ConceptFormer:在大型语言模型中高效使用知识图谱嵌入的方法
检索增强生成(RAG)在过去一段时间内受到了越来越多的关注,最近大型语言模型(LLMs)的发展突显了将世界知识整合到这些系统中的重要性。当前的RAG方法通常会修改预训练语言模型(PLMs)的内部架构或依赖于文本化知识图谱(KGs),这在标记使用上是低效的。本文介绍了ConceptFormer,这是一种新的方法,可以在不改变其内部结构或依赖于KG的文本输入的情况下,将来自KGs(如Wikidata)
Joel Barmettler
joel.barmettler@uzh.ch
University of Zurich
Zurich, Switzerland
Abraham Bernstein
bernstein@ifi.uzh.ch
University of Zurich
Zurich, Switzerland
Luca Rossetto
luca.rossetto@dcu.ie
Dublin City University
Dublin, Ireland
摘要
检索增强生成(RAG)在过去一段时间内受到了越来越多的关注,最近大型语言模型(LLMs)的发展突显了将世界知识整合到这些系统中的重要性。当前的RAG方法通常会修改预训练语言模型(PLMs)的内部架构或依赖于文本化知识图谱(KGs),这在标记使用上是低效的。本文介绍了ConceptFormer,这是一种新的方法,可以在不改变其内部结构或依赖于KG的文本输入的情况下,将来自KGs(如Wikidata)的结构化知识增强到LLMs中。ConceptFormer在LLM嵌入向量空间中运行,创建并注入概念向量,这些向量直接封装了KG节点的信息。与冻结的LLM一起训练时,ConceptFormer生成了一个全面的查找表,该表将KG节点映射到各自的概念向量。这种方法旨在通过使LLMs能够以本地方式处理这些概念向量来增强其事实回忆能力,从而以高效和可扩展的方式丰富它们的结构化世界知识。我们的实验表明,在Wikipedia句子上测试时,添加概念向量到GPT-2 0.1B可以将其事实回忆能力(Hit@10)提高至多272%,而在合成生成的句子上则可提高至多348%。即使只在提示中注入一个概念向量,也可以将Wikipedia句子的事实回忆能力(Hit@10)提高至多213%,显著优于基于图形文本化的RAG方法,同时使用的输入标记少130倍。
CCS概念
- 计算方法 → 知识表示和推理;·信息系统 → 数据编码和规范化;语言模型。
关键词
检索增强生成,知识图谱嵌入,知识注入
1 引言
大型语言模型(LLMs)在各种自然语言处理任务中表现出非凡的潜力,包括对话代理、摘要和信息检索(IR)。它们通常在大规模、通用(文本)语料库上进行训练,并通过自我监督目标进行优化[21]。通过这种预训练,LLMs获取了大量的知识,这些知识隐含地存储在其模型权重中[38, 56]。然而,这种隐式存储可能导致知识检索效率低下,并存在过时、有偏见或不完整信息的风险,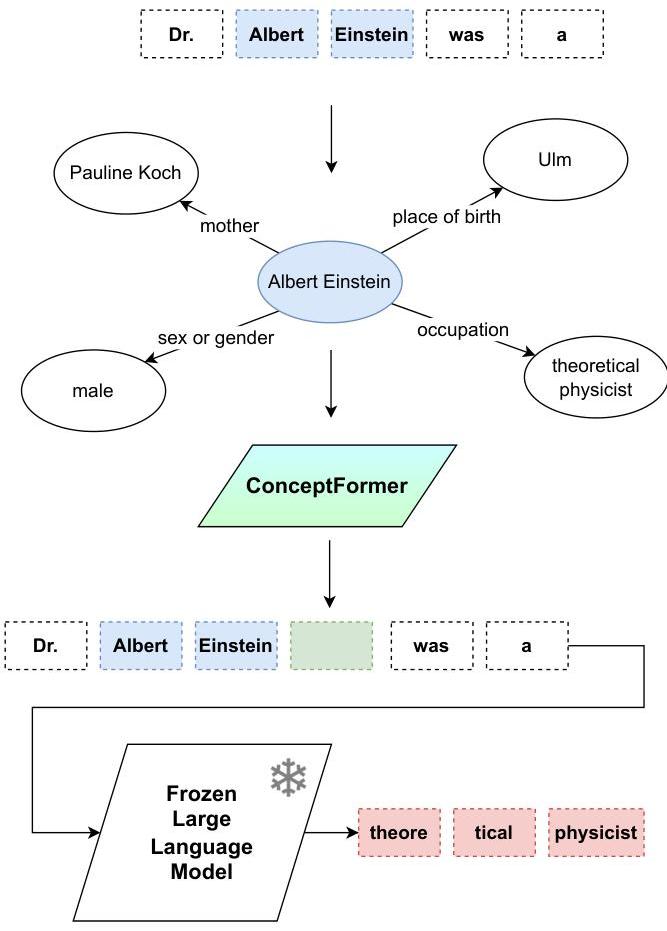
图1:ConceptFormer通过从原始提示的嵌入向量扩展出学习到的概念向量来增强提示。实体识别和实体链接用于检测原始提示中的实体“Albert Einstein”(用蓝色显示)并将其链接到大型KG如Wikidata。ConceptFormer为检测到的实体创建一个与LLMs输入嵌入空间兼容的向量嵌入。生成的概念向量(用绿色显示)显示出比单独的原始标记嵌入向量更能捕捉实体的本质,从而使LLM生成的知识更丰富的输出(用红色显示)。
对检索增强生成(RAG)和知识密集型IR任务构成了关键障碍[20, 25, 28]。
一种常见的增强LLMs知识保留的方法是通过语料库策划或扩展,这种方法已被证明可以减少幻觉[13, 46]。但是,仅仅改进或扩大训练语料库并不总是能解决深层IR挑战,例如特定领域的知识检索或实时更新[14, 43]。模型仍然经常产生幻觉或遗漏关键事实[29, 35],尤其是在不可避免领域变化的专业领域中[47]。研究表明,增加LLMs的参数数量可以改善事实回忆[18],但即使是像ChatGPT这样的大型模型在从DBPedia等来源准确检索和表达结构化知识方面仍面临困难[40, 51]。这些困难反映了更广泛的IR问题:系统无法有效检索相关概念会阻碍下游任务,如问答、推荐和对话搜索。
为了应对知识密集场景中的这些挑战,知识图谱(KGs)[16, 30]已成为有价值的结构化资源。像Wikidata [45]这样的KG捕获了准确、最新且领域丰富的事实信息。使这种基于图的知识可供LLMs访问是IR研究中的长期目标,特别是对于检索增强生成和问答[1, 53]。流行的RAG重点方法通常依赖于“文本化”图边或节点[10, 22],并将它们连接到LLM提示中。虽然有效,但此策略消耗了模型上下文窗口的大部分内容,并可能引入噪声[55]。
考虑一个必须回答用户关于小众话题(例如,“阿尔伯特·爱因斯坦著名留的是哪种胡子?”)查询的对话IR系统。如果系统被迫每次都将数百个描述KG邻居的标记文本输入LLM提示中,它可能会遇到上下文限制或淹没在无关细节中。另一种方法是以更紧凑的形式嵌入这种知识,将其无缝集成到用户的查询中,进入LLM的嵌入空间。这种解决方案不仅可以节省标记,还可以产生更精确的检索结果,反映核心IR主题:在准确性与效率之间取得平衡。
本文中,我们介绍了一种名为ConceptFormer的新颖、标记高效的将KG集成到任何预训练LLM中的方法,而无需修改其内部架构或重新训练其核心参数。ConceptFormer不是将知识文本化,而是将从KG派生的概念向量直接注入LLM的输入嵌入空间。图1说明了实体识别如何将文本提及(“阿尔伯特·爱因斯坦”)链接到相应的Wikidata节点,以及ConceptFormer如何学习生成少量密集的概念向量以增强或替换朴素的标记嵌入。这些向量本机编码最相关的图邻域信息,使LLM能够在最小上下文开销的情况下集成结构化知识。
本文的贡献有三方面:(1) 我们提出了ConceptFormer,一种灵活的机制,将KG节点嵌入LLM提示空间,使得在不需要更改LLM架构的情况下实现需要大规模或特定领域事实检索的IR场景成为可能。(2) 我们引入了新数据集-Tri-REx、T-REx Bite和T-REx Star,专门设计用于评估下一个标记和事实回忆任务。这些数据集有助于衡量LLM检索、重新排名和生成实体级事实的能力。(3) 我们实证展示了ConceptFormer在合成句子上的事实回忆(Hit@10)提高了高达348%\mathbf{3 4 8 \%}348%,在基于Wikipedia的句子上提高了高达272%272 \%272%,相较于GPT-2 0.1B基线。值得注意的是,即使单个概念向量也能提供具有竞争力的回忆提升,同时消耗的标记比基于文本的RAG少130×130 \times130×。我们免费提供了所有数据集、我们的实现1{ }^{1}1和预训练模型[2]供下载。
尽管大多数增强KG的LLM研究聚焦于知识的文本表示[26, 41, 54],我们专注于压缩图信息直接进入LLM输入空间的向量注入方法。由于其相对较小的规模和简单的架构,我们特意选择了GPT-2 0.1B [37]进行实验。然而,这项技术可以通过最小调整扩展到更大的LM。
我们在论文其余部分的结构如下:第2节调查了检索增强生成、提示调优和知识图增强的相关方法。第3节描述了新引入的数据集及其与IR任务的对齐情况。第4节详细介绍了ConceptFormer架构、其训练过程以及如何将压缩的KG嵌入注入提示中。第5节展示了广泛的实验结果,包括与RAG基线的比较、标记使用的分析和问答场景。第6节总结了对基于检索的LLM应用的影响和未来工作。
通过展示一种保持LLM原始权重的知识注入的向量中心方法,我们希望激励进一步的基于KG的IR研究,以实现知识密集型生成任务的有效、最新的检索。
2 相关工作
ConceptFormer交叉涉及多个与大型语言模型(LLMs)存在下信息检索(IR)的核心研究领域。我们将我们的工作置于(i)检索增强生成(RAG),(ii) KG增强的LLMs,(iii)标记压缩或“概要”,(iv) 提示调优,以及(v) 多模态或专业化概念的伪词嵌入的研究领域中。
检索增强生成(RAG)。检索增强生成(RAG)[12, 20]通过在或在文本生成过程中检索相关外部数据来增强基于LLM的文本生成,从而将模型输出建立在来自结构化或非结构化来源的事实信息之上。在传统的IR管道中,这种方法类似于查询扩展或情境化:用户查询(或部分文本)被检索到的文档所增强,使LLM能够生成更准确反映检索证据的内容。
