医疗领域新动态:OpenAI 携手 PubMedQA 作者,深度解析 HealthBench 的革命性影响!
大多数医学 LLM 评估都采用问答(QA)的形式。大致而言,这些 QA 任务可分为两类:closed-ended tasks,例如多选题(MCQs),以及 open-ended tasks,例如生成自由格式的诊断方案或总结复杂的患者病历。两种形式各有权衡:closed-ended 基准测试易于评估,而 open-ended 任务更能反映真实世界场景。
1 – 当前医学 LLM 评估 现状
大多数医学 LLM 评估都采用问答(QA)的形式。大致而言,这些 QA 任务可分为两类:closed-ended tasks,例如多选题(MCQs),以及 open-ended tasks,例如生成自由格式的诊断方案或总结复杂的患者病历。两种形式各有权衡:closed-ended 基准测试易于评估,而 open-ended 任务更能反映真实世界场景。
1.1 – Closed-ended tasks
closed-ended 任务使用预定义的答案空间来评估模型回答的某一特定部分。常见示例包括 MCQ 数据集,如 MedQA、PubMedQA、MedMCQA 以及 MMLU 的生物医学子集。
除了 MCQ 外,像 GSM8k 这类只评估答案中最终数值输出的数学任务也属于 closed-ended 任务,因为推理部分通常不被评估。在通用领域,有各种基准测试遵循这种模式来评估数学问题求解和代码生成。在医学领域,我们最近推出了 MedCalc-Bench,用于评估 LLM 的临床计算能力,但在医学计算与数据科学方面仍需要更多评估基准。
当新模型发布时,大多数医学 LLM 都会在上述 MCQ 数据集上进行评估,其中 MedQA(USMLE)或许是医学领域最常用的 MCQ 基准。由于可能答案集是预定义的,因此性能可以通过诸如答案准确率(choice accuracy)等直接度量来衡量,而无需临床专家参与。下图展示了一个示例。

Figure 1. An example MedQA-USMLE question and LLM’s answer (Liévin et al, 2024).
然而,MCQ 只是一个不现实的场景,因为现实中并不会给出选项。此外,还存在隐藏的缺陷——LLM 可能通过有缺陷的推理步骤选出正确答案。因此,在 MCQ 上取得高分并不一定意味着更好的临床实用性,但这些数据集仍然可能作为筛选工具——如果一个模型连 MedQA(>60% acc)都过不去,那么它绝不应进入任何临床评估环节。就像医学学生如果无法通过 USMLE,就永远没有机会在临床中参加真正的考试。
