LangChain4j简介
LangChain4j 是 LangChain 的 Java 版本,旨在为 Java 开发者提供构建大型语言模型(LLM)应用的框架。它简化了 LLM 与 Java 应用程序的集成,支持多种主流模型(如 OpenAI、阿里百炼、百度文心等),并提供丰富的工具链,如聊天记忆管理、提示模板、检索增强生成(RAG)、工具调用(Function Calling)和智能代理(Agent)等。
LangChain4j
LangChain4j 是 LangChain 的 Java 版本,旨在为 Java 开发者提供构建大型语言模型(LLM)应用的框架。它简化了 LLM 与 Java 应用程序的集成,支持多种主流模型(如 OpenAI、阿里百炼、百度文心等),并提供丰富的工具链,如聊天记忆管理、提示模板、检索增强生成(RAG)、工具调用(Function Calling)和智能代理(Agent)等
OpenAI API 请求与响应参数详解
请求信息
响应信息
LangChain4j快速入门
获取ApiKey
阿里云百炼获取ApiKey:https://bailian.console.aliyun.com/?utm_content=se_1021829511&tab=model#/api-key
创建ApiKey
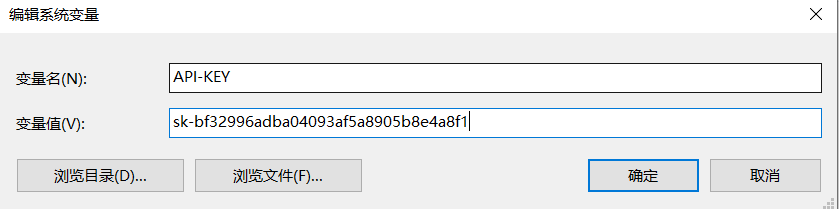
给ApiKey设置环境变量
引入依赖
langchain4j-open-ai依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.0.1-beta6</version>
</dependency>
junit5依赖
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.10.1</version>
</dependency>
LangChain4j官方demo
使用官方提供的演示模型
/**
* 官方提供的演示ai模型
*/
@Test
void official()
{
OpenAiChatModel model = OpenAiChatModel.builder()
.baseUrl("http://langchain4j.dev/demo/openai/v1")
.apiKey("demo")
.modelName("gpt-4o-mini")
.build();
String answer = model.chat("你是谁?");
System.out.println(answer);
}
运行后结果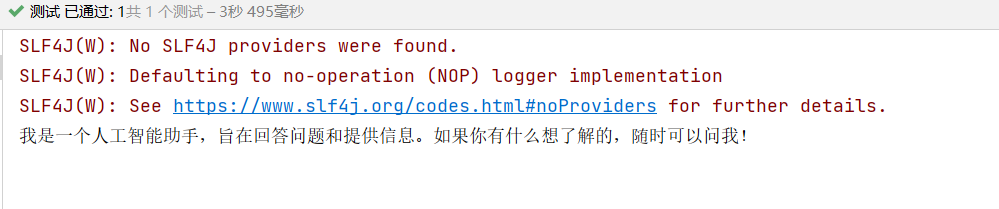
使用通义千问(qwen-plus)
/**
* 接入通义千问(qwen-plus)
*/
@Test
void getApiKey()
{
//获取环境变量配置的API-KEY
String key = System.getenv("API-KEY");
OpenAiChatModel model = OpenAiChatModel.builder()
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1") //基地址
.apiKey(key) //密钥
.modelName("qwen-plus") //使用模型
.build(); //构建
//调用chat方法进行交互
String mes = model.chat("你是谁?");
System.out.println(mes);
}
运行后如果获取不到环境变量,需要重启编译器(idea)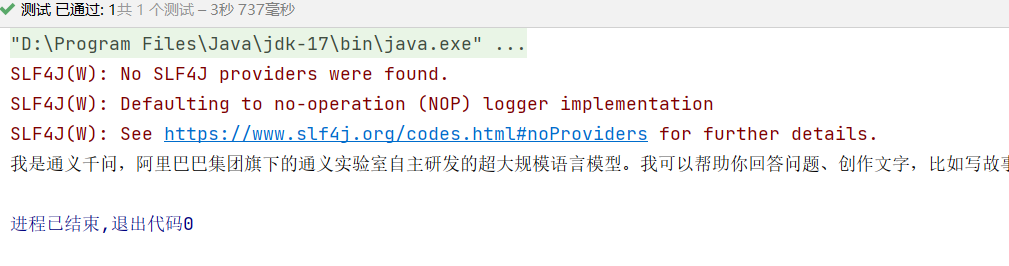
LangChain4j配置日志信息
日志依赖
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.5.18</version>
</dependency>
代码
设置logRequests和logResponses
OpenAiChatModel model = OpenAiChatModel.builder()
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1") //基地址