一个简单却强大的变体是图文本化,其中知识图(KG)被线性化为文本模板[10]。例如,每个主语-谓语-宾语三元组都可以转换成一个文本短语并与用户查询串联。Brate等人[7]和Li等人[22]的工作依赖于这些文本扩展来利用LLM生成过程中的结构化知识。尽管有效,这种策略常常施加沉重的标记开销,拉伸上下文窗口并在涉及许多图边时引入潜在的噪音。
相比之下,ConceptFormer避免文本化知识。与其插入数百个描述KG邻域的标记,它将KG节点(及其邻接信息)转换为一组小型密集的学习向量,直接注入LLM的嵌入空间。这显著减少了上下文使用,同时保留了检索和集成基于图的证据的能力。
KG增强的LLMs用于IR。除了RAG之外,多条研究路线旨在将KG信息集成到LLM的表示中。早期工作通常需要广泛的架构修改或额外的训练头。例如:DKPLM[54]通过知识提取和伪标记注入动态更新语言模型,修改模型层并解冻网络的一部分。CoLAKE[41]构建混合单词-知识图,并修改Transformer的嵌入和编码器层,从头开始训练LLM。K-Bert[26]、KnowBert[32]和KP-PLM[48]各提出新的注意力或注入层,部分或完全覆盖模型的内部架构。K-Adapter[50]附加专注于某些类型知识的适配器。虽然这些方法有效地增强了带有结构化知识的LLM,但大多数都是针对仅编码器模型(如BERT)定制的,或者需要部分微调LLM。这在RAG部署中复杂化了他们的使用,因为人们可能更喜欢保持大规模预训练模型不变以保留现有能力。
ConceptFormer与这些方法在目标上一致——使KG信息对LLM可用——但在严格输入嵌入级别操作,保留了仅解码器LLM的基本架构。在RAG场景中,具有最少推理内存或偏好即插即用模块时,ConceptFormer可以以非侵入性方式与标准LLM结合。此外,其概念向量可以预先计算并存储以快速检索,消除重建图邻居的推理开销。
概括和提示压缩。概括调优[31]将长提示压缩为更紧凑的“概括标记”。类似于知识文本化,大提示扩展可能在依赖大量背景段落的任务中降低性能或超出上下文限制。通过训练一个压缩器生成一序列可学习的标记,概括调优减少了所需的标记数量,通常保持高质量生成。
将大量文本压缩为最小嵌入的想法与ConceptFormer相呼应,后者将整个KG邻域表达为几个概念向量。而不是详述文本扩展,ConceptFormer形成实体局部子图的高层次“概括”。这在基于检索的LLM用例中特别有益:上下文窗口留给用户查询或额外数据,但LLM仍能访问结构化知识。
提示调优和连续提示。提示调优方法[23, 27, 36]冻结LLM的大部分或全部参数,引入连续嵌入(“前缀向量”或“软提示”)来引导模型的行为。这不同于典型的微调,后者更新模型的内部权重,可能导致灾难性的遗忘原有功能。对于涉及
许多特定领域扩展或多样化子任务的IR任务,保留LLM的核心权重可能是有利的。
ConceptFormer扩展了这一范式:它不是编码通用样式或指令,而是注入实体为中心的知识。每个KG节点都伴随一个或多个学习到的嵌入向量,存储局部关系背景。这类似于“软提示”,但具体针对RAG设置中的知识注入。
专业化概念的伪词。相关的一条研究脉络通过在模型的输入空间中插入“伪词”来解决LLMs中新概念获取的问题。在多模态或领域适应背景下,这些伪标记可以代表例如新颖的视觉概念[11, 44]或领域特定术语。其想法是将新的语义附加到其他未使用的标记嵌入上,使模型在生成过程中能够集成或引用该概念。
ConceptFormer类似地通过密集向量表示新概念(KG实体),但它专注于子图级知识,而不仅仅是图像或单一领域标签。通过将整个实体邻域映射为几个向量,它在压缩嵌入中保留了关系结构。这种局部图信息和标记空间注入的协同作用允许LLMs更准确地回忆与IR任务(如实体为中心的问答、知识基础摘要或领域定向检索)相关的事实联系。
3 数据集
信息检索任务通常需要评估模型是否能够检索正确的知识片段,并将其响应基于准确的事实。大型语言模型通常从融合语言和事实内容的大规模语料库(如维基百科)中学习,但当目标是注入新事实或系统测量模型在受控方式下回忆或生成事实信息的有效性时,这些语料库往往不够理想。
为了解决这个问题,我们引入了三个数据集-T-REx Bite、Tri-REx和T-REx Star,这些数据集建立在 TTT REx数据集[9]的基础之上。虽然T-REx将维基百科句子链接到维基数据三元组,但它并不是专门为下一个标记预测设计的。相比之下,我们的数据集提供了明确的结构,便于知识注入和基于检索的LLM评估,解决了T-REx及其基于LAMA的扩展[33, 34]的关键局限性。这些局限性包括单标记对象的假设、知识覆盖率不均以及与仅解码器LLM在IR环境中常用的需求不符。
3.1 T-REx Bite
T-REx Bite [3] 通过对每个文本片段确保主体出现在对象之前,将T-REx改编为下一个标记预测范式。这种对齐模拟了现实世界中的情景,即模型看到部分信息(主体和一些上下文),然后必须预测或“检索”缺失的对象。为了使片段在较小语言模型(如GPT-2)的有限上下文窗口内可控,每个片段限制为512个字符。我们进一步要求片段明确提及主体和对象,不以对象开始新句子,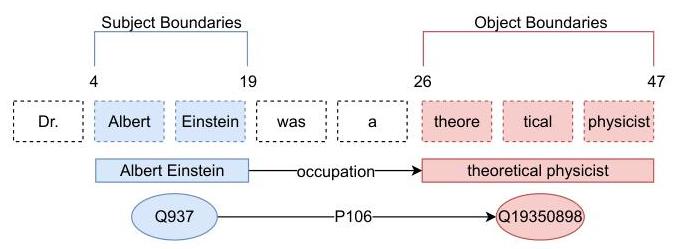
图2:来自Tri-REx(合成)数据集的示例数据点。该数据点由主要句子(s)、提及的维基数据三元组信息以及句子中实体标签位置的边界指示组成。
并且与T-REx Star中的相应子图链接(见第3.3节)。
通过应用这些约束条件,我们获得了约640万个短“咬合”用于训练,92万个用于测试,以及75万个用于验证。每个“咬合”是一个紧凑的维基百科文本片段,保留了T-REx原有的清晰度和多样性,但经过调整以确保直接的主客体对齐。这种结构让研究人员能够轻松评估LLM在给定前置主语后完成对象标记的能力。该数据集自然容纳现代子词标记下的多标记对象,去除了LAMA类方法的单标记假设。
3.2 Tri-REx
尽管T-REx Bite很有用,但它仍然依赖于许多模型在预训练阶段可能部分见过的维基百科文本。为了创建一个没有这种潜在污染的情景,我们引入了Tri-REx [5]。Tri-REx 不是从维基百科提取文本,而是使用Mistral 7B [17] 以少量示例提示的方式合成简短的主题-谓词-宾语句子。例如,三元组(阿尔伯特·爱因斯坦,面部毛发,海象胡须)可能会生成“阿尔伯特·爱因斯坦博士留着浓密的海象胡须。” 每个生成的句子都会自动过滤以确保连贯性、正确提及主体和对象,并准确保存S-P-O关系,从而生成高质量的合成数据。图2给出了Tri-REx的一个数据点示例。
Tri-REx 包含2150万条训练句子、90万条测试句子和170万条验证句子,每条句子通常少于30个标记。这个集合之所以突出,是因为它有意避免了预训练重叠:模型不能仅仅依赖记忆的维基百科文本。相反,它们必须学习或利用新提供的知识源(例如ConceptFormer的概念向量)来在下一个标记预测期间恢复正确的对象标记。因此,研究人员可以验证RAG技术或知识注入方法是否确实向模型传达了事实,而不仅仅是触发了记忆文本的回忆。
3.3 T-REx Star
虽然T-REx Bite 和 Tri-REx 侧重于文本输入,但它们并未明确嵌入将主体实体与其邻居连接起来的更广泛图结构。T-REx Star [4] 填补了这一空白,提供
来自Wikidata的星形拓扑子图,适用于T-REx中作为主体出现的每个实体。每个实体的局部子图以JSON格式表示,包含多达100个按PageRank [42]排序的邻居,并存储节点(Q-ID、英文标签、PageRank)和边(PID、关系标签)元数据。JSON结构可以轻松加载到如NetworkX [15]之类的工具中,以进行进一步的基于图的处理或嵌入。
至关重要的是,T-REx Star 通过使用一致的划分方案与T-REx Bite 和 Tri-REx 对齐。在三个数据集中任一作为主体出现的每个实体都恰好出现在一个划分(训练、验证或测试)中。尽管如此,如果实体是不同主体的邻居,则可以在多个划分中作为对象出现。这种一致性对于公平比较LLM在训练和评估集之间的表现非常重要。
3.4 对IR的相关性和实用性
通过设计,这三个数据集相互补充,支持广泛的IR驱动研究:
T-REx Bite 保留了原始维基百科文本的自然性。它适合于主体-对象对出现在真实语言环境中的实际RAG设置。在T-REx Bite上评估下一个标记预测揭示了模型在不超出现实上下文限制的情况下填充事实对象的能力。
Tri-REx 通过为每个实体-邻居对合成新的S-PO句子避免了潜在的污染。因此,它将学习和评估严格集中在外部提供的事实上,这是测量知识注入方法如何将新或特定领域的信息注入LLM的理想设置。
