Chainlit+LlamaIndex 实战 6:把 RAG 系统玩出花!界面优化、OCR 识别、知识库问答一步到位
这篇文章介绍了如何优化RAG系统,从界面美化到功能增强的完整实战指南。主要内容包括: 界面优化:通过5个步骤将Chainlit默认界面升级为专业UI,包括更换logo、添加提示块、设置面板、对话恢复功能和CSS定制,提升用户体验。 OCR集成:使用Umi-OCR实现图片/文档文字识别,详细说明了从服务配置到代码集成的完整流程,解决RAG系统无法处理图片内容的问题。 知识库建设:基于Milvus构建
各位,有没有过这种时刻?搭好的 RAG 系统界面像 “毛坯房”,logo 丑到想捂脸;传张图片想提取文字,结果 OCR 要么识别成乱码,要么干脆罢工;好不容易弄好知识库,用户却找不到入口 —— 别慌!今天这篇实战文,咱们就把这些问题一锅端,从 “界面精装修” 到 “OCR 精准识别”,再到 “知识库智能问答”,手把手教你把 RAG 系统打造成 “用户夸、自己爽” 的好用工具~

一、先唠 5 毛钱的:咱们为啥要折腾这三件事?
在动手前,先搞懂 “优化界面、做 OCR、搭知识库” 的意义 —— 不然白忙活!
- 界面优化:你总不能让用户对着默认的 “Chainlit 灰底白字” 发呆吧?就像买手机要贴个膜、换个壳,界面好看了,用户才愿意用;
- 自定义 OCR:很多时候用户传的是图片(比如扫描件、截图),RAG 认不了图片里的字,OCR 就是 “把图片翻译成文字” 的翻译官;
- 知识库问答:没有知识库的 RAG 就是 “没带课本的学生”,问啥都只能靠大模型瞎编,挂上联 Milvus 的知识库,回答才准、才专业。
一句话:这三件事,是把 “能用的 RAG” 变成 “好用的 RAG” 的关键!
二、Chainlit 界面优化:从 “毛坯房” 到 “精装修”
先从最直观的界面下手,咱们分 5 步走,每步都有 “避坑指南”,放心跟着做~
2.1 改 logo:换掉默认的 “占位符饼干”
Chainlit 默认 logo 长啥样?懂的都懂,像块没烤好的饼干,毫无辨识度。咱们换成自己的 logo,三步搞定:
- 备图:准备三张图 ——
logo_dark.png(深色模式用)、logo_light.png(浅色模式用)、favicon.png(浏览器标签图标),尺寸不用太大,logo 建议 200x60 像素,favicon 用 32x32 像素; - 放对地方:把图片扔进项目根目录的
public文件夹里 —— 别问我为啥放这,Chainlit 默认从这读图片,放错了就像钥匙插错锁,找不到; - 查文档:要是还不放心,看 Chainlit 官方指南
- (https://docs.chainlit.io/customisation/custom-logo-and-favicon),里面写得明明白白。
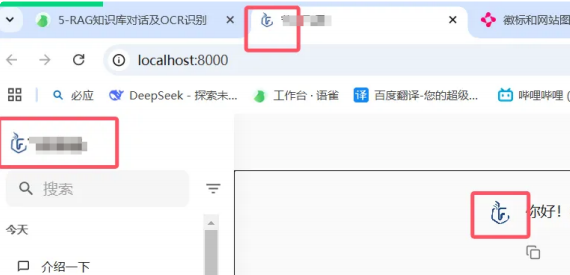
避坑指南:图片格式别用.webp!有些浏览器不兼容,老老实实用 PNG,省得折腾。
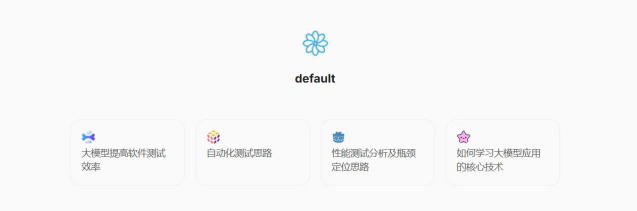
2.2 加提示块(Starters):帮用户 “开口提问”
你有没有遇到过用户盯着输入框半天,憋出一句 “我该问点啥?”—— 提示块就是解决这个问题的 “救星”,预设几个常见问题,用户点一下就能提问。实现超简单,就在chainlit_ui.py里加段代码:
@cl.set_starters
async def set_starters():
return [
cl.Starter(
label="大模型提高软件测试效率",
message="详细介绍如何借助大语言模型提高软件测试效率~",
icon="/public/apidog.svg" # 图标放public文件夹
),
# 再加几个常用场景,比如自动化测试、性能瓶颈定位
]
关键提醒:记得把@cl.on_chat_start里的 “欢迎消息” 代码注释掉!不然用户一进来,又弹欢迎框又显提示块,像菜市场一样乱。
效果?用户再也不用 “对着输入框发呆”,点一下提示块,问题直接发出去,爽!