.apiKey(key) //密钥
.modelName("qwen-plus") //使用模型
.logRequests(true) //请求
.logResponses(true) //响应
.build(); //构建
结果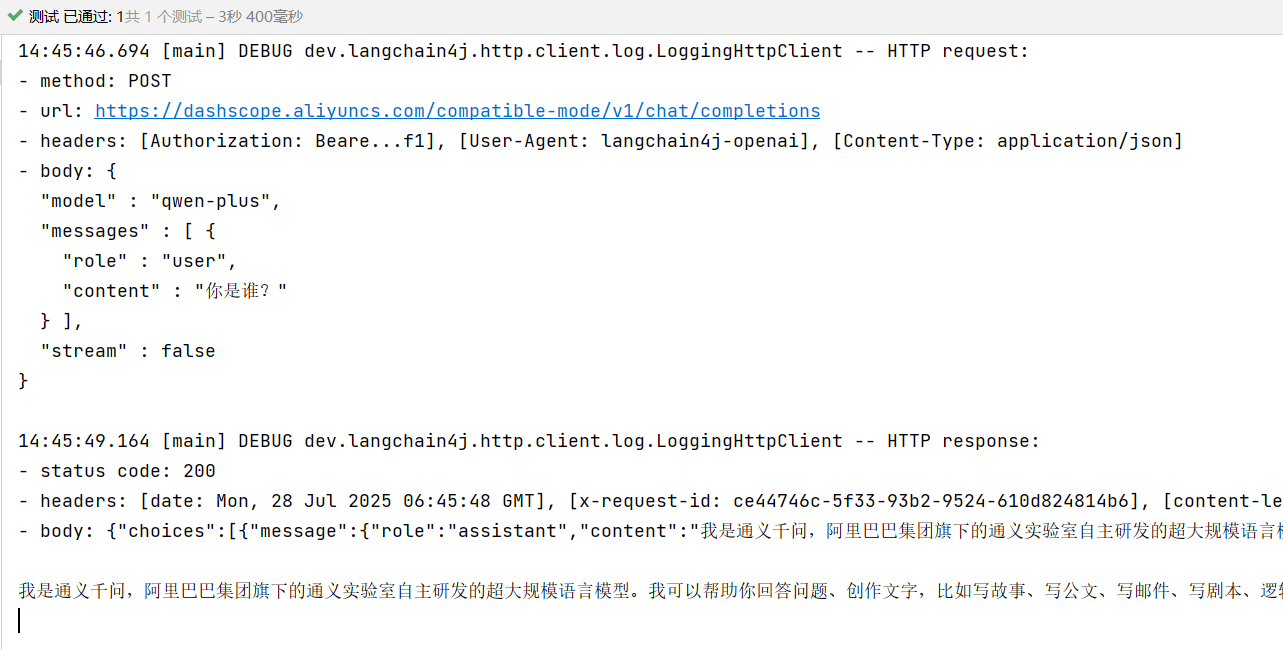
Spring整合LangChain4j
使用环境
SpringBoot:3.2.4
引入依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.0.0-beta3</version>
</dependency>
yaml文件配置
server:
port: 8100
#配置langchain4j
langchain4j:
open-ai:
chat-model:
api-key: ${API-KEY} #使用环境变量配置
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 #基地址
model-name: qwen-plus #模型
log-requests: true #请求
log-responses: true #响应
#配置日志级别
logging:
level:
dev.langchain4j: debug
配置日志一定要开启log-requests和log-responses并且设置日志级别
Controller代码
import dev.langchain4j.model.chat.ChatLanguageModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ChatController {
@Autowired
ChatLanguageModel chatLanguageModel;
@GetMapping("/chat")
public String model(@RequestParam(value = "message", defaultValue = "Hello") String message)
{
return chatLanguageModel.chat(message);
}
}
运行
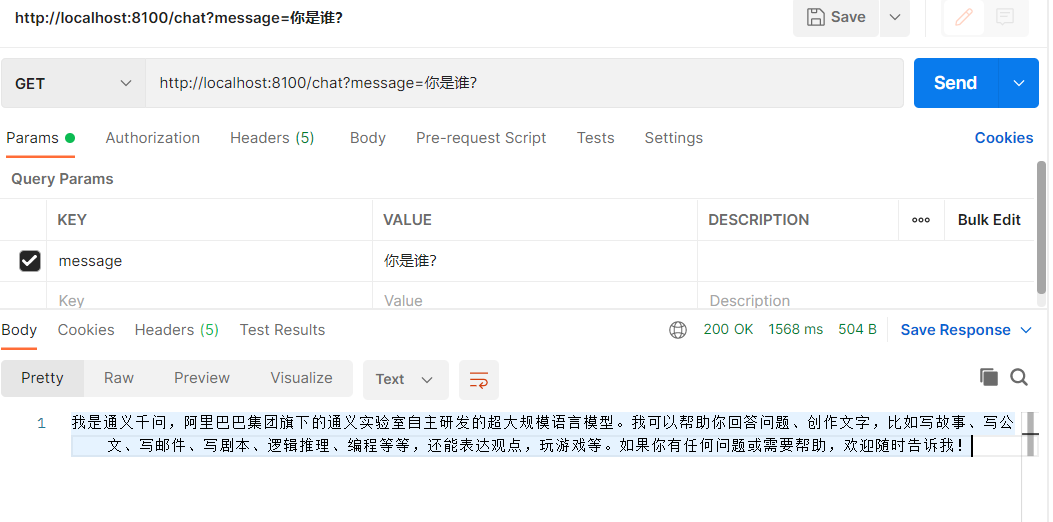
会话功能
AiService工具
引入依赖
<!-- 工具 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.0.1-beta6</version>
</dependency>
声明接口
import dev.langchain4j.service.spring.AiService;
import dev.langchain4j.service.spring.AiServiceWiringMode;
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, //手动装配
chatModel = "openAiChatModel" //指定模型
)
public interface ConsultantService
{
public String chat(String mes);
}
在Controller中注入使用
import org.example.service.ConsultantService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ChatController
{
@Autowired
private ConsultantService consultantService;
@GetMapping("chat")
public String chat(@RequestParam String mes)
{
String chat = consultantService.chat(mes);
return chat;
}
}
流式调用
引入依赖
<!--流式调用-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.0.1-beta6</version>
</dependency>
修改yml配置
