LLM分布式训练(二):流水线并行,让你的大模型“流动”起来!
LLM分布式训练(二):流水线并行,让你的大模型“流动”起来!
大家好,我是小雲呀!很高兴能和大家聊聊分布式训练中的另一个核心技术——流水线并行(Pipeline Parallelism)。
在上一篇关于数据并行的讨论中(如果你还没看,建议先了解一下),我们知道了像 DDP 和 FSDP 这样的技术如何通过在多个 GPU 上复制模型、处理不同数据分片来加速训练。特别是 FSDP,通过分片参数,大大缓解了显存压力。但当模型变得极其巨大(比如万亿参数级别),即便是 FSDP,单个 GPU 也可能无法容纳一个完整的模型分片(哪怕只是一个 Transformer 层的完整参数)。这时候,我们就需要另一种并行策略了。
想象一下,你的模型是一个超长的生产线,长到任何一个车间(GPU)都放不下。怎么办?很自然的想法就是,把生产线拆成几段,每个车间负责一段。这就是**模型并行(Model Parallelism)**的核心思想:将模型本身(而不是数据)拆分到不同的设备上。
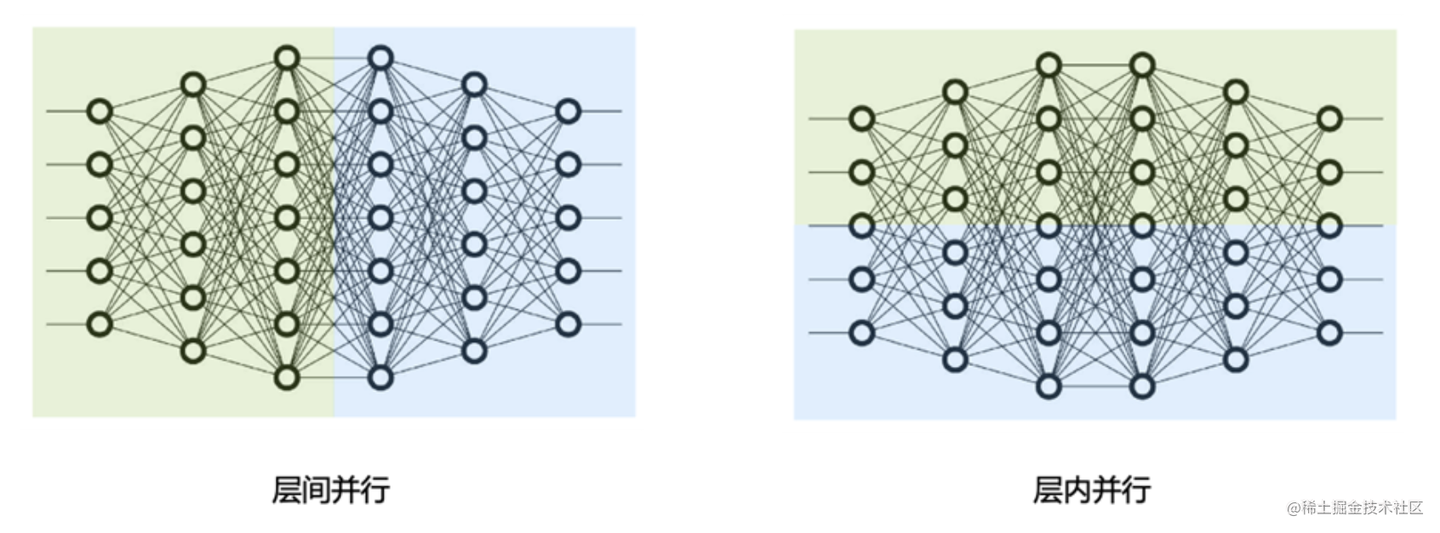
模型并行主要有两种“拆法”:
- 张量并行(Tensor Parallelism, TP):在“层内部”拆分。比如 Transformer 层里的矩阵乘法,可以把大矩阵切成小块,分给不同 GPU 计算,最后再汇总结果。这通常用于加速计算和节省单层内的显存。
- 流水线并行(Pipeline Parallelism, PP):在“层之间”拆分。把模型的不同层(比如多个 Transformer Blocks)放到不同的 GPU 上。这是我们今天的主角。
这篇博客,我们就来深入浅出地聊聊流水线并行,特别是业界知名的 GPipe 和 PipeDream 方案,帮助大家在面试中胸有成竹!
LLM分布式训练(二):流水线并行,让你的大模型“流动”起来!
1. 什么是流水线并行?为啥需要它?
简单来说,当你的模型大到单个 GPU 塞不下时,流水线并行就是救星。它把模型的不同层(或者一组层)分配到不同的 GPU 上。
核心思想: 模型按层顺序切分,每个 GPU 只负责模型的一部分(称为一个 Stage)。
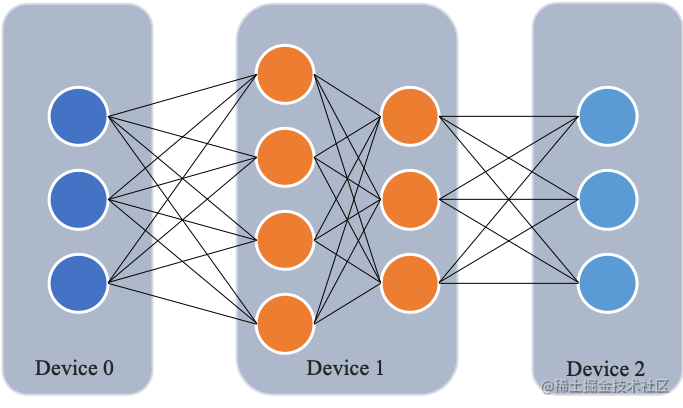
执行流程(直观理解):
- 前向传播 (Forward Pass):
- 输入数据
x进入 GPU 0,计算Stage 0(第 1 层) 的输出a1。 a1通过网络传输给 GPU 1。- GPU 1 基于
a1计算Stage 1(第 2、3 层) 的输出a3。 a3通过网络传输给 GPU 2。- GPU 2 基于
a3计算Stage 2(第 4 层) 的最终输出y,并计算损失Loss。
- 输入数据
- 反向传播 (Backward Pass):
- GPU 2 计算
Loss对a3的梯度g_a3。 g_a3传回给 GPU 1。- GPU 1 基于
g_a3计算Stage 1内部的参数梯度,并计算Loss对a1的梯度g_a1。 g_a1传回给 GPU 0。- GPU 0 基于
g_a1计算Stage 0内部的参数梯度。
- GPU 2 计算