2.3 加设置面板:给用户一个 “遥控器”
用户想换模型(比如从 DeepSeek 换成 Moonshot)、想关了多模态功能,总不能让他改代码吧?加个设置面板,让用户自己调:还是在chainlit_ui.py里,聊天启动时发个面板:
@cl.on_chat_start
async def start():
# 发设置面板:模型选择+多模态开关
await cl.ChatSettings(
Select(
id="Model",
label="模型选择",
values=["DeepSeek", "Moonshot"], # 你的模型列表
initial_index=0 # 默认选第一个
),
Switch(id="multimodal", label="多模态RAG", initial=True) # 默认开
).send()
# 设置更新时存起来
@cl.on_settings_update
async def setup_settings(settings):
cl.user_session.set("settings", settings)
避坑指南:initial_index别瞎写!比如你只有 2 个模型,写个 3,面板直接报错,记着 “从 0 开始数”。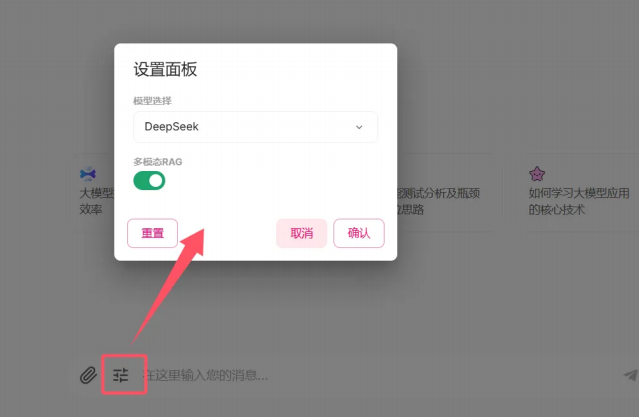
2.4 加 “返回 / 恢复对话”:避免用户 “从头再来”
用户聊到一半关掉页面,再打开要重新说一遍 —— 这体验谁受得了?加个对话恢复功能,让聊天能 “续上”:
@cl.on_chat_resume
async def on_chat_resume(thread: ThreadDict):
# 初始化聊天引擎
chat_engine = SimpleChatEngine.from_defaults()
# 从历史里扒消息,重建聊天记录
for message in thread.get("steps", []):
if message["type"] == "user_message":
chat_engine.chat_history.append(ChatMessage(content=message["output"], role="user"))
elif message["type"] == "assistant_message":
chat_engine.chat_history.append(ChatMessage(content=message["output"], role="assistant"))
# 存起来,后续用
cl.user_session.set("chat_engine", chat_engine)
效果:用户再打开页面,能看到之前的对话记录,还能接着聊,再也不用 “重复说第三遍” 了~
2.5 CSS 自定义:把 “冗余按钮” 藏起来
Chainlit 默认有 README 按钮、Chat 按钮、页脚,看着乱?用 CSS 藏起来,就像收拾房间一样,把没用的东西收进柜子:
- 建 CSS 文件:在
public文件夹里建个ui.css; - 写样式:把要藏的组件 “隐身”:
/* 藏README按钮 */
.css-8kxmdr { visibility: hidden !important; }
/* 藏Chat按钮 */
.css-plyx71 { visibility: hidden !important; }
/* 藏默认logo(要是你换了新的) */
.css-12hxhao { visibility: hidden !important; }
/* 藏页脚(Chainlit版权信息) */
.css-1705j0v { visibility: hidden !important; }
- 关联配置:在
config.toml里加一句custom_css="/public/ui.css",告诉 Chainlit “用我这个 CSS”。
避坑指南:CSS 类名别瞎改!这些类名是 Chainlit 默认的,你可以用浏览器 “审查元素” 查(右键→检查),改对了才能藏住。
三、自定义 OCR 识别:让 RAG “看懂图片”