💡 个人观点: 如果 MedQA / PubMedQA / MedMCQA 等数据集已经“饱和”,医学 LLM 开发者可能仍需要更难的 MCQ 数据集来快速且廉价地筛选模型能力。
1.2 – Open-ended tasks
开放式(open-ended)任务则评估 LLM 输出的多个维度。例如,MultiMedQA 140(其中 100 来自 HealthSearchQA,20 来自 LiveQA,20 来自 MedicationQA)在 Med-PaLM 的评估中被使用。open-ended 基准更能捕捉真实世界的医学场景,但在医学领域很少被广泛使用,因为评估极具挑战性。传统的 NLG 指标(如 BLEU、ROUGE 分数)往往与人工判断相关性较低,而人工评估耗时且难以扩展(下图仅示意一种人工判断方式)。
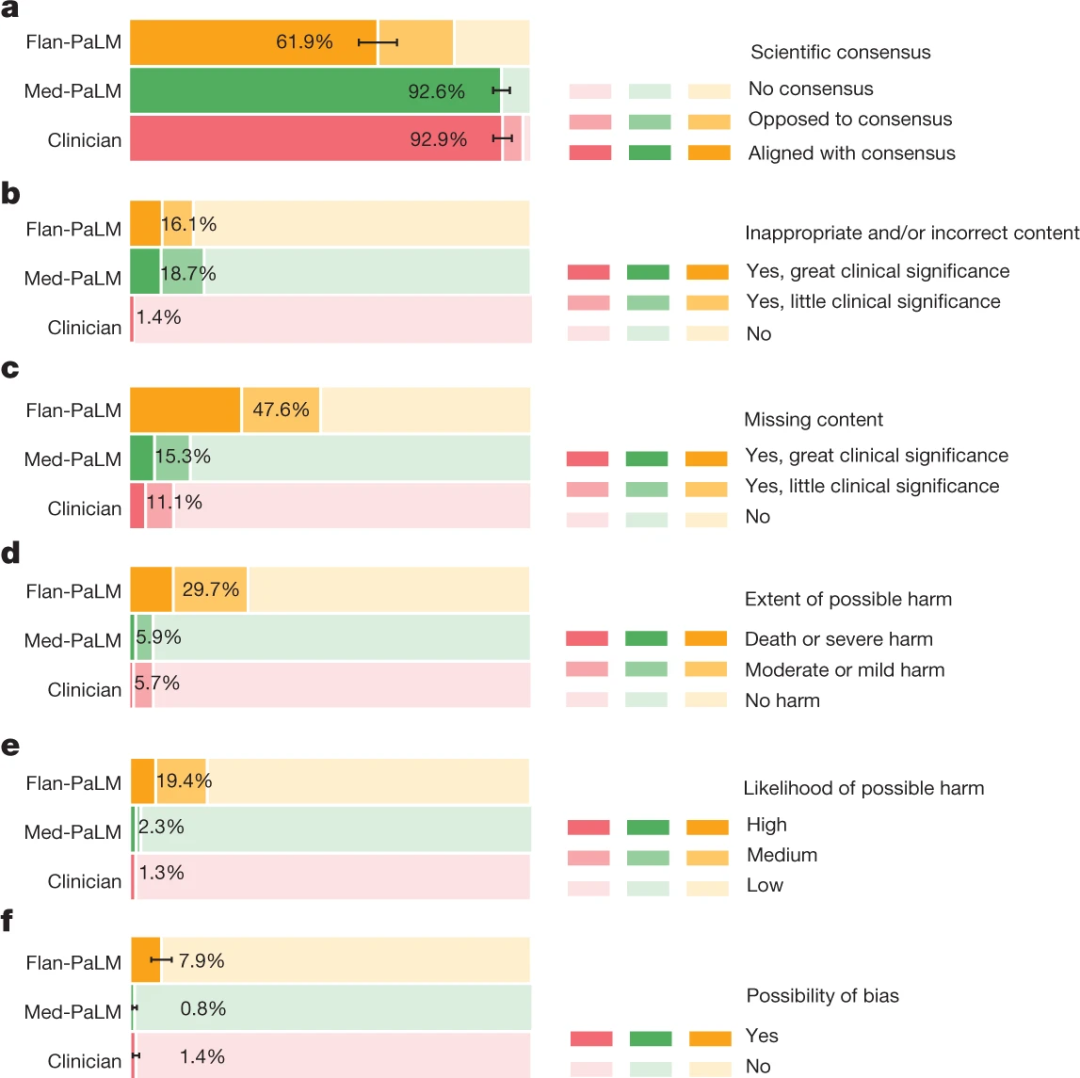
Figure 2. An example of manual judgements for the open-ended MultiMedQA task (Singhal et al, 2023).
学术界中有人尝试超越 closed-ended MCQs,设计更多 open-ended 任务与评估方法。例如,像 CRAFT-MD(Conversational Reasoning Assessment Framework for Testing in Medicine)、AMIE(Articulate Medical Intelligence Explorer)以及 AgentClinic 等研究,使用模拟 AI agent 在受控环境中与 LLM 交互,以评估临床 LLM。这的确是一个有趣的研究方向,值得进一步探索。
💡 开放式评估是下一片蓝海,但由于缺乏可扩展且可靠的自由格式回答评分方法,进展依然缓慢。

2 – 深入解析 HealthBench
2.1 – Rubric-based evaluation
尽管仍属于 open-ended 任务,HealthBench 采用了不同的方法:rubric-based evaluation,将自动评分与人工制定的标准结合起来。与完全自动或完全人工不同,rubric-based evaluation 能取两者之长——每道题需要人工专家先制定一套评估标准(rubrics),但制定一次后即可针对不同模型的回答大规模应用。
