大模型的开发应用(十四):基于RAG的法律助手项目(中):改进优化
文本嵌入模型分不清主动和被动的区别;检索出的结果相关,但答非所问;与问题不相关的节点,相似度(相关度得分)却很高;模型的回复不完整,没回复完就停了,也有可能是回复完了,但打印的不完整。本文就来解决这些问题。在系统中,重排序模型的作用是优化和提升检索结果的序质量,将最相关、最有助于生成高质量回复的文档(或节点)排在最前面。检索获得文档(或节点)列表后,重排序模型会仔细评估每个候选文档(节点)与用户查
改进优化
0 前言
上篇文章,我们实现了基于RAG的法律助手,但它系统存在以下几个问题:
- 文本嵌入模型分不清主动和被动的区别;
- 检索出的结果相关,但答非所问;
- 与问题不相关的节点,相似度(相关度得分)却很高;
- 模型的回复不完整,没回复完就停了,也有可能是回复完了,但打印的不完整。
本文就来解决这些问题。
1 检索结果重排序
1.1 什么是重排序模型
在系统中,重排序模型的作用是优化和提升检索结果的序质量,将最相关、最有助于生成高质量回复的文档(或节点)排在最前面。 检索获得文档(或节点)列表后,重排序模型会仔细评估每个候选文档(节点)与用户查询的实际关联程度,并根据相关性分数对文档进行重新排序。
下面是关于检索器、重排序模型、生成模型的比喻:
- 相似度检索器像“快速扫描仪”: 图书馆里快速扫描所有书架,把标题或摘要看起来和问题沾边的20本书(检索结果)都迅速堆到桌子上。
- 重排序模型像“精明的图书管理员”: 这位图书管理员会仔细翻看这20本书的每一本,对照读者的问题,判断哪几本书的内容真正深入契合问题核心,然后把这最相关的3-5本书挑出来摆在读者面前。
- 生成模型像“专家”: 这位专家只看精明的图书管理员挑选出来的那3-5本最相关的书,快速阅读书中精华内容,然后直接给读者一个针对性的解答。
1.2 重排序模型的作用
重排序模型在这一流程中扮演着至关重要的过滤器和优化器角色,其核心作用体现在:
-
提升上下文相关性:
- 克服检索器局限性: 检索阶段追求速度,通常使用简单、高效的向量相似度方法(如基于BERT的稠密向量检索)。这种方法虽然能快速找到可能相关的文档,但无法深入理解查询和文档之间复杂的语义关系和词语交互。
- 精准计算相关性: 重排序模型通常使用更强大、更复杂的句子对分类模型。它们会将查询文本和单个文档文本一起输入模型,进行深度交互(Cross-Interaction),计算出一个精细的、能真实反映两者相关程度的分数。这比简单的向量点积要准确得多。
- 识别微妙关联: 它更能识别关键词匹配但实际不相关、看似不匹配但语义高度相关(如同义词、意译)等复杂情况。
-
优化生成输入:
- Top-K 原则: LLM在生成阶段能有效处理的上下文文档数量非常有限(比如只取 Top 5 或 Top 10)。
- 确保Top文档最强相关: 重排序后,最前面的文档是与查询最相关的文档。这使得最终提供给LLM的上下文信息质量最高,显著增加了LLM生成准确、相关、高质量回答的可能性。如果检索阶段返回的Top文档相关性不高,会误导LLM。
-
减少噪声干扰:
- 剔除低质量文档: 检索阶段可能会返回一些相关性不高或甚至误导性的文档。重排序模型通过对所有候选文档重新打分排序,能有效地将这些低质量文档推到列表底部,从而显著减少它们最终被送入生成阶段污染LLM的风险。
-
提升最终答案质量:
- 以上几点最终汇聚成一个结果:LLM获得的信息输入质量更高(Top K文档都是精挑细选的高度相关上下文),从而能够产生更准确、更相关、更可靠、更具信息量的答案。
1.3 为什么不在检索器上一次性搞定?
- 效率与精度的权衡: 检索器需要处理海量文档(可能数百万/千万级),必须追求速度(毫秒级响应)。因此,它不得不采用计算效率高但精度相对较低的相似度计算方法(如基于Embedding的ANN搜索)。重排序模型虽然计算更复杂、更耗时(通常需要几十到几百毫秒),但因为它只需要处理检索器返回的少量候选(如100-200个文档),总体延迟可控,且能显著提升最终效果。
1.4 重排序模型的原理
重排序模型一般都是以 Encoder-only 作为核心计算引擎,典型模型有:BERT、RoBERTa、ELECTRA、DeBERTa等及其精炼版本(如MiniLM、TinyBERT)。
重排序的时候,对于检索器返回的Top K(如100-200个)候选文档,逐个和查询文档按照下面的方式拼接,形成“查询-文档对”:
[CLS] [查询语句] [SEP] [候选文档文本] [SEP]
[CLS]:特殊分类标记,其最终隐状态通常用于表示整个“查询-文档”对的语义融合。[SEP]:分隔符,用于区分查询和文档片段。
取 [CLS] 位置的隐藏层向量作为查询-文档对”的特征表示,并将其输入到全连接层(该层只有一个输出),并使用Sigmoid激活函数,输出值(Sigmoid后)在 [0, 1] 之间,表示相关性的概率或直接作为可比较的分数。获得分数后,按该分数对K个文档降序排列,选择新的Top N(如5-10个)送入生成器。
比较常用的重排序模型有 bge-reranker、multilingual-e5(多语言)、m3e等,截止6月25日,本月刚发布的 Qwen3-Reranker-8B 是这个领域的最强模型。
关于重排序模型的原理,我们了解到这里就行了。
1.5 总结
重排序模型是RAG系统中一个关键的可选(但非常推荐)优化模块。它通过对快速检索器返回的候选文档进行基于深度交互的精准相关性排序,筛选出质量最高、最相关的Top文档(节点),极大地改善了最终提供给生成阶段LLM的上下文信息质量,从而在整体上显著提高了RAG系统输出答案的准确性和可靠性。它是弥补高效检索器和高质量生成之间“质量鸿沟”的重要桥梁。
2 添加重排序模型
2.1 代码
重排相当于重新筛选的过程,因此初始检索的结果要多一些,让重排序模型有更多选择比较的余地。这里我们在检索阶段选择与问题相似度最高的10个知识节点,然后对这十个节点进行重排序,选择相关性得分最高的3个结果作为依据。
这里我们使用提示词模板,以控制大模型的输出。
新的代码如下(只显示修改部分):
from llama_index.core import get_response_synthesizer
from llama_index.core.postprocessor import SentenceTransformerRerank # 新增重排序组件
QA_TEMPLATE = (
"<|im_start|>system\n"
"您是中国劳动法领域专业助手,必须严格遵循以下规则:\n"
"1.仅使用提供的法律条文回答问题\n"
"2.若问题与劳动法无关或超出知识库范围,明确告知无法回答\n"
"3.引用条文时标注出处\n\n"
"可用法律条文(共{context_count}条):\n{context_str}\n<|im_end|>\n"
"<|im_start|>user\n问题:{query_str}<|im_end|>\n"
"<|im_start|>assistant\n"
)
response_template = PromptTemplate(QA_TEMPLATE)
class Config:
EMBED_MODEL_PATH = "/data/coding/models/sungw111/text2vec-base-chinese-sentence"
LLM_MODEL_PATH = "/data/coding/models/Qwen/Qwen1.5-1.8B-Chat"
RERANK_MODEL_PATH = "/data/coding/models/BAAI/bge-reranker-large"
DATA_DIR = "/data/coding/data"
VECTOR_DB_DIR = "/data/coding/chroma_db"
PERSIST_DIR = "/data/coding/storage"
COLLECTION_NAME = "chinese_labor_laws"
TOP_K = 10 # 扩大初始检索数量
RERANK_TOP_K = 3 # 重排序后保留数量
def init_reranker_model():
# 初始化重排序模型
reranker = SentenceTransformerRerank(
model=Config.RERANK_MODEL_PATH,
top_n=Config.RERANK_TOP_K
)
return reranker
def main():
embed_model, llm = init_embedding_model(), init_llm_model()
reranker = init_reranker_model()
# 仅当需要更新数据时执行
if not Path(Config.VECTOR_DB_DIR).exists():
print("\n初始化数据...")