接下来搞 OCR,咱们用免费开源的 Umi-OCR(离线能用,不花钱!),从 “工具配置” 到 “代码集成”,一步都不落下。
3.1 Umi-OCR 准备:先把 “翻译官” 叫醒
Umi-OCR 是个离线 OCR 工具,Windows 和 Linux 都能用,先把它配置好:
- 下载安装:去官网(https://github.com/hiroi-sora/Umi-OCR)下最新版,或者直接用这个链接(https://hiroi-sora.lanzoul.com/s/umi-ocr),速度快;
- 开服务:打开 Umi-OCR,点 “高级→服务”,勾选 “允许 HTTP 服务”,主机设为 “任何可用地址”,端口默认 1314(记着这个数,后面要用);
- 查文档:要是不会用,看官方 API 文档(https://github.com/hiroi-sora/Umi-OCR/blob/main/docs/http/README.md),里面有示例代码,抄都能抄明白。
避坑指南:服务别关!Umi-OCR 一关,OCR 功能直接罢工,建议把它设为 “启动时后台运行”。
3.2 OCR 核心流程:像 “收发快递” 一样简单
别觉得 OCR 复杂,其实就 5 步,跟收发快递一模一样:
- 上传文件(寄快递):把图片 / 文档传给 Umi-OCR,拿个 “快递单号”(任务 ID);
- 轮询状态(查物流):每隔 1 秒问一下 “快递到哪了”(OCR 好了没);
- 生成链接(取件码):OCR 好了,拿个 “取件码”(下载链接);
- 下载文件(取快递):把识别后的文本文件下载到本地;
- 清理任务(扔快递盒):用完了把任务删了,别占 Umi-OCR 的内存。
记住这个流程,后面写代码就不会乱!
3.3 写 ocr.py 模块:把 “快递流程” 写成代码
在rag文件夹下建个ocr.py,把上面的流程写成函数,每个函数干一件事,清晰得很:
_upload_file:上传文件,还能处理 Linux 下 “中文文件名上传失败” 的问题(比如把 “测试.png” 改成 “temp.png” 再传);_process_file:轮询 OCR 状态,还会打印进度(比如 “处理进度:2/5 页”),失败了还会报错;_generate_target_file:要下载链接,支持 TXT、PDF 等格式;_download_file:下载文件,每下 10MB 提醒一次(避免用户以为卡住了);_clean_up:删任务,释放资源;ocr_file_to_text:把上面的函数串起来,调用一次就能完成 “上传→下载→清理”;ocr_image_to_text:专门处理图片,传路径就返回识别文本。
关键代码片段(处理中文文件名):
def _upload_file(file_path):
url = f"{base_url}/api/doc/upload"
# 先试原始文件名
with open(file_path, "rb") as file:
response = requests.post(url, files={"file": file})
res_data = response.json()
# 要是返回101(没收到文件),换临时文件名
if res_data["code"] == 101:
file_prefix, file_suffix = os.path.splitext(os.path.basename(file_path))
temp_name = "temp" + file_suffix # 临时名:temp.png
with open(file_path, "rb") as f:
response = requests.post(url, files={"file": (temp_name, f)})
return res_data["data"] # 返回任务ID
避坑指南:Linux 用户一定要加这段!不然中文文件名会让你怀疑人生。
3.4 改配置:让系统 “找到 OCR”
光写代码还不够,得告诉系统 “OCR 在哪”,改两个文件:
- rag/config.py:加 OCR 配置(单例模式,全系统共用):
class RAGConfig(BaseModel):
