[arXiv 2024]BrainMAE: A Region-aware Self-supervised Learning Framework for Brain Signals
计算机-人工智能-fMRI解码和重建大模型用于年龄/行为/任务分类

论文网址:[2406.17086] BrainMAE: A Region-aware Self-supervised Learning Framework for Brain Signals
论文代码:https://anonymous.4open.science/r/fMRI-State-F014
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.3.1. Region-aware Graph Attention
2.3.2. Brain Masked AutoEncoder
2.4.1. Model Validation with Synthetic Data
2.4.3. Pre-training Evaluation
2.4.4. Transfer Learning Evaluation
2.6. Discussion and Conclusion
1. 心得
(1)早点发出去啊!!我要用你了!!给个名头!
(2)如果训练的人能再多一点就好了,这样看上去好像就几千个,能不能做大做强
(3)好人更一下代码!!看不到了!!拿给我用啊!!
2. 论文逐段精读
2.1. Abstract
①Challenges: dynamic representation of functional connectivity (FC) and noise
2.2. Introduction
①Modeling method: Fixed-FC and Dynamic-FC(简而言之就是前面那个是把整个BOLD序列拿来求相关矩阵,后面的就是类似滑完窗分了不同时间窗再分别求相关矩阵)
2.3. Approach
①Pipeline of BrainMAE:
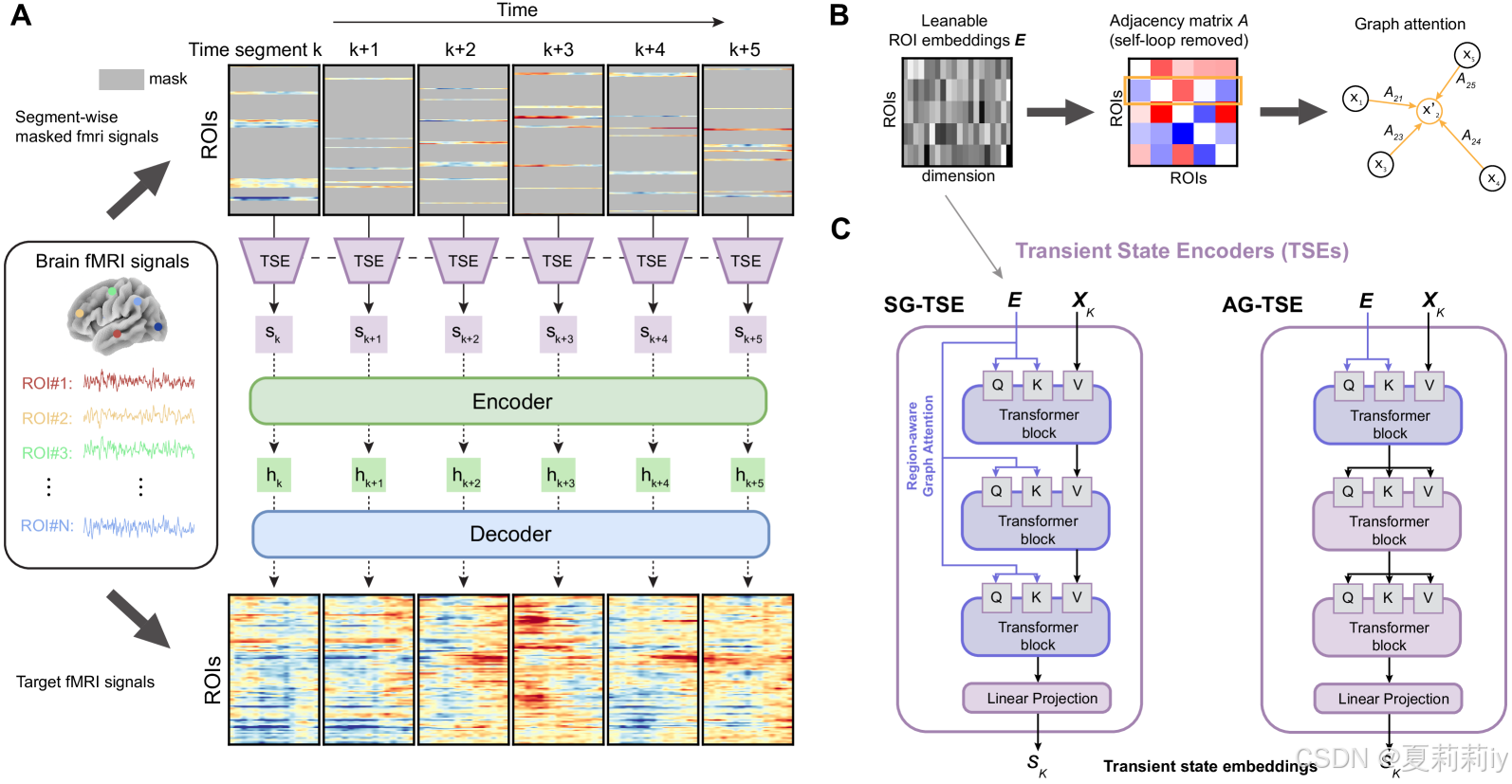
2.3.1. Region-aware Graph Attention
①"There is a notable similarity in the representation properties between brain ROIs and words in language"(尊都假嘟?直接说ROI和单词很像??也没有引用论文啊。”单独都有特征,组合在一起会变成更复杂的特征。“啊啊啊啊啊啊啊啊有点没有必要了吧)
②“因此,在语言建模研究的推动下,我们分配了一个可学习的d维向量,称为 ROI 嵌入”(啊.....ROI的嵌入为什么是语言来的...)全脑的ROI嵌入式
③Node (ROI) feature:
④Node set:
⑤⭐Adjacency matrix: ,
where
denotes similarity measurement and the
is asymmetry
⑥Attention score between nodes:
⑦Node feature aggregation:
2.3.2. Brain Masked AutoEncoder
①Time points segmentations: each window with size , and
②作者设计了静态图Transient State Encoder(SG-TSE)和动态图Transient State Encoders(AG-TSE),具体区别看主图,比较明显。最终单个时间窗的输出经过线性层变成