nodes = load_and_create_nodes(Config.DATA_DIR)
else:
nodes = None # 已有数据时不加载
# 初始化向量存储
print("\n初始化向量存储...")
start_time = time.time()
index = init_vector_store(nodes)
print(f"索引加载耗时:{time.time()-start_time:.2f}s")
# 创建检索器和响应合成器(修改部分)
retriever = index.as_retriever(
similarity_top_k=Config.TOP_K
)
response_synthesizer = get_response_synthesizer(
text_qa_template=response_template,
verbose=True
)
# 示例查询
while True:
question = input("\n请输入劳动法相关问题(输入q退出): ")
if question.lower() == 'q':
break
# 执行检索-重排序-回答流程(新增重排序步骤)
start_time = time.time()
# 1. 初始检索
initial_nodes = retriever.retrieve(question)
retrieval_time = time.time() - start_time
for node in initial_nodes:
node.node.metadata['initial_score'] = node.score # 保存初始分数到元数据
# 2. 重排序
reranked_nodes = reranker.postprocess_nodes(
initial_nodes,
query_str=question
)
rerank_time = time.time() - start_time - retrieval_time
# 3. 合成答案
response = response_synthesizer.synthesize(
question,
nodes=reranked_nodes
)
synthesis_time = time.time() - start_time - retrieval_time - rerank_time
# 显示结果(修改显示逻辑)
print(f"\n智能助手回答:\n{response.response}")
print("\n支持依据:")
for idx, node in enumerate(reranked_nodes, 1):
# 兼容新版API的分数获取方式
initial_score = node.metadata.get('initial_score', node.score) # 获取初始分数
rerank_score = node.score # 重排序后的分数
meta = node.node.metadata
print(f"\n[{idx}] {meta['full_title']}")
print(f" 来源文件:{meta['source_file']}")
print(f" 法律名称:{meta['law_name']}")
print(f" 初始相关度:{node.node.metadata['initial_score']:.4f}")
print(f" 重排序得分:{node.score:.4f}")
print(f" 条款内容:{node.node.text[:100]}...")
print(f"\n[性能分析] 检索: {retrieval_time:.2f}s | 重排序: {rerank_time:.2f}s | 合成: {synthesis_time:.2f}s")
if __name__ == "__main__":
main()
输入问题进行测试


可以看到,虽然大模型仍然在胡说八道,说明提示词模板并没能控制模型的回答范围,提示词模板想要发挥作用,需要更强大的模型才行,我们这里用的模型太小了,无法完全按照模板中的指令来回答。但三条依据的重排序得分都非常低,我们可以设定一个阈值过滤掉。
也就是说,对于 “与问题不相关的节点,相似度(相关度得分)却很高” 的问题,我们可以通过重排序,把 “不相关的知识节点” 过滤掉。
再来看一个列子: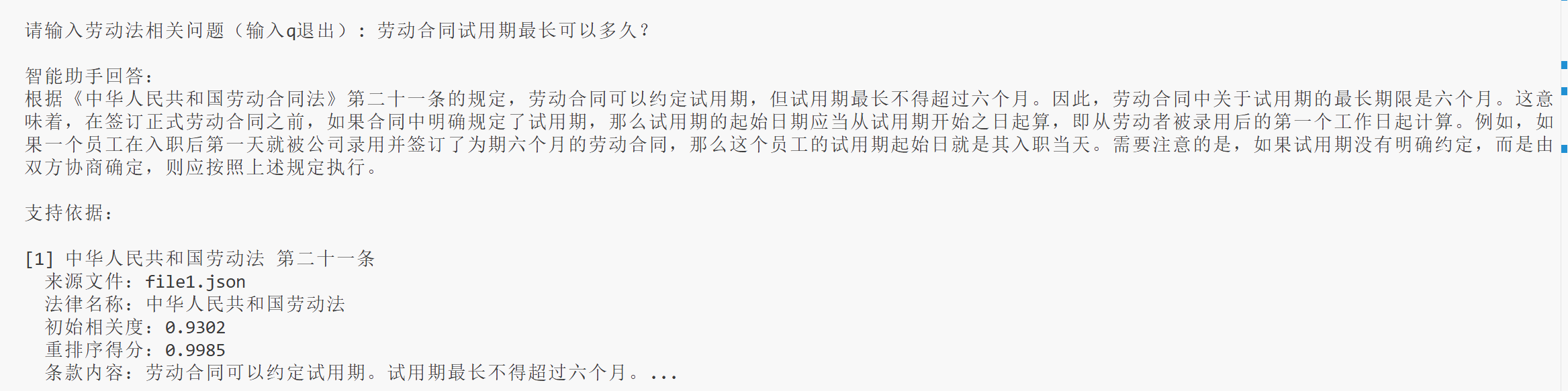

可以看到,三个依据都有规定试用期长度,重排序后的结果是相当靠谱的。
2.2 重排序后的结果分析
我们再看一个例子:

上面第3个依据没有打印完整,完整内容是下面这样的。
"中华人民共和国劳动合同法 第九十三条": "对不具备合法经营资格的用人单位的违法犯罪行为,依法追究法律责任;劳动者已经付出劳动的,该单位或者其出资人应当依照本法有关规定向劳动者支付劳动报酬、经济补偿、赔偿金;给劳动者造成损害的,应当承担赔偿责任。",
重排序得到的3条依据,前两条都提到了单位解除劳动合同需要支付赔偿,是我们想要的结果,第三条虽然也提到了赔偿,但并不是解除劳动合同导致的赔偿,并不是我们想要的结果,因此它的重排序得分明显低于前面两条,这个后面可以通过阈值进行过滤。可以得出结论:重排序模型能减少“相关,但答非所问”的检索结果出现。
重排序得到的三条依据并没有出现多大问题,但模型却出现了错误的回答,这是因为我们使用的模型太小了,而计算经济补偿需要模型有一定的推理能力。与此同时,模型没有回答完就停了(也有可能是回答完了,但打印的不完整)。
再来看下一个例子
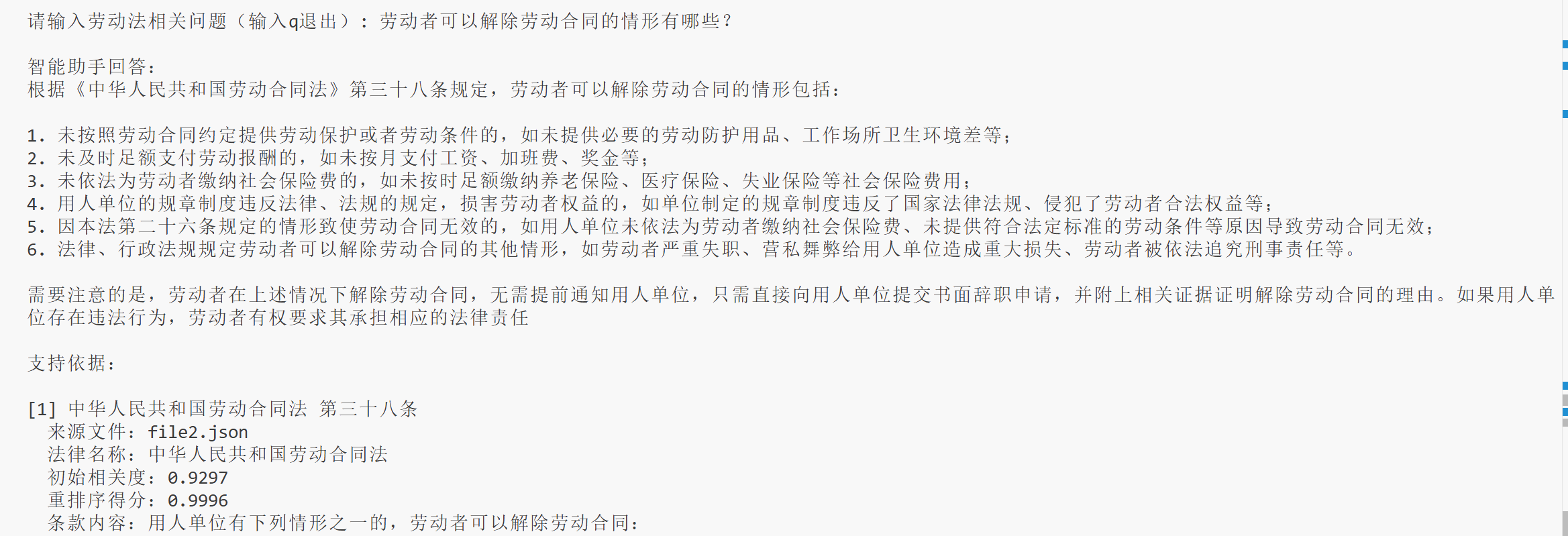