- 参数更新:各个 GPU 使用计算得到的梯度更新自己负责的那部分模型的参数。
优点:
- 解决了显存瓶颈:每个 GPU 只需存储模型的一部分参数和对应的优化器状态,大大降低了单卡显存需求。
- 通信量相对可控:相邻 Stage 间传递的是激活值(前向)或激活值的梯度(反向),而不是整个模型的梯度(像数据并行那样需要 AllReduce)。
听起来很美好?别急,最简单的实现方式(朴素流水线并行)有个大问题。
2. 朴素流水线并行:起了个大早,赶了个晚集
最直接的想法就是:一个 mini-batch 的数据,按顺序流过所有 GPU。GPU 0 算完给 GPU 1,GPU 1 算完给 GPU 2……
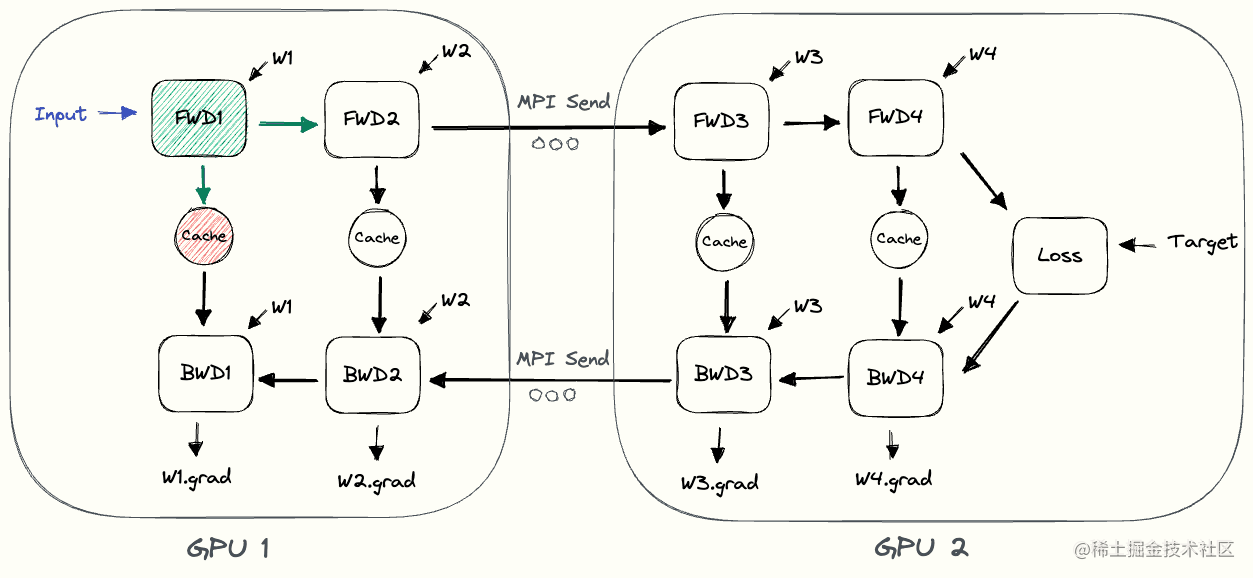
我们用伪代码模拟一下这个过程(假设有 2 个 GPU,模型分为 L1, L2 和 L3, L4 两部分):
# Mini-batch data: input
# GPU 0
activation_gpu0 = L2(L1(input)) # 计算并缓存激活
send(activation_gpu0, to=GPU1)
grad_activation_gpu0 = recv(from=GPU1)
backward(grad_activation_gpu0) # 计算 L1, L2 的梯度
update_params(L1, L2)
# GPU 1
activation_gpu0 = recv(from=GPU0)
output = L4(L3(activation_gpu0)) # 计算并缓存激活
loss = compute_loss(output, target)
backward(loss) # 计算 L3, L4 的梯度,以及对 activation_gpu0 的梯度
grad_activation_gpu0 = get_gradient(activation_gpu0)
send(grad_activation_gpu0, to=GPU0)
update_params(L3, L4)
问题在哪?—— “流水线气泡”(Pipeline Bubble)
看下面这张图,这是朴素流水线的执行时间线:
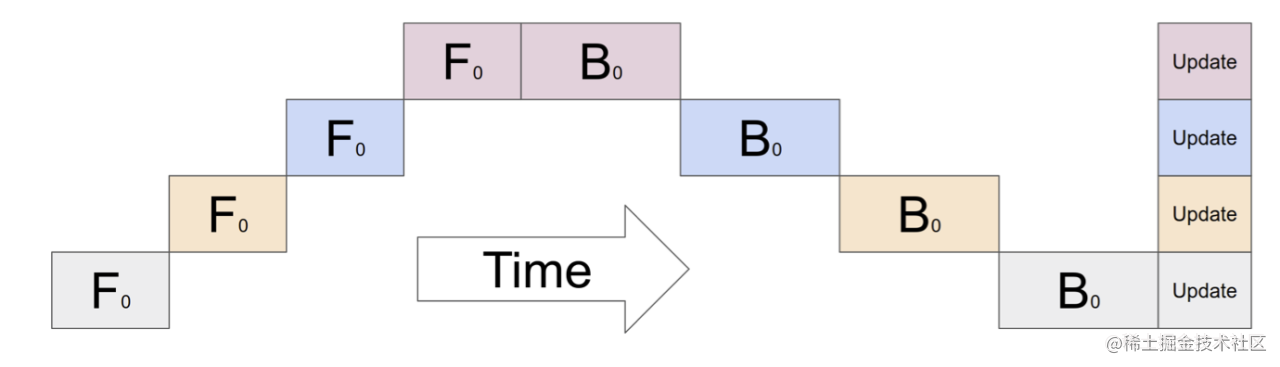
发现了没?在任何一个时间点,只有一个 GPU 在忙活!其他 GPU 都在干等。就像一条生产线,第一个工人加工完交给第二个工人时,自己就闲着了。这导致 GPU 利用率极低。
具体来说,朴素流水线并行的缺点:
- 严重的 GPU 空闲(Bubble 巨大):如果有 K 个 GPU (K个 Stage),那么空闲时间占比接近
(K-1)/K。GPU 越多,浪费越严重! - 通信开销:虽然单次通信量不大,但每次传输都需要时间。
- 计算与通信无法重叠:发送/接收数据时,GPU 往往处于等待状态。
- 高激活内存:第一个 Stage (GPU 0) 需要缓存整个 mini-batch 的激活值,直到反向传播传回来才能释放,内存压力可能很大。
结论:朴素流水线并行虽然解决了模型放不下的问题,但牺牲了太多计算效率,性价比不高。我们需要让所有 GPU 都动起来!