T-REx Star 明确包含了每个实体周围的Wikidata结构,使研究如何通过局部图邻域影响检索增强LLM的使用成为可能。像ConceptFormer这样的系统可以将这些子图高效地注入为一小套学习嵌入,而不是将它们文本化。
这三个数据集基于主体划分共享一致的训练、验证和测试拆分,确保在知识检索和生成任务中进行受控实验。这些资源与本工作一同公开发布,以促进无需过度依赖文本扩展即可将结构化知识整合到LLMs中的新方法。通过提供自然和合成数据,无论是否明确包含KG邻域,这些资源旨在推动IR系统如何利用知识注入进行下一个标记和事实回忆评估的边界。
4 方法
ConceptFormer旨在在不改变LLM内部架构的情况下,将紧凑的基于图的知识注入到大型语言模型(LLM)中。在信息检索的背景下,这种设计选择是至关重要的:大型预训练模型通常由于计算限制或担心灾难性遗忘而“原样”部署。通过纯粹在输入嵌入级别操作,ConceptFormer无缝地与大多数仅解码器的LLM集成,并可以在检索增强生成、实体为中心的搜索或特定领域的IR管道中灵活应用。
总体而言,ConceptFormer可以被视为一个模块化的知识注入器:
(1)实体检测和链接:给定用户查询或部分文本(例如,“阿尔伯特·爱因斯坦是一位…”),现成的命名实体识别(NER)和实体链接器识别“阿尔伯特·爱因斯坦”并检索其在Wikidata或其他KG中的对应节点ID(Q_ID)。
(2)子图提取:获取围绕实体的星形拓扑子图,包含其直接邻居和连接它们的边(谓词)。在我们的实验($3)中,子图是从T-REx Star预先提取的。
(3)ConceptFormer向量生成:提取的节点和边嵌入被输入到ConceptFormer中,生成捕捉局部邻域的概念向量。
(4)提示扩展:这些概念向量被附加到主体的现有输入嵌入中,形成更丰富的表示,LLM本机处理(图3)。
此过程允许LLM以最小的提示开销纳入结构化图知识。与将大量文本扩展(有时数百个标记)连接到提示的基于文本的RAG方法不同,ConceptFormer只为每个实体插入nnn个向量——其中nnn通常小得多(例如,1到20个向量)。因此,它显著减少了上下文消耗,为用户文本或系统指令腾出了标记,在实际的RAG场景中非常有用。
4.1 ConceptFormer架构
ConceptFormer以锚定在中央实体上的星形拓扑子图为输入,我们将其表示为CCC。该实体有mmm个邻居N1,…,NmN_{1}, \ldots, N_{m}N1,…,Nm和对应的边(谓词)嵌入E1,…,EmE_{1}, \ldots, E_{m}E1,…,Em。正式地,每个邻居NiN_{i}Ni是一个固定维度的向量(例如,768 D),表示邻居的标签或文本描述,每条边EiE_{i}Ei同样被嵌入。这些嵌入可以使用现成的文本嵌入模型(例如,GPT-2,Word2Vec)或专用方法如TransE [6] 或PBG [19]得出。
按照Liang等人的方法 [24],我们将(i)节点/边嵌入步骤与(ii)对齐和压缩步骤分开。前者产生C,N,EC, N, EC,N,E,维度为dimi\operatorname{dim}_{i}dimi,后者是ConceptFormer的可训练参数所在之处。
ConceptFormer实现了nnn个并行的概念向量生成块。每个生成器通过线性层学习Key (Kn)\left(K_{n}\right)(Kn)、Query (Qn)\left(Q_{n}\right)(Qn)、Value (Vn)\left(V_{n}\right)(Vn)和Output (On)\left(O_{n}\right)(On)变换,权重为WnQ,WnS,WnVW_{n}^{Q}, W_{n}^{S}, W_{n}^{V}WnQ,WnS,WnV和WnOW_{n}^{O}WnO。每个概念注意力层的输出是一个中间概念向量(1,dimi)\left(1, \operatorname{dim}_{i}\right)(1,dimi),详见方程1-4。
每个OnO_{n}On随后通过所有概念注意力生成器共享的输出变换进行处理,以生成最终的概念向量,详见方程5。这种变换对于将概念向量转换为与LLM输入空间兼容的格式至关重要,其他论文也采用这种技术来弥合TransE等图表示和LLM文本嵌入之间的差距[57]。该层的输出维度dimo\operatorname{dim}_{o}dimo由LLM使用的输入标记嵌入定义。其隐藏维度是一个自由参数,在我们的实验中设置为1228。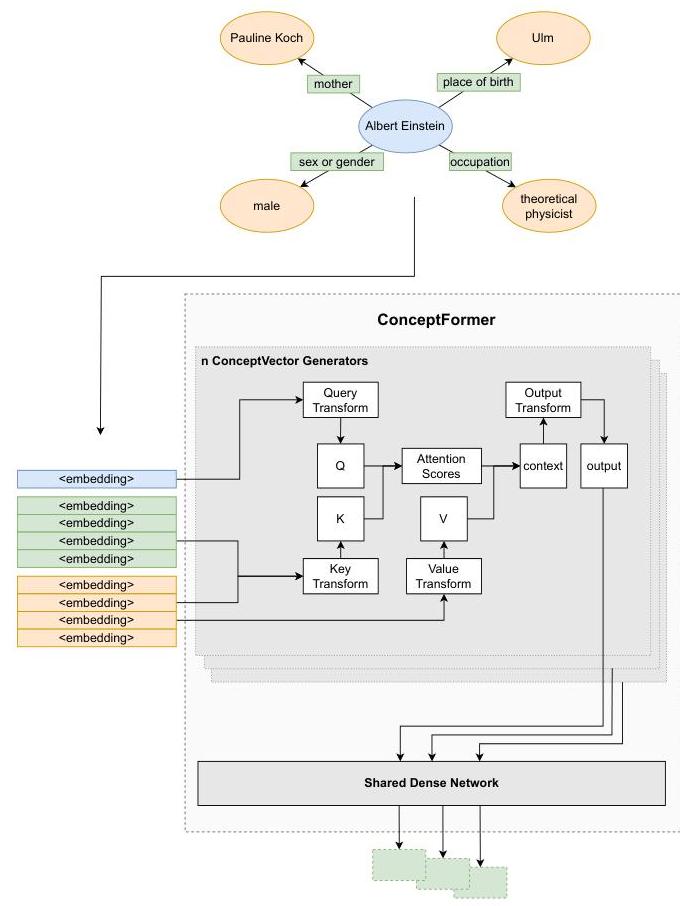
图3:ConceptFormer的输入是三个矩阵,分别表示中心节点、相邻节点和连接边。这些嵌入可以通过多种文本嵌入机制生成。在我们的工作中,我们通过将它们的标签通过LLM并平均最后一层隐藏层来生成节点和边嵌入。ConceptFormer训练多个并行且完全独立的概念向量生成块,每个块都实现了一个注意力机制,其中中心节点变为查询Q\mathbf{Q}Q,拼接后的相邻节点和对应的边变为键K\mathbf{K}K,相邻节点变为值V。最后,共享的密集网络将每个概念向量生成块的输出转换为LLM的输入嵌入空间。
Qn=CWnQKn=NWnK+EVn=NWnVOn=(softmax(QnKnTdimi)Vn)WnO concept vector n=LeakyReLu(OnW1P)W2P \begin{aligned} Q_{n} & =C W_{n}^{Q} \\ K_{n} & =N W_{n}^{K}+E \\ V_{n} & =N W_{n}^{V} \\ O_{n} & =\left(\operatorname{softmax}\left(\frac{Q_{n} K_{n}^{T}}{\sqrt{\operatorname{dim}_{i}}}\right) V_{n}\right) W_{n}^{O} \\ \text { concept vector }_{n} & =\operatorname{LeakyReLu}\left(O_{n} W_{1}^{P}\right) W_{2}^{P} \end{aligned} QnKnVnOn concept vector n=CWnQ=NWnK+E=NWnV=(softmax(dimiQnKnT)Vn)WnO=LeakyReLu(OnW1P)W2P
ConceptFormer可以微调以适应新的LLM,使其成为一个多功能工具,可以与各种语言模型集成。ConceptFormer的输出是一组nnn个概念向量,形成大小为(n,dimn)\left(n, \operatorname{dim}_{n}\right)(n,dimn)的矩阵。这个矩阵表示从输入子图转换来的知识,准备输入LLM以丰富语言生成。
4.2 训练目标和阶段
我们首先在Tri-REx ($3) 的合成句子上训练ConceptFormer,这些句子刻意不被基础LLM见过。这确保了LLM不能简单地从记忆的文本模式中预测出正确的对象。换句话说,它必须依赖于概念向量中嵌入的知识。对于每个形式为"[Subject] … [Predicate] … [Object]"的合成句子:
(1) 我们在[Object]之前截断句子。
(2) 从T-REx Star检索[Subject]的星形子图,使用ConceptFormer生成nnn个概念向量,并将其插入原始[Subject]文本嵌入向量之后。
(3) LLM被赋予下一个标记预测任务[Object],最小化跨熵损失在真实标记上。
由于LLM是冻结的,梯度更新仅影响ConceptFormer参数。通过重复批次,ConceptFormer学会以帮助LLM正确预测对象标记的方式编码子图,尽管LLM本身没有在这些未见过的事实上进行微调。
在预训练之后,我们进一步使用T-Rex Bite的真实世界文本细化ConceptFormer,确保它从合成领域转移到更自然、上下文丰富的句子。这个第二阶段是至关重要的,以避免过于简单地依赖“三元组模式”。
- 我们在从维基百科截取的真实句子上应用相同的下一个标记预测目标,参考相同的实体子图。
-
- 概念向量必须适应真实的维基百科文本的多样性和更嘈杂的风格,而不是整齐结构化的合成陈述。
这种两阶段训练(合成 → 真实文本)在我们的实验($5)中已证明有效,允许ConceptFormer处理从短事实查询到更复杂的、上下文依赖的查询等各种RAG使用案例。
- 概念向量必须适应真实的维基百科文本的多样性和更嘈杂的风格,而不是整齐结构化的合成陈述。
4.3 实现细节和训练超参数
