用LangChain和Streamlit,三小时复刻出一个“AI数据分析师”,让你的Excel数据开口说话!
作为一名正在探索大语言模型(LLM)世界的小白,我总想着能否做一个既酷炫又实用的项目,来检验自己的学习成果。在我们的工作和学习中,很多人都面临这样的场景:手里有一份数据(比如产品销售记录、用户行为日志、运营数据等),我们知道这里面有宝藏,但要挖出来却不容易。它让我们能像搭乐高一样,把LLM、工具、数据源快速地**链接(Chain)**在一起,把我们的精力聚焦在业务逻辑的创新上。代码跑通了,但我们更
大家好,我是昨日嘉靖。作为一名正在探索大语言模型(LLM)世界的小白,我总想着能否做一个既酷炫又实用的项目,来检验自己的学习成果。今天,我非常兴奋地和大家分享我的最新作品:一个能通过自然语言和数据对话的“AI数据分析师”Web应用。
一、引人入胜的开篇
1. 开门见山,展示成果
先不啰嗦,直接上成果!想象一下,你只需要上传一个Excel或CSV文件,然后在聊天框里用大白话问它问题,它就能自动分析数据并告诉你答案。就像这样:
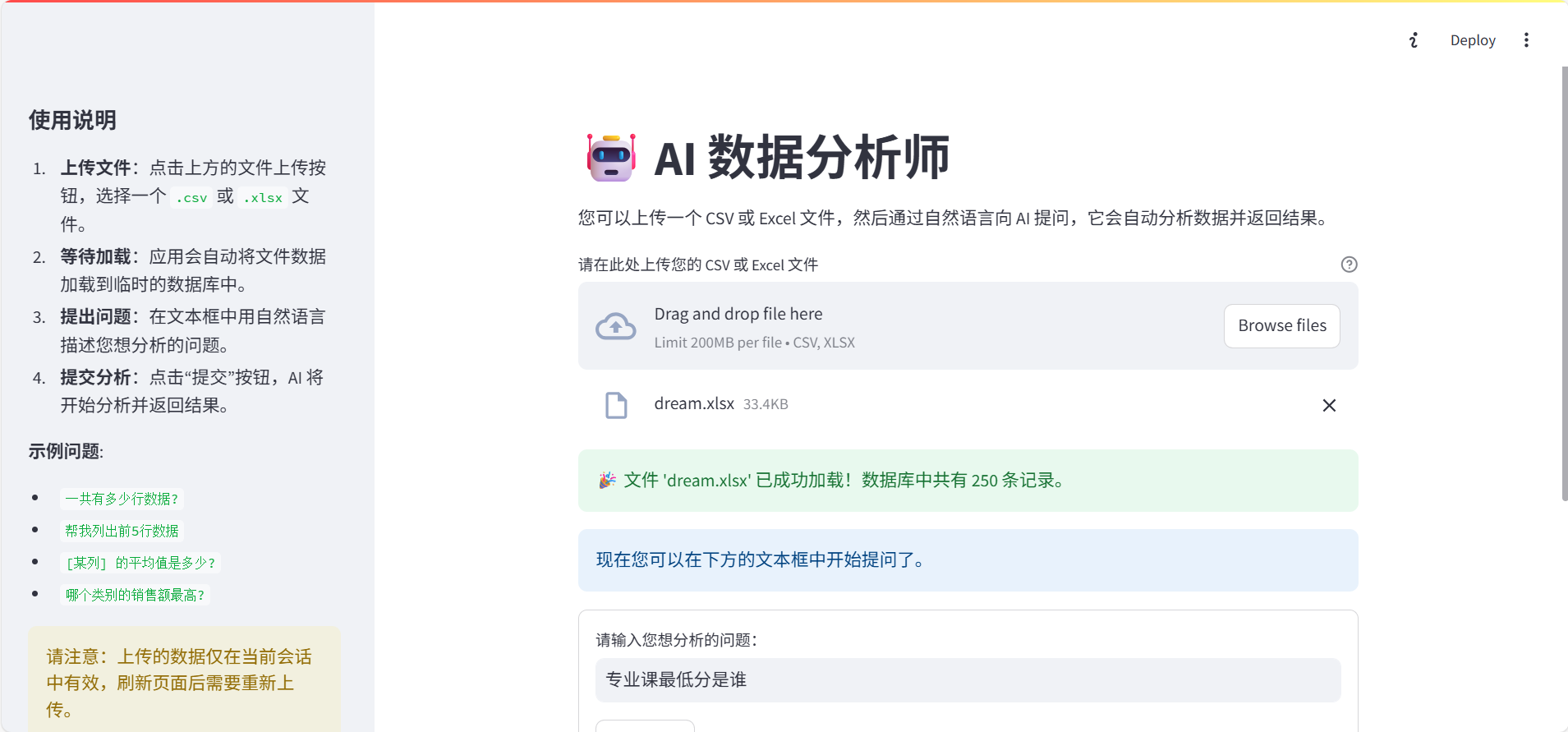
是不是感觉数据分析的门槛瞬间降低了?
