Google 智能体设计模式:知识检索(RAG)
检索增强生成(RAG)通过整合外部知识库解决大语言模型(LLM)静态知识局限,提升回答的实时性与准确性。其核心流程包括语义检索、提示增强与答案生成,依赖嵌入、分块和向量数据库技术。高级模式如GraphRAG(知识图谱)和Agentic RAG(智能代理)可处理复杂跨文档问题,但增加复杂度。应用涵盖企业问答、客服、科研等领域,需权衡准确性、维护成本与延迟。RAG的关键价值在于减少幻觉、支持引用验证,
·
1. 背景与意义
- LLM 的局限:仅依赖训练数据,知识静态,无法访问实时、专有或特定领域信息 → 导致回答过时、不准确或缺乏上下文。
- RAG 的作用:通过检索外部知识库并增强提示,使 LLM 从“闭卷推理者”变为“开卷推理者”,生成更准确、可验证的答案。
- 价值:减少幻觉、支持引用、整合企业内部知识、提升可信度与实用性。
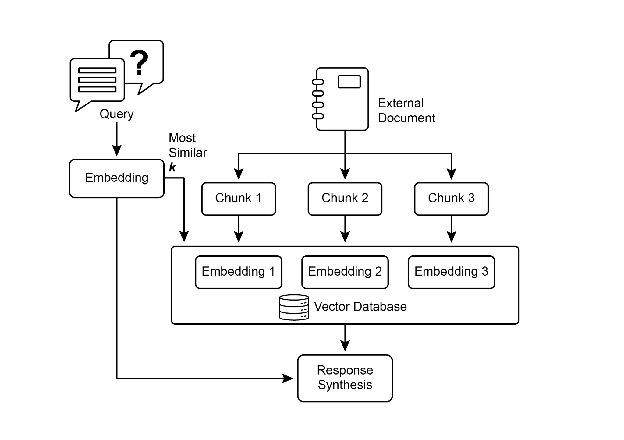
2. RAG 工作流程
- 用户提出问题
- 系统在外部知识库中进行语义搜索,检索相关片段(chunks)
- 将检索结果与原始提示增强合并
- LLM 基于增强提示生成答案
3. 核心概念
- 嵌入(Embeddings):文本的向量化表示,捕捉语义关系。
- 文本相似度:衡量两段文本的相似程度,基于语义而非仅词汇。
- 语义相似度/距离:语义越接近,向量空间距离越小。
- 文档分块(Chunking):将大文档拆分为小片段,便于检索与上下文保持。
- 检索方法:
- 向量搜索(基于语义)
- BM25(基于关键词)
- 混合搜索(结合两者优势)
- 向量数据库:高效存储与检索嵌入,如 Pinecone、Weaviate、Chroma、Milvus、Qdrant,或 Redis/Elasticsearch/Postgres(pgvector)。
4. RAG 的挑战
- 信息分散在多个块或文档 → 检索不完整
- 分块与检索质量直接影响结果
- 矛盾信息难以综合
- 知识库需预处理并持续更新 → 成本高
- 性能问题:延迟、token 消耗、运营成本
5. 高级演进模式
GraphRAG
- 机制:利用知识图谱而非向量库,基于实体与关系(节点-边)检索。
- 优势:能综合分散信息,回答复杂跨文档问题。
- 应用:金融分析、基因研究等。
- 缺点:构建与维护成本高,灵活性差,延迟更大。
Agentic RAG
- 机制:引入推理 agent,主动评估、验证、协调检索结果。
- 能力:
- 源验证:选择最新、权威文档,丢弃过时信息
- 冲突协调:在矛盾数据中优先可靠来源
- 多步推理:分解复杂问题,执行子查询并综合
- 知识补全:识别缺口,调用外部工具(如实时搜索)
- 挑战:复杂性与成本显著增加,可能引入新的错误与延迟。
6. 实际应用场景
- 企业搜索与问答:基于内部文档(HR政策、技术手册)回答员工问题
- 客户支持:自动回答 FAQ、产品手册问题
- 个性化推荐:基于语义相关性推荐内容
- 新闻与时事摘要:结合实时新闻源生成最新总结
- 法律、科研、金融分析:需要可验证、基于事实的答案
7. 经验法则
- 何时使用 RAG:当需要 LLM 基于最新、专有或特定领域信息回答问题时。
- 优势:减少幻觉、支持引用、增强可信度。
- 权衡:准确性与上下文增强 vs. 系统复杂性与延迟。
8. 关键要点总结
- RAG 让 LLM 从静态知识转向动态、可验证知识。
- 基础技术:嵌入、语义搜索、向量数据库、分块策略。
- 高级模式:GraphRAG(知识图谱)、Agentic RAG(推理 agent)。
- 应用广泛:企业、客服、新闻、科研、金融。
- 挑战:信息碎片化、冲突协调、知识库维护、性能开销。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)