在我们的实验中,每个概念向量生成块使用维度为dimi→dimi\operatorname{dim}_{i} \rightarrow \operatorname{dim}_{i}dimi→dimi的线性变换,其中dimi\operatorname{dim}_{i}dimi通常为768。后续的MLP有一个尺寸为1228的隐藏层,使用LeakyReLU激活函数。我们改变了并行块的数量n∈{1,2,3,4,5,10,15,20}n \in\{1,2,3,4,5,10,15,20\}n∈{1,2,3,4,5,10,15,20},在性能和内存开销之间进行权衡。我们采用了AdamW,权重衰减为0.01和恒定学习率,通常为6×10−56 \times 10^{-5}6×10−5,通过网格或贝叶斯超参数搜索确定。我们冻结了所有LLM权重,确保ConceptFormer的稳定优化。
我们批量处理多个子图和部分句子,限制每个的最大标记长度(例如,512),以保证与GPT-2兼容。如果在合成或真实数据阶段的验证损失在一个完整周期后没有改善,我们就提前停止,以防止过度拟合狭窄模式。一旦训练完成,ConceptFormer可以以两种方式使用:
(1) 实时生成:对于推理过程中遇到的每个实体提及,动态检索其子图并通过ConceptFormer生成概念向量。这支持实时更新,如果KG频繁变化,但需要额外的推理计算。
(2) 预计算查找表:对于像Wikidata快照这样的静态KG,离线生成所有实体的概念向量并存储在巨大的键值映射中。在推理过程中,只需为每个检测到的实体获取相关概念向量,几乎不增加开销。
对于具有稳定或缓慢变化的知识库的IR系统,第二种方法通常是吸引人的,因为它避免了反复为相同实体重新运行ConceptFormer。
5 实验
在本节中,我们探讨了大型语言模型从知识图谱中回忆事实的能力,特别关注Wikidata。我们从IR的角度框架化实验:模型被呈现部分文本(类似于用户查询加上一些上下文),并必须检索或回忆事实对象实体。通过隔离知识密集型任务,我们旨在展示ConceptFormer如何实现紧凑的知识集成,而不会超出上下文预算或重新训练LLM。
5.1 评估范式和指标
我们的实验基于第3节中介绍的Tri-REx和T-REx Bite数据集。这两个数据集由在提到目标对象实体之前截断的句子组成(例如,“阿尔伯特·爱因斯坦是一个…”),LLM的任务是预测与真实实体标签对应的下一个标记。
为了量化回忆,我们采用了广泛使用的Hit@k指标。对于分成TTT个标记的对象标签,我们记录模型输出logits中每个标记ttt的排名(rt)\left(r_{t}\right)(rt)。序列排名取为r=max{r1,…,rT}r=\max \left\{r_{1}, \ldots, r_{T}\right\}r=max{r1,…,rT},如果r≤kr \leq kr≤k(即所有标记出现在各自的步骤中的前kkk预测中),则计为“命中”。这种方法对多标记实体具有鲁棒性,这是涉及命名实体的IR任务中的常见挑战(“纽约时报” vs. “NYT”)。
限制在Hit@1(顶级预测)可能会低估模型的事实知识,因为许多事实可以用多种正确的方式来表述。对于检索任务,我们感兴趣的是地面真相是否可以在前几个候选者中出现。因此,我们主要强调Hit@10,尽管我们也报告了Hit@1和Hit@5以作完整性。Hit@1和Hit@10之间的较大差距也可能揭示真实世界IR中的用户体验差异。
5.2 基准评估
我们首先为六个不同大小和架构的LLM建立基准性能:
表1:不同模型在不同数据集上使用无增强、文本化图注入或使用不同ConceptFormer-nnn变体(生成1到20个概念向量)的正确预测实体百分比。
| Tri-REx | T-Rex Bite | |||||
|---|---|---|---|---|---|---|
| Model | H@1 | H@5 | H@10 | H@1 | H@5 | H@10 |
| LLaMA-2 7B | 4.1%4.1 \%4.1% | 17.5%17.5 \%17.5% | 24.5%24.5 \%24.5% | 39.3%39.3 \%39.3% | 65.3%65.3 \%65.3% | 73.0%73.0 \%73.0% |
| LLaMA-2 3B | 4.3%4.3 \%4.3% | 16.4%16.4 \%16.4% | 22.9%22.9 \%22.9% | 34.8%34.8 \%34.8% | 59.5%59.5 \%59.5% | 67.5%67.5 \%67.5% |
| GPT-2 1.5B | 1.7%1.7 \%1.7% | 8.8%8.8 \%8.8% | 12.7%12.7 \%12.7% | 22.9%22.9 \%22.9% | 43.8%43.8 \%43.8% | 51.8%51.8 \%51.8% |
| GPT-2 0.7B | 1.6%1.6 \%1.6% | 8.8%8.8 \%8.8% | 12.4%12.4 \%12.4% | 19.7%19.7 \%19.7% | 39.3%39.3 \%39.3% | 47.1%47.1 \%47.1% |
| GPT-2 0.3B | 0.9%0.9 \%0.9% | 7.0%7.0 \%7.0% | 10.3%10.3 \%10.3% | 16.3%16.3 \%16.3% | 36.2%36.2 \%36.2% | 44.2%44.2 \%44.2% |
| GPT-2 0.1B | 1.3%1.3 \%1.3% | 5.8%5.8 \%5.8% | 8.5%8.5 \%8.5% | 4.7%4.7 \%4.7% | 14.3%14.3 \%14.3% | 19.5%19.5 \%19.5% |
| LLaMA-2 7B + RAG | 25.6%25.6 \%25.6% | 61.0%61.0 \%61.0% | 72.2%72.2 \%72.2% | 55.3%55.3 \%55.3% | 85.1%85.1 \%85.1% | 90.6%90.6 \%90.6% |
| LLaMA-2 3B + RAG | 28.4%28.4 \%28.4% | 61.5%61.5 \%61.5% | 71.7%71.7 \%71.7% | 52.0%52.0 \%52.0% | 82.3%82.3 \%82.3% | 88.4%88.4 \%88.4% |
| GPT-2 1.5B + RAG | 26.0%26.0 \%26.0% | 54.2%54.2 \%54.2% | 63.8%63.8 \%63.8% | 39.6%39.6 \%39.6% | 70.3%70.3 \%70.3% | 78.3%78.3 \%78.3% |
| GPT-2 0.7B + RAG | 20.9%20.9 \%20.9% | 48.9%48.9 \%48.9% | 59.1%59.1 \%59.1% | 30.9%30.9 \%30.9% | 60.0%60.0 \%60.0% | 69.3%69.3 \%69.3% |
| GPT-2 0.3B + RAG | 21.5%21.5 \%21.5% | 50.7%50.7 \%50.7% | 59.9%59.9 \%59.9% | 30.5%30.5 \%30.5% | 62.3%62.3 \%62.3% | 71.4%71.4 \%71.4% |
| GPT-2 0.1B + RAG | 8.3%8.3 \%8.3% | 32.1%32.1 \%32.1% | 41.3%41.3 \%41.3% | 6.6%6.6 \%6.6% | 23.8%23.8 \%23.8% | 32.4%32.4 \%32.4% |
| GPT-2 0.1B + CF-20 | 16.8%16.8 \%16.8% | 31.2%31.2 \%31.2% | 36.9%36.9 \%36.9% | 46.1%46.1 \%46.1% | 65.6%65.6 \%65.6% | 70.7%70.7 \%70.7% |
| GPT-2 0.1B + CF-15 | 16.2%16.2 \%16.2% | 32.3%32.3 \%32.3% | 38.2%38.2 \%38.2% | 46.7%46.7 \%46.7% | 67.1%67.1 \%67.1% | 72.5%72.5 \%72.5% |
| GPT-2 0.1B + CF-10 | 15.7%15.7 \%15.7% | 31.6%31.6 \%31.6% | 37.8%37.8 \%37.8% | 46.4%46.4 \%46.4% | 67.2%67.2 \%67.2% | 72.9%72.9 \%72.9% |