3. 微批次流水线并行:让流水线“流动”起来
怎么解决 GPU 空闲问题?答案是微批次(Micro-batching)。
核心思想: 将一个大的 mini-batch 切分成 M 个更小的 micro-batch。然后,像流水线一样,将这些 micro-batch 一个接一个地送入 GPU 计算流程。
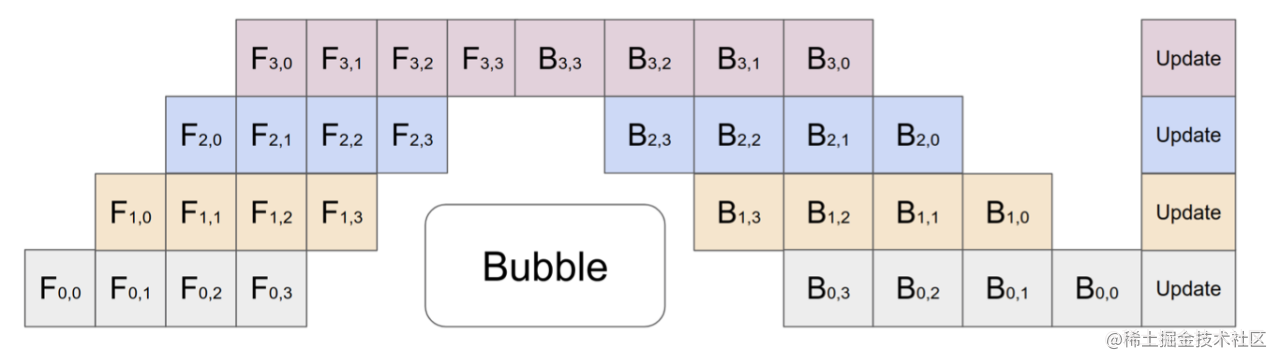
当第一个 micro-batch 在 GPU 1 上计算时,GPU 0 可以立刻开始处理第二个 micro-batch。这样,多个 GPU 就能在不同 micro-batch 上并行工作,大大减少了空闲时间。
这就是现代流水线并行(如 GPipe, PipeDream)的基础。
4. GPipe:微批次 + 重计算,谷歌的开创性工作
GPipe 是谷歌提出的早期且非常成功的流水线并行方案,它基于 PyTorch 的实现后来也被整合进了官方库 (torch.distributed.pipeline.sync.Pipe)。
GPipe 的两大核心技术:
-
微批次流水线 (Micro-batch Pipelining):
- 如上所述,通过将 mini-batch 拆分为 M 个 micro-batch,让多个 GPU 能同时处理不同的 micro-batch,显著减少了流水线气泡。
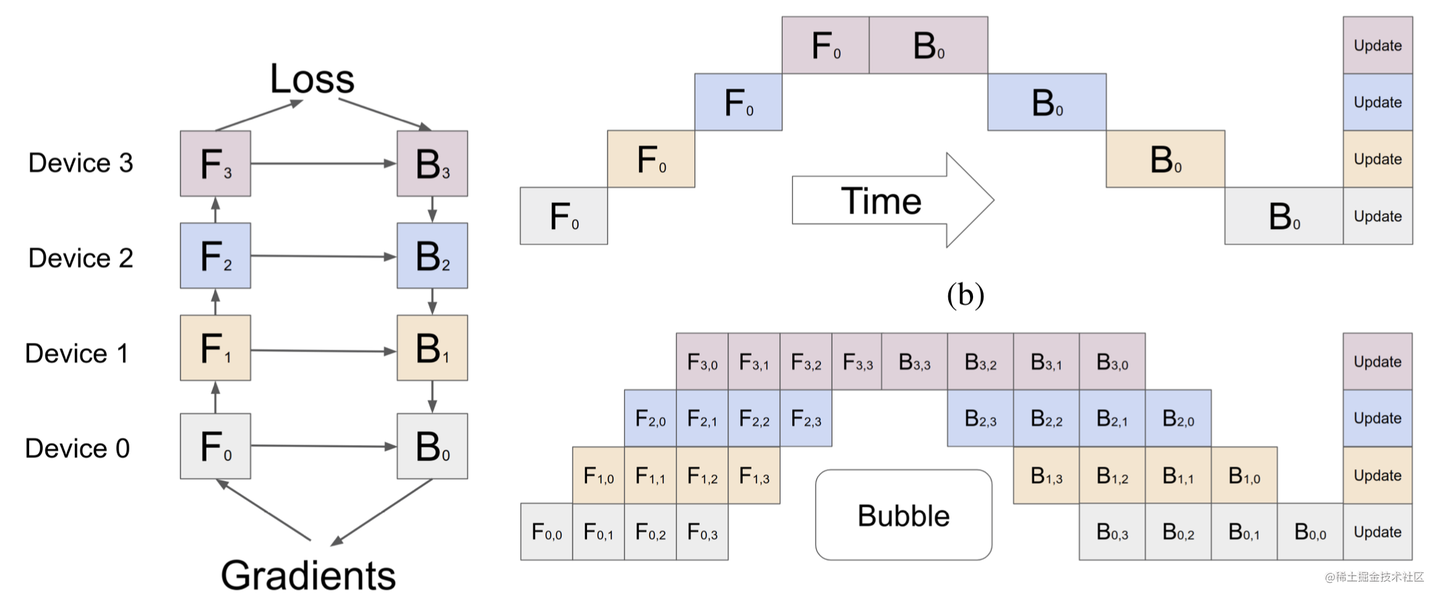
(图示:朴素流水线 vs GPipe 微批次流水线,气泡明显减少) - 气泡分析:假设有 K 个 Stage (GPU),M 个 micro-batch。气泡时间(或说浪费的比例)大致是
O((K-1)/(M+K-1))。当 M 远大于 K 时(M >> K),这个比例就变得很小,GPU 利用率大大提高。 - 对 Batch Normalization 的影响:BN 层依赖于批次统计量(均值、方差)。Micro-batch 会导致统计量不准。GPipe 的处理方式是:训练时用 micro-batch 的统计量,但同时累积计算整个 mini-batch 的移动平均统计量,用于推理(inference)。Layer Normalization 则不受影响。
- 如上所述,通过将 mini-batch 拆分为 M 个 micro-batch,让多个 GPU 能同时处理不同的 micro-batch,显著减少了流水线气泡。
-
重计算 (Re-materialization / Activation Checkpointing):
-
问题:即使有了 micro-batch,每个 Stage 仍然需要为所有在其上传递的 micro-batch 缓存激活值,直到对应的反向传播完成。如果 M 很大,这仍然可能导致显存 OOM。
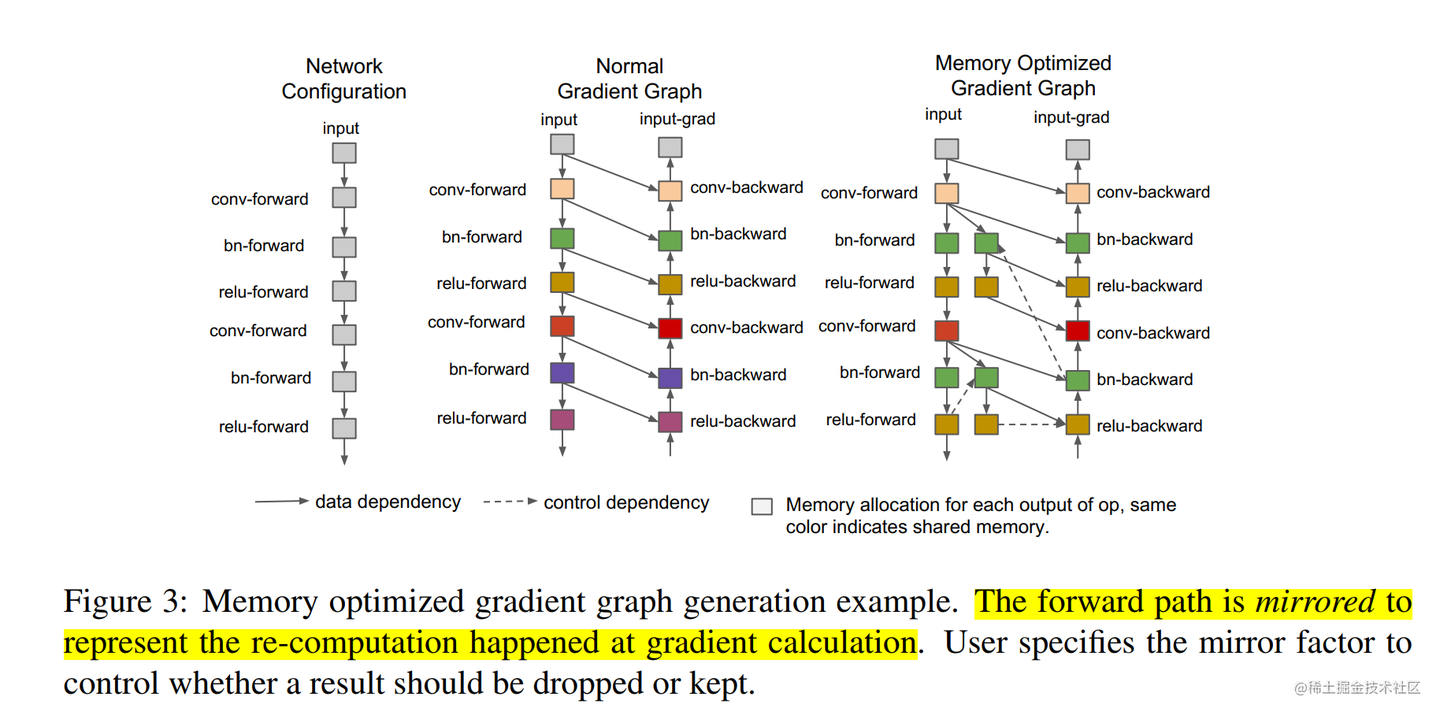
*(图示:前向传播需要缓存激活用于反向计算)* -
解决方案:在反向传播需要某个激活值时,不从缓存读取,而是重新进行一次前向计算得到它!这样,在前向传播时,我们只需要保存当前 Stage 的输入即可,中间层的激活值可以不用保存。
-
本质:用计算换显存。牺牲一点计算时间(重新计算前向),来大幅降低峰值显存占用。这对于显存极其宝贵的超大模型训练至关重要。