③Mask: 70%
④Reconstruction loss: MSE:
2.4. Experiments
2.4.1. Model Validation with Synthetic Data
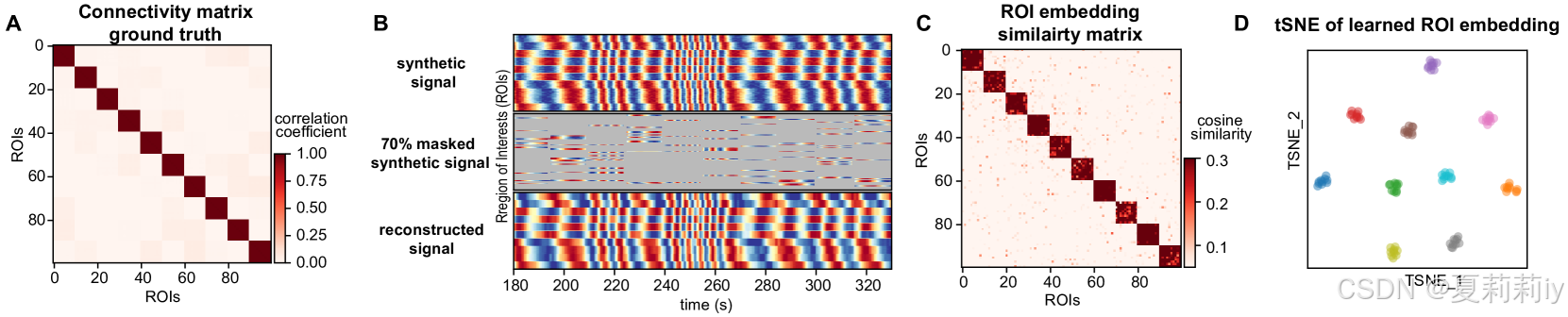
①Pre-training SG-BrainMAE on synthetic data:
2.4.2. fMRI Datasets
①Datasets: HCP-3T with 897 healty subjects, HCP-7T with 184, HCP-Aging with 725 and NSD with 8
2.4.3. Pre-training Evaluation
(1)Implementation Details
①Time points selection: 300s
②Segmentaion number: 20, for 15s each
③Mask ratio for each batch: (0, 0.8)
④Epoch: 1000
(2)Masked Signal Reconstruction
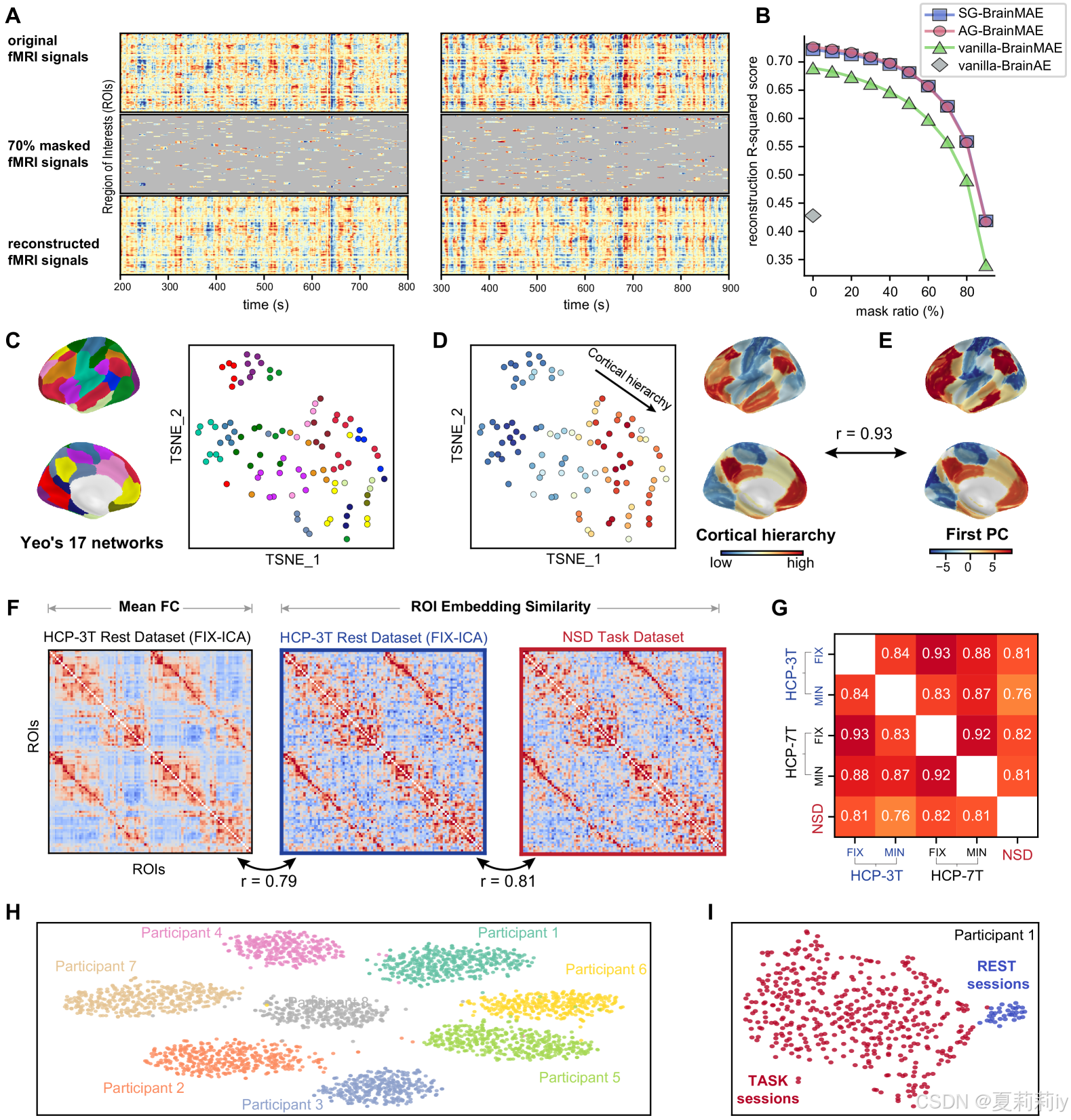
①Reconstruction visualization (A) and performance (B):
(3)ROI Embeddings
①讲了上图C是他们的ROI特征聚类,D是t-sne分布展示,F和G是可视化的功能连接矩阵
(4)Representation Analysis
①Session separation on H and I
2.4.4. Transfer Learning Evaluation