| GPT-2 0.1B + CF-5 | 13.6%13.6 \%13.6% | 28.6%28.6 \%28.6% | 35.1%35.1 \%35.1% | 42.1%42.1 \%42.1% | 63.3%63.3 \%63.3% | 69.3%69.3 \%69.3% |
| GPT-2 0.1B + CF-4 | 12.7%12.7 \%12.7% | 27.1%27.1 \%27.1% | 33.7%33.7 \%33.7% | 40.1%40.1 \%40.1% | 61.5%61.5 \%61.5% | 68.0%68.0 \%68.0% |
| GPT-2 0.1B + CF-3 | 11.9%11.9 \%11.9% | 26.6%26.6 \%26.6% | 32.9%32.9 \%32.9% | 40.4%40.4 \%40.4% | 61.0%61.0 \%61.0% | 67.1%67.1 \%67.1% |
| GPT-2 0.1B + CF-2 | 11.1%11.1 \%11.1% | 25.3%25.3 \%25.3% | 31.7%31.7 \%31.7% | 37.6%37.6 \%37.6% | 57.8%57.8 \%57.8% | 64.1%64.1 \%64.1% |
| GPT-2 0.1B + CF-1 | 10.0%10.0 \%10.0% | 23.2%23.2 \%23.2% | 28.8%28.8 \%28.8% | 33.3%33.3 \%33.3% | 54.1%54.1 \%54.1% | 61.1%61.1 \%61.1% |
- GPT-2 0.1B, 0.3B, 0.7B, 1.5B [37]
-
- LLaMA-2 3B, 7B [43]
每个模型都在没有任何知识注入的情况下进行评估。我们在Tri-REx和T-REx Bite的测试集上测量Hit@1、Hit@5和Hit@10。
- LLaMA-2 3B, 7B [43]
表1(没有RAG或CF的行)显示,较大的模型在两个数据集上始终优于其较小的同类模型,反映了众所周知的扩展趋势[18]。Tri-REx和T-REx Bite之间的差距在Hit@1尤为显著:基于维基百科的T-REx Bite的表现通常比合成的Tri-REx高出5−10×5-10 \times5−10×,这表明模型利用了其预训练语料库中的记忆文本模式。这一现象突显了一个关键挑战:超越记忆事实以推广到新或罕见的知识。
此外,LLaMA-2变体(3B和7B)的结果明显优于参数量更大的GPT-2模型(例如GPT-2 1.5B),这意味着架构和训练方法可以极大地影响IR任务中的事实回忆。
5.3 带有图文本化的RAG
接下来我们将ConceptFormer与基于文本的检索增强生成(RAG)方法进行比较。具体来说,对于每个主体实体,我们从Wikidata中检索其1跳邻居,并将其文本化为一个短段落附加到LLM提示中[10, 22]。
我们使用简单的模板方法将图邻域转换为文本。性能根据所使用的注入模板而显著变化,有时导致超过100%100\%100%的结果差异,这与[27]中的发现一致。我们观察到使用“主体 ([谓词_1]: (对象_1), {谓词_2}: {对象_2}, …)”形式的模板表现特别差,而“主体, {谓词_1} {对象_1}, {谓词_2} {对象_2}, …”形式的模板表现最佳,后者也被[8]使用。然而,这种方法很容易扩展到100-800个标记,对于知名实体而言,消耗了LLM上下文窗口的很大一部分。
在表1中,标有“+ RAG”的行显示相对于基线有较大提升。对于较小的GPT-2模型,在Hit@10上的提升可以超过6×6 \times6×。这突显了如果有效集成结构化知识对IR的潜在价值。然而,标记开销是巨大的(平均每个主体130个标记,但著名的概念最多可达800个),使其在单个查询中出现多个丰富实体的情况下不切实际。我们还发现,由于知识噪声[26],大邻域的性能可能会下降,这与之前的研究结果一致,即过多的上下文可能会压倒模型。
5.4 ConceptFormer评估
ConceptFormer采用向量方式集成知识,极大地减少了表示实体子图所需的额外标记数量。我们用GPT-2 0.1B(125M参数)实例化ConceptFormer,以测试是否可以通过概念向量格式的结构化提示来弥补小模型缺乏知识的问题。我们在第4节中介绍了两阶段训练方案:
(1) 在Tri-REx上预训练:我们冻结GPT-2 0.1B并优化ConceptFormer以生成合成主谓宾句子的正确下一个标记。这促使模型依赖于外部子图数据,因为模型不能简单地通过记忆来回忆它们。
(2) 在T-REx Bite上微调:我们继续在真实的维基百科句子上训练ConceptFormer。这一步确保该方法能够推广到真实的文本上下文中,而不仅仅是合成集合中的最小三元组。
为了探索向量容量和提示开销之间的权衡,我们训练了具有n∈{1,2,3,4,5,10,15,20}n \in\{1,2,3,4,5,10,15,20\}n∈{1,2,3,4,5,10,15,20}的ConceptFormer变体。每个变体看到相同的星形子图,但可以生成更多或更少的概念向量。
表1(标有“GPT-2 0.1B + CF-nnn"的行)和图4显示,从n=1n=1n=1增加到n=15n=15n=15显著提高了Hit@1和Hit@10。超过15后,我们看到收益递减或无收益,这表明大约10−1510-1510−15个向量足以覆盖Tri-REx中典型的1跳邻域。对于GPT-2 0.1B,某些CF-nnn模型甚至超过了LLaMA-2 7B(一个大50倍的模型)在Hit@1上的表现——这是一个显著的结果,表明概念向量可以比模型自身参数更紧凑地编码必要知识。
在真实句子上微调后,表1显示了最终性能。值得注意的是,CF-15的Hit@1为46.7%46.7\%46.7%,Hit@10为72.5%72.5\%72.5%——比基准GPT-2 0.1B提升了约10倍。即使是一个单一的概念向量(n=1)(n=1)(n=1)也优于GPT-2 0.1B在Hit@1上的基于文本的RAG(33.3%33.3\%33.3% vs. 6.6%6.6\%6.6%),同时平均消耗少130130130倍的标记。
图5强调了这种权衡:图文本化会饱和输入上下文,特别是对于知名主题,而ConceptFormer则以最小的向量开销保持高精度。这对于可能同时出现多个丰富实体的IR场景至关重要。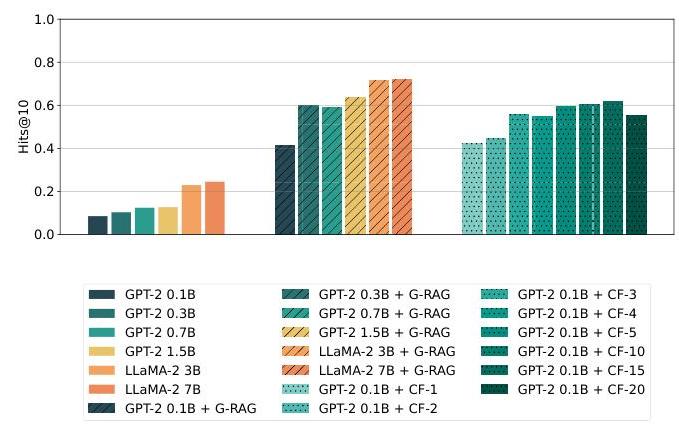
图4:不同基础模型在或不带图RAG(G-RAG)情况下的Hit@10率,与经过Tri-REx预训练后的GPT-2 0.1B和不同ConceptFormers(CF)相比。
按照Liu等人[26]的方法,我们将主题划分为:
- 小众概念(1-10个邻居):通常是不太知名的实体。CF-15在这里显著优于RAG,可能是因为这些实体的文本扩展较短,但LLM仍然受益于学习到的概念表示。
-
- 中等流行(11-90个邻居):混合结果显示CF-15在基线GPT2上有持续改进,尽管RAG在适度的文本扩展下也取得了良好表现。
-
- 非常著名(90-100个邻居):像“阿尔伯特·爱因斯坦”或“伊丽莎白二世女王”这样的实体可以产生非常大的文本扩展。RAG的表现下降,而CF-15保持稳定,说明ConceptFormer在处理广泛子图时避免了知识噪声问题。
- 总体而言,ConceptFormer在不同实体度数上保持高召回率,使其适用于涵盖从稀有到知名话题的IR任务。
5.5 WebQSP上的问答
为了进一步验证ConceptFormer在类似IR的问答环境中的表现,我们在WebQuestions Semantic Parsing(WebQSP)数据集[52]上对其进行评估。由于原始WebQSP引用了Freebase,我们使用了一个链接到Wikidata的变体[39]。在过滤掉缺少或不兼容子图的问题后,我们形成了2,463个问答对,每个都标注了相关实体的节点ID。
我们将GPT-2 0.1B适应到一个提示模板:“问题:[Q]? 答案:”,然后测量正确的实体标签是否出现在前- kkk logits中。由于许多问题有多个有效的答案或同义词,我们采用了较为宽松的Hit@5阈值:只要有一个正确的标签出现在前5个标记中,我们就认为这是召回成功。
表2比较了:
-
基准GPT-2 0.1B: Hit@1为0%,对于这些专门的QA提示几乎随机猜测。
-
- ⋅\cdot⋅ RAG(图文本化):对于GPT-2 0.1B,Hit@5提高到1.4%,对于GPT-2 1.5B提高到13.0%,但绝对性能仍然较低。
-