-
GPipe 中的应用:如果一个 Stage 包含多层,可以只保存该 Stage 的第一个 micro-batch 的输入,后续 micro-batch 的激活在反向传播时按需重算。
-
GPipe 小结:通过微批次提高了并行度,通过重计算降低了显存峰值。
PyTorch GPipe 示例 (torch.distributed.pipeline.sync.Pipe):
import torch
import torch.nn as nn
import os
from torch.distributed.pipeline.sync import Pipe
# 假设在单机多卡环境 (GPU 0, GPU 1)
# 需要先初始化 RPC (远程过程调用) 框架
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500' # 选择一个未被占用的端口
# 注意:实际多机或多进程使用时,rank 和 world_size 需要正确设置
torch.distributed.rpc.init_rpc('worker', rank=0, world_size=1)
# 定义模型层,并分配到不同 GPU
fc1 = nn.Linear(16, 8).cuda(0)
fc2 = nn.Linear(8, 4).cuda(1)
model_sequential = nn.Sequential(fc1, fc2)
# 将模型包装成 Pipe 对象
# chunks: 指定一个 mini-batch 包含多少个 micro-batch
model = Pipe(model_sequential, chunks=8, checkpoint='always') # checkpoint='always' 开启重计算
# 准备输入数据 (放在第一个 stage 所在的 GPU 上)
input_tensor = torch.rand(16 * 8, 16).cuda(0) # 假设 batch_size=16*8=128
# 执行前向传播 (会自动处理流水线和通信)
# 注意:输出是一个 RRef (Remote Reference),需要 .local_value() 获取实际张量
output_rref = model(input_tensor)
output_tensor = output_rref.local_value() # 这会阻塞直到计算完成
print("Output shape:", output_tensor.shape) # 应为 torch.Size([128, 4])
# 后续的反向传播和优化器步骤也需要相应调整 (参考 PyTorch Pipeline 文档)
# ... loss.backward(), optimizer.step() ...
torch.distributed.rpc.shutdown()
GPipe 很有效,但它的调度方式(称为 F-then-B)还有优化空间。
5. 流水线调度策略:F-then-B vs 1F1B
GPipe 使用的是 F-then-B (Forward-then-Backward) 调度策略:
-