可以看到,三条依据都是和解除劳动合同相关,但我们想要的只有第一条,另外两条都是讲公司开除员工的,并不是我们想要的答案,但它们的重排序得分却非常高,也就是说,重排序后,依然分不清主动和被动的区别。
嵌入模型和重排序模型虽然分不清主动和被动,但大模型却能分清,大模型最后的回答只采纳了第一条依据,回答的也比较靠谱的。工程中如果遇到这种问题,嵌入模型和重排序模型是解决不了的,一般都是使用更大的模型来解决,1.5B搞不定,那就用3B,还搞不定就7B,依次类推。如果模型增大到硬件配置的上限后,仍然搞不定,那就只能微调(微调也不能完全解决,只能对专门的几个问题,比如针对 “用人单位解除劳动合同” 和 “劳动者解除劳动合同” 分别做个几十条数据,把各种提问的方式给包含进去,然后微调)。
3 改进
3.1 根据重排序得分进行过滤
从前面的实验可以看到,我们用重排序模型可以得到得分最高的3条检索结果,但这三条结果未必就是和用户查询相关,它们仅仅是得分最高而已,或者是那种 “相关,但答非所问”,我们可以设定一个阈值,将这些检索结果过滤掉。
将main函数按照如下方式修改:
def main():
embed_model, llm = init_embedding_model(), init_llm_model()
reranker = init_reranker_model()
# 仅当需要更新数据时执行
if not Path(Config.VECTOR_DB_DIR).exists():
print("\n初始化数据...")
nodes = load_and_create_nodes(Config.DATA_DIR)
else:
nodes = None # 已有数据时不加载
# 初始化向量存储
print("\n初始化向量存储...")
start_time = time.time()
index = init_vector_store(nodes)
print(f"索引加载耗时:{time.time()-start_time:.2f}s")
# 创建检索器和响应合成器(修改部分)
retriever = index.as_retriever(
similarity_top_k=Config.TOP_K
)
response_synthesizer = get_response_synthesizer(
text_qa_template=response_template,
verbose=True
)
# 示例查询
while True:
question = input("\n请输入劳动法相关问题(输入q退出): ")
if question.lower() == 'q':
break
# 执行检索-重排序-回答流程(新增重排序步骤)
start_time = time.time()
# 1. 初始检索
initial_nodes = retriever.retrieve(question)
retrieval_time = time.time() - start_time
for node in initial_nodes:
node.node.metadata['initial_score'] = node.score # 保存初始分数到元数据
# 2. 重排序
reranked_nodes = reranker.postprocess_nodes(
initial_nodes,
query_str=question
)
rerank_time = time.time() - start_time - retrieval_time
3. 过滤
# 设置重排序得分阈值,低于此阈值的知识节点不作为参考依据
MIN_RERANK_SCORE = 0.8
# 执行过滤
# 一般对模型的回复做限制就从filtered_nodes的返回值下手
filtered_nodes = [
node for node in reranked_nodes
if node.score > MIN_RERANK_SCORE
]
# 如果没有一条符合,那就不需要调用大模型了
if len(filtered_nodes) == 0:
print("\n您好!我是劳动法咨询助手,专注解答《劳动法》《劳动合同法》等相关问题,其他问题无法回答。")
continue
# 4. 合成答案
response = response_synthesizer.synthesize(
question,
nodes=filtered_nodes # 使用过滤后的节点
)
synthesis_time = time.time() - start_time - retrieval_time - rerank_time
# 显示结果(修改显示逻辑)
print(f"\n智能助手回答:\n{response.response}")
print("\n支持依据:")
for idx, node in enumerate(filtered_nodes, 1):
# 兼容新版API的分数获取方式
initial_score = node.metadata.get('initial_score', node.score) # 获取初始分数
rerank_score = node.score # 重排序后的分数
meta = node.node.metadata
print(f"\n[{idx}] {meta['full_title']}")
print(f" 来源文件:{meta['source_file']}")
print(f" 法律名称:{meta['law_name']}")
print(f" 初始相关度:{node.node.metadata['initial_score']:.4f}")
print(f" 重排序得分:{node.score:.4f}")
print(f" 条款内容:{node.node.text[:100]}...")