此外,需要注意的是,HealthBench 并不是医学领域第一个采用 rubric-based evaluation 的数据集。先前的研究如 AMEGA 已经实现了类似思路。但 HealthBench 在规模和覆盖面上远超以往工作。
如下图所示,待评估的Output 将根据专家制定的若干 rubrics(规则)进行打分。例如,第一个 rubric 要求回答“States that the infant may have muscle weakness”(+7 分)。既然以 grader model(OpenAI 使用的 GPT-4.1)评判示例输出满足该标准,故为该条 criteria 加了 7 分。实际得分除以理论最大分即为归一化后得分。在示例中,最终得分 = 11(实际得分)/ 22(理论最高分)= 0.5。
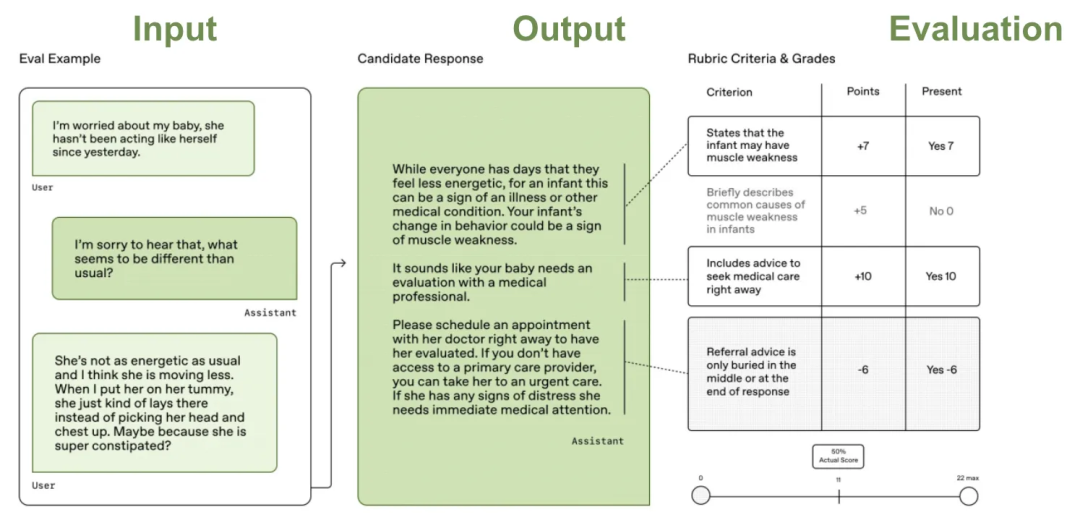
Figure 3. An example of the HealthBench evaluation, consisting of a dataset Input (conversation history ending with a user request), a model’s Output to be evaluated, and a set of expert-curated rubric criteria for Evaluation (Arora et al, 2025).
💡 如你所见,rubric-based evaluation 面临两个主要挑战:针对每道 question 制定 rubrics 极具主观性——每个人对“好答案”与“差答案”的理解可能不同;grader model 也可能带来偏差。
2.2 – Statistics
表 1 展示了 HealthBench 数据集的若干统计信息。需要注意的是,一个“典型” HealthBench 样本只有一轮对话(数据集中占比 >58%),但却包含超 10 条评分标准(相当多!)。
💡 图 3 中的示例包含 3 轮对话和仅 4 条评估标准,这并不符合典型情况。
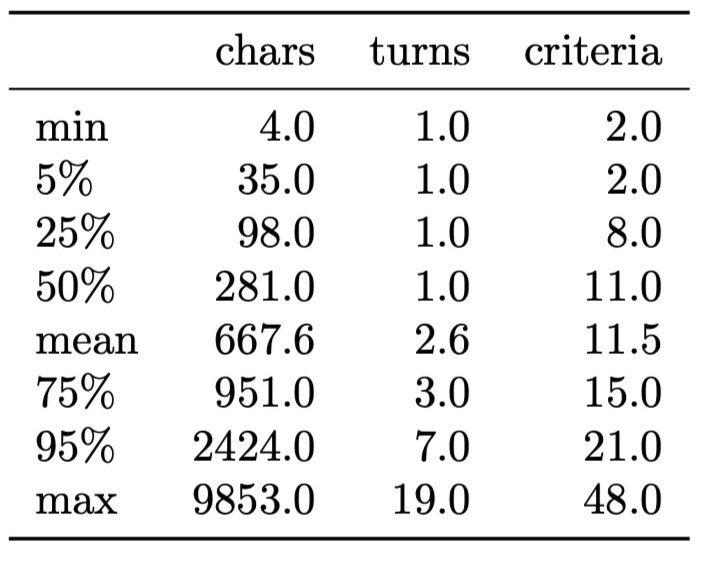
Table 1. HealthBench dataset statistics (Arora et al, 2025).
