ES日志报警方案调研
针对业务文档类数据的日志监控的项目基本没有,只有ElasAlert还算可用,在使用了一段时间之后,面临很多棘手的问题:死板的调度策略(只能统一每隔x分钟,所有监控调度一次,经常不知道堵在哪个监控),报警内容无法做灵活定制,配置文件管理困难,后面我们的配置文件数量达到200左右,一个配置文件配置不当,进程挂掉或阻塞,最后效果可以说很不理想。frostmourne还需要数据库,xxl-job等,但因为
报警方案
基本思路:
监控(定时任务检查ES) -> 如条件匹配 ->报警(发送邮件、微信...)
方案一:ES+ Grafana + prometheus AlertManager
实现:Grafana监控ES数据,如果匹配报警条件,使用AlertManager进行报警。
支持企微、邮件
不推荐理由:
1 收到报警后具体还得看日志系统,不能直接展现日志信息
2 环境依赖:Grafana需要装ES插件、prometheus装AlertManager
3 日志信息全在Message一个字段里面,没有再区分字段,不好查询统计。
方案二:ES + ElastAlert
Yelp公司开源,Yelp是美国最大点评网站,2004年,Yelp在旧金山起步。2012年3月2日登陆纽交所,股票代码为“YELP”,共发行715万股普通股。按照15美元的发行价计算,Yelp融资额为1.07亿美元,市值为60亿美元 [1] 。
ElastAlert是一个python项目,通过提供的规则添加一个个的配置文件,实现监控和报警。
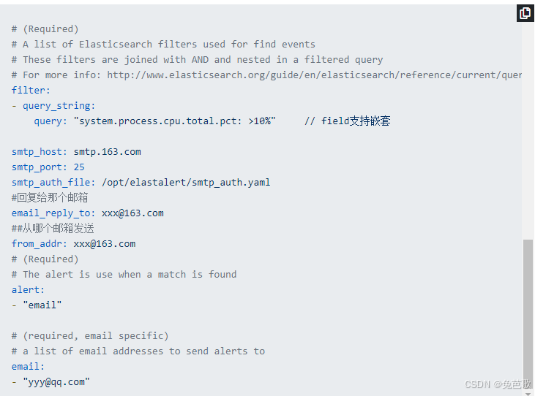
简介
ElastAlert是一个简单的框架,用于从Elasticsearch中的数据中对异常、峰值或其他感兴趣的模式发出警报。
在Yelp,我们使用Elasticsearch、Logstash和Kibana来管理不断增加的数据和日志。Kibana非常适合可视化和查询数据,但我们很快意识到它需要一个配套工具来提醒数据中的不一致性。出于这种需要,ElastAlert应运而生。
如果您有近实时写入Elasticsearch的数据,并且希望在该数据与某些模式匹配时收到警报,ElastAlert是您的工具。
ElastAlert有三个主要组件,可以作为模块导入或定制:
1 规则类型
2 警报
3 增强
使用
前端UI:其它国外开发者开源elastalert-kibana-plugin,用于在页面上配置规则,报警等。
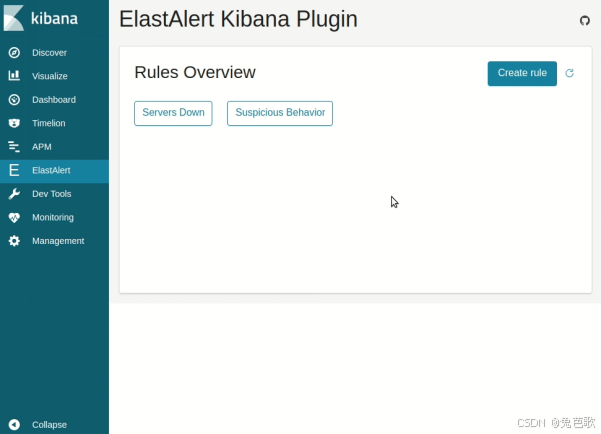
后端:ElastAlert。规则丰富,但报警方式没有企微,如果使用企微,需使用国内开发者开源的elastalert-docker。
案例
邮件、企微
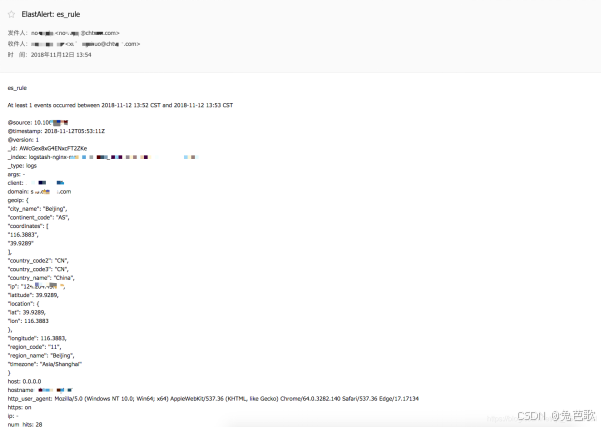
