论文解读 | 为什么大模型学会了“答题”,却不会“思考”?一文读懂清华&北大&腾讯联合提出的GTR方法!
1.揭示强化学习中"思想崩塌"陷阱:首次系统论证视觉语言模型在RL训练中因结果导向奖励机制导致的中间推理能力退化现象,模型通过输出固定套路欺骗奖励系统,丧失真实问题解决能力。2.提出GTR创新训练框架:通过"思维生成-自动纠错-联合优化"三阶段架构,将监督学习与强化学习有机结合,首创思维过程实时校正机制,在24点游戏任务中使7B小模型成功率超越GPT-4o,为多模态Agent训练提供新范式。
学术致敬:论文解读基于《GTR: Guided Thought Reinforcement Prevents Thought Collapse in RL-based VLM Agent Training》,来自于腾讯AI总监叶德珩及其团队
链接:https://arxiv.org/pdf/2503.08525
🎮 起点:让AI玩24点游戏,结果出事了!
想象你在训练一个 AI 玩“24点”纸牌游戏。任务规则简单:给定四张牌(如10, 4, 6, 8),用加减乘除凑出24,输出一个数学表达式。
你以为AI会这样“推理”:
因为 (10 - 6 - 8) * 4 = 24,所以我选择减号,然后再选……
但过了几万轮训练,你惊讶地发现,不论输入啥,它总说:
“我选择10”,然后继续输出固定公式……
这就像学生参加奥数训练营,结果最后变成只会背模板的人,题目稍微一变就不会了。
这不是能力退化,而是大模型在强化学习训练中出现的“思想崩塌”(Thought Collapse)。
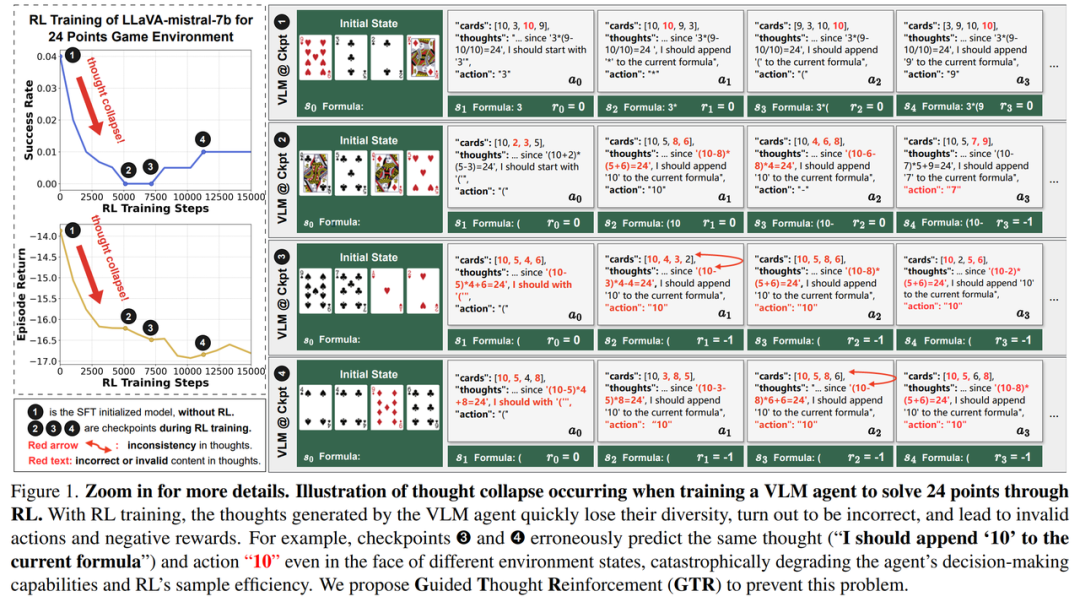
❗问题:什么是“思想崩塌”?