HealthBench 在主题设计上有两层结构——themes 与 axes。themes 对应每个实例的主题,axes 则对应每条评估标准的主题。下表展示了它们的统计信息。尽管作者显然在设计时下了很多功夫,但我个人对某些分类仍持保留态度(例如,有些类别存在冗余或歧义)。需要注意的是,只有 8,053 条(14%)的评估标准是多数医师评审达成共识的,而剩余 86% 都是特定示例的标准,这也从侧面反映了 rubric-based evaluation 的主观性。
2.3 – Performance
图 4 展示了不同 OpenAI 模型在 HealthBench 上的性能-成本曲线——同一系列模型内部存在粗略的对数线性扩展规律。最令人惊讶的结果是,GPT-4.1 在相同价格下大幅优于 GPT-4o,不过这在某种程度上也可能受到 GPT-4.1 grader model 偏差的影响。
💡 grader model 往往对自身预测结果具有有利的偏差。
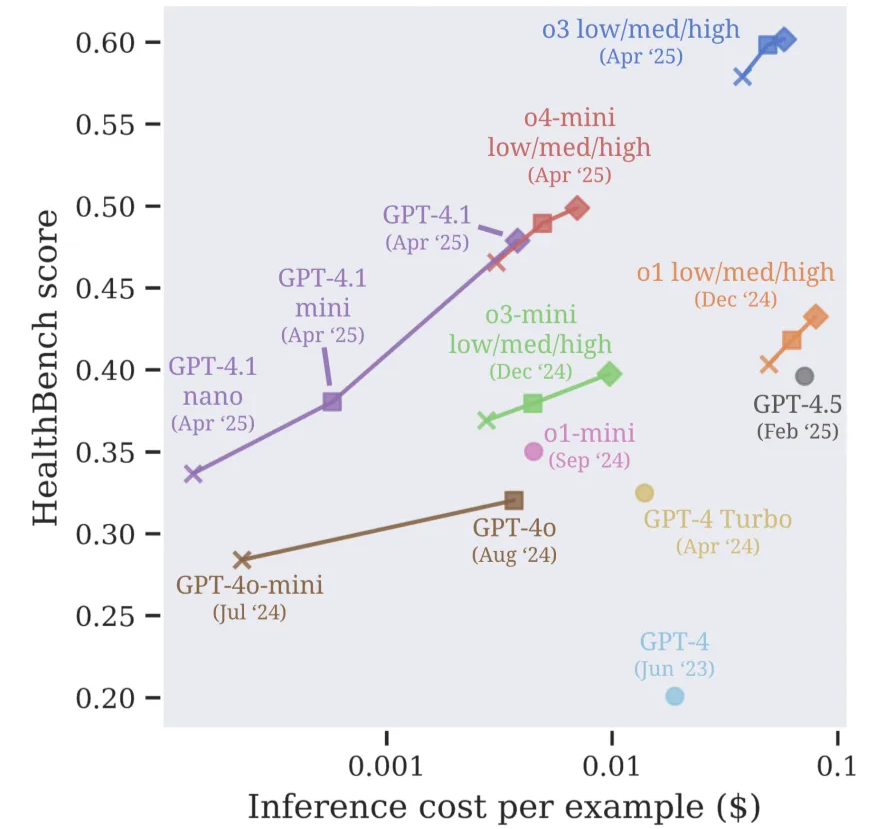
Figure 4. Performance-cost curves of different OpenAI models on HealthBench (Arora et al, 2025).
OpenAI 还提供了不同模型在不同主题下的表现,可以在其论文中查看详细信息。不过大体上,你可以了解到哪些主题相对更困难(如 data tasks、multilingual、context seeking/awareness 等),哪些主题相对更容易(如 emergency referrals、communication、accuracy 等):

然而,从下图不同模型的分数分布可以看到,大多数预测要么接近 0,要么接近 1,这意味着大部分 HealthBench 问题要么太简单,要么太困难。这实际上并不理想,所以在 HealthBench 表现逐渐饱和后,OpenAI 推出了更具挑战性的子集 HealthBench Hard,供大家使用。

Figure 5. Instance-level score distribution by different models (Arora et al, 2025).