server:
port: 8100
#配置langchain4j
langchain4j:
open-ai:
streaming-chat-model: #流式调用配置
api-key: ${API-KEY} #使用环境变量配置
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 #基地址
model-name: qwen-plus #模型
log-requests: true #请求
log-responses: true #响应
chat-model: #阻塞调用配置
api-key: ${API-KEY} #使用环境变量配置
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 #基地址
model-name: qwen-plus #模型
log-requests: true #请求
log-responses: true #响应
#配置日志级别
logging:
level:
dev.langchain4j: debug
流式调用只需要关注streaming-chat-model参数
修改接口
修改接口放回值,并且添加流式模型
import dev.langchain4j.service.spring.AiService;
import dev.langchain4j.service.spring.AiServiceWiringMode;
import reactor.core.publisher.Flux;
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, //手动装配
chatModel = "openAiChatModel", //阻塞 指定模型
streamingChatModel = "openAiStreamingChatModel" //流式 指定模型
)
public interface ConsultantService
{
public Flux<String> chat(String mes);
}
Controller代码
import org.example.service.ConsultantService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
public class ChatController
{
@Autowired
private ConsultantService consultantService;
// @GetMapping(value = "chat",produces = "text/html;charset=utf-8") //produces设置字符集
@GetMapping(value = "chat")
public Flux<String> chat(@RequestParam String mes)
{
Flux<String> chat = consultantService.chat(mes);
return chat;
}
}
效果
还在输出中
输出完成
消息注解
@SystemMessage
用于标记系统消息,通常用于设置AI助手的角色或行为
使用
添加@SystemMessage注解,并且设置系统提示词,
- 定义 AI 助手的 角色(如“你是一名心理咨询师”)。
- 提供 行为规范(如“回答要简洁专业”)。
- 设置 全局上下文(如“所有回答请用中文”)。
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.spring.AiService;
import dev.langchain4j.service.spring.AiServiceWiringMode;
import reactor.core.publisher.Flux;
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, //手动装配
chatModel = "openAiChatModel", //阻塞 指定模型
streamingChatModel = "openAiStreamingChatModel" //流式 指定模型
)
