LLM 优化技术(5)——StreamingLLM 拥有无限长生成能力
因为 Attention 的计算量和内存需求都随着序列长度增加而成平方增长,所以增加序列长度很难,一些实现方法包括:训练时用 FlashAttention 等工程优化,以打破内存墙的限制,或者一些 approximate attention 方法,比如 Longformer 这种 Window Attention 方法。这篇论文通过使用 approximate attention 的方法,放松了对
0 背景
论文:
Efficient Streaming Language Models with Attention Sinks
论文代码:
GitHub - mit-han-lab/streaming-llm: Efficient Streaming Language Models with Attention Sinks
本文作者着力解决的核心问题是:能否在不牺牲效率和性能的情况下,部署一个能处理无限输入的LLM?以实现流式LLM应用部署的效果。也就是可以不受长度限制不停地输出,无限长输入和无限长上下文还不同,前者不需要对所有输入有记忆。
解决这个问题的挑战:
- 在解码阶段,由于 KV Cache 存在导致内存使用或延迟增加,内存上限和推理服务 SLA 存在,导致 KV Cache 不能无限大,这是性能瓶颈。kv_cache
- 现有模型的外推(extrapolation)能力有限,也就是说当序列长度超过pretraining时设定的注意力窗口大小时,它们的表现会下降,这是模型能力的瓶颈。Dense Attention 具有 O ( T 2 ) O(T^2) O(T2) 的时间和内存复杂度。当文本长度超过预训练文本长度时,其运行的性能会下降。
目前主流地增加输入文本长度的方法有如下两大类方法:
-
长度外推(Length Extrapolation):该方法让训练在较短文本上的LLM能够在推理时处理较长的文本。比如,编码方法 RoPE,ALiBi 等都归于此类。然而,目前尚未有方法实现无限长度的外推,还无法满足作者流式应用的需求。关于外推性:Transformer升级之路:7、长度外推性与局部注意力
-
上下文窗口扩展(Context Window Extension):该方法实打实地去扩大LLM的上下文窗口长度,也就是序列长度。因为 Attention 的计算量和内存需求都随着序列长度增加而成平方增长,所以增加序列长度很难,一些实现方法包括:训练时用 FlashAttention 等工程优化,以打破内存墙的限制,或者一些 approximate attention 方法,比如 Longformer 这种 Window Attention 方法。
- Window Attention 缓存最近的 L 个 token 的 KV。虽然在推理过程的效率高,但一旦开头的 token 的 KV 被驱逐出 Cache,模型推理的表现就会急剧下降(PPL 越高模型表现越差)。
- 一个降低内存需求的优化是,让 Window Attention 重新计算从每个新令牌的 L 个最近令牌中重建 KVCache。虽然它在长文本上表现良好,但由于上下文重新计算中的二次注意力导致的 O ( T ∗ L 2 ) O(T*L^2) O(T∗L2) 复杂性,使其相当慢。
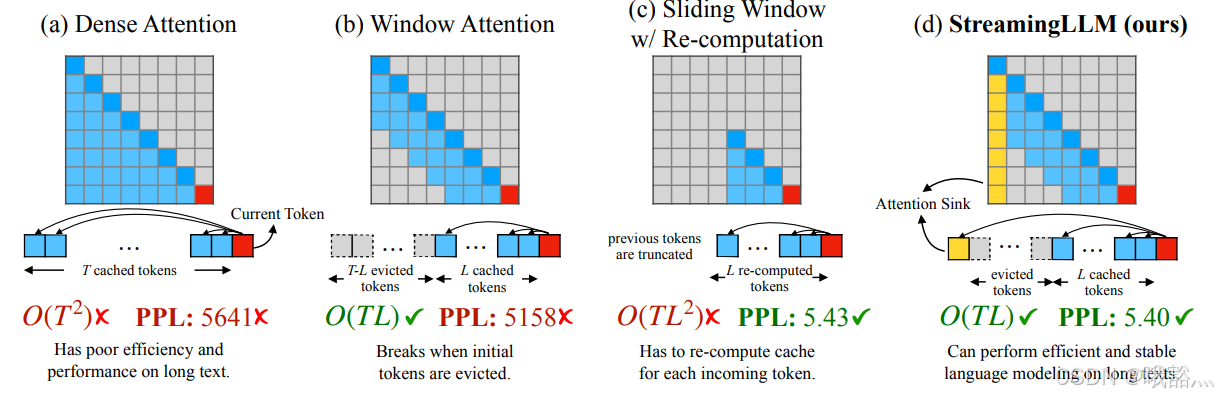
通常,使用这些技术后,大型语言模型(LLM)的推理输入长度会受到一定的限制。
这篇论文通过使用 approximate attention 的方法,放松了对全部输入记忆的限制,仍然只记住最近的上下文,但实现了处理无限输入并获得无限输出的效果,另辟蹊径。
1 方法

对于 Window Attention 在超长文本输入时,如上图的橘色曲线所示,即使窗口大小只比KVCache Size大1,也就是说,注意力计算只减少了第一个token,模型推理的PPL值却会急剧上升。
直觉告诉我们,随着窗口大小的增大,模型推理的表现应该逐渐变差。然而,仅仅少输入一个 token,模型的性能就一触即溃,这似乎暗示着开头的第一个 token 可能具有关键的作用。