print(f"\n[性能分析] 检索: {retrieval_time:.2f}s | 重排序: {rerank_time:.2f}s | 合成: {synthesis_time:.2f}s")
实验一下:
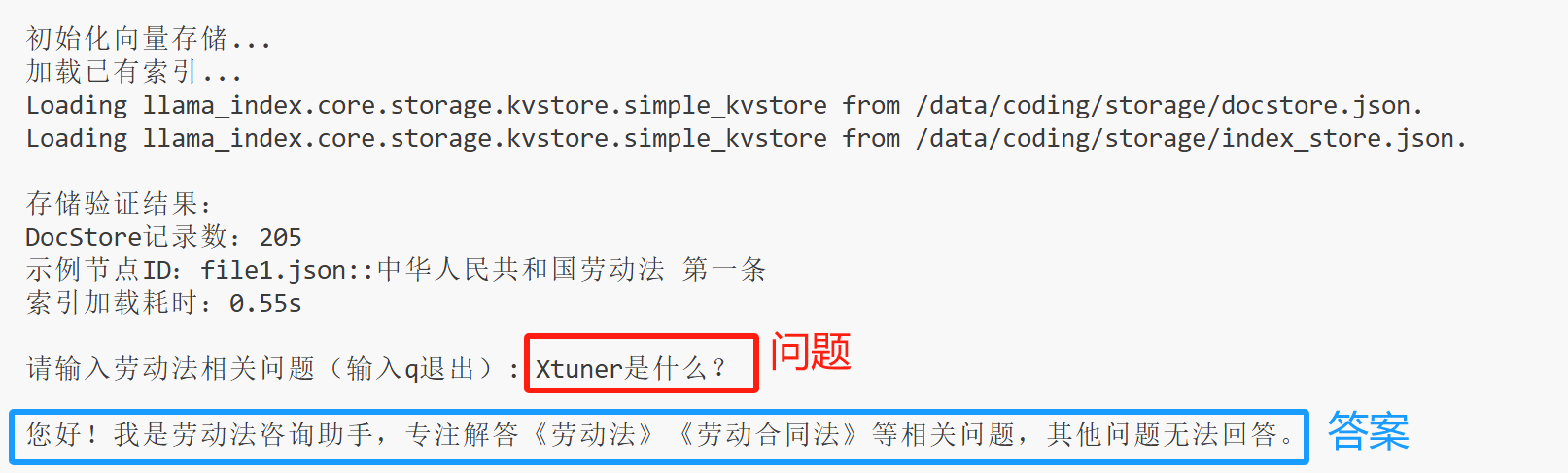
可以看到,当问的问题和劳动法或者劳动合同法无关时,系统会给出指定的提示。
再试一个例子:


可以看到,经过 检索——重排序——过滤 之后,只剩下了两条依据,这两条依据都是和问题相关的,而且也正是我们想要的(并不是 “相关,但答非所问”)。当然,最后模型的回复是有问题的,主要原因是我们输入的问题需要一定的推理能力,而当前使用的模型才1.8B,实现不了这个能力。
3.2 替换更大的语言模型
为了增强推理能力,我们使用更大的语言模型,我们把原始的 1.8B 的模型替换为 4B,如果还不行,那就用 7B 模型,或者用 Qwen2.5 系列的。总之,逐个尝试,直到达到硬件配置的上限。
配置类修改如下:
class Config:
EMBED_MODEL_PATH = "/data/coding/models/sungw111/text2vec-base-chinese-sentence"
LLM_MODEL_PATH = "/data/coding/models/Qwen/Qwen1.5-4B-Chat"
RERANK_MODEL_PATH = "/data/coding/models/BAAI/bge-reranker-large"
DATA_DIR = "/data/coding/data"
VECTOR_DB_DIR = "/data/coding/chroma_db"
PERSIST_DIR = "/data/coding/storage"
COLLECTION_NAME = "chinese_labor_laws"
TOP_K = 10 # 初始检索数量
RERANK_TOP_K = 3 # 重排序后保留数量
再来试一下刚刚的计算赔偿金的问题:
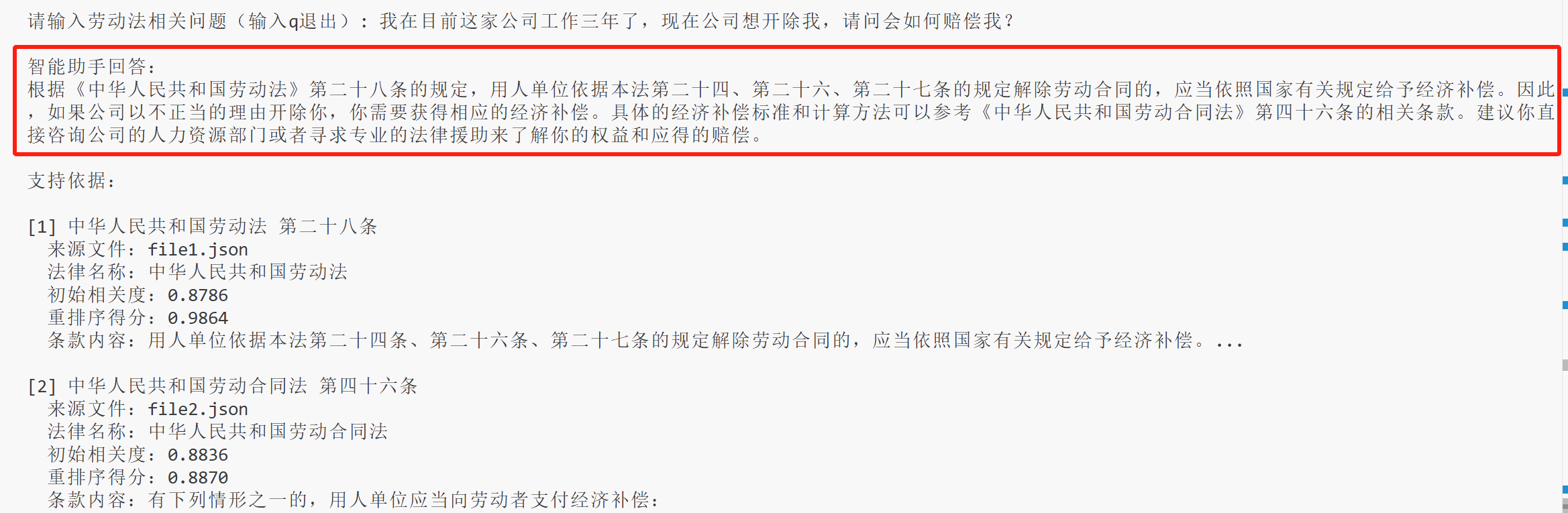
可以看到,4B 模型回答并没有出现错误,但也没能计算出赔偿金,我查了一下《劳动合同法》,第四十七条才是经济补偿的条款,所以这里没能算出赔偿经,主要原因是相关知识节点没有检索到,或者在重排序/阈值过滤的时候,被过滤掉了。
我们把问题改成:我在目前这家公司工作三年了,现在公司想开除我,请问我的经济补偿该如何计算?
新的问题有两点改进:(1)把 “赔偿” 改成 “经济” 补偿;(2)明确告知让模型帮我们计算。结果如下:

改进了问题之后,给出的依据是我们想要的,并且模型直接帮我们计算出来了要赔多少个月。
当然,4B的模型也还是太小,我把问题稍微改了一下:我在目前这家公司工作三年了,现在公司想开除我,请问公司给我的赔偿该如何计算?