public interface ConsultantService
{
@SystemMessage("你是一名心理咨询师")
public Flux<String> chat(String mes);
}
结果
@UserMessage
用于定义 用户输入 或 AI 需要处理的查询。它通常与 @SystemMessage 结合使用,构建完整的 AI 对话逻辑。
使用
1.定义用户的输入(如问题、指令)。
2.支持模板化输入(使用 {{variable}} 语法动态插入变量)。
@UserMessage("1.友好且专业的语气回答2.简短回答,{{it}}") //协助用户设置词条,it为默认参数表示用户消息
public Flux<String> chat(String mes);
结果: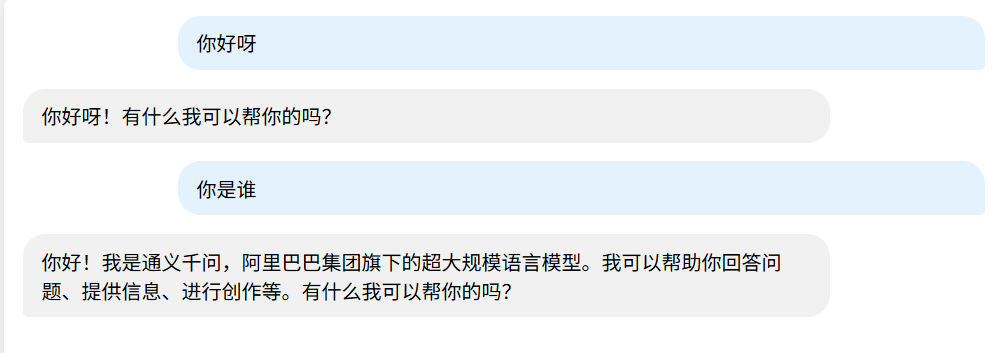
引入外部文本系统提示词
在resource目录下创建system.txt文件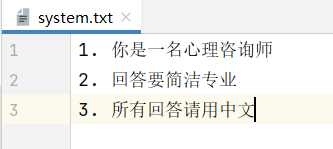
使用system.txt文件
@SystemMessage(fromResource = "system.txt") //提供文本设置
public Flux<String> chat(String mes);
动态变量({{variable}} 语法)
如果不使用@V注解的话,默认就是{{it}}
@UserMessage("1.友好且专业的语气回答2.简短回答,{{mes}}") //协助用户设置词条
public Flux<String> chat(@V("mes") String mes);
会话记忆
在 LangChain4j 中,会话记忆(Conversation Memory)是指 AI 能够记住之前的对话内容,从而实现多轮对话的上下文感知能力。
ChatMemory接口介绍
配置会话记忆对象提供者
@Configuration
public class ComponentConfig
{
@Bean
public ChatMemory chatMemory()
{
return MessageWindowChatMemory.builder()
.maxMessages(5) // 保留最近5条消息
.build(); //构建
}
}
@AiService添加参数chatMemory
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, //手动装配
chatModel = "openAiChatModel", //阻塞 指定模型
streamingChatModel = "openAiStreamingChatModel", //流式 指定模型
chatMemory = "chatMemory" //指定消息记忆
)
会话记忆隔离
如果不实现会话隔离,所有人使用的会话记忆是共用的
核心隔离机制@MemoryId 会话隔离,最基础的隔离方式,为每个对话会话分配唯一ID
配置会话记忆对象提供者
@Bean
public ChatMemoryProvider chatMemoryProvider()
{
return new ChatMemoryProvider() {
@Override
public ChatMemory get(Object o) { //这个o就是消息ID唯一标识
return MessageWindowChatMemory.builder()
.id(o) //唯一标识
.maxMessages(5)
.build();
}
};
}
ConsultantService修改
@AiService添加参数
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, //手动装配
chatModel = "openAiChatModel", //阻塞 指定模型
streamingChatModel = "openAiStreamingChatModel", //流式 指定模型
chatMemoryProvider = "chatMemoryProvider"
)
为chat方法添加@MemoryId注解,在默认只有一个参数mes的情况下可以不添加@UserMessage