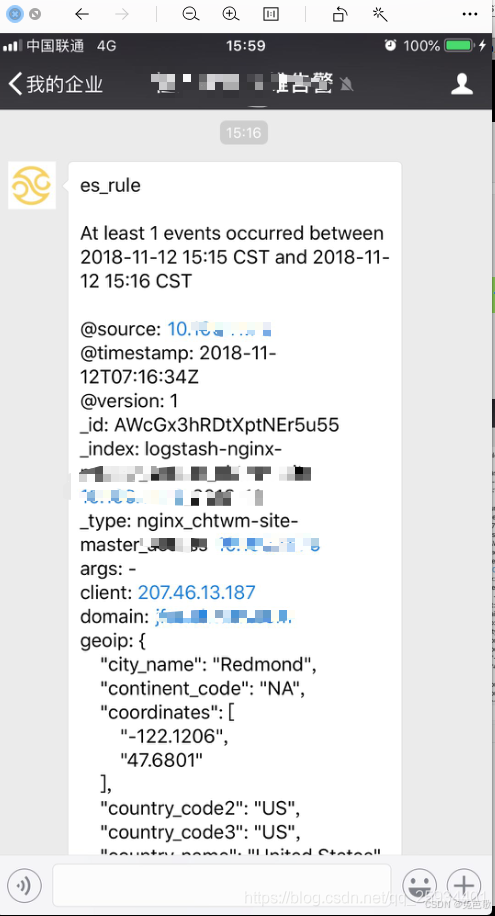
资料链接:https://blog.csdn.net/qq_25934401/article/details/83993034
小缺陷
1 不支持企微,但有个人开发者的开源插件:
https://github.com/anjia0532/elastalert-docker
2 会有非常多的配置文件
3 UI是其他开发者开源的,据说不是特别友好
4 使用ui需要依赖kibana,作为插件安装到kibana
优点
规则丰富
文档
github
https://github.com/Yelp/elastalert/blob/master/docs/source/elastalert.rst
官方文档
https://elastalert.readthedocs.io/en/latest/ruletypes.html#rule-types
其他开发者开源前端UI插件文档
https://github.com/bitsensor/
ES + sentinl
简介
sentinl是基于javascript开发的kibana插件,提供了X-Pack两款收费组件:Alert(告警)和Reporting(报表)的替代功能,它将前端UI、webserver和告警逻辑代码都集成在一个项目中,告警功能配置简单、页面美观、操作友好,UI完全秒杀elastalert-kibana-plugin。Report功能就问题较多,生成的报表也有很多瑕疵。
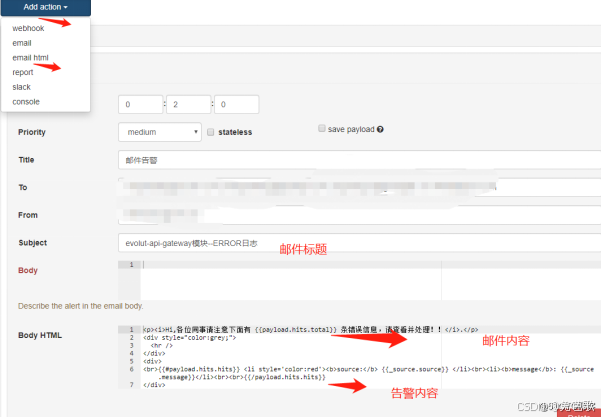
案例
企业微信告警:
- 登录企业微信-创建群聊-创建机器人
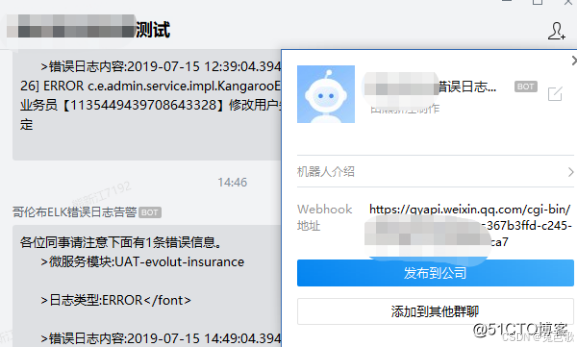
- 在kibana的Sentinl里面的错误日志告警添加webhook
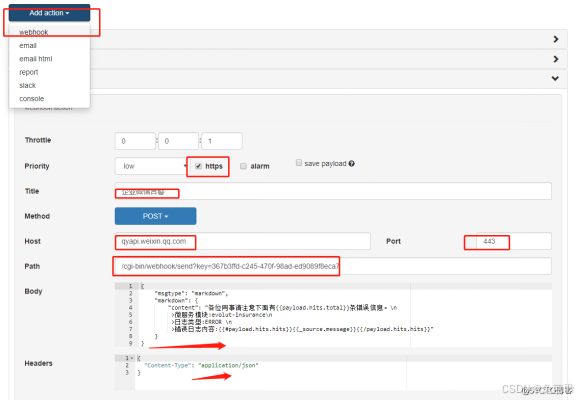
文档
github
https://github.com/sentinl/sentinl/releases
官方文档
https://sentinl.readthedocs.io/en/latest/
Sentinl & ElastAlert对比
与elastalert相比较,就告警功能而言的话,如果要求不高,推荐使用sentinl,因为安装容易并且配置简单;但如果有复杂的告警场景或独立的告警方式,那推荐选择elastalert。
整理一个对比表格,想必这样看起来更直观:
|
比较 |
Sentinl |
ElastAlert |
|
安装 |
简单 |
一般复杂 |
|
配置 |
简单 |
一般复杂 |
|
UI |
简单美观 |
不友好 |
|
告警规则数量 |
1 |
11 |
|
告警方式数量 |
6 |
11 |
|
告警方式隔离 |
不独立 |
独立 |
|
开发语言 |
javascript |