F-then-B:对于一个 mini-batch (包含 M 个 micro-batch),先把所有 M 个 micro-batch 的前向计算全部跑完,然后再依次进行所有 M 个 micro-batch 的反向计算。
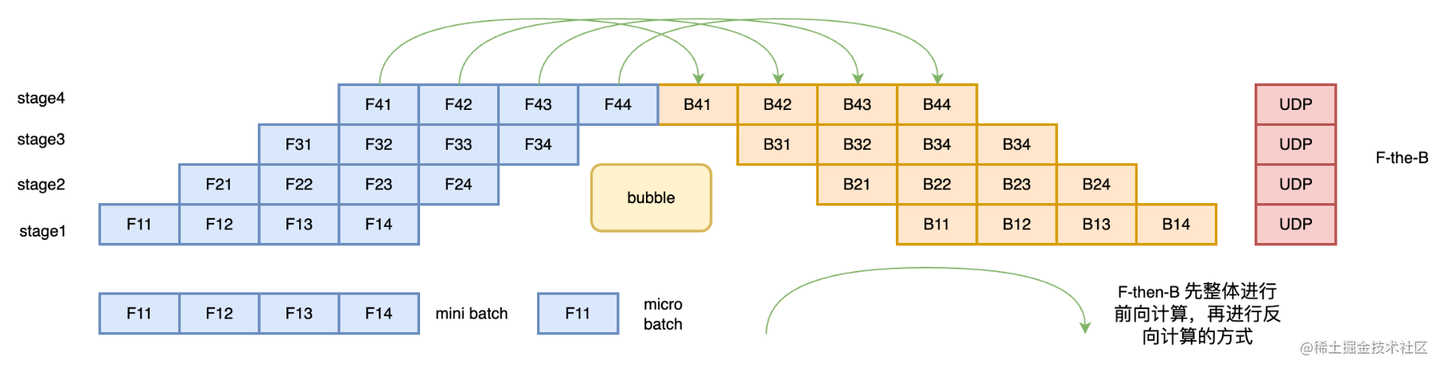
*(图示:F-then-B 调度,先完成所有前向,再进行所有反向)* -
缺点:需要缓存的激活值数量峰值与 M 相关,内存压力还是比较大。
为了进一步优化显存,1F1B (One Forward, One Backward) 调度策略应运而生:
-
1F1B:想法是,一旦某个 micro-batch
i在某个 Stagej完成了前向计算,并且下游 Stagej+1也完成了它的前向计算,那么 Stagej就可以尽快开始 micro-batchi的反向计算。这样,micro-batchi的激活值可以更早地被释放。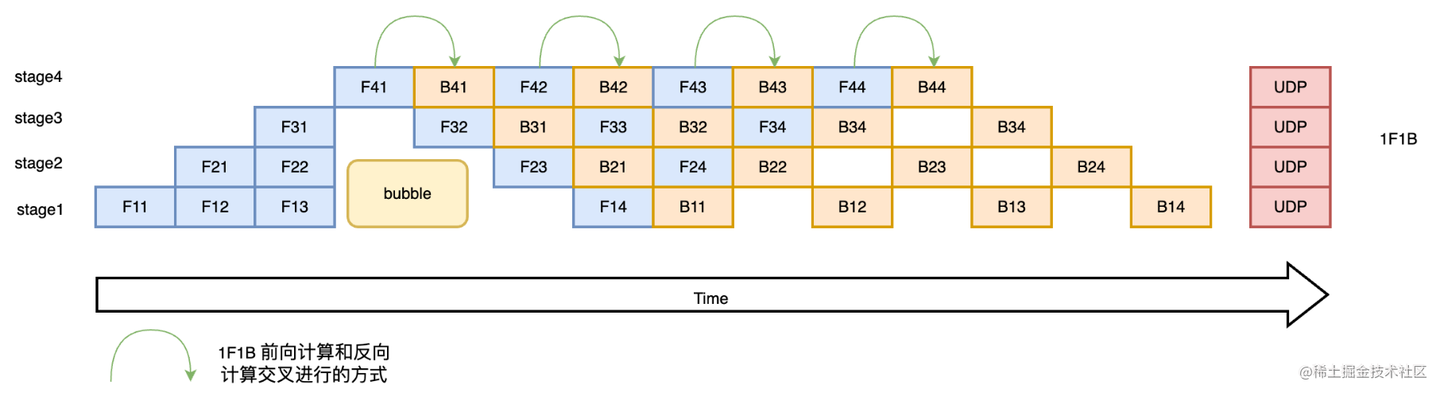
(图示:1F1B 调度,前向和反向交错进行) -
优点:通过交错执行前向和反向,可以显著降低峰值激活内存。理论上,峰值激活内存只跟 Stage 数量 K 相关,而与 micro-batch 数量 M 无关(或关系减弱)。研究表明,相比 F-then-B,峰值显存可节省高达 37.5%。
1F1B 策略是 PipeDream 系列方案的核心。
6. PipeDream:1F1B 调度,微软的显存优化探索
PipeDream (来自微软 DeepSpeed 团队) 针对 GPipe 的问题进行了改进,主要采用了 1F1B 调度策略。
PipeDream 的出发点 (解决 GPipe 的问题):
- 流水线刷新 (Pipeline Flush) 效率低:GPipe 的 F-then-B 需要在 M 个 micro-batch 的前向和反向之间有一个“空档期”,称为 Flush,这会降低效率。
- 激活内存依然较高:即使有重计算,F-then-B 模式下,需要缓存的激活值(或其输入)的生命周期较长。
PipeDream (早期版本) 的核心思想:
-
采用 1F1B 调度:实现上述的 Forward/Backward 交错执行,目标是让每个 Stage 在稳定状态(Steady State)下,总是有活干(要么是某个 micro-batch 的前向,要么是另一个 micro-batch 的反向),从而提高 GPU 利用率,并降低峰值显存。
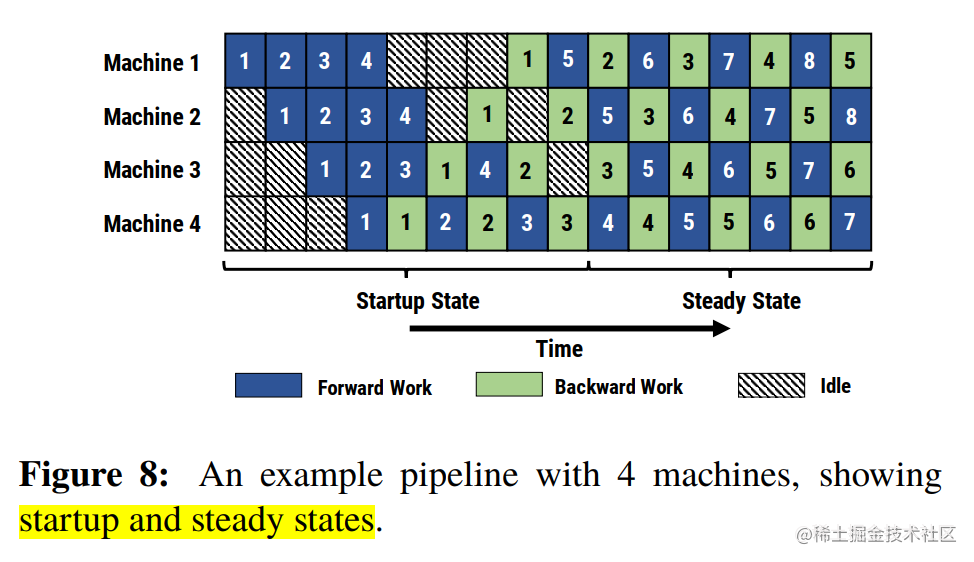
*(图示:PipeDream (非交错式 1F1B) 的调度时间线)* -
权重版本问题 (Weight Stashing - 早期 PipeDream 的挑战):1F1B 带来一个新问题。考虑 micro-batch
i和i+1。i的前向计算用的是权重W_v。在i+1的反向计算完成前,i可能已经完成了前向和反向,并更新了权重得到W_{v+1}。那么i+1的反向计算应该用哪个版本的权重?为了保证梯度计算的正确性(与朴素串行计算一致),理论上i+1的前向和反向应该使用同一版本权重W_v。早期 PipeDream 提出了一种权重存储 (Weight Stashing) 方案:为不同的“飞行中”的 micro-batch 保存不同版本的权重。这会带来额外的显存开销和管理复杂性。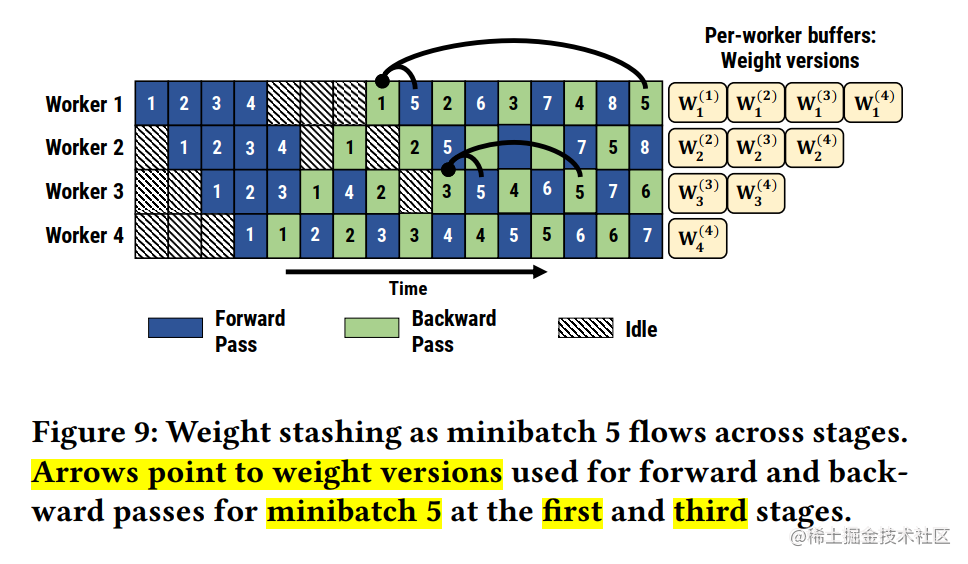