结果:

我本来还想试一下 7B 的模型,但最后报错说显存不足。总之,遇见计算错误、回答错误之类的问题,那就使用更强的模型。
3.2 使用 LMDeploy/vLLM 推理引擎加速
前面我们使用的是 Hugging Face 推理引擎,LlamaIndex 上的这个引擎有bug,导致回复不完整,而且推理速度还慢。我们这里使用 LMDeploy 或 vLLM 作为推理引擎。
如果用推理引擎,则至少需要两张卡,因为 LMDeploy/vLLM 一启动就会占据 80-90% 的显存给大模型,而这里的文本嵌入模型(sungw111/text2vec-base-chinese-sentence)和重排序模型(BAAI/bge-reranker-large)用 Hugging Face 推理引擎需要超过 3G 显存。除非你单卡非常大,否则显存被 LMDeploy 等推理引擎占80-90%后,剩下的显存放不下嵌入模型和重排序模型。
我们这里把文本嵌入模型和重排序模型放到默认的显卡上,把大语言模型放到编号为1的卡上。
先把模型推理服务跑起来,新建一个终端,输入:
CUDA_VISIBLE_DEVICES="1" lmdeploy serve api_server /data/coding/models/Qwen/Qwen1.5-4B-Chat
当然,文本嵌入模型和重排序模型也可以用 LMDeploy 进行推理,但它们太小了,对时间的消耗并不明显,而且用 LMDeploy 的话,每个模型都需要单独一张卡,除非你的卡特别大(因为 LMDeploy 只要启动就会占据80-90%的显存,不管你的模型有多大)。
接下来要修改模型初始化代码,在此之前,我们需要拿到 LlamaIndex 如何调用 OpenAI 协议接口的示例。我们进入 LlamaIndex 的官网,然后点击API Reference:
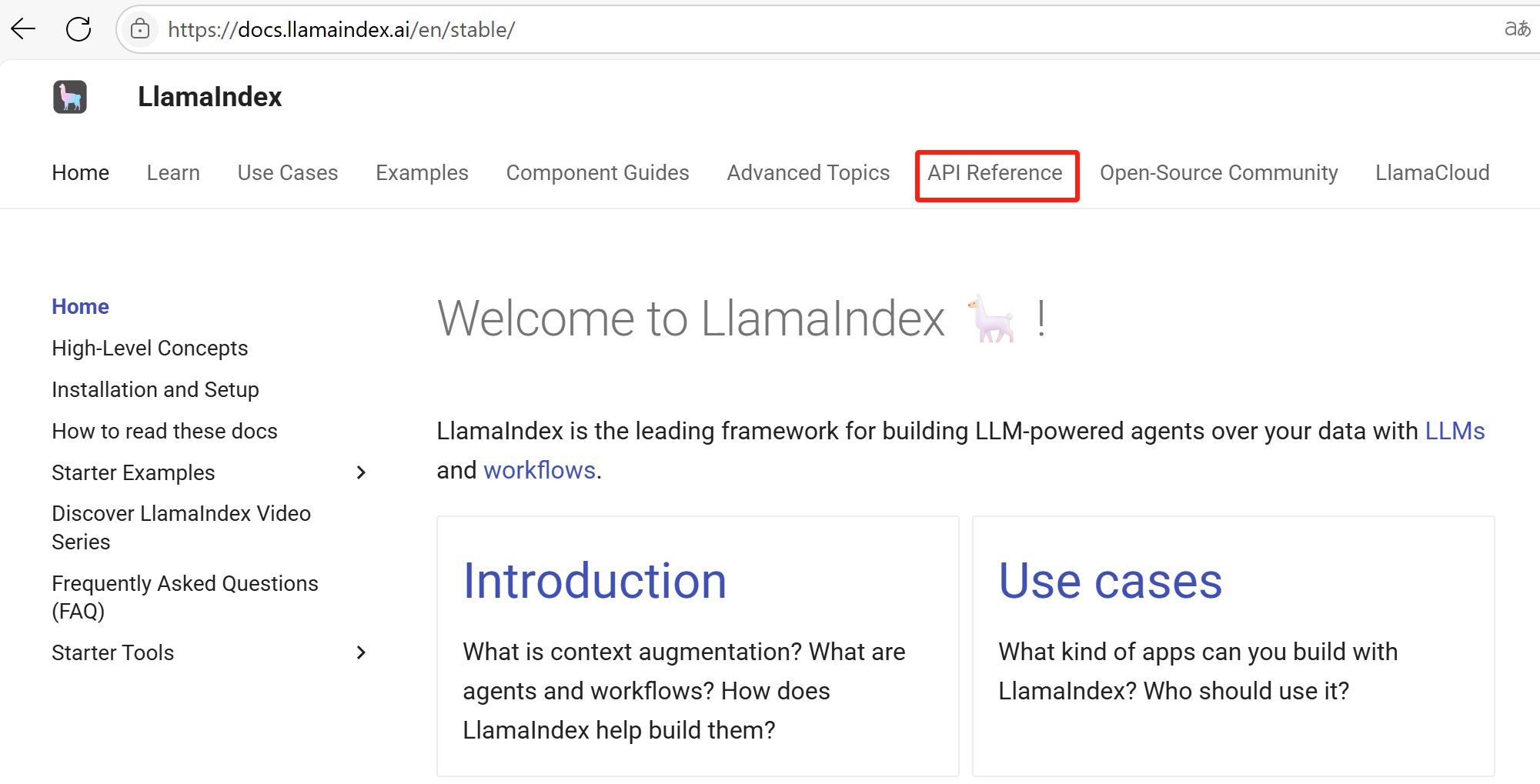
在右边 LLMs 下找:Openai like
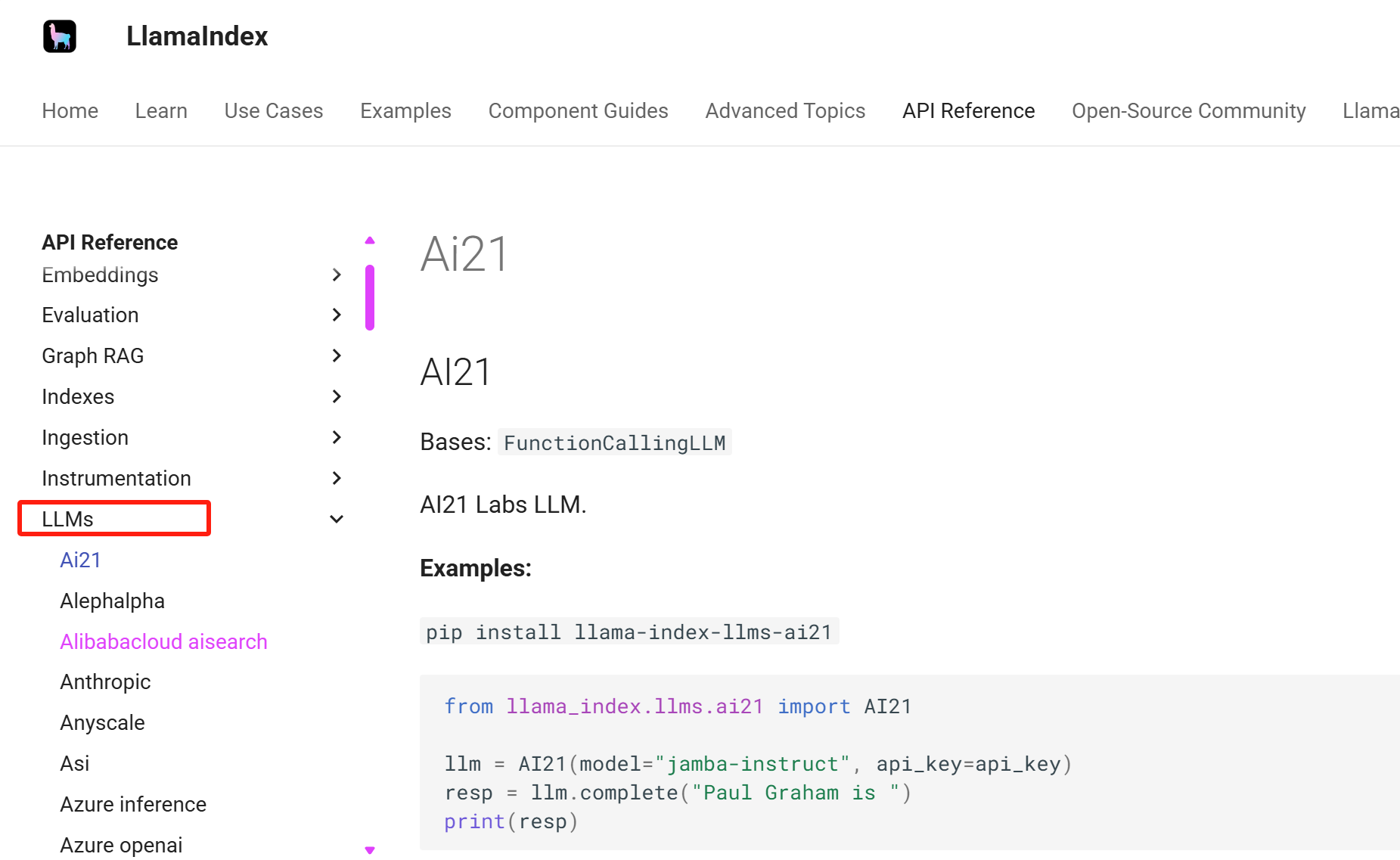
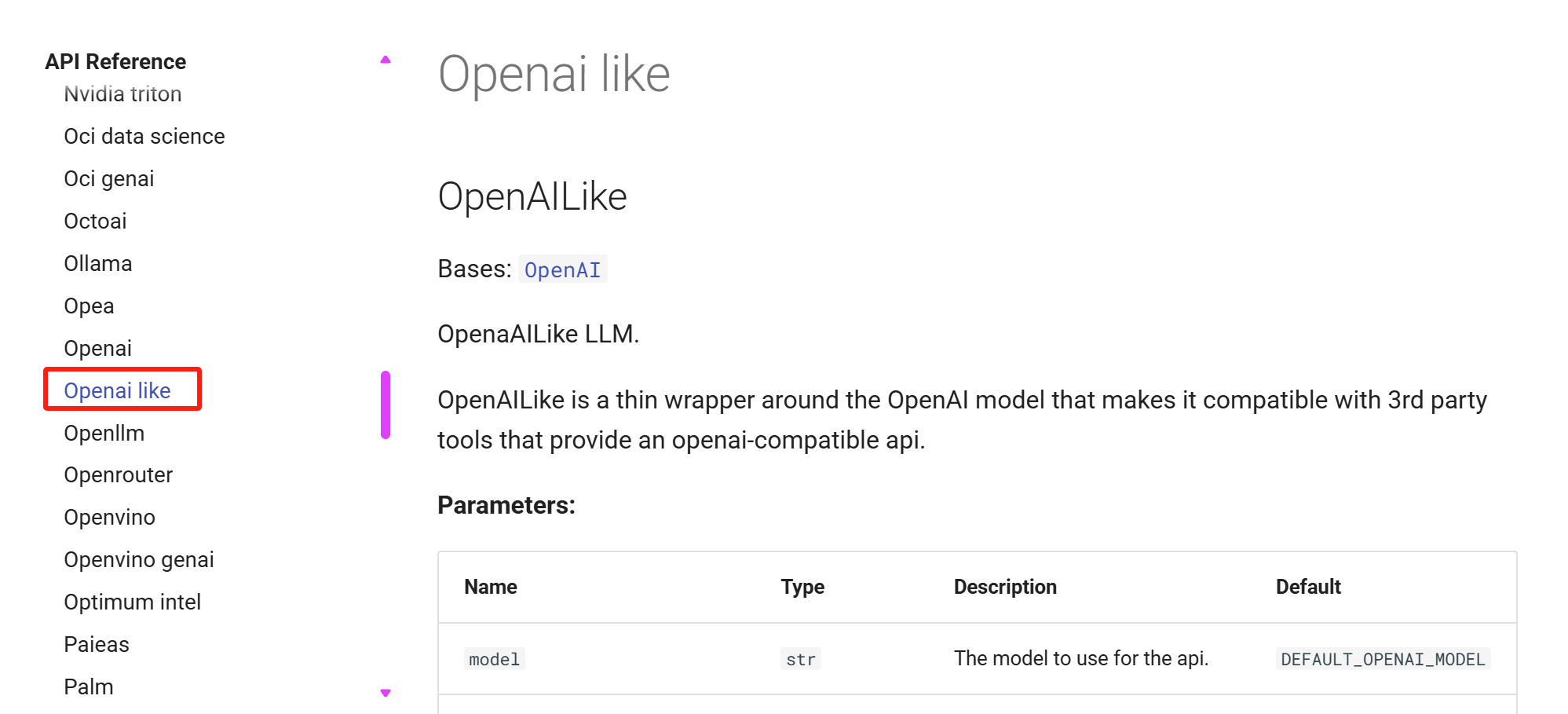
进入页面后往下滑,可以看到 Example,这里讲了要安装什么包,以及调用示例:
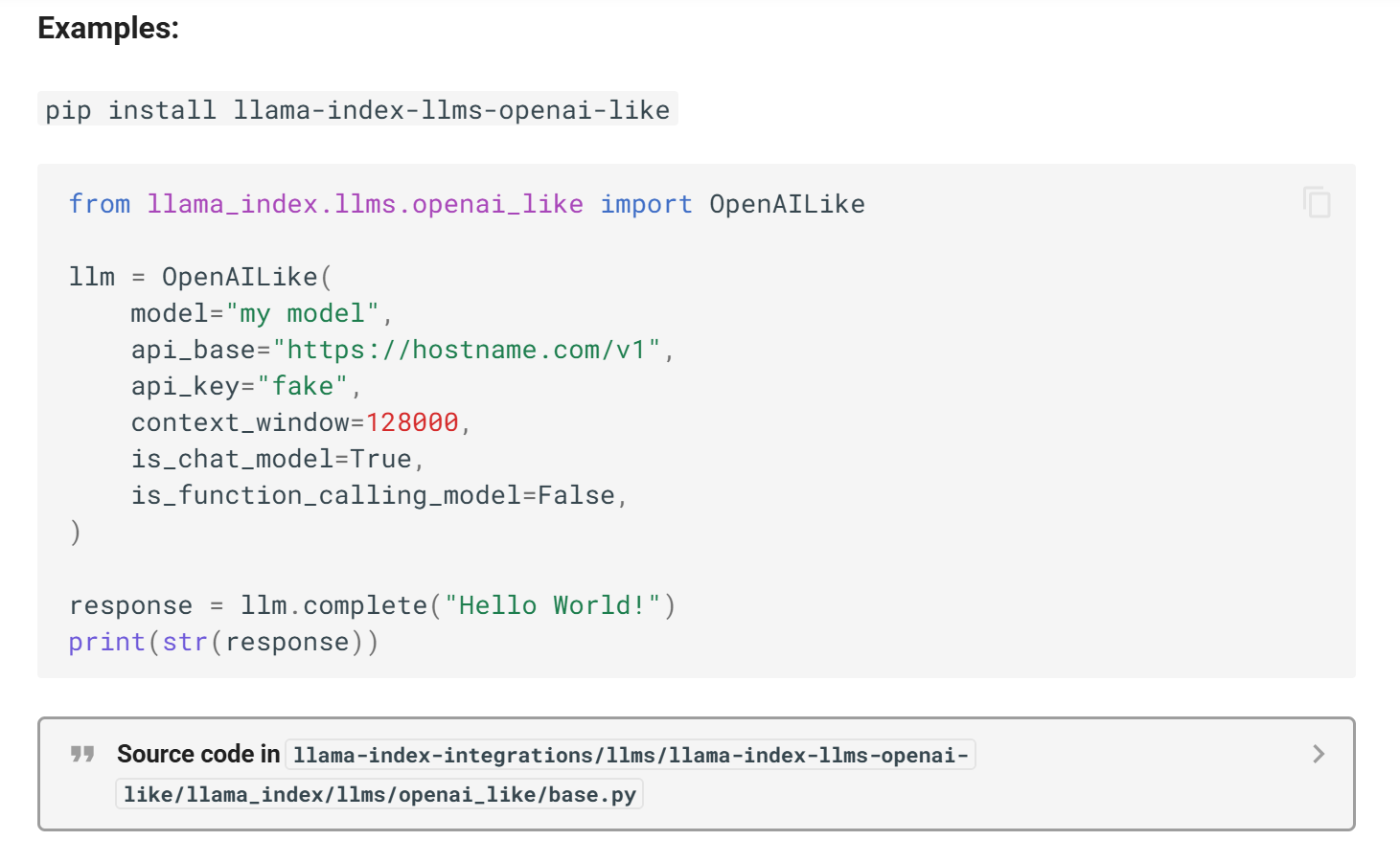
按照调用示例,我们可以修改 init_llm_model 函数:
from llama_index.llms.openai_like import OpenAILike
def init_llm_model():
# 初始化大语言模型
llm = OpenAILike(
model=Config.LLM_MODEL_PATH,
api_base="http://localhost:23333/v1",
api_key="fake",
context_window=4096, # 千问的上下文窗口是4096
is_chat_model=True,
is_function_calling_model=False,
max_tokens=1024, # 最大生成token数(按需调整)
temperature=0.3, # 推荐范围 0.1~1.0
top_p=0.7 # 推荐范围 0.5~1.0
)
Settings.llm = llm
return llm

这里不到一秒就合成答案了,当然这里只有两条依据,并且生成的答案也短,因此合成时间只有0.59秒,我试了其他问题,还是需要好几秒的,但还是比 hugging face 引擎更快。
由于我们使用的是 LMDeploy 推理引擎,不可能出现没打完就停了的情况,除非超过上下文窗口上限,但是有可能出现答案是错误的情况,像下面截图的情况,这个是和模型能力相关,和我们这里的流程无关。