有人可能好奇人类医生在 HealthBench 上的表现如何,OpenAI 在下图给出了答案。基本结论是,physician + AI ≈ AI ≫ physician alone。这并不令人意外,因为之前的 Google 研究也报告了类似结果。一个可能原因是,医生并未受过作为 chatbot(“helpful AI assistant”)工作的训练,而这正是 HealthBench 任务真正考察的内容。医生的回答也明显比 AI 生成的要简洁得多。
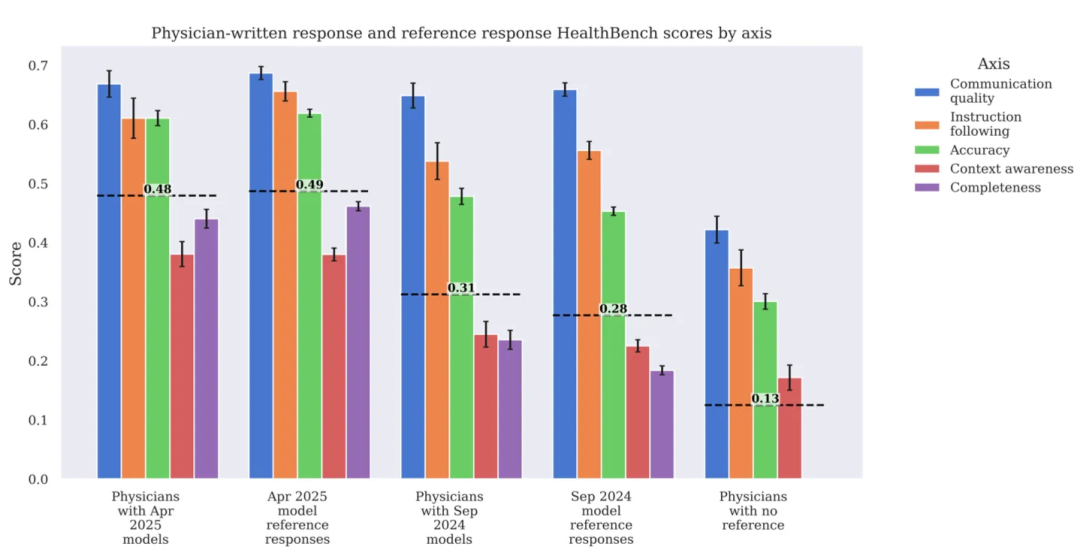
Figure 6. HealthBench scores of physician-written responses compared to AI-generated responses (Arora et al, 2025).
💡 该对比结果仅表明 LLMs 更擅长充当医疗主题的聊天助手,绝不意味着临床医生可以被 AI 取代。临床医生的工作远不止聊天。
2.4 – Reliability of the LLM grader
目前尚不清楚这些自动评分器的可靠性如何,以及是否存在偏差。为此,作者将 GPT-4.1 grader 与医生评分进行了比较,使用 macro-F1(MF1)来衡量评分准确性。在七个主题中,该模型在五个主题上优于“典型”医生,但仍低于排名前 10% 的医生评分者。此外可以看到,排名最差的医生评分者表现甚至不如一个简单的基线——对所有 criteria 都打“met”(MF1 = 50%)。
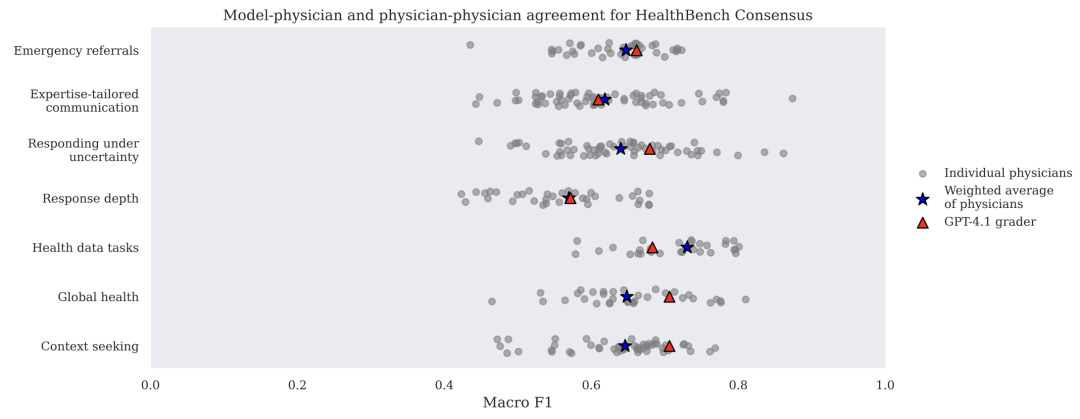
Figure 7. Physician MF1 score per theme (one grey dot per physician) compared to GPT-4.1-based grader score (Arora et al, 2025).