PipeDream-Flush (DeepSpeed 中常用的变种):
鉴于 Weight Stashing 的复杂性和显存开销,实际中(如 DeepSpeed 框架)常用的是一种称为 PipeDream-Flush 的变体。
-
核心思想:结合了 1F1B 的调度优势(低激活内存)和 GPipe 的简单性(单一权重版本)。
-
做法:采用 1F1B 的调度模式来执行前向和反向,但只维护一套模型权重。为了保证权重更新的一致性(类似于数据并行),它也引入了周期性的流水线刷新 (Flush)。在一个 mini-batch (M 个 micro-batch) 处理完毕后,累积梯度,然后进行一次参数更新。
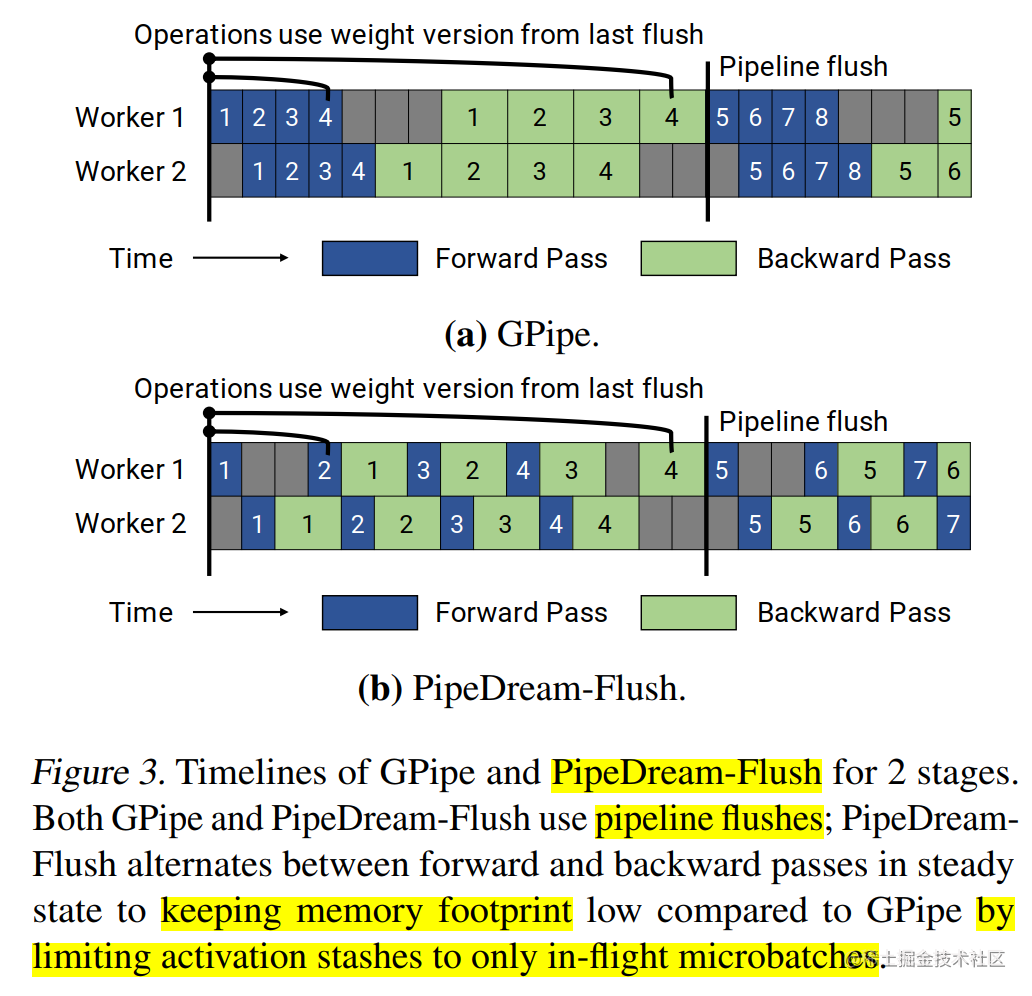
*(图示:PipeDream-Flush vs GPipe 时间线对比,两者都有 Flush 阶段)* -
权衡 (Trade-off):相比需要 Weight Stashing 的“纯”1F1B,它牺牲了一点吞吐量(因为有 Flush),但大大降低了实现复杂度和权重版本的显存开销。相比 GPipe (F-then-B),它通常有更好的峰值激活内存表现。
PipeDream-2BW (另一个变种):
还存在一种 PipeDream-2BW (Double-Buffered Weights) 方案,试图在权重版本数量和吞吐量之间取得更好的平衡。它只维护两个版本的权重(当前版本和下一个版本),通过精心设计的缓冲和更新策略,减少了 Flush 的需要,提高了吞吐量,同时限制了权重版本的内存开销。但这相对复杂,PipeDream-Flush 更为常见。

吞吐量与内存对比总结 (大致趋势):
- 吞吐量:PipeDream-2BW > PipeDream-Flush ≈ GPipe (取决于具体参数和模型)
- 峰值激活内存:PipeDream-Flush ≈ PipeDream-2BW < GPipe (1F1B 优于 F-then-B)
- 权重内存:PipeDream-Flush = GPipe (单版本) < PipeDream-2BW (双版本) < 早期 PipeDream (多版本)
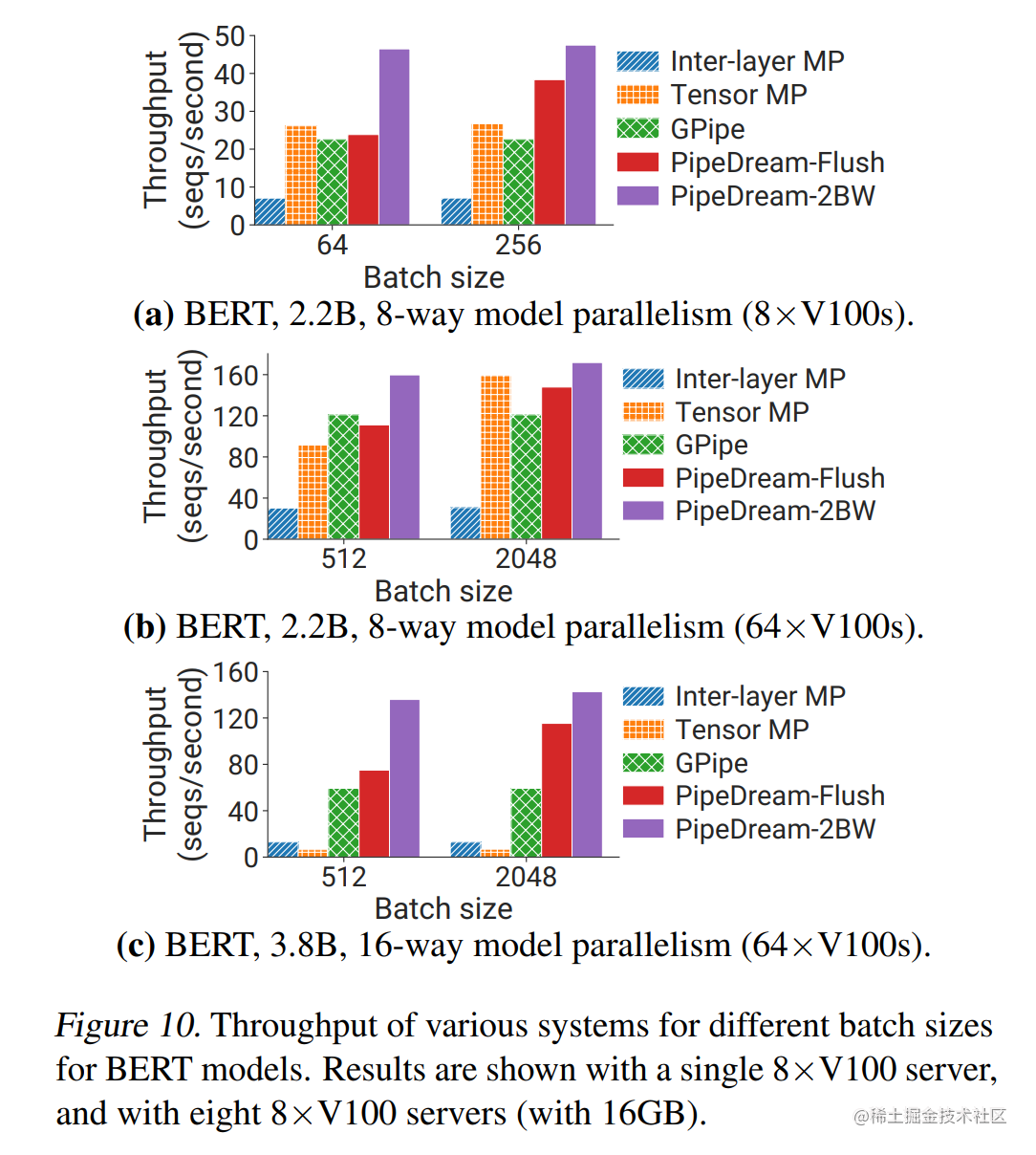
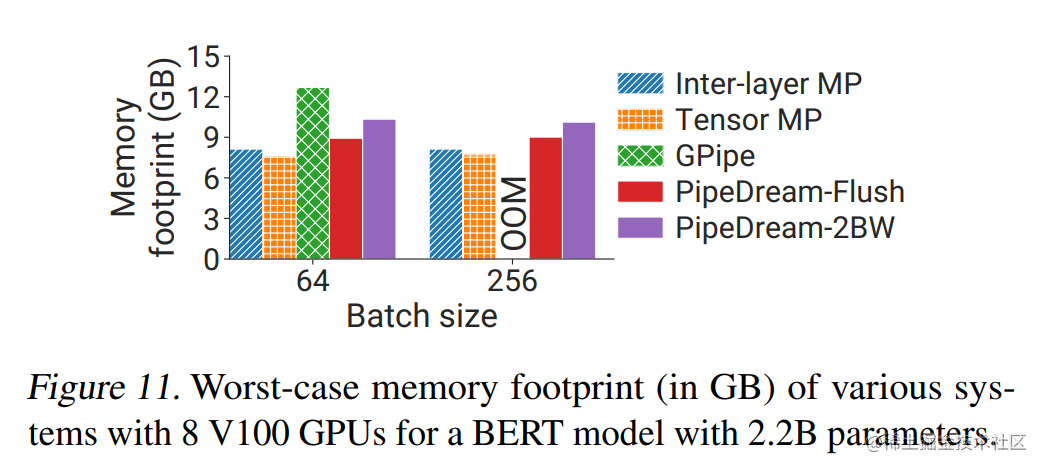
PipeDream-Flush (非交错 1F1B) 已经很不错了,但还有没有办法进一步减少气泡呢?
7. 交错式 1F1B (Interleaved 1F1B):Megatron-LM 的进一步优化
观察 PipeDream-Flush (或 GPipe) 的时间线,即使使用了微批次,在流水线启动(warm-up)和结束(cool-down)阶段,仍然存在明显的气泡。
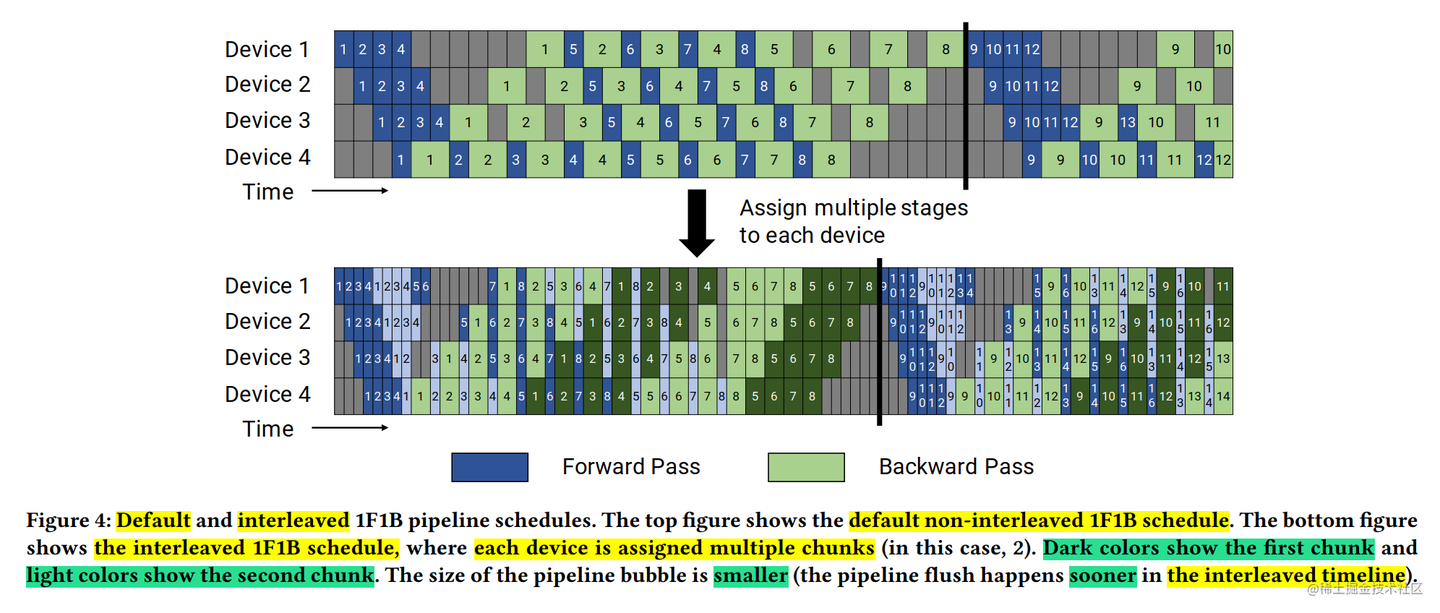
英伟达的 Megatron-LM 框架提出了一种 交错式 1F1B (Interleaved 1F1B) 调度策略,有时也称为 虚拟流水线 (Virtual Pipeline)。