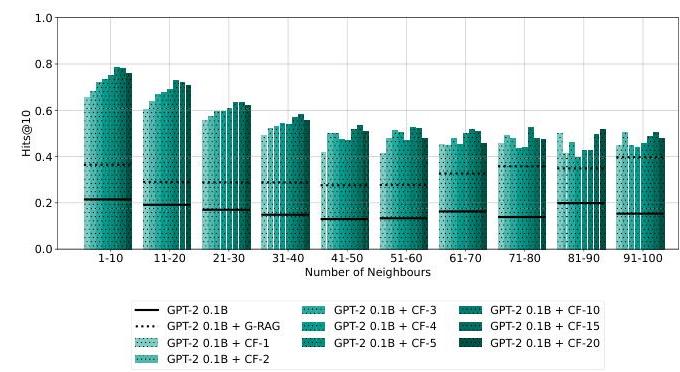
图5:GPT-2 0.1B + 各种ConceptFormers在基于Wikipedia的T-Rex Bite数据集上的Hit@10率。 -
⋅\cdot⋅ ConceptFormer-10(CF-10):实现了Hit@1为7.6%,Hit@5为28.3%,远远超过了LLaMA-2 7B不到1%的Hit@1结果。
-
虽然这些数字与能达到75%以上的专用QA系统相比相对较小,但它们证明了通过ConceptFormer的向量注入,可以使现成的0.1B参数LLM在领域知识查询中变得领域感知。这突出了一条路径,即无需重新训练大型模型即可在面向领域的IR任务(如专业KB)中使用小型LLM。
5.6 其他研究:多跳和全局对齐
尽管我们的实验重点是1跳子图,原则上ConceptFormer可以扩展到多跳邻域。同样,使用全局对齐的节点嵌入(例如来自PBG [19])并未比更简单的基于文本的嵌入提供一致的优势。我们假设ConceptFormer本身通过重复1跳暴露内部化了足够的全局结构。
5.7 发现总结
在各种评估设置中:
- 即使是一个单一的概念向量(n=1)(n=1)(n=1)也可以将GPT-2 0.1B从接近零的性能提升到具有竞争力的结果,同时使用的标记比基于文本的图扩展少∼100×\sim 100 \times∼100×。
-
- 15个概念向量成为一个有效的上限,用于1跳邻域,推动更高的召回率但仍保持标记效率。
-
- 复杂或大型子图对基于文本的RAG造成的影响较小,因为ConceptFormer将子图压缩成固定数量的向量。
-
- 一般的QA场景如WebQSP表明ConceptFormer可以将小型LLM转化为基本的领域知识查询QA引擎。虽然性能不是最先进的,但它强调了基于向量的知识注入的可行性。
- 总的来说,我们的实验确认ConceptFormer为将结构化知识注入LLM提供了强大且可扩展的方法
- 表2:WebQSP数据集中正确回答问题的百分比,比较基础模型(BM)、图RAG(G-RAG)和ConceptFormer-10(CF-10)。
| | BM | | G-RAG | | CF-10 | |
| :-- | :–: | :–: | :–: | :–: | :–: | :–: |
| Model | H@1 | H@5 | H@1 | H@5 | H@1 | H@5 |
| LLaMA-2 7B | 0.9% | 13.5%13.5 \%13.5% | 0.1%0.1 \%0.1% | 6.1%6.1 \%6.1% | | |
| LLaMA-2 3B | 0.1%0.1 \%0.1% | 10.3%10.3 \%10.3% | 0.0%0.0 \%0.0% | 10.1%10.1 \%10.1% | | |
| GPT-2 1.5B | 0.1%0.1 \%0.1% | 4.2%4.2 \%4.2% | 0.2%0.2 \%0.2% | 13.0%13.0 \%13.0% | | |
| GPT-2 0.7B | 0.0%0.0 \%0.0% | 3.9%3.9 \%3.9% | 0.1%0.1 \%0.1% | 2.4%2.4 \%2.4% | | |
| GPT-2 0.3B | 0.0%0.0 \%0.0% | 1.5%1.5 \%1.5% | 0.0%0.0 \%0.0% | 1.1%1.1 \%1.1% | | |
| GPT-2 0.1B | 0.0%0.0 \%0.0% | 0.0%0.0 \%0.0% | 0.2%0.2 \%0.2% | 1.4%1.4 \%1.4% | 7.6%‾\underline{7.6 \%}7.6% | 28.3%‾\underline{28.3 \%}28.3% |
从IR的角度来看,ConceptFormer为诸如查询扩展、实体为中心的检索和基于知识的问答等知识密集型任务提供了解决方案。通过在输入嵌入级别而不是冗长的文本扩展中嵌入图信息,ConceptFormer减少了上下文窗口饱和的风险——使其高度可扩展,适用于高级检索工作流中常见的多实体查询。它弥合了稠密检索技术和结构化KG查找之间的差距,与IR中日益转向检索增强生成方法的趋势相一致。
我们的结果表明,ConceptFormer相较于原始LLM和大多数情景下的模板化图RAG方法表现出优越性能(参见表3)。值得注意的是,它通过最小的上下文大小增加增强了知识回忆,为将大规模知识库集成到现代IR管道中提供了一条高效途径。ConceptFormer的有效性在比较ConceptFormer-1和图RAG的输入标记使用时尤为显著:仅一个单一的概念向量可以在Hit@10上超过图RAG在T-Rex Bite数据集上的表现达88%。这种节省直接惠及IR任务,这些任务需要在一个提示中为多个实体注入相关知识,包括复杂查询或基于对话的搜索。
表3:GPT-2 0.1B + 15个概念向量与GPT-2 0.1B基础模型和GPT-2 0.1B + 图RAG(G-RAG)相比的性能变化。
| Tri-REx | T-Rex Bite | |||||
|---|---|---|---|---|---|---|
| Model | H@1 | H@5 | H@10 | H@1 | H@5 | H@10 |
| GPT-2 0.1B | 1121%1121 \%1121% | 457%457 \%457% | 348%348 \%348% | 894%894 \%894% | 370%370 \%370% | 271%271 \%271% |
| GPT-2 0.1B + G-RAG | 93%93 \%93% | 0%0 \%0% | 8%8 \%8% | 612%612 \%612% | 181%181 \%181% | 123%123 \%123% |
一旦训练完成,ConceptFormer可以预先生成一个全面的查找表,将实体映射到概念向量。或者,它可以动态使用,即时查询源图的相关邻域,并将其嵌入到输入空间兼容的概念向量中,从而在IR管道中提供简化的检索增强步骤。在线KG的变化会自动反映并让LLM可用,使ConceptFormer适合快速变化图的高度动态检索场景。总体而言,它为结构化KG和LLM的生成能力之间提供了一个多功能、标记高效的桥梁,支持更稳健和最新的信息检索。
ConceptFormer展现出四个关键特性,使其特别适合IR管道:
标记效率 每个实体的邻域被压缩成少量向量(≈1-20个“软标记”),相比于典型基于文本的RAG扩展所需数百个标记。IR场景通常有有限的上下文预算,使得这种节省对于复杂或多实体查询至关重要。
无需微调LLM 通过完全停留在输入空间内,ConceptFormer允许系统集成者重用标准开源或商业LLM。这在无法重新训练、受专有原因限制或过于昂贵的情况下尤其有价值。
适应任何KG 该方法对特定的知识图或嵌入技术无关。任何星形拓扑子图都可以输入,允许IR专家无缝将专业化领域知识(例如医学或法律)整合到检索工作流程中。
可扩展性和动态更新 如果KG较大且相对稳定,可以快速集成预计算的概念向量。相反,如果KG动态或需要实时更新,即时生成仍然是可行的。这种灵活性对于需要不断更新知识的领域特别有利。
这些特点突出了ConceptFormer在基于检索的生成、问答或任何要求最新事实依据的IR任务中的适用性。通过优先考虑标记效率、模块化和动态可扩展性,ConceptFormer填补了结构化图数据与冻结的大语言模型之间的关键空白,同时最大限度地减少对上下文预算的负担。最终,它以一种实用、可扩展且高度符合现代信息检索系统需求的方式统一了结构化图知识与LLM的基础生成。
ConceptFormer展示了四项关键属性,使其在IR管道中特别引人注目:
标记效率 每个实体的邻域被压缩成少量向量(约1-20个“软标记”),相比典型的基于文本的RAG扩展所需的数百个标记。IR场景通常有有限的上下文预算,因此这种节省对于复杂的或多实体查询至关重要。
无需微调LLM 通过完全保留在输入空间中,ConceptFormer允许系统集成商重用标准开源或商用LLM。这在无法重新训练、受专有原因限制或成本过高的情况下尤其有价值。
适应任何KG 该方法对特定的知识图或嵌入技术无偏倚。任何星形拓扑子图都可以输入,允许IR专家无缝将专门领域知识(如医疗或法律)整合到检索工作流程中。
可扩展性和动态更新 如果KG较大且相对稳定,可以快速集成预计算的概念向量。相反,如果KG动态或需要实时更新,即时生成仍是可行的。这种灵活性对于需要不断更新知识的领域特别有利。