2. 痛点:数据分析的“最后一公里”
在我们的工作和学习中,很多人都面临这样的场景:手里有一份数据(比如产品销售记录、用户行为日志、运营数据等),我们知道这里面有宝藏,但要挖出来却不容易。原因很简单:我们有分析需求,但我们不一定会写SQL查询,或者觉得每次都要打开工具写代码很繁琐。 这就是数据分析到洞察之间的“最后一公里”。
3. 解决方案:让AI成为你的数据助理
为了打通这“最后一公里”,我构思了这个项目。它的核心目标就是:让AI作为桥梁,将我们的自然语言“翻译”成精确的SQL查询,然后自动执行并返回结果。用户不再需要学习SQL,只需要像和助理聊天一样,就能完成数据探索。
4. 本文目标
在这篇文章中,我将毫无保留地分享整个项目的构建过程,带你从零到一,一步步实现这个AI数据分析师。我们不仅会完成代码,我还会和你深入探讨背后最核心的技术概念,比如什么是LLM Agent,以及LangChain在这个过程中到底扮演了多么重要的角色。
无论你和我一样是LLM初学者,还是有经验的开发者,相信这篇文章都能给你带来启发。
二、架构概览——“蓝图”先行
在撸起袖子写代码之前,我们先花一分钟看一下项目的整体设计蓝图。一张清晰的地图,能让我们在代码的森林里不迷路。
我们的应用其实由四个核心部分组成,它们像一个团队一样紧密协作:
[用户 User] <--> [① 前端界面 Frontend (Streamlit)] <--> [② 智能大脑 Backend (LangChain Agent)]
|
V
[③ 临时数据仓库 Database (DuckDB)]
技术选型说明
我选择的这套技术栈,可以说是兼顾了开发效率和强大功能,非常适合初学者快速上手:
- Streamlit (前端): 为什么是它?因为它能让你用纯Python代码,在几分钟内就搭建出一个漂亮、可交互的Web界面。你不需要懂任何HTML或JavaScript,对于我们这些想聚焦后端逻辑的AI开发者来说,简直是神器!
- DuckDB (数据库): 为什么不用大家熟悉的MySQL?因为DuckDB是一个轻量级的嵌入式分析数据库。它不需要单独安装和配置,可以直接在内存中运行,对CSV/Excel这类文件的分析速度极快。对于这种“即用即抛”的临时分析场景,它是完美的选择。
- LangChain (核心框架): 它在项目中扮演什么角色?一言以蔽之:“粘合剂”和“总指挥官”。LangChain将我们的“大脑”(LLM)和“数据仓库”(DuckDB)连接起来,并提供了一个叫做
Agent的强大工具,让LLM能够自主地思考、写SQL、执行SQL。 - DeepSeek (语言模型): 作为一个在代码生成方面表现优异的模型,DeepSeek能够很好地理解我们的数据分析意图并生成高质量的SQL查询。当然,你也可以很方便地替换成其他任何兼容OpenAI API的LLM。
三、手把手代码实战
好了,蓝图在手,现在我们正式开始编码!
步骤一:环境准备
一个好的开始是成功的一半。我们先把项目的地基打好。
-
项目结构:
/AI_Data_Analyst ├── .env ├── requirements.txt └── app.py -
依赖库 (
requirements.txt):
把下面这些我们需要的库写进去。streamlit langchain langchain-openai langchain-community langchain-experimental python-dotenv duckdb duckdb-engine pandas openpyxl tabulate然后在终端运行
pip install -r requirements.txt来安装它们。 -
API密钥管理 (
.env文件):
这是一个非常好的开发习惯!永远不要把你的密钥硬编码在代码里。DEEPSEEK_API_BASE="https://api.deepseek.com/v1" DEEPSEEK_API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxxxx" # 换成你自己的真实密钥
步骤二:搭建Streamlit前端界面
打开 app.py,我们先用几行代码把应用的“脸面”画出来。
# app.py
import streamlit as st
import pandas as pd
# ... (其他导入稍后添加)
# --- 界面布局 ---
st.set_page_config(page_title="AI 数据分析师", page_icon="🤖")
st.title("🤖 AI 数据分析师")
st.write("您可以上传一个CSV或Excel文件,然后通过自然语言提问,AI会自动分析数据并返回结果。")