核心思想:不让一个 GPU 只负责一段连续的层,而是负责多段不连续的层块 (model chunks)。
例子:假设有 16 层模型,4 个 GPU (K=4)。
- 非交错 (传统 PP):
- GPU 0: Layers 0-3
- GPU 1: Layers 4-7
- GPU 2: Layers 8-11
- GPU 3: Layers 12-15
- 交错 (Megatron-LM, 假设每个 GPU 负责 v=2 个 chunk):
- GPU 0: Layers 0-1 (Chunk 0) + Layers 8-9 (Chunk 4)
- GPU 1: Layers 2-3 (Chunk 1) + Layers 10-11 (Chunk 5)
- GPU 2: Layers 4-5 (Chunk 2) + Layers 12-13 (Chunk 6)
- GPU 3: Layers 6-7 (Chunk 3) + Layers 14-15 (Chunk 7)
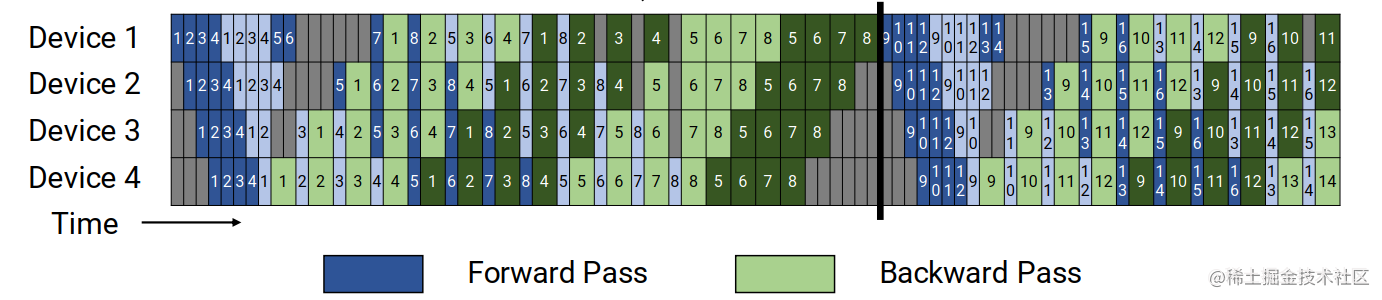
好处:
- 显著减少气泡:通过将任务更均匀地打散和交错,启动和结束阶段的气泡可以被大幅压缩。理论上,气泡比例可以降低
v倍(v是每个 GPU 负责的 chunk 数)。 
- (公式:气泡时间与 v 成反比)
代价:
- 增加通信量:原来只需要在相邻 Stage (GPU) 之间通信。现在,比如 GPU 0 完成 Chunk 0 (Layers 0-1) 后,需要将结果发给 GPU 1 (负责 Chunk 1);完成 Chunk 4 (Layers 8-9) 后,需要发给 GPU 1 (负责 Chunk 5)。通信模式变得更复杂,总通信量增加了
v倍。 - 实现更复杂:调度逻辑更难处理。
- 对网络要求高:需要高速的 GPU 间互联(如 NVLink)和节点间网络(如 InfiniBand)来承受增加的通信压力。
交错 1F1B 小结:用更多的通信换取更少的空闲时间(气泡),适合硬件(特别是网络)条件好的场景。
8. 各大框架中的流水线并行方案
- PyTorch (原生):主要提供基于 GPipe 的
torch.distributed.pipeline.sync.Pipe,采用 F-then-B 调度,支持重计算。相对简单易用,但效率可能不是最优。 - DeepSpeed:实现了基于 PipeDream-Flush 的流水线并行,采用非交错 1F1B 调度。注重显存效率和易用性,是训练超大模型的热门选择。其流水线调度模块是可扩展的。
- Megatron-LM:其特色是交错式 1F1B 调度(Virtual Pipeline),追求极致的吞吐量,尤其是在 NVLink 和 InfiniBand 等高速网络支持下表现优异。通常与张量并行结合使用。
- Colossal-AI:提供了多种流水线调度选项,包括非交错 1F1B (
PipelineSchedule) 和交错 1F1B (InterleavedPipelineSchedule),让用户可以根据场景选择。
9. 总结与回顾
流水线并行是解决单卡显存不足、训练超大模型的关键技术。我们回顾一下它的发展历程和核心要点:
- 朴素流水线并行:最简单的想法,按层切分模型到不同 GPU,但存在严重的气泡问题,GPU 利用率低。