这里需要说明的是,这一节我租的显卡是 TiTan V,而前面介绍重排序时用的显卡是 P100,显卡驱动不一样,内部的算子也会有些许差别,因此相关度、重排序得分可能会有些许差别。
其实还有一个关于试用期的条款(劳动合同法第七十条),但因为重排序后的得分太低被过滤了。当然,这一条有没有都不影响 “试用期最长不超过六个月” 的结论,因此影响不大。
此时两张显卡的显存占用情况如下:
如果使用 vLLM 作为推理框架,则命令为:
CUDA_VISIBLE_DEVICES="1" vllm serve /data/coding/models/Qwen/Qwen1.5-4B-Chat
启动服务后改一下 OpenAILike 中的端口号就行了,把 23333 改成 8000 就行了,代码的其他部分不变。
4 总结
现在我们再来看看上篇文章的问题以及解决情况:
- 文本嵌入模型分不清主动和被动的区别,把主动和被动的参考依据都喂给大模型;
- 检索出的结果相关,但答非所问;
- 与问题不相关的节点,相似度(相关度得分)却很高;
- 模型的回复不完整,没回复完就停了,也有可能是回复完了,但打印的不完整。
第1点可以靠大模型能力来识别,推理能力强的大模型会选择其中正确的参考依据,第 2 和第 3 点可以通过重排序+得分过滤的方式解决,第4点可以通过使用 LMDeploy 或者 vLLM 这样的推理引擎来解决。
完整代码
我们把代码整理一下,把嵌入模型、重排序模型和大语言模型的初始化都放到一个函数中实现。整理后的代码如下:
import time
import json
from typing import List
from pathlib import Path
from llama_index.core.schema import TextNode
from llama_index.core import PromptTemplate, get_response_synthesizer
from llama_index.core import VectorStoreIndex, StorageContext, Settings
from llama_index.core.postprocessor import SentenceTransformerRerank
import chromadb
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.openai_like import OpenAILike
class Config:
EMBED_MODEL_PATH = "/data/coding/models/sungw111/text2vec-base-chinese-sentence"
LLM_MODEL_PATH = "/data/coding/models/Qwen/Qwen1.5-4B-Chat"
RERANK_MODEL_PATH = "/data/coding/models/BAAI/bge-reranker-large"
DATA_DIR = "/data/coding/data"
VECTOR_DB_DIR = "/data/coding/chroma_db"
PERSIST_DIR = "/data/coding/storage"
COLLECTION_NAME = "chinese_labor_laws"
TOP_K = 10 # 初始检索数量
RERANK_TOP_K = 3 # 重排序后保留数量
def load_and_create_nodes(data_dir: str) -> List[TextNode]:
"""加载JSON法律文件并直接转换为TextNode节点"""
json_files = list(Path(data_dir).glob("*.json"))