# 使用 st.session_state 来持久化数据,防止每次交互都重新加载
# 这是提升Streamlit应用体验的关键!
if 'agent_executor' not in st.session_state:
st.session_state.agent_executor = None
# 文件上传控件
uploaded_file = st.file_uploader(
"请在此处上传您的 CSV 或 Excel 文件",
type=["csv", "xlsx"]
)
# 用户提问表单
with st.form("query_form"):
user_query = st.text_input("请输入您想分析的问题:", placeholder="例如:总销售额是多少?哪个产品的销量最高?")
submitted = st.form_submit_button("提交分析")
- 代码解释:
st.set_page_config和st.title设置了页面的基本信息。st.session_state是Streamlit的会话状态管理工具。我们把初始化好的Agent存进去,这样用户每次提问时,应用都不需要重新加载文件和创建Agent,大大提升了响应速度和用户体验。st.file_uploader和st.form创建了我们看到的交互组件。
步骤三:数据加载与处理
当用户上传文件后,我们需要读取它,并把它“喂”给DuckDB。
# app.py (接上文)
from sqlalchemy import create_engine, text
# ...
# 当用户上传新文件时执行
if uploaded_file is not None:
try:
# 根据文件类型读取数据
if uploaded_file.name.endswith('.csv'):
df = pd.read_csv(uploaded_file)
else:
df = pd.read_excel(uploaded_file)
# 创建一个内存中的DuckDB引擎
engine = create_engine("duckdb:///:memory:")
# 将Pandas DataFrame加载到名为 'user_data' 的DuckDB表中
df.to_sql('user_data', engine, index=False, if_exists='replace')
st.success(f"🎉 文件 '{uploaded_file.name}' 已成功加载!")
except Exception as e:
st.error(f"处理文件时发生错误: {e}")
- 代码解释:
- 我们用
pandas这个强大的数据处理库来读取文件。 create_engine("duckdb:///:memory:")这行代码非常有意思,它创建了一个完全在内存中运行的DuckDB实例,速度飞快,且应用关闭后会自动消失,非常适合我们的场景。df.to_sql(...)这行代码将我们DataFrame中的数据,无缝地导入到了DuckDB的一个名为user_data的表中。
- 我们用
步骤四:召唤AI核心——LangChain Agent
现在,到了最激动人心的部分!我们要把“大脑”、“数据”和“框架”组装起来。
# app.py (在文件处理的 try 块内部继续添加)
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_community.utilities import SQLDatabase
from langchain_community.agent_toolkits import create_sql_agent
import os
load_dotenv()
# 1. 初始化大语言模型 (大脑)
llm = ChatOpenAI(
model_name="deepseek-chat",
temperature=0, # 我们希望它给出稳定、精确的SQL
openai_api_key=os.getenv("DEEPSEEK_API_KEY"),
openai_api_base=os.getenv("DEEPSEEK_API_BASE")
)
# 2. 封装数据库 (让大脑能理解的“工具”)
db = SQLDatabase(engine=engine)
# 3. 创建SQL Agent (最关键的一步!)
# 我们把大脑(llm)和工具(db)交给LangChain,它会自动帮我们组装好一个智能体
agent_executor = create_sql_agent(
llm=llm,
db=db,
agent_type="openai-tools",
verbose=True, # 设置为True,可以在终端看到Agent的“思考过程”
handle_parsing_errors=True
)
# 将创建好的Agent存入会话状态
st.session_state.agent_executor = agent_executor
- 代码解释:
- 初始化LLM: 我们创建了一个
ChatOpenAI的实例,告诉LangChain我们要用哪个模型,以及如何连接它。temperature=0是个小技巧,它让模型的输出更具确定性,对于生成严谨的SQL代码非常有帮助。 - 封装数据库: 我们不能直接把数据库连接扔给LLM,
SQLDatabase(engine)的作用就是把它包装成一个LangChain标准的“工具”,这个工具包含了“查看表结构”、“执行SQL”等多个子功能。 create_sql_agent: 这就是魔法发生的地方!这个函数接收了我们定义的LLM和数据库工具,内部已经集成了一套非常强大的提示词模板和ReAct(思考-行动)逻辑。它创建出的agent_executor就是一个随时可以上岗的“数据分析师”。当它接到问题后,会自动进行如下的思考:- 思考: “用户的任务是什么?我需要哪些信息?”
