RAG大模型怎么通过python调用 (接口)
·
什么是检索增强的生成模型(RAG)知识库
1.1 大模型目前有的局促行
LLM 的知识不是实时的
LLM 可能不知道你私有的领域/业务知识
1.2 检索增强生成
RAG(Retrieval Augmented Generation)顾名思义,通过检索的方式来增强生模型的能力
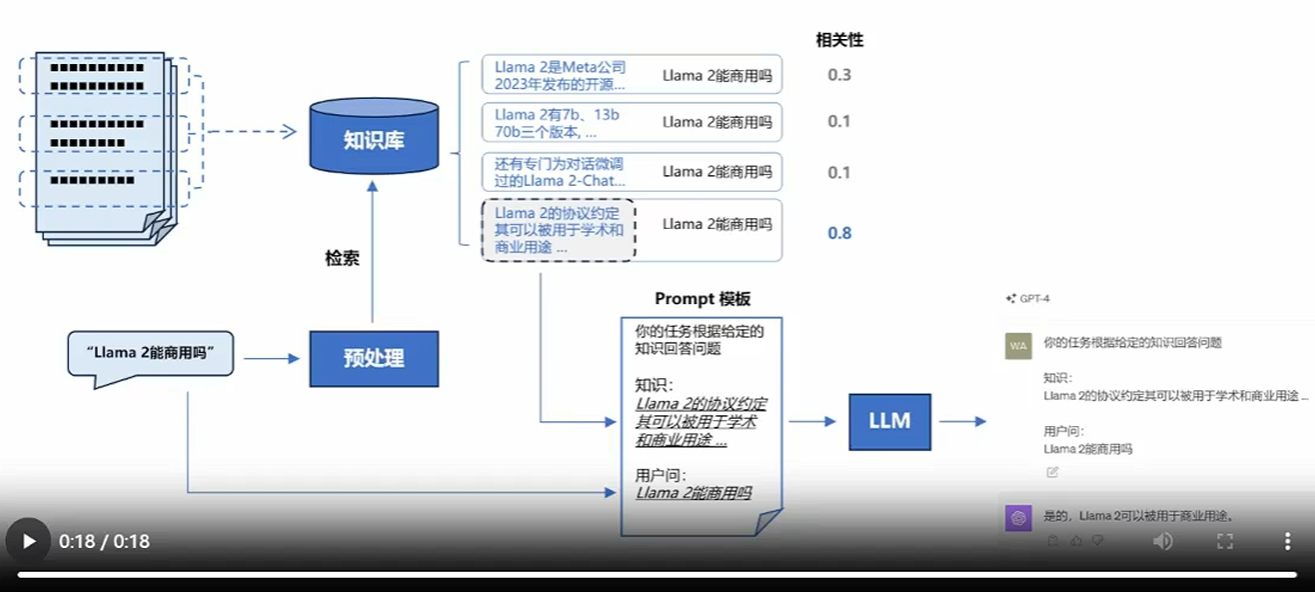
在这张图片可以看到原始文档 构建一个知识库 我们提过一个文字(首先通过知识库来检索文档也就是说预处理)然后进行排序 生成一个Prompt模板 然后就是上传我们的大模型(LLM 推理模型或文本生成模型) 然后大模型给我们进行一个归纳总结
可以理解为这几个阶段所
第一个阶段 需要的文档存储到知识库中 知识库大部分使用向量数据库
第二个阶段 用户提供一个问题(也就是一个文本内容) 预处理可以理解为人类说的大白话 编译为文本向量 然后就是在向量数据库中做一个相似度匹配 知识库中存储的两个东西 一个是向量(做索引)向量对应一个原始文本 也就是说 向量 = 原始文本反复的
RAG系统的基本搭建流程
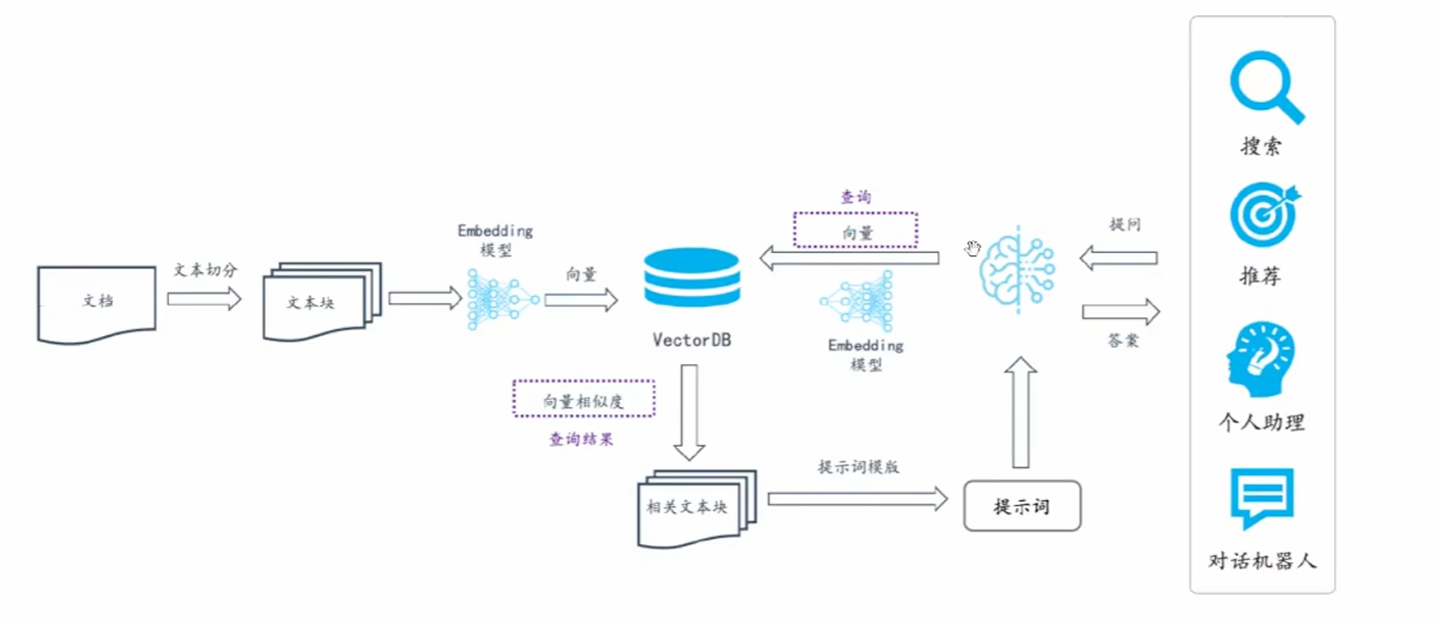
搭建过程 :
1.文档加载,并一定条件 切割 成片段
2.将切割的文本段灌入 检索引擎(凡是有检索的地方都要考虑有性能瓶颈)大白话就是数据多了 查找的内容就会变慢
3.封装检索接口
4.构建调用流程: Query ->检索 ->Prompt ->LLM回复
2.1文档的加载与切割
# pip instal.--upgrade openai#安装 pdf解析库等等
# pip install pdfminer.sixfrom pdfminer.high _evel import extract_pages
from pdfminer.layout import LTTextContainer#函数结构简要说明
def extract_text_from_pdf(filename, page_numbers=None, min_line_length=1):
# filename:PDF 文件路径
# page_numbers:需要提取的页码列表(可选)
# min_line_length:行的最小长度(用于排除太短的行)
#主体流程
paragraphs = []
buffer = ''
full_text = ''
#遍历 PDF 页面:
for i, page_layout in enumerate(extract_pages(filename)):
#若设置了 page_numbers,只处理指定页码:
if page_numbers is not None and i not in page_numbers:
continue
#提取该页的所有 LTTextContainer 对象中的文本,并拼接
if isinstance(element, LTTextContainer):
full_text += element.get_text() + '\n'
#按行分割文本并组织成段落:
lines = full_text.split('\n')
#合并多行组成段落,避免短行或断行(如带 - 的):
if len(text) >= min_line_length:
buffer += (' ' + text) if not text.endswith('-') else text.strip('-')
#处理缓冲区内容并追加到段落列表
elif buffer:
paragraphs.append(buffer)
buffer = ''
#返回所有段落
return paragraphs
下面你是完整代码...
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
def extract_text_from_pdf(filename, page_numbers=None, min_line_length=1):
paragraphs = []
buffer = ''
full_text = ''
for i, page_layout in enumerate(extract_pages(filename)):
if page_numbers is not None and i not in page_numbers:
continue
for element in page_layout:
if isinstance(element, LTTextContainer):
full_text += element.get_text() + '\n'
lines = full_text.split('\n')
for text in lines:
if len(text.strip()) >= min_line_length:
buffer += (' ' + text.strip()) if not text.strip().endswith('-') else text.strip('-')
elif buffer:
paragraphs.append(buffer.strip())
buffer = ''
if buffer:
paragraphs.append(buffer.strip())
return paragraphs
# 测试代码
if __name__ == '__main__':
paras = extract_text_from_pdf('../LLMPython/LLMPython/text.pdf', page_numbers=[0], min_line_length=5)
for i, p in enumerate(paras):
print(f'段落 {i+1}:\n{p}\n{"-"*40}')
2.2LLM接口封装(大白话 调用模型)我这边使用的是DeepSeek
# pip install -U python-dotenvimport os
from dotenv import load_dotenv
from openai import OpenAI
# 加载 .env 文件
load_dotenv('../LLMPython/Load_dotenv.env')
# 获取 DeepSeek API Key
api_key = os.getenv("DEEPSEEK_API_KEY")
if not api_key:
raise ValueError("请在 .env 文件中设置 DEEPSEEK_API_KEY")
# 初始化客户端:指定 base_url 指向 DeepSeek API
client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com")
print("已初始化 DeepSeek API")
# 嵌入式模型的选中
# 在一个标准中比如要了解医学 需要找需求相关的语料库来惊醒文本向量转换测试,,经行评估
# 这是国内一个https://www.modelscope.cn/home模型库
# 举例来说 我在上面的连接上找到text-embedding-ada-002 这个模型 这个模型就是对跨语言的模型是比较适合的,比如很多文档的法文,英文,中文,等等
# 总结来说不同的模型在不同的领域中是适用于不同的方面
# 比较重要!!
def get_completion(prompt, model="deepseek-chat"):
"""调用 DeepSeek 的聊天模型接口"""
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "你是一个有帮助的助手"},
{"role": "user", "content": prompt},
],
temperature=0
)
return response.choices[0].message.content
# 示例调用
if __name__ == "__main__":
prompt = "你是谁?"
result = get_completion(prompt)
print("模型回复:", result)
# 嵌入式模型的选中 # 在一个标准中比如要了解医学 需要找需求相关的语料库来惊醒文本向量转换测试,,经行评估 # 这是国内一个https://www.modelscope.cn/home模型库 # 举例来说 我在上面的连接上找到text-embedding-ada-002 这个模型 这个模型就是对跨语言的模型是比较适合的,比如很多文档的法文,英文,中文,等等 # 总结来说不同的模型在不同的领域中是适用于不同的方面 # 比较重要!!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)