Senna多模态大模型中关键数据及代码解析
每层的0应该是k, 1应该是v,(1,32,999, 128)中的1是batch size,32是multi head的head数,128是每个head的维度,999就是上次输入的999个token。今天将Senna官方代码中的eval跑了一下,同时用pycharm的debug工具追踪一些关键数据的处理流程,也梳理了代码的执行流程,记录一些关键信息如下,作为一个记录,同时也希望能对大家有所帮助。5
今天将Senna官方代码中的eval跑了一下,同时用pycharm的debug工具追踪一些关键数据的处理流程,也梳理了代码的执行流程,记录一些关键信息如下,作为一个记录,同时也希望能对大家有所帮助。
sh eval_tools/senna_plan_cmd_eval_multi_img.sh
我将我改的配置列在文末,仅供参考。
上一篇关于Senna的文章:Senna模型训练的工程跑通
我们知道Senna的大语言模型部分,输入就是6张环视图片,同时加一些对话指令文本(prompt),输出就是路径和速度的决策信息,给到下游模块使用。
1,将输入6张环视图片处理成336*336大小,(N=6,C,H,W)
2,将prompt进行token化:
下面这句是Senna模型推理时,固定的prompt输入,其中有图片占位符。
A chat between a curious human and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the
human's questions. USER: <FRONT VIEW>:
<image>
<FRONT LEFT VIEW>:
<image>
<FRONT RIGHT VIEW>:
<image>
<BACK LEFT VIEW>:
<image>
<BACK RIGHT VIEW>:
<image>
<BACK VIEW>:
<image>
Your current speed is 8 m/s, the navigation command is 'turn left',
based on the understanding of the driving scene and the navigation
information, what is your plan for the next three seconds? Please