这些特性凸显了ConceptFormer在基于检索的生成、问答或任何需要最新事实依据的IR任务中的适用性。通过优先考虑标记效率、模块化和动态可扩展性,ConceptFormer在连接结构化图数据与冻结的大语言模型的同时,最小化了对上下文预算的负担。最终,它以一种实用、可扩展且高度符合现代信息检索系统需求的方式统一了结构化图知识与LLM的基础生成。
参考文献
[1] Bilal Abu-Salih. 2021. 领域特定知识图谱:调查报告。J. Netw. Comput. Appl. 185 (2021),103076. https://doi.org/10.1016/J.JNCA.2021.103076
[2] Joel Barmetter, Abraham Bernstein, and Luca Rossetto. 2025. 在T-REx Lite上训练的ConceptFormer. https://doi.org/10.5281/zenodo.15187984
[3] Joel Barmetter, Abraham Bernstein, and Luca Rossetto. 2025. T-REx Bits 1.0. https://doi.org/10.5281/zenodo.15165883
[4] Joel Barmetter, Abraham Bernstein, and Luca Rossetto. 2025. T-REx Star 1.0. https://doi.org/10.5281/zenodo.15165974
[5] Joel Barmetter, Abraham Bernstein, and Luca Rossetto. 2025. Tri-REx 1.0. https://doi.org/10.5281/zenodo.15166163
[6] Antoine Bordes, Nicolas Usunier, Alberto Garcia-Durán, Jason Weston, and Oksana Yakhnenko. 2013. 用于建模多关系数据的翻译嵌入. 在 Advances in Neural Information Processing Systems 26: 第27届神经信息处理系统年度会议论文集(2013年12月9-8日,美国内华达州太浩湖),Christopher J. C. Burges, Léon Bottou, Zoubin Ghahramani, 和 Kilian Q. Weinberger 编辑。2787-2795. https://proceedings.neurips.cc/paper/2013/hash/1cecc7a77026cab135fa2468ba86d39-Abstract.html
[7] Ryan Brate, Minh Hoang Dang, Fabian Hoppe, Yuan He, Albert Meroho-Peñuela, and Vijay Sadashivaiah. 2022. 使用富含知识图谱的提示改进语言模型预测. 在 第21届国际语义网会议(ISWC 2022)期间举行的深度学习知识图谱研讨会(DL4KU 2022)论文集(CEUR Workshop Proceedings, Vol. 3342),Mebwish Alam 和 Michael Coches 编辑。CEUR-W5.org. https://ceur-ws.org/Vol-3342/paper-3.pdf
[8] Ryan Brate, Minh Hoang Dang, Fabian Hoppe, Yuan He, Albert Meroho-Peñuela, and Vijay Sadashivaiah. 2022. 使用富含知识图谱的提示改进语言模型预测. 在 第21届国际语义网会议(ISWC 2022)期间举行的深度学习知识图谱研讨会(DL4KU 2022)论文集(CEUR Workshop Proceedings, Vol. 3342),Mebwish Alam 和 Michael Coches 编辑。CEUR-W5.org. https://ceur-ws.org/Vol-3342/paper-3.pdf
[9] Hady Elbahar, Pavlou Vougiouklis, Arslen Renuci, Christophe Gravier, Jonathon S. Hare, Frédérique Laforest, and Elena Simperl. 2018. T-REx: 自然语言与知识库三元组的大规模对齐. 在 第十一届国际语言资源与评估会议论文集,LREC 2018, 宫崎县日本,2018年5月7-12日,Nicoletta Calcolari, Khalid Choukri, Christopher Cleri, Thierry Declerck, Sara Goggi, Köiti Hasida, Hitoshi Inahara, Benfe Maegaard, Joseph Mariani, Hélène Mazo, Asunción Moreno, Jan Odijk, Stelios Piperidis, 和 Takenobu Tokunaga 编辑。欧洲语言资源协会(ELRA)。http://www.lerc-conf.org/proceedings/lerc2018/summaries/ 652.html
[10] Bahare Fatemi, Jonathan Halcrow, and Bryan Perozzi. 2023. 谈话如图:为大型语言模型编码图. CoRR abs/2310.04560 (2023). https://doi.org/10.48550/ARXIV. 2310.04560 arXiv:2310.04560
[11] Binost Gil, Yuval Alahif, Yuval Atzmon, Or Patashnik, Amir Haim Bermano, Gal Chechik, and Daniel Cohen-Oz. 2023. 一幅图像等于一个单词:使用文本反转个性化文本到图像生成. 在 第十一届国际学习表征会议,ICLR 2023, 卢旺达基加利,2023年5月1-5日. OpenReview.net. https://openreview.net/pdf?id=NAQvF08TcyG
[12] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinlin Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, and Haofen Wang. 2023. 面向大型语言模型的检索增强生成综述. CoRR abs/2312.10997 (2023). https://doi.org/10.48550/ARXIV.2312.10997 arXiv:2312.10997
[13] Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura PerezBeltrachini. 2017. 创建NLG微型规划器的训练语料库. 在 第55届计算语言学年会论文集,ACL 2017, 加拿大温哥华,2017年7月30日-8月4日,长篇论文卷1,Regina Barofay 和 Min-Yen Kan 编辑。计算语言学协会。179-188. https://doi.org/10.18653/V1/P17-1017
[14] Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sevakaath Gopi, Mojan Javaheripi, Piero Kaulfinann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sebastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee, and Yuanzhi Li. 2023. 文本书就是你所需要的. CoRR abs/2306.11644 (2023). https://doi.org/10. 48550/ARXIV.2306.11644 arXiv:2306.11644
[15] Aric A. Hagberg, Daniel A. Schult, and Pieter J. Swart. 2008. 使用NetworkX探索网络结构、动力学和功能. 在 第7届Python科学会议论文集,Gail Varoquaux, Travis Vaught, and Jarrod Millman 编辑。帕萨迪纳,加州美国,11 - 15.