- 微批次 (Micro-batching):将大 batch 拆成小 micro-batch,让 GPU 并行处理,是现代流水线并行的基础。
- GPipe:结合了微批次和重计算 (Activation Checkpointing),前者提高并行度,后者降低激活内存。采用 F-then-B 调度。
- 1F1B 调度:通过交错执行前向和反向,进一步降低峰值激活内存。
- PipeDream:
- PipeDream-Flush (常用):采用 非交错 1F1B 调度 + 单权重版本 + 周期性 Flush。在显存和实现复杂度上取得良好平衡。
- 其他变种 (如 PipeDream-2BW, 早期需 Weight Stashing) 探索不同的权重管理策略。
- 交错式 1F1B (Megatron-LM):通过让 GPU 负责不连续的模型块 (Virtual Pipeline),显著减少气泡,但增加通信量。
核心权衡 (Trade-offs) 无处不在:
- 气泡 vs 通信 (交错 vs 非交错 1F1B)
- 激活内存 vs 计算 (重计算)
- 权重一致性/简单性 vs 吞吐量 (单版本+Flush vs 多版本/复杂更新)
面试要点提炼 (Interview Key Points)
面试官可能会问到:
- 什么是流水线并行?它解决了什么问题?
- 答:将模型按层切分到不同设备,解决单卡显存不足的问题。
- 朴素流水线并行有什么缺点?如何解决?
- 答:主要缺点是“流水线气泡”,GPU 利用率低。通过“微批次”技术解决,让多 GPU 并行处理不同 micro-batch。
- GPipe 的核心思想是什么?
- 答:微批次提高并行度,重计算(Activation Checkpointing)降低激活内存。使用 F-then-B 调度。
- 什么是 1F1B 调度?相比 F-then-B 有什么优势?
- 答:交错执行前向和反向计算。主要优势是显著降低峰值激活内存占用。
- PipeDream (特别是 PipeDream-Flush) 和 GPipe 的主要区别?
- 答:调度策略不同 (1F1B vs F-then-B),导致 PipeDream-Flush 通常有更好的激活内存效率。两者都使用单权重版本和 Pipeline Flush。
- Megatron-LM 的交错式 1F1B (Virtual Pipeline) 是什么?有什么优缺点?
- 答:让每个 GPU 负责多个不连续的模型块。优点是进一步减少流水线气泡,提高吞吐量。缺点是显著增加通信量和实现复杂度,依赖高速网络。
- 流水线并行中的关键权衡有哪些?
- 答:气泡 vs 通信;激活内存 vs 重计算开销;权重管理简单性 vs 吞吐量。
希望这篇博客能帮助大家更深入地理解流水线并行技术。分布式训练是通往更大、更强模型之路的必经技术,掌握它,无论对面试还是实际工作都大有裨益。
如果你有任何问题,或者想进一步讨论某个细节,欢迎在评论区留言交流!祝大家学习顺利,面试成功!
参考链接:
https://zhuanlan.zhihu.com/p/653860567

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)