answer your SPEED plan and your PATH plan. SPEED includes KEEP,
ACCELERATE and DECELERATE, and STOP, PATH includes STRAIGHT, RIGHT_CHANGE,
LEFT_CHANGE, RIGHT_TURN, LEFT_TURN. For example, a correct
answer format is like 'KEEP, LEFT_CHANGE'. ASSISTANT:
上面的文本中的每个单词都变成在词表中的ID,其中-200代表图片占位符。共237个ID。如下: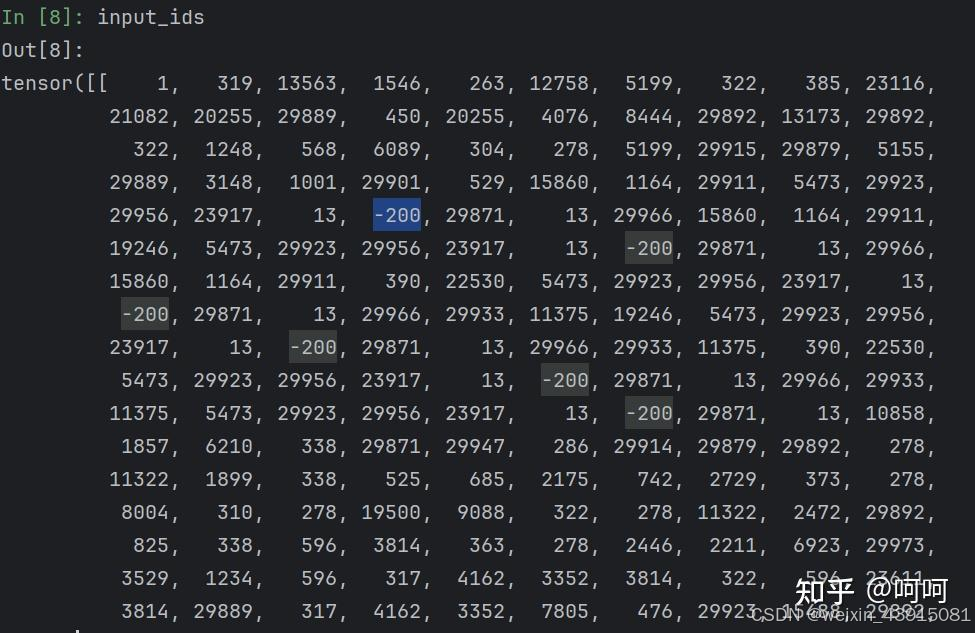
3,SennaLlavaLlamaForCausalLM:prepare_inputs_labels_for_multimodal()函数
将图片数据经过vit特征提取模块,再经过adapter模块转换为下面格式,也就是每张图片处理成128个token,每个token的维度是4096,跟文本token的维度是一样的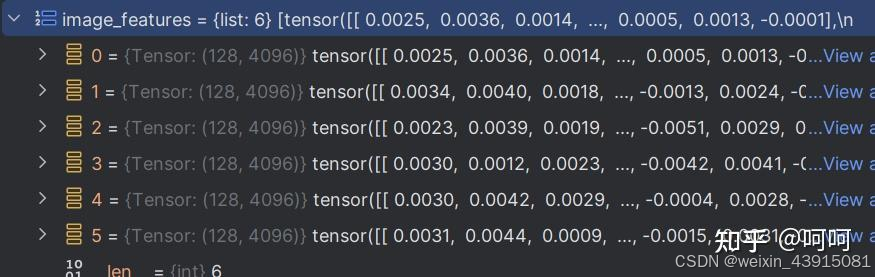
然后将上面237个单词 - 6个图片占位符 + 128*6个图片token = 999个token,按顺序整合在一起。也就是在每个图片占位符的地方插入此处图片对应的128个token,形成inputs_embeds。1是 batch size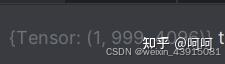
4,将上面的汇总的多模态信息,输入给大语言模型,模型推理形成决策信息,过程如下:
SennaLlavaLlamaForCausalLM:generate中调用了super.generate(),即进入了GenerationMixin:generate,然后又进入了GenerationMixin:greedy_search函数。从进入GenerationMixin类后,就进入了hugging face的transformer库了,属于第三方的代码,不是Senna项目代码,但因为比较重要,就简要介绍一下greedy_search函数。greedy_search里面有一个 while True循环,也就是不断的推理(调用SennaLlavaLlamaForCausalLM:forward)下一个token ,直到遇到结束token为止。