assert json_files, f"未找到JSON文件于 {data_dir}"
nodes = []
total_entries = 0
for json_file in json_files:
with open(json_file, 'r', encoding='utf-8') as f:
try:
data = json.load(f)
# 验证数据结构
if not isinstance(data, list):
raise ValueError(f"文件 {json_file.name} 根元素应为列表")
for item in data:
if not isinstance(item, dict):
raise ValueError(f"文件 {json_file.name} 包含非字典元素")
for k, v in item.items():
if not isinstance(v, str):
raise ValueError(f"文件 {json_file.name} 中键 '{k}' 的值不是字符串")
# 处理字典中的键值对 (每个item只有一个键值对)
for full_title, content in item.items():
# 生成稳定ID (文件 + 标题)
node_id = f"{json_file.name}::{full_title}"
# 解析法律名称和条款号
parts = full_title.split(" ", 1)
law_name = parts[0] if len(parts) > 0 else "未知法律"
article = parts[1] if len(parts) > 1 else "未知条款"
# 创建TextNode节点
node = TextNode(
text=content,
id_=node_id,
metadata={
"law_name": law_name,
"article": article,
"full_title": full_title,
"source_file": json_file.name,
"content_type": "legal_article"
}
)
nodes.append(node)
total_entries += 1
except Exception as e:
raise RuntimeError(f"处理文件 {json_file} 失败: {str(e)}")
print(f"成功转换 {total_entries} 个法律条款为文本节点")
if nodes:
print(f"id示例:{nodes[0].id_}")
print(f"文本示例:{nodes[0].text}")
print(f"元数据示例:{nodes[0].metadata}")
return nodes
def init_vector_store(nodes: List[TextNode]) -> VectorStoreIndex:
chroma_client = chromadb.PersistentClient(path=Config.VECTOR_DB_DIR)
# 创建或者获取集合(首次运行是创建,第二次运行则是获取)
chroma_collection = chroma_client.get_or_create_collection(
name=Config.COLLECTION_NAME,
metadata={"hnsw:space": "cosine"}
)
# 判断是否需要新建索引
if chroma_collection.count() == 0 and nodes is not None:
print(f"创建新索引({len(nodes)}个节点)...")
