智能体脚本中的
Max Steps参数设置为 0。 相反,应使用 MultiAgentGroup 处理最大步数,通过使用GroupEpisodeInterrupted()结束整个组的回合。 -
EndGroupEpisode和GroupEpisodeInterrupted在游戏中做同样的工作,但对训练的影响略有不同。如果情节已完成,您可能想要调用EndGroupEpisode。但如果情节尚未结束但已运行了足够的步骤,即达到最大步骤,您将调用GroupEpisodeInterrupted。 -
如果某个智能体提前结束,例如完成了任务/被移除/在游戏中被消灭,不要在该智能体上调用
EndEpisode()。相反,应禁用该智能体,并在下一回合开始时重新启用它,或者完全销毁该智能体。这是因为调用EndEpisode()会调用OnEpisodeBegin(),这会立即重置智能体。虽然可以以这种方式调用EndEpisode(),但在训练一组智能体时,这通常不是期望的行为。 -
如果场景中禁用的智能体需要重新启用,则必须将其重新注册到 MultiAgentGroup。
-
群体奖励旨在强化智能体以群体而非个人的最佳利益行事,并且在训练期间与单个智能体奖励的处理方式不同。因此,调用
AddGroupReward()并不等同于在组中的每个智能体上调用agent.AddReward()。 -
Agent.AddReward()如果智能体属于某个组,您仍然可以使用 向他们添加增量奖励。这些奖励只会提供给那些智能体 ,并且在智能体活跃时才会收到。 -
使用多智能体组的环境可以使用 PPO 或 SAC 进行训练,但智能体在停用/删除后将无法从群体奖励中学习,也不会表现出合作行为。
录制演示
为了记录来自智能体的演示,请将 Demonstration Recorder组件添加到包含组件的场景中的游戏对象Agent。添加后,可以命名将从智能体记录的演示。

当勾选 Record 时,每次从编辑器播放场景时都会创建一个演示。根据任务的复杂程度,可能需要几分钟到几小时的演示数据才能对模仿学习有用。要指定要记录的确切步骤数,请使用 Num Steps To Record 字段,编辑器将在记录了这么多步骤后自动结束您的播放会话。如果您将 Num Steps To Record 设置为 0 ,则记录将一直持续到您手动结束播放会话为止。播放会话结束后,将在 Assets/Demonstrations 文件夹(默认情况下)中创建一个 .demo 文件。此文件包含演示内容。点击该文件将在检查器中提供有关演示的元数据。
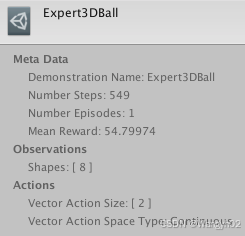
然后,您可以在训练配置中指定该文件的路径 。
鉴于作者水平有限,本文可能存在不足之处,欢迎各位读者提出指导和建议,共同探讨、共同进步。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)