“思想崩塌”是指: 在基于强化学习(RL)训练视觉语言模型(VLM)的过程中,由于只根据最终动作是否成功来打分,导致模型逐渐忽略中间推理过程,转而重复输出无关、机械的“套路化思考”,甚至输出“错的但看上去像对的”推理语句。
论文中用一个例子说明:
环境状态不同,模型却给出完全一样的“思路”和“动作”。
比如:无论你给它什么四张牌,它都说“我应该选择10”,结果模型完全失去了状态感知能力。
更严重的是:
- 推理过程不再根据输入变化;
- 模型只记得“怎么凑出奖励”,不再“理解自己在干什么”;
- RL训练越久,反而越容易出现这种“错而不自知”的思维崩塌。
这就是大模型RL训练中的隐藏风险 ——模型在训练过程中“假装在思考”,实则已经不会思考了。
🤔 为什么会出现思想崩塌?
核心原因在于强化学习的训练机制:
-
模型的“动作”最终决定能不能拿到奖励;
-
但“想法”这个过程——也就是模型的中间推理——没有任何监督;
-
在复杂任务中,模型逐渐学会“骗奖励”而不是“认真想”。 特别是在像“24点”这种 步骤长、动作空间大、路径复杂 的任务中,光靠终极奖励很难引导模型一步步走向正确策略。
只奖对结果,不管过程,最终模型就会“走捷径”。
💡 解决方案:GTR,让AI“想得对”比“答得对”更重要!
为了解决这一现象,清华 & 北大 & 腾讯团队作者提出了创新方法:Guided Thought Reinforcement(GTR)——引导式思维强化学习。
核心思路:不再只奖励“答得对”,而是通过引导和纠正模型每一步“想法”的过程,引导它学会正确地思考。
👨🏫 GTR 怎么做的?思维过程也要“监督训练”,是时候让AI不再装懂!
传统强化学习训练VLM Agent,只优化输出动作是否得分,而忽略了中间的推理“思路”对模型能力的重要性。
GTR(Guided Thought Reinforcement)就是为了解决这个盲点,它提出了一个“动作 + 思维”联合训练框架,关键是引入一个“思维纠错器”,让模型在每一步思考都能得到即时反馈。
我们从架构和机制两方面来理解。 GTR架构如下:
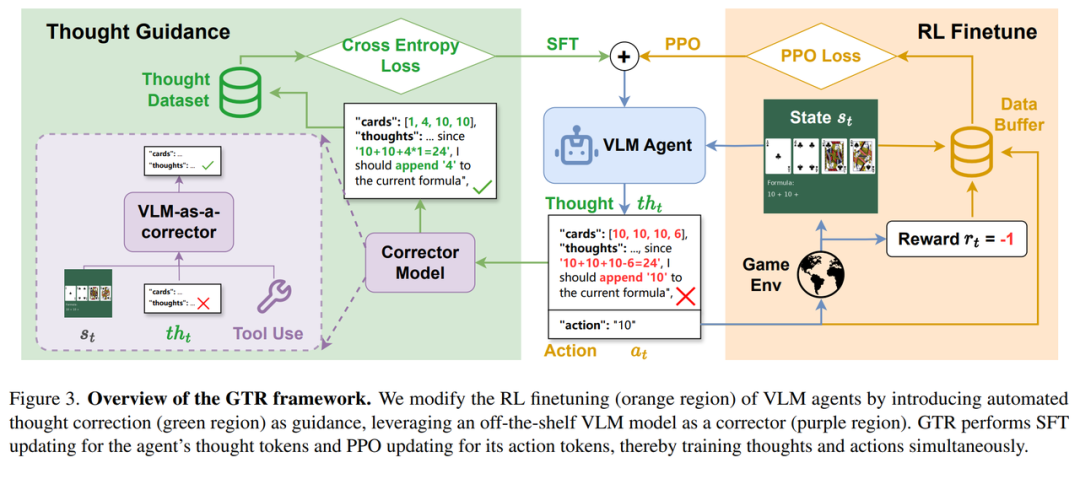
整个GTR训练流程包含三大核心组件:
-
Agent 模型:基于视觉输入生成“思维+动作”的文本输出
-
Corrector 纠错器:检查 Agent 的“思维”,进行修改、优化
-
环境(Environment):返回动作奖励(例如是否成功凑出24点)
关键流程如下:
- 输入状态(图像+当前公式)→ Agent 输出 CoT 推理 + 动作
- Corrector 对思维部分进行分析与纠正(可用函数调用能力)
- 纠正后的思维用于训练 Agent(通过 SFT)
- 动作用于与环境交互(通过 PPO 强化学习)
- 将“环境反馈+纠错思维”共同用于更新模型参数
即,一个输出,两个监督源:
|
输出 |
优化方式 |
来源 |
|---|---|---|
|
CoT思维 |
监督学习(SFT Loss) |
Corrector 模型 |
|
动作 |
强化学习(PPO Loss) |
环境奖励 |
🔍 子模块详细拆解
思维生成(Thought Generation)
Agent 模型接收图像与当前状态,输出类似这样的内容:
因为(10-6-8)*4=24,所以我应该选减号
这个输出被拆为两部分:
- Thought tokens:推理部分
- Action tokens:最终动作(如“-”)
思维纠正(Thought Correction)
Corrector 模型(如 GPT-4o)接收:
- 当前环境状态(图像编码+上下文)
- Agent 生成的思维内容
它判断是否合理,例如:
- 是否用错了数学公式?