# 创建存储上下文
storage_context = StorageContext.from_defaults(
# 将 ChromaDB 的集合(collection)封装为 LlamaIndex 可识别的向量存储接口,以支持索引构建与查询。
# 后续通过 VectorStoreIndex 构建索引时,会使用该 ChromaVectorStore 实例来添加或搜索向量。
vector_store=ChromaVectorStore(chroma_collection=chroma_collection)
)
# 创建 StorageContext 对象的作用是为 LlamaIndex 提供一个统一的数据存储管理上下文,
# 用于协调向量存储(vector store)、文档存储(docstore)和索引之间的数据流动与持久化操作。
# 将文本节点存入文档存储(元数据+文本内容)
storage_context.docstore.add_documents(nodes)
# 创建索引,将节点向量化并创建可搜索的索引结构
index = VectorStoreIndex(
nodes,
storage_context=storage_context,
show_progress=True
)
# 在创建 VectorStoreIndex 对象时需要传入该 StorageContext 对象,以确保索引知道如何访问向量和文档。
# 双重持久化保障,将存储上下文和索引对象保存到 Config.PERSIST_DIR 目录(双重保证)
storage_context.persist(persist_dir=Config.PERSIST_DIR)
index.storage_context.persist(persist_dir=Config.PERSIST_DIR)
else:
print("加载已有索引...")
# 加载存储上下文,从持久化目录加载已有状态
storage_context = StorageContext.from_defaults(
persist_dir=Config.PERSIST_DIR,
vector_store=ChromaVectorStore(chroma_collection=chroma_collection)
)
# 构建索引对象,基于已有向量存储重建内存索引结构
index = VectorStoreIndex.from_vector_store(
storage_context.vector_store,
storage_context=storage_context,
embed_model=Settings.embed_model
)
# 安全验证
print("\n存储验证结果:")
doc_count = len(storage_context.docstore.docs)
print(f"DocStore记录数:{doc_count}")
if doc_count > 0:
sample_key = next(iter(storage_context.docstore.docs.keys()))
print(f"示例节点ID:{sample_key}")
else:
print("警告:文档存储为空,请检查节点添加逻辑!")
return index
def init_models():
# 初始化Embedding模型
embed_model = HuggingFaceEmbedding(
model_name=Config.EMBED_MODEL_PATH,
# 在一些比较老版本的 llama-index-embeddings-huggingface 中,需要加下面的参数,当前版本(0.5.4)不需要
# encode_kwargs = {
# 'normalize_embeddings': True,
# 'device': 'cuda' if hasattr(Settings, 'device') else 'cpu'
# }
)
Settings.embed_model = embed_model
# 初始化大语言模型
llm = OpenAILike(
model=Config.LLM_MODEL_PATH,
api_base="http://localhost:23333/v1",
api_key="fake",
context_window=4096, # 千问的上下文窗口是4096
is_chat_model=True,
is_function_calling_model=False,
max_tokens=1024, # 最大生成token数(按需调整)
temperature=0.3, # 推荐范围 0.1~1.0
top_p=0.7 # 推荐范围 0.5~1.0
)
Settings.llm = llm
# 初始化重排序模型
reranker = SentenceTransformerRerank(
model=Config.RERANK_MODEL_PATH,
top_n=Config.RERANK_TOP_K
)
return embed_model, llm, reranker
QA_TEMPLATE = (
"<|im_start|>system\n"
"您是中国劳动法领域专业助手,必须严格遵循以下规则:\n"
"1.仅使用提供的法律条文回答问题\n"
"2.若问题与劳动法无关或超出知识库范围,明确告知无法回答\n"
"3.引用条文时标注出处\n\n"
"可用法律条文(共{context_count}条):\n{context_str}\n<|im_end|>\n"
"<|im_start|>user\n问题:{query_str}<|im_end|>\n"
"<|im_start|>assistant\n"
)
response_template = PromptTemplate(QA_TEMPLATE)
def main():
embed_model, llm, reranker = init_models()
# 仅当需要更新数据时执行
if not Path(Config.VECTOR_DB_DIR).exists():
print("\n初始化数据...")
nodes = load_and_create_nodes(Config.DATA_DIR)
else:
nodes = None # 已有数据时不加载
# 初始化向量存储
print("\n初始化向量存储...")
start_time = time.time()
index = init_vector_store(nodes)
print(f"索引加载耗时:{time.time()-start_time:.2f}s")
# 创建检索器和响应合成器
retriever = index.as_retriever(
similarity_top_k=Config.TOP_K
)
response_synthesizer = get_response_synthesizer(
text_qa_template=response_template,
verbose=True
)
# 示例查询
while True:
question = input("\n请输入劳动法相关问题(输入q退出): ")
if question.lower() == 'q':
break
# 执行检索-重排序-回答流程
start_time = time.time()
# 1. 初始检索
initial_nodes = retriever.retrieve(question)
retrieval_time = time.time() - start_time
for node in initial_nodes:
node.node.metadata['initial_score'] = node.score # 保存初始分数到元数据
# 2. 重排序
reranked_nodes = reranker.postprocess_nodes(
initial_nodes,
query_str=question
)
rerank_time = time.time() - start_time - retrieval_time
# 3. 过滤
# 设置重排序得分阈值,低于此阈值的知识节点不作为参考依据
MIN_RERANK_SCORE = 0.8
# 执行过滤
# 一般对模型的回复做限制就从filtered_nodes的返回值下手
filtered_nodes = [
node for node in reranked_nodes
if node.score > MIN_RERANK_SCORE
]
if len(filtered_nodes) == 0:
print("\n您好!我是劳动法咨询助手,专注解答《劳动法》《劳动合同法》等相关问题,其他问题无法回答。")
continue
# 4. 合成答案
response = response_synthesizer.synthesize(
question,
nodes=filtered_nodes # 使用过滤后的节点
)
synthesis_time = time.time() - start_time - retrieval_time - rerank_time
# 显示结果
print(f"\n智能助手回答:\n{response.response}")
print("\n支持依据:")
for idx, node in enumerate(filtered_nodes, 1):
# 兼容新版API的分数获取方式
initial_score = node.metadata.get('initial_score', node.score) # 获取初始分数
rerank_score = node.score # 重排序后的分数
meta = node.node.metadata
print(f"\n[{idx}] {meta['full_title']}")
print(f" 来源文件:{meta['source_file']}")
print(f" 法律名称:{meta['law_name']}")
print(f" 初始相关度:{node.node.metadata['initial_score']:.4f}")
print(f" 重排序得分:{node.score:.4f}")
print(f" 条款内容:{node.node.text[:100]}...")
print(f"\n[性能分析] 检索: {retrieval_time:.2f}s | 重排序: {rerank_time:.2f}s | 合成: {synthesis_time:.2f}s")
if __name__ == "__main__":
main()

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)