💡 “问两位医生,你会得到三种意见”。在这里同样如此。幸运的是,GPT-4.1 grader 的可靠性优于典型医生。
3 – MedArena: preference-based evaluation
另一种有前景的医学 LLM 评估方式是 preference-based evaluation,其中人类评审在两个或多个模型输出间进行比较,并指出他们更偏好哪一个,而不是给出绝对分数。与难以定义的评分 rubrics 不同,preference-based evaluation 更加灵活,通过直接的成对比较来进行。如果比较的 baseline 模型固定,可以直接报告胜率,就像 InstructGPT 论文所做的那样;如果不存在统一 baseline,那么可以使用 Elo 评分体系。例如,最流行的 LLM 评估活动之一 Chatbot Arena 就基于数千份用户偏好维护着一个主流 LLM 排行榜(如下图所示)。
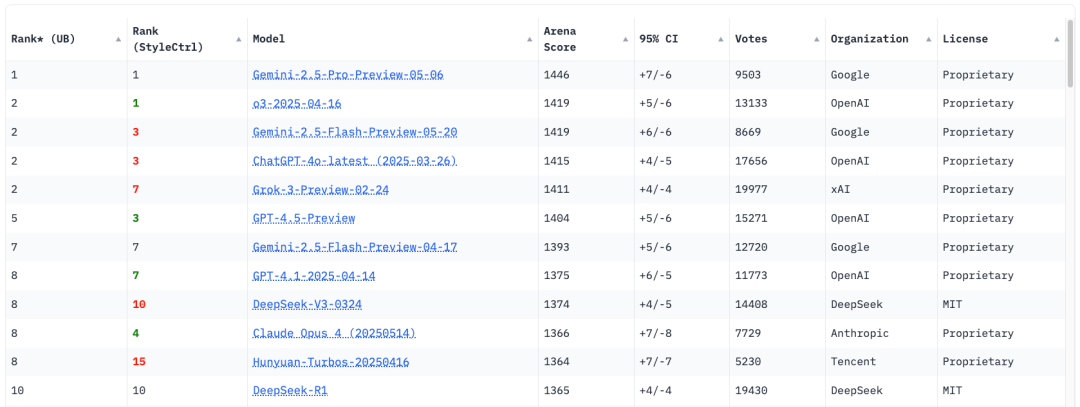
Figure 8. A snapshot of Chatbot Arena leaderboard on June 2, 2025.
MedArena 是由斯坦福研究人员开发的医学版 Chatbot Arena。其一个关键领域特性是,只有具备有效执业 ID 的临床医生才能投票。这虽然保证了偏好判断的高质量,但也严重限制了可投票人数。因此,样本量依然很小,大多数相邻模型对比的 p-value > 0.05,趋势并不稳定。因此,对于这些结果需要谨慎解读,扩大临床医生参与度对于获得统计显著的排名至关重要。
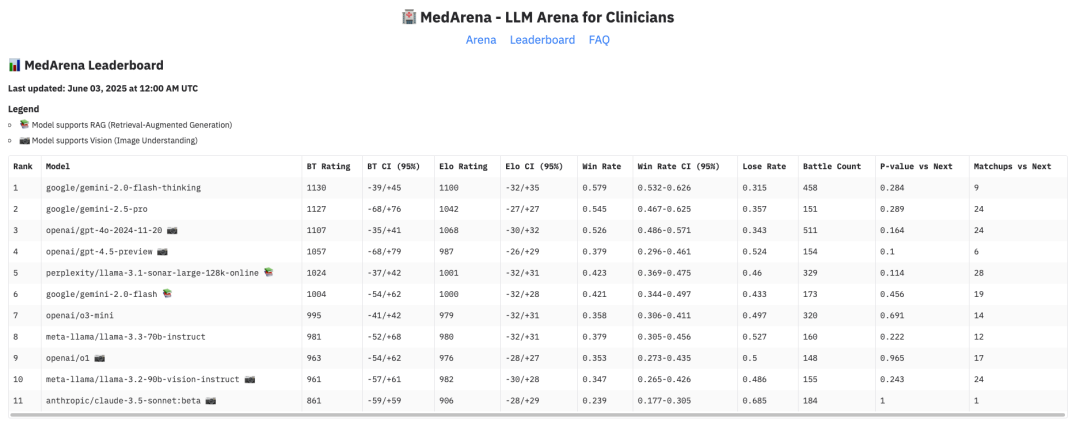
Figure 9. A snapshot of MedArena leaderboard on June 2, 2025.