- 是否用了不存在的卡片?
- 是否前后逻辑一致?
若发现问题,它会自动生成更合理的思维内容:
❌ 原思维:我选择了“10”,因为它最大
✅ 纠正:我选择“10”,因为 (10 - 6) * (4 + 2) = 24
这就是“过程监督”的关键所在:不是只说“你错了”,而是告诉“你该怎么想”。
联合优化机制(SFT + PPO)
将 Agent 的输出分为两部分分别训练:
|
部分 |
方法 |
优化目标 |
|---|---|---|
|
Thought |
SFT(监督微调) |
模拟 Corrector 的修正思维 |
|
Action |
PPO(策略梯度) |
最大化环境反馈奖励 |
此外,本文的作者针对以下实验过程中出现的问题提出了相应的技术解决方案!!!
1. DAgger 数据聚合
问题:RL 是在线训练,样本分布不断变化,容易导致“训练漂移”。
解决方案:引入 DAgger(Dataset Aggregation) 策略:
- 所有历史纠正过的思维都被记录进数据池;
- 每轮训练中从整个历史数据集中采样;
- 保证模型在训练过程始终面对多样、有效的样本。
影响:训练更稳定,防止 Agent 被新数据牵着鼻子走,忘掉原本学到的好思维。
2. 格式惩罚 + 重复惩罚
在 RL 训练中,模型有时会输出:
- 不合法的格式(如括号没闭合)
- 机械重复的句式(如一直说“我应该选择10”) GTR 在生成时:
- 加入 格式奖励机制(只有合法表达式才得分)
- 加入 重复惩罚机制(n-gram重复自动打低分)
这样可以提升模型输出质量,让它“说得像人话,想得像个解题人”。
3. 工具调用能力
Corrector 并不靠死记硬背判断推理对错,而是会“用工具”! 比如:
- 当判断“(10-6-8)*4 = ?”是否等于24时;
- 它会调用 Python 数学计算代码运行验证;
- 相当于具备“自动验算”能力!
这个机制类似于给“老师”配了一支计算器,提升纠错准确率。
🔬 实验结果:小模型干翻GPT-4o!