- 行动: “我先看看数据库里有哪些表和列。” (调用
db.get_table_info()) - 观察: “我看到了
user_data表,里面有product_name,sales等列。” - 再次思考: “很好,现在我可以根据这些信息构建一个SQL查询了。”
- 行动: “生成SQL语句,并用SQL执行工具运行它。”
- 观察: “查询成功,得到了结果。”
- 最终思考: “现在我用自然语言把这个结果总结给用户。”
- 初始化LLM: 我们创建了一个
步骤五:运行与交互
最后一步,就是把用户的提问“喂”给我们创建好的Agent。
# app.py (在文件末尾添加)
if submitted:
if st.session_state.agent_executor is None:
st.warning("⚠️ 请先上传一个文件。")
elif not user_query:
st.warning("⚠️ 请输入您的问题。")
else:
with st.spinner('🤖 AI 正在思考中,请稍候...'):
try:
# 调用Agent来处理查询
response = st.session_state.agent_executor.invoke({"input": user_query})
# 显示结果
st.subheader("分析结果:")
st.write(response['output'])
except Exception as e:
st.error(f"分析过程中出现错误: {e}")
- 代码解释:
st.spinner提供了一个友好的加载动画,改善了用户体验。agent_executor.invoke(...)这行代码就是我们与AI交互的入口。把用户的自然语言问题传进去,然后就可以泡杯咖啡,等待AI把分析结果“端”出来了。
第四部分:核心概念深度解析 (升华部分)
代码跑通了,但我们更要理解背后的“为什么”,这才是真正的学习。
1. 什么是LLM Agent?它和简单的API调用有什么区别?
- 简单的API调用: 你问一句,AI答一句。AI像一个“计算器”,你按什么它算什么,没有自主性。
- LLM Agent: 你给它一个目标和一个工具箱。Agent像一个“聪明的工匠”,它会自己思考如何分步骤、如何使用工具来达成这个目标。它有自主性,能进行多步推理,这是迈向通用人工智能的关键一步。我们的SQL Agent就是一个典型的例子。
2. RAG vs Fine-tuning
- Fine-tuning (微调): 像“填鸭式教育”。你找来成千上万个“问题-SQL”的例子,把它们都喂给模型,让模型死记硬背下这种转换模式。成本高,且对新出现的数据表结构适应性差。
- RAG (检索增强生成): 像“开卷考试”。我们不直接教模型答案,而是给它一本“参考书”(在本项目中,就是通过工具实时获取数据库的表结构信息)。当遇到问题时,它先翻阅参考书,然后结合参考书的内容来回答问题。我们的Agent模式,就是一种广义上的、动态的RAG,它适应性更强,成本更低。
3. LangChain的价值
如果没有LangChain,我们要自己手动编写与LLM交互的循环逻辑、自己拼接复杂的提示词、自己处理工具的调用和返回。LangChain把这些繁琐的、重复性的工作全部标准化、模块化了。它让我们能像搭乐高一样,把LLM、工具、数据源快速地**链接(Chain)**在一起,把我们的精力聚焦在业务逻辑的创新上。
五、总结与展望
回顾成果
恭喜你!通过这篇文章,我们从零到一构建了一个功能完整的AI数据分析师应用。它不仅是一个有趣的项目,更是一个绝佳的、用来理解现代AI应用架构的实践案例。
分享心得(我踩过的坑)
在开发过程中,我遇到了一个langchain库版本更新导致的小问题。旧版本create_sql_agent可以直接接收一个engine对象,而新版本要求传入一个SQLDatabase对象。这个小插曲提醒了我:AI领域技术迭代飞快,保持对官方文档的关注,理解API的变化非常重要!
展望未来
这个项目只是一个起点,我们可以让它变得更强大:
- 数据可视化: 让Agent不仅能返回文本,还能根据数据生成图表(比如调用Matplotlib或Plotly)。
- 处理大数据: 对于无法加载到内存的大文件,可以探索使用DuckDB直接查询外部Parquet/CSV文件的能力。
- 连接生产数据库: 将其连接到公司真实的PostgreSQL或MySQL数据库,成为一个真正可用的内部工具。
鼓励与分享
AI的世界广阔而精彩,动手实践是最好的学习方式。希望这篇文章能点燃你的热情!
我已将完整的项目代码上传到了GitHub,欢迎大家Star、Fork,并在此基础上构建出更有趣的应用!
GitHub链接:https://github.com/ljzjxza/AI-Data-Analyst
感谢你的阅读!如果觉得文章对你有帮助,别忘了点赞、收藏、加关注哦!我们下篇文章再见!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)