python |
|
后端配置透明度 |
不透明 |
透明 |
|
成熟度 |
700+ star |
5000+ start |
|
开发者数量 |
28 |
160 |
|
commit数 |
1500+ |
1800+ |
|
最近更新 |
2020-8-21 |
2020-4-16 |
根据上述表格,我们可以看出各有各的优势,sentinl更加偏向于集成进kibana的一种页面展示插件,而elastalert则是更偏向与后端告警功能的打磨。单从告警功能来看,elastalert看起来更强大一些,但是sentinl也有它的优势,UI非常地棒,其次还支持report功能。
ES+frostmourne(霜之哀伤)
简介
frostmourne(霜之哀伤)是汽车之家经销商技术部监控系统的开源版本,用于帮助开发监控应用日志,现主要用于监控Elasticsearch数据。 关于内部日志系统的设计实现感兴趣的话,请移步文章: 之家经销商技术部基于Elasticsearch的日志系统设计与实现 可以认为frostmoure是监控部分的实现。 如果你现在使用Elastic stack(ELK)建立起了日志系统,却苦恼于没有一个配套日志监控系统,也许它能帮到你。
- 主要功能
-只需要写一条数据查询就可以轻松搞定监控
-多数据源(Elasticsearch, InfluxDB, Mysql, ClickHouse)支持
-多种数值计算类型监控(count,min,max,avg,sum,unique count,percentiles,standard deviation)
-数值同比监控
-HTTP数据监控, js表达式判断是否报警
-UI功能,简单易用
-监控管理,测试,另存。执行日志,历史消息。
-灵活的报警消息freemarker模板定制,支持变量;消息模板管理
-多种报警消息发送方式(email,短信,钉钉(机器人),企业微信(机器人), HTTP请求)
-Elasticsearch数据查询,分享,下载
-报警消息附带日志查询短链接,直达报警原因
-报警消息抑制功能,防止消息轰炸
-每个监控都是独立调度,互不影响
-自带账号,团队,部门信息管理模块,也可自己实现内部对接
-集成LDAP登录认证
-权限控制,数据隔离,各团队互不影响
平台设计
https://segmentfault.com/a/1190000021494332
开源的日志监控相关产品基本都是针对指标类时序数据的主机监控,比如:zabbix,open-falcon, Prometheus等。针对业务文档类数据的日志监控的项目基本没有,只有ElasAlert还算可用,在使用了一段时间之后,面临很多棘手的问题:死板的调度策略(只能统一每隔x分钟,所有监控调度一次,经常不知道堵在哪个监控),报警内容无法做灵活定制,配置文件管理困难,后面我们的配置文件数量达到200左右,一个配置文件配置不当,进程挂掉或阻塞,最后效果可以说很不理想。在经历这些过程后,决定自研一套监控系统。