于是,作者们把 attention 每一层每一个 Head 经过 softmax 输出后的 logits 值翻出来观察。作者们发现:

-
第一和第二 layer(0 和 1 layer)的注意力图展示了"local"模式,离当前处理 token 最近的 token 收到了更多的 attention,即 attention 矩阵对角线位置值相对更大。
-
除了网络最前面的两层外,模型在所有 layer 和 head 都重点对于 initial token(开头的几个tokens)给予更多的attention值。
基于如上观察,作者提出了 attention sink 概念来解释 Window Attention 失败的原因。输入给 LLM 推理开头的几个 intial tokens 是非常特殊的,仿佛水池(sink)中的排水口一样,吞噬了大量的 attention。而且** intial tokens 与被预测 token 的距离如何,语义信息如何都不重要,重要的只是它的绝对位置**。也就是说前几个位置上的 token 不管是啥,对维持 LLMs 推理的稳定性都很关键。
那么 Attention sink 是什么原因造成的呢?作者尝试给出一些解释。
高通论文地址:https://arxiv.org/abs/2306.1292
高通 AI Research 的人研究 LLM 量化方法时发现 Attention Head 激活张量里有一些值异常突出(常被称为 outliner),追查发现是 Softmax 引发的。这个问题引起了程序员 Evan Miller 的注意,他研究发现 softmax 函数存在 Bug,并发表了一篇博客《Attention Is Off By One》:
在 Attention 机制中,Softmax 的输出代表了 key/query 的匹配程度的概率。如果 softmax 在某个位置的值非常大,那么在反向传播时,这个位置的权重就会被大幅度地更新。然而,有时候 attention 机制并不能确定哪个位置更值得关注,但由于 Softmax 需要所有位置的值的总和为 1,因此必须表态给某些位置较大的权重,这就可能导致错误的权重更新,而这个错误在后续的过程中很难被纠正。Miller 的原话:
The problem with using softmax is that it forces each attention head to make an annotation, even if it has no information to add to the output vector
于是,他改进了一下 Softmax,把 softmax 的分母加了个 1 ,这样所有位置的概率和可以不为 1,这样 Attention 就有了可以不对任何位置表态的权利。
( s o f t m a x 1 ( x ) ) i = e x p ( x i ) 1 + ∑ j e x p ( x j ) \left( softmax_1(x) \right)_i = \frac{exp(x_i)}{1 + \sum _j exp(x_j)} (softmax1(x))i=1+∑jexp(xj)exp(xi)
这里看起里有点像统计学里面使用样本均数计算总体方差的时候,需要除以 (n - 1),而不是 n。
S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ^ ) 2 S^2 = \frac{1}{n - 1} \sum _{i=1} ^n (X_i - \hat{X})^2 S2=n−11i=1∑n(Xi−X^)2
统计学重要的研究内容之一是用样本推测总体。具体而言,就是用样本均数和样本标准差来估计总体均数和总体标准差,而这里的估计有一个很重要的原则就是无偏。所谓无偏,就是说,样本值应该是围绕总体值上下波动的,它不能总在总体值的上面,或者总在总体值下面。对于一个特定的总体,其总体均数和总体标准差是恒定不变的。但是,从总体中我们可以进行无数次抽样,每次抽样便获得一个特定的样本,然后计算出特定的样本均数和样本标准差。所以,只要抽样一次,样本值就可能变化一次。因此,样本值是变化的。用一个变化的量去估计一个恒定的量,首要原则就是无偏。换言之,如果我们知道某一个变化的量如果总是小于这个恒定的量,那么这个变化量就不是一个无偏估计。