[16] Shaoxiong Ji, Shiroi Pan, Erik Cambria, Pekka Marttinen, and Philip S. Yu. 2022. 知识图谱综述:表示、获取和应用. IEEE Trans. Neural Networks Learn. Syst. 33, 2 (2022), 494-514. https://doi.org/ 10.1109/TNNLS.2021.3070843
[17] Albert Q. Jiang, Alexandre Sablayeilles, Arthur Mensch, Chris Bamford, Devendra Singh Chupot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavid, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. VintraT 3D. CoRR abs/2310.06825 (2023). https: //doi.org/10.48550/ARXIV.2310.06825 arXiv:2310.06825
[18] Nayeon Lee, Wei Ping, Peng Xu, Mostofa Patwary, Pascale Fong, Motiammad Shoxybi, and Bryan Catanzaro. 2022. 增强语言模型的事实性以实现开放文本生成. 在 Advances in Neural Information Processing Systems 35: 2022年神经信息处理系统年度会议论文集,NeurIPS 2022, 美国路易斯安那州新奥尔良,2022年11月28日-12月9日, Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh 编辑。http://papers.nips.cc/paper_files/paper/2022/hash/ df438caa36714f69277daaf02608d4b3-Abstract-Conférence.html
[19] Adam Lerer, Ledell Wu, Jiajun Shen, Timothée Lacroix, Luca Wehrstedt, Abhijit Bose, and Alex Peyyakhovich. 2019. Pytorch-BigGraph: 大规模图嵌入系统. 在 Proceedings of Machine Learning and Systems 2019, MLSys 2019, 斯坦福大学,加利福尼亚州,美国,2019年3月31日-4月2日, Ameret Talwalkar, Virginia Smith, and Matei Zaharia 编辑。mlsys.org. https://proceedings.mlsys.org/book/282.pdf
[20] Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. 检索增强生成用于知识密集型NLP任务. 在 Advances in Neural Information Processing Systems 35: 2020年神经信息处理系统年度会议论文集,NeurIPS 2020, 2020年12月6-12日,虚拟会议, Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin 编辑。https://proceedings.neurips.cc/paper/2020/hash/ 6b493230203f780e1bc26945df74f1e5-Abstract.html
[21] Junyi Li, Tianyi Tang, Wayne Xin Zhao, and Ji-Rong Wen. 2021. 预训练语言模型用于文本生成:综述. CoRR abs/2105.10311 (2021). arXiv:2105.10311. https://arxiv.org/abs/2105.10311
[22] Shiyang Li, Yifan Gao, Haoming Jiang, Qingyu Yin, Zheng Li, Xifeng Yan, Chao Zhang, and Bing Yin. 2023. 基于三元组检索的图推理问答. 在 Findings of the Association for Computational Linguistics: ACL 2023, 加拿大多伦多,2023年7月9-14日, Anna Rogers, Jordan L. Boyd-Graber, and Nacaki Okazaki 编辑。计算语言学协会,3366-3375. https://doi.org/10.18653/V1/2023.FINDINGS-ACL. 208
[23] Xiang Lisa Li and Percy Liang. 2021. 前缀调优:用于生成的连续提示优化. 在 第59届计算语言学年会论文集,ACL7JUNLP 2021, (长论文卷1),虚拟活动,2021年8月1-6日, Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli 编辑。计算语言学协会,4582-4597. https://doi.org/10.18653/V1/2021 ACL-123NG.153
[24] Sheng Liang, Mengjie Zhao, and Hinrich Schütze. 2022. 带有提示的模块化和参数高效多模态融合. 在 Findings of the Association for Computational Linguistics: ACL 2022, 爱尔兰都柏林,2022年5月22-27日, Smaranda Muresan, Preslav Nakov, and Aline Villavicencio 编辑。计算语言学协会,2976-2985. https://doi.org/10.18653/V1/2022.FINDINGS-ACL. 234
[25] Adam Liska, Tomás Kociský, Elena Gribovskaya, Tayfun Terzi, Sevakaath Gopi, Mojan Javaheripi, Piero Kaulfinann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sebastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee, and Yuanzhi Li. 2022. StreamingQA:问答模型随时间适应新知识的基准. 在 国际机器学习会议论文集,ICML 2022, 2022年7月17-23日,美国马里兰州巴尔的摩 (Proceedings of Machine Learning Research, Vol. 162),Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato 编辑。PMLR, 13604-13622. https://proceedings.mlr.press/v162/liska22a.html
[26] Weijie Liu, Peng Zhou, Zhe Zhao, Zhirun Wang, Qi Ju, Haotang Deng, and Ping Wang. 2020. K-BERT:通过知识图谱启用语言表示. 在 第三十四届人工智能会议论文集,AAAI 2020, 第三十二届人工智能创新应用会议论文集,IAAI 2020, 第十届人工智能教育进展研讨会论文集,EAAI 2020, 美国纽约,2020年2月7-12日. AAAI Press, 2901-2908. https://doi.org/10.1609/AAAI.V34B553681
[27] Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Tujie Qian, Zhilin Yang, and Jie Tang. 2021. GPT也理解. CoRR abs/2103.10385 (2021). arXiv:2103.10385 https://arxiv.org/abs/2103.10385
[28] Kelvin Luu, Daniel Khashabi, Suchin Gururangan, Karishma Mandyam, and Noah A. Smith. 2022. 时间不等人!分析和挑战时间错配. 在 北美计算语言学协会2022年会议论文集:人类语言技术,NAACL 2022, 美国华盛顿州西雅图,2022年7月10-15日, Marine Carpuat, Marie-Catherine de Marneffe, and Ivan Vladimir Meza Ruiz 编辑。计算语言学协会,5944-5958. https://doi.org/10.18653/V1/2022. NAACL-MAIN. 435
[29] Sewon Min, Kaljeish Krishna, Xinyi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemeyer, and Hannaneh Hajisharsi. 2023. FActScore:长篇文本生成中细粒度原子事实精确度评估. 在 第2023届经验方法自然语言处理会议论文集,EMNLP 2023, 新加坡,2023年12月6-10日, Honda Bouamon, Juan Pino, and Kalika Bali 编辑。计算语言学协会,1207612100. https://aclanthology.org/2023.emnlp-main.741
[30] Tom M. Mitchell, William W. Cohen, Estevam R. Hruschka Jr, Partha P. Talukdar, Bo Yang, Justin Betteridge, Andrew Carlson, Bluvana Dalvi Mishra, Matt Gardner, Bryan Kisel, Jayant Krishnamurthy, Ni Lao, Kathryn Mazaitis, Thalur Mohammed, Ndapandula Nakashole, Emmanouil A. Platanios, Alan Ritter, Mehdi Samadi, Burr Settles,哈希特·贝格曼,理查德·C·王,德里·威贾亚,阿宾纳夫·古普塔,辛雷·陈,萨帕洛夫·戈扎维斯,马科利亚斯·戈泽维斯,乔尔·韦林。2018. 无止境的学习。ACM通讯 61, 5 (2018), 103-115. https://doi.org/10.1145/3191515
参考论文:https://arxiv.org/pdf/2504.07624

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)