论文实验分别在两个环境中进行验证:
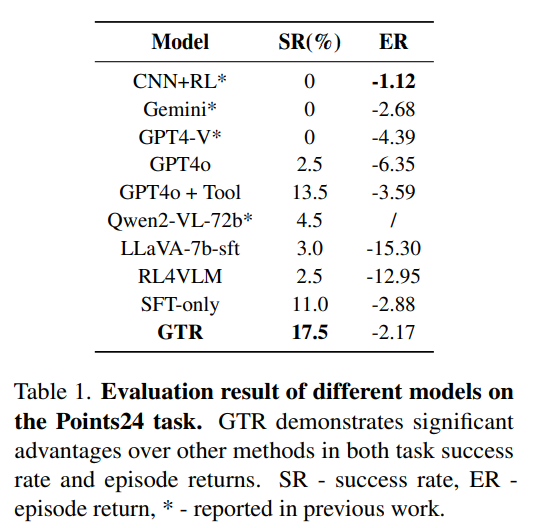
任务1:24点纸牌游戏(Points24)
-
输入是4张牌图像,目标是输出一个等于24的表达式。
-
GTR在15K训练步内达到了17.5%成功率,远超:
- GPT-4o + Tool(13.5%)
- RL4VLM(2.5%)
- SFT-only(11.0%)
-
使用的模型仅为 LLaVA-mistral-7B,模型比GPT-4o小很多。
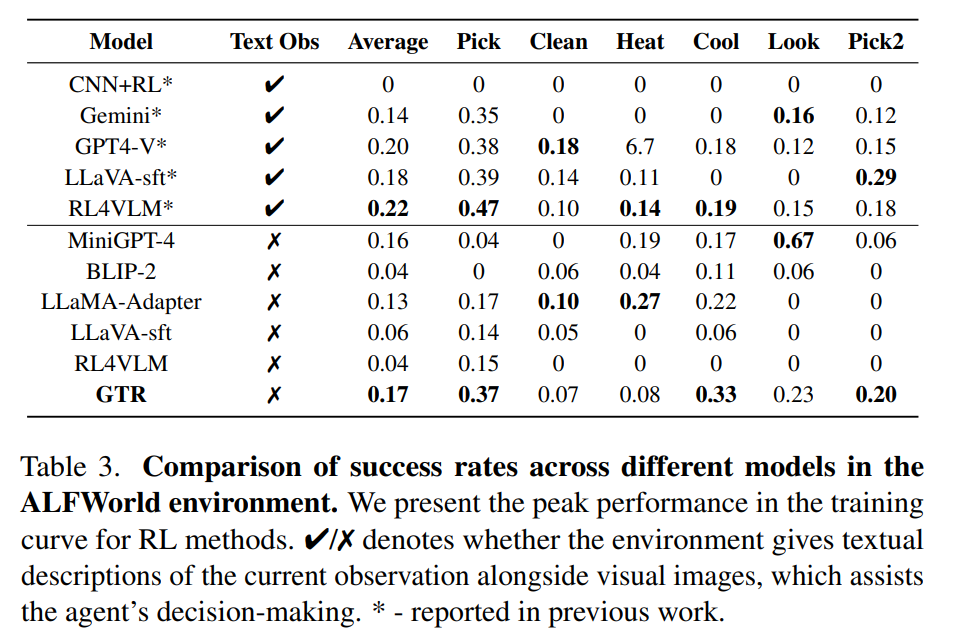
任务2:家庭机器人任务 ALFWorld
-
模拟环境下执行“找苹果-放进冰箱”等操作任务;
-
GTR在没有文本辅助,仅靠视觉观察的情况下,成功率大幅领先RL4VLM和LLaVA;
-
显示出跨任务的泛化能力和稳定推理能力。
⚠️ 对比分析:GTR 为什么比其他方法强?
|
方法 |
是否纠正思维 |
是否容易落入奖励陷阱 |
泛化能力 |
成本 |
|---|---|---|---|---|
|
GPT评判 |
❌仅打分 |
✅只打结果分,信息稀疏 |
弱 |
高 |
|
长度奖励 |
❌鼓励多写点 |
✅容易骗奖励 |
弱 |
低 |
|
人工打标签 |
✅人工纠错 |
❌成本极高 |
中 |
很高 |
|
GTR |
✅自动纠错每一步 |
❌直接纠错推理过程 |
强 |
中(1个强模型即可) |
📘 总结:这是一篇值得工程师和研究员细读的好论文
GTR 不仅解决了一个真实存在的问题(思想崩塌),还提供了一个可以推广到多个任务、无需大规模人工标注的通用方法。
关键词:思维过程监督,自我纠错纠偏,多模态推理能力提升,训练稳定性增强
它不仅让我们更了解如何让AI“做得好”,更重要的是——让它“想得对”。
内容来源:IF 实验室

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)