# 其他配置...
ocr_download_dir: str = Field(default=os.getenv("OCR_DOWNLOAD_PATH"), description="OCR下载目录")
ocr_base_url: str = Field(default=os.getenv("OCR_BASE_URL"), description="Umi-OCR地址")
RagConfig = RAGConfig() # 单例实例
- .env 文件:填具体值,跟 Umi-OCR 配置对应:
OCR_DOWNLOAD_PATH="./data/ocr_download" # OCR结果存在这
OCR_BASE_URL="http://127.0.0.1:1314" # Umi-OCR服务地址(端口1314)
避坑指南:OCR_BASE_URL别写错!多写个斜杠(比如http://127.0.0.1:1314/),或者端口不对,都会连不上。
3.5 集成到 RAG:让 TraditionalRAG “会用 OCR”
最后一步,把 OCR 集成到之前的TraditionalRAG类里,在rag/traditional_rag.py的load_data方法里加判断:
async def load_data(self):
docs = []
for file in self.files:
if is_image(file): # 是图片,用图片OCR
contents = ocr_image_to_text(file)
# 存临时文件
temp_file = datetime.now().strftime("%Y%m%d%H%M%S") + ".txt"
with open(temp_file, "w", encoding="utf-8") as f:
f.write(contents)
f_name = temp_file
else: # 是文档,用文档OCR
f_name = ocr_file_to_text(file)
# 读临时文件,建Document对象
data = SimpleDirectoryReader(input_files=[f_name]).load_data()
doc = Document(text="\n\n".join([d.text for d in data]), metadata={"path": file})
docs.append(doc)
os.remove(f_name) # 删临时文件,别占空间
return docs
效果:用户传图片,系统自动 OCR 成文字;传 PDF,也能提取文本 ——RAG 终于 “看懂图片” 了!
四、基于知识库的智能问答:让 RAG “有课本可查”
没有知识库的 RAG 就是 “瞎猜”,咱们用 Milvus 存知识库,再搭个界面让用户选,最后用 FastAPI 部署,搞定!
4.1 utils/milvus.py:管理 Milvus “知识库”
先写个工具类,管理 Milvus 里的 “集合”(也就是知识库),就两个核心函数:
list_collections:查 Milvus 里有哪些知识库;drop_collection:删知识库(谨慎用!删了就找不回来了)。
代码超简单:
from pymilvus import MilvusClient
import os
client = MilvusClient(uri=os.getenv("MILVUS_URI")) # 从.env拿地址
def list_collections():
return client.list_collections() # 查所有知识库
def drop_collection(collection_name):
client.drop_collection(collection_name=collection_name) # 删知识库
避坑指南:MILVUS_URI要在.env 里配置好(比如MILVUS_URI="http://127.0.0.1:19530"),不然连不上 Milvus。
4.2 chainlit_ui.py:让用户 “选知识库聊天”
用户怎么选知识库?在chainlit_ui.py里加个 “聊天配置文件”,只有管理员能看见(避免普通用户乱删):
@cl.set_chat_profiles
async def chat_profile(current_user: cl.User):
# 不是管理员,不给看
if current_user.metadata["role"] != "admin":
return None
# 查Milvus里的知识库
kb_list = list_collections()
# 建配置列表,先加个“默认对话”(不用知识库)
profiles = [
cl.ChatProfile(
name="default",
markdown_description="直接跟大模型聊",
icon="/public/kbs/4.png"
)
]
# 每个知识库加个配置
for kb_name in kb_list:
profiles.append(
cl.ChatProfile(
name=kb_name,
markdown_description=f"{kb_name}知识库(专业问答)",
icon=f"/public/kbs/{random.randint(1,3)}.jpg" # 随机图标
)
)
return profiles
然后在聊天启动时,根据用户选的知识库加载索引:
@cl.on_chat_start
async def start():