(1)Implementation Details
①Cross validation: 5 fold
(2)Steady-state Variables Prediction
①Compared with behavior prediction model:
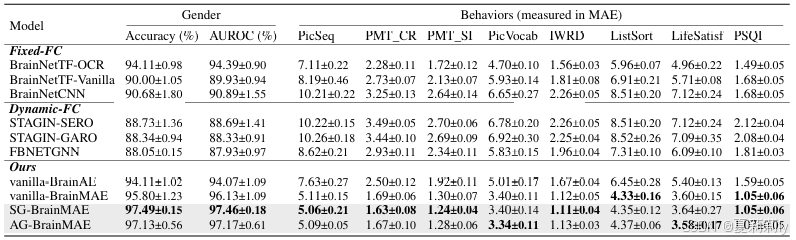
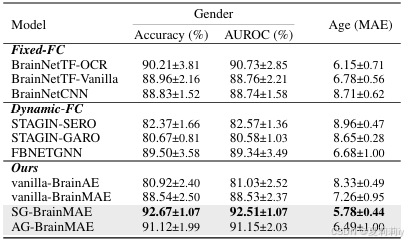
②Compared with age prediction models:
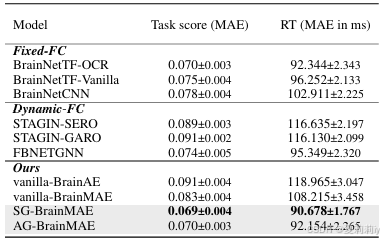
③Compared with task models:
(3)Transient Mental State Decoding
①Mental state classification on transient signal (about 10s)
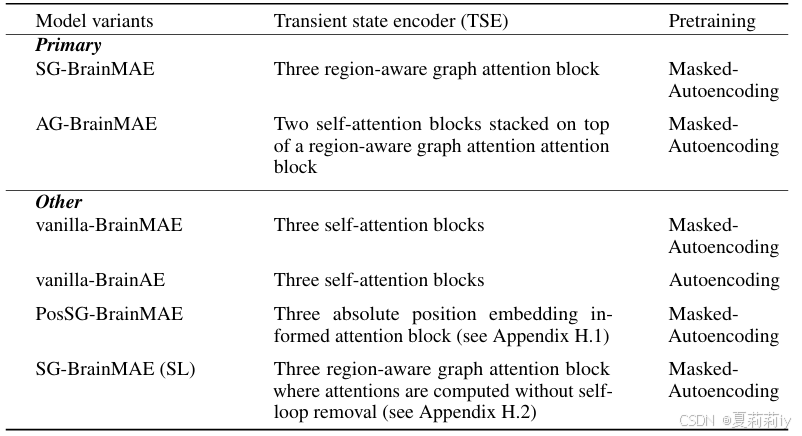
(4)Ablation Study
①Difference of proposed models:
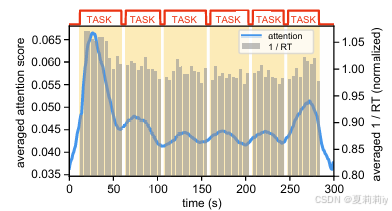
(5)Interpretation Analysis
①Attention score:
2.5. Related Work
①Lists auto encoder models and brain network analysis methods
2.6. Discussion and Conclusion
~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)