SennaLlavaLlamaForCausalLM:forward开始,才是大模型的核心推理逻辑。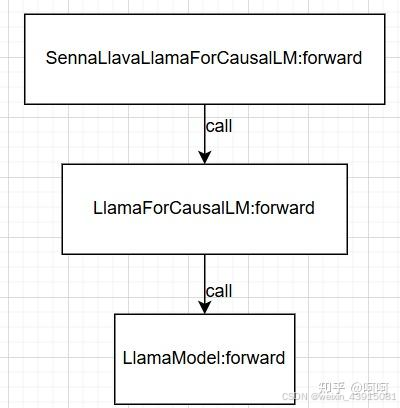
在代码框架中,推理第一个token,跟推理后面的token,传入到LLamaModel:forward的参数是完全不一样的。
第一次输入的三个核心变量如下,可以看到,第一次将inputs_embeds 999个token全部输入进来。position_ids和attention_mask是一些必要的基本输入,不重点讲解。


第二次及以后输入如下,可以看到第二次只输入了第一次生成的那个token,它的ID是476。以前的999个不用输入了,都变成kv缓存了,不了解大模型kv缓存的,可以自行搜索学习。下面有一篇,写得还不错,供参考:图解LLM训练和推理的秘密-1
总结一下,第二次及以后,就只输入上一次生成的token,然后依次不断生成下一个token(上面刚说到的while循环),直到生成结束符。



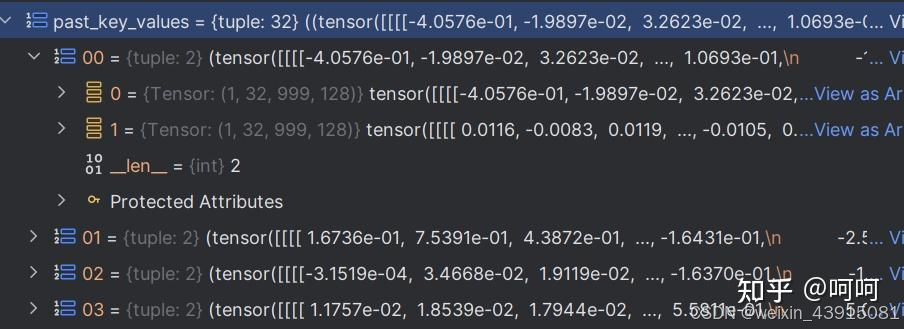
第二次及以后的重点其实是上面这个 past_key_values,也就是kv缓存,因为历史已经计算过的kv可以缓存起来,减少计算量。共有32个元素(大模型有32层)。每层的0应该是k, 1应该是v,(1,32,999, 128)中的1是batch size,32是multi head的head数,128是每个head的维度,999就是上次输入的999个token。可以发现32*128=4096,也就是 token的维度。
可以再看下第三次的输入:
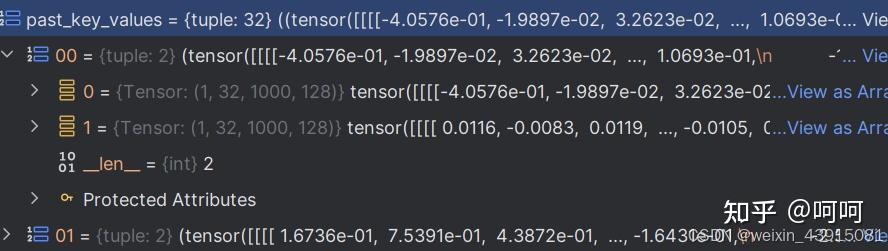
可以发现,position_id加了1,past_key_values中的一个维度也从999变成了1000,也就是不断有新的cache加进来
5,最终上面的一大堆文本和图片的输入,生成了2个单词,即在速度和路径上的决策信息,速度保持,路径直行。信息传递给下游e2e模块进行轨迹生成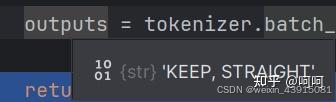
配置修改: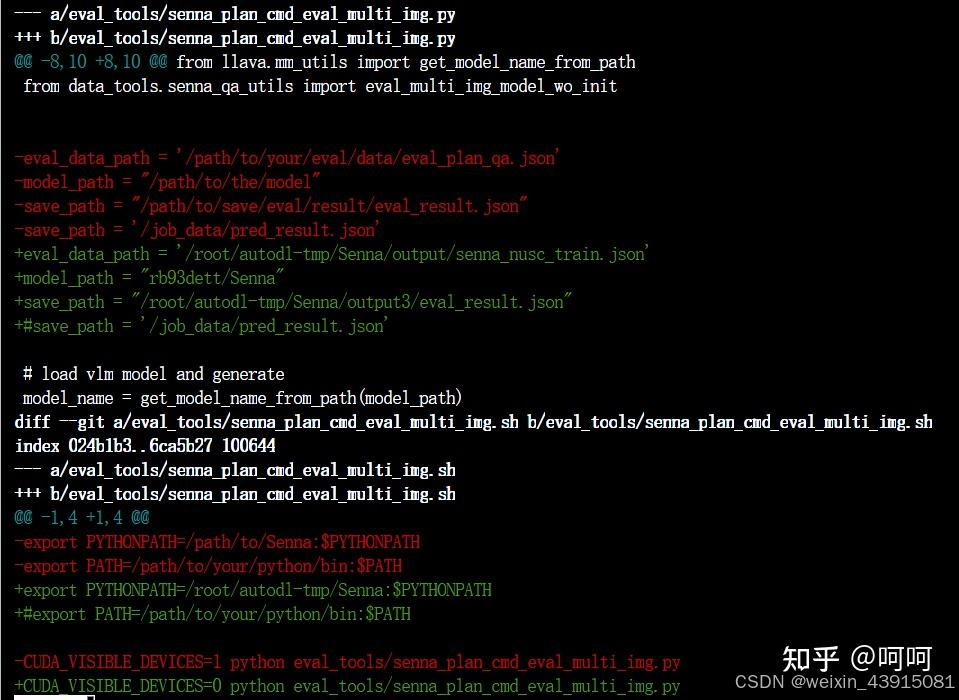

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 43
43 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)