# 发设置面板(之前写过的)
# ...
# 看用户选了哪个知识库
kb_name = cl.user_session.get("chat_profile")
if kb_name is None or kb_name == "default":
# 默认:直接聊,不用知识库
memory = ChatMemoryBuffer.from_defaults(token_limit=1024)
chat_engine = SimpleChatEngine.from_defaults(memory=memory)
else:
# 加载知识库索引
index = await RAG.load_index(collection_name=kb_name)
chat_engine = index.as_chat_engine(chat_mode=ChatMode.CONTEXT)
cl.user_session.set("chat_engine", chat_engine)
效果:管理员登录能看到所有知识库,选一个就能基于它聊天,回答精准多了!
4.3 FastAPI 部署:让别人也能用你的 RAG
自己用得爽还不够,得让别人也能访问,用 FastAPI 搭个服务:
- 写 main.py:提供文件上传接口和首页:
from fastapi import FastAPI, UploadFile, File, Form
from fastapi.templating import Jinja2Templates
from rag.traditional_rag import TraditionalRAG
import os
app = FastAPI()
templates = Jinja2Templates(directory="templates") # 模板文件夹
# 文件上传接口:传文件,建知识库索引
@app.post("/uploadfiles/")
async def create_upload_files(
files: list[UploadFile] = File(...),
collection_name: str = Form(...), # 知识库名称
multimodal: bool = Form(False)
):
file_list = []
# 保存上传的文件
for file in files:
file_path = os.path.join("documents", file.filename)
with open(file_path, "wb+") as f:
f.write(await file.read())
file_list.append(file_path)
# 建索引
rag = TraditionalRAG(files=file_list)
await rag.create_index(collection_name=collection_name)
return {"code": 200, "message": "索引创建成功", "data": file_list}
# 首页:文件上传表单
@app.get("/")
async def main(request: Request):
return templates.TemplateResponse("index.html", {"request": request})
- 写 templates/index.html:简单的上传表单:
<!DOCTYPE html>
<html>
<head><title>上传文件建知识库</title></head>
<body>
<form action="/uploadfiles/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple> <!-- 多文件上传 -->
<input name="collection_name" type="text" placeholder="输知识库名称">
<input name="multimodal" type="checkbox"> <!-- 多模态开关 -->
<input type="submit" value="上传建索引">
</form>
</body>
</html>
- 启动服务:命令行输
uvicorn main:app --host 0.0.0.0 --port 8080,别人访问你的 IP:8080 就能上传文件建知识库了。
避坑指南:documents文件夹要提前建,不然保存文件会报错;端口别用 80(可能被占用),用 8080、8000 都可以。
五、总结:这三件事,让 RAG 从 “能用” 变 “好用”
今天咱们干了三件大事:
- 界面优化:改 logo、加提示块、设面板、恢复对话、藏冗余按钮,界面好看又好用;
- OCR 识别:用 Umi-OCR 做离线识别,处理图片 / 文档,让 RAG “看懂图片”;
- 知识库问答:用 Milvus 存知识库,加权限控制,用 FastAPI 部署,让 RAG “有课本可查”。
其实这些都不难,关键是 “一步一步来,别着急”。比如 OCR 配置不对,先查端口是不是 1314;知识库加载失败,先看 Milvus 是不是开着。遇到问题别慌,评论区留言,咱们一起解决~
下次咱们再聊多模态 RAG,让系统不仅能处理文字图片,还能读音频视频。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)