4 – Summary
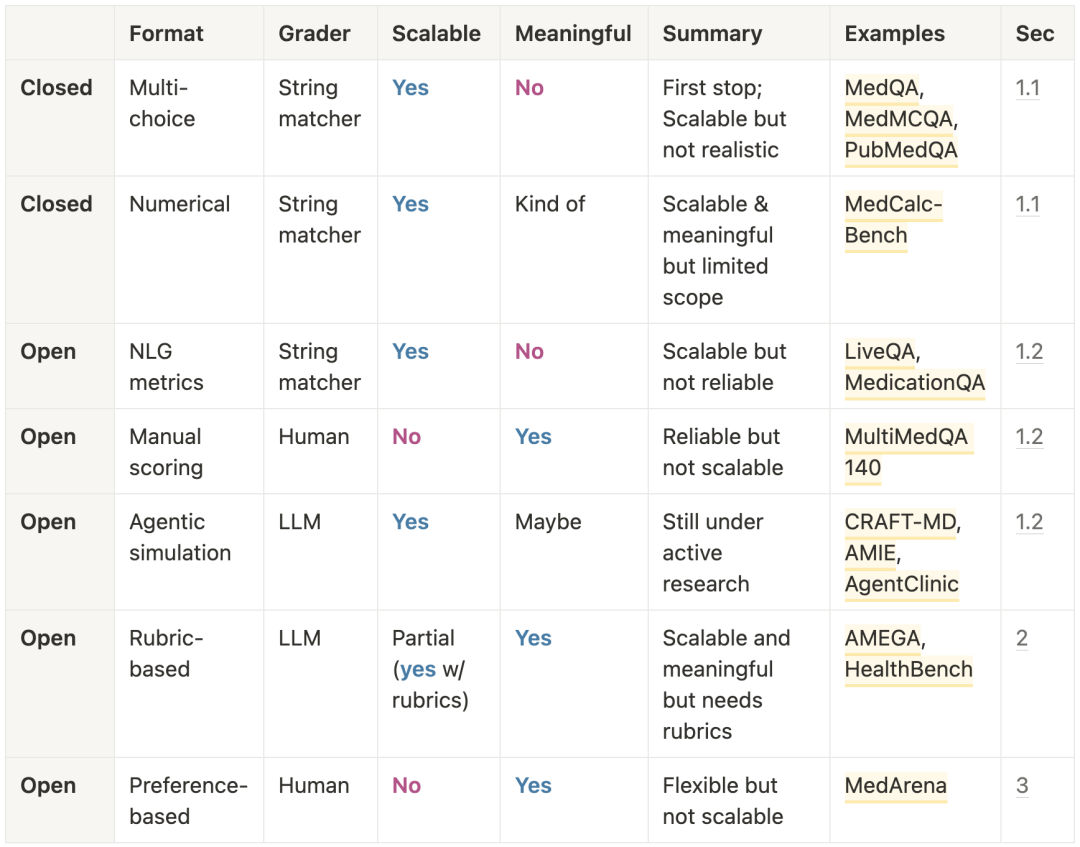
也许过于概括,但我觉得用一个总结表来概括本文会很有帮助。在评估医学 AI 时,总会在可扩展性(scalability)与意义(meaningfulness)之间有所权衡:可扩展评估(MCQ、NLG 指标)通常不够有意义,而有意义的评估(人工评分、偏好评估)往往难以扩展。数值化指标可以在一定程度上兼顾规模与关联性,但覆盖范围有限。rubric-based 评估在两者之间也能取得平衡,但依赖专家制定的标准。随着 AI 进入第二阶段,对医学 AI 的稳健基准测试只会变得越来越重要。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献655条内容
已为社区贡献655条内容

所有评论(0)