数学上可以证明:
∑ i = 1 n ( X i − X ^ ) 2 ≤ ∑ i = 1 n ( X i − μ ) 2 \sum _{i=1} ^n (X_i - \hat{X})^2 \leq \sum _{i=1} ^n (X_i - \mu)^2 i=1∑n(Xi−X^)2≤i=1∑n(Xi−μ)2
1 n ∑ i = 1 n ( X i − X ^ ) 2 ≤ 1 n ∑ i = 1 n ( X i − μ ) 2 \frac{1}{n} \sum _{i=1} ^n (X_i - \hat{X})^2 \leq \frac{1}{n} \sum _{i=1} ^n (X_i - \mu)^2 n1i=1∑n(Xi−X^)2≤n1i=1∑n(Xi−μ)2
上面不等式恒成立。左边是样本均数,右边是总体均数。
当用样本均数代替总体均数后,上面左边的式子总是小于右边的式子。因此,如果我们采取左式计算样本方差,那它就不是总体方差的无偏估计了,而是总小于总体方差。
现实中我们无法计算右式(总体均数 μ \mu μ 未知)。考虑到在右边的式子中,每一项都是自由变换的,因此每个出现的概率为 1 n \frac{1}{n} n1。左边的式子中,对于特定的样本, n 项如果确定了其中的 n − 1 n-1 n−1 项,那么第 n 项就是确定的了,因此每一项出现的概率就是 1 n − 1 \frac{1}{n-1} n−11。
回归概率的定义,上面的式子里面的 1 n \frac{1}{n} n1 以及 1 n − 1 \frac{1}{n-1} n−11 表达的是概率,不是数量的倒数。
回到这里的问题,模型作为真实世界的一个拟合,训练数据就是真实世界的一个样本。而 softmax 函数计算的是 key-query 的匹配概率。如上所述,使用样本估计总体,求得的概率必然是偏大的。因此对 softmax 的分母做改动,分母加一的合理性如上所述。
StreamingLLM 的作者采用了类似的观点解释 attention sink 现象。SoftMax 函数的性质使得所有经过 attention 结构的激活张量不能全部为零,虽然有些位置其实不需要给太多的注意力。因此,模型倾向于将不必要的注意力值转嫁给特定的 token,作者发现这个特定的 token 就是 initial tokens。在量化异常值的领域也有类似的观察,Miller 大佬提出了 SoftMax-Off-by-One 作为可能的解决方案。
有了这个洞见,作者设计了 Window Attention 的改进版。思路很直接,在当前滑动窗口方法基础上,重新引入了一些 initial tokens 的 KV 在注意力计算中使用。
StreamingLLM 中的 KV Cache 可以从概念上分为两部分,如下图:
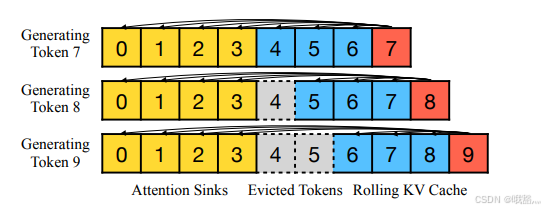
- attention sink 是 4 个 initial tokens,稳定了注意力计算;
- Rolling KV 缓存保留了最近的 token,这个窗口值是固定的,图中为3。
需要有些小改动来给 attention 注入位置信息,StreamingLLM 就可以无缝地融入任何使用相对位置编码的自回归语言模型,如 RoPE 和 ALiBi。目前为止,StreamingLLM 不需要做训练,把 initial tokens 数目设置为4就可以获得不错的长输入下的推理表现了。
可以通过 Pre-training LLMs with attention sinks 获得更好的表现。作者提出两种方法:(1)指定一个全局可训练的 attention sink token,称之为Sink Token,它将作为不必要的注意力的存储库,从而把 initial tokens 作为 attention sink 的作用转移到 sink token 上。(2)用类似 Miller 提出的 SoftMax-off-by-One 的变体替换传统的 SoftMax 函数,作者称之为 Zero Sink 方法。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)