主要功能有程序日志监控,访问日志监控,慢日志监控,http调用监控,metric监控。目前运行监控数量近800个,基本线上有问题,开发同事分钟级别就能收到报警。
无论是从使用者的反馈和运行情况来看,效果还是很理想的。下面是一张监控配置的页面截图:
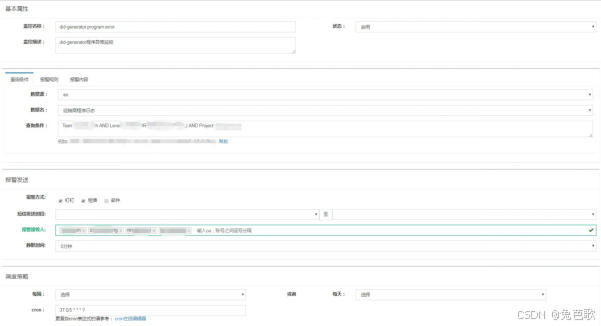
案例
在线demo:
https://frostmourne-demo.github.io/
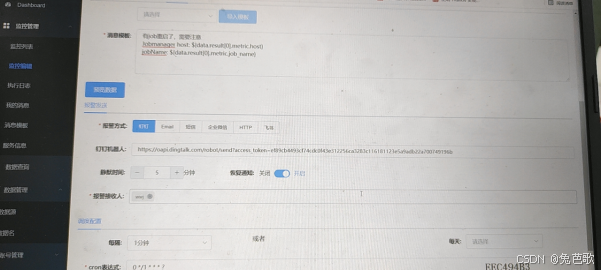
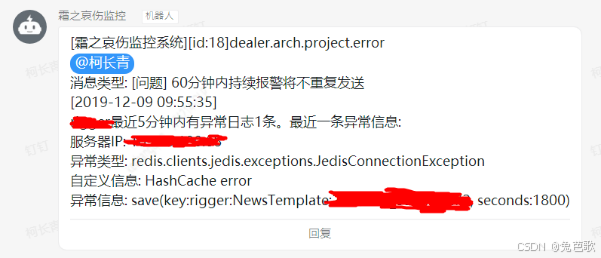
文档
gitee
https://gitee.com/tim_guai/frostmourne
小总结
个人想法
ElastAlert和frostmourne比较起来,
ElastAlert应该是质量更高(总觉得国外的比国内的强),有丰富的规则和报警。但是前端UI由其他开发者开源做的可能不是很完善。企微报警需要使用国内开发者开源的插件。
frostmourne国内开源java项目,有问题跟开源方沟通起来比较方便。但是他的定时任务执行用的是自己写的查询语句,怀疑性能比不上ElastAlert的规则配置方式。得单独弄一个项目,依赖数据库,xxl-job等。
这两个我都非常看好(O(∩_∩)O~),
从个人来说更喜欢ElastAlert,因为觉得国外项目更高级些,规则丰富强大,还可以从他们设计的规则等等窥视他们的思路,可以学习英语,扩充python技术栈。
从公司技术栈匹配来说,虽然frostmourne还需要数据库,xxl-job等,但因为是个java项目,还是国产,理解和沟通占优势,虽然看着项目很大,但用起来反而可能会简单一些。但报警涉及部门的逻辑也需要适配我们自己的情况。 虽然可能不够高级,但应该够用了。
期望效果
需报警日志
- 1 程序中未处理的运行错误日志
程序启动中或执行过程中出现的报错信息
- 2 程序中关注的error/warn日志
- -程序中try catch的异常
以项目为单位输出到单独的日志文件,建立单独索引,进行监控
- -特别关注的某些业务行为
跟运营同事收集哪些行为是需要特别关注的,程序埋点,以每个行为为单位输出到单独的文件,建立单独索引,进行监控
报警方式
报警规则
1 程序中未处理的运行错误日志
每两分钟检查一次,只要发现就报警
2 程序中关注的error/warn日志
-程序中try catch的异常
每两分钟检查一次,只要发现就报警
-特别关注的某些业务行为
每X分钟检查一次,超过行为次数的阈值就报警
报警途径
企微群 /邮件

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)