@SystemMessage(fromResource = "system.txt") //提供文本设置
public Flux<String> chat(@MemoryId String memoryId,@UserMessage String mes);
controller修改
@RestController
public class ChatController
{
@Autowired
private ConsultantService consultantService;
@GetMapping(value = "chat",produces = "text/html;charset=utf-8") //produces设置字符集
public Flux<String> chat(@RequestParam String memoryId,@RequestParam String mes)
{
Flux<String> chat = consultantService.chat(memoryId,mes);
return chat;
}
}
会话记忆持久化
如果我们重启了服务器,之前和用户会话记忆全部都会消失,因为会话记忆全部都在服务器内存当中,没有保存,可以将数据存储在mysql中或其它地方
使用了mybatis-plus
配置mysql
sql表,存储会话历史消息
CREATE TABLE `messages` (
`id` int NOT NULL AUTO_INCREMENT,
`memory_id` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`json_text` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2076209155 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
yml配置
spring:
datasource:
type: com.mysql.cj.jdbc.MysqlDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/ai_demo
username: root
password: 123
提供ChatMemoryStore接口的实现类
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.ChatMessageDeserializer;
import dev.langchain4j.data.message.ChatMessageSerializer;
import dev.langchain4j.store.memory.chat.ChatMemoryStore;
import org.example.pojo.Messages;
import org.example.service.MessagesService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public class MysqlChatMemoryStore implements ChatMemoryStore
{
@Autowired
MessagesService messagesService;
/**
* @param o 为 memoryId
* @return
*/
@Override
public List<ChatMessage> getMessages(Object o) {
//获取
QueryWrapper qw = new QueryWrapper<>();
qw.eq("memory_id",o);
Messages one = messagesService.getOne(qw);
List<ChatMessage> chatMessages = List.of();
if(one != null)
chatMessages = ChatMessageDeserializer.messagesFromJson(one.getJsonText());
return chatMessages;
}
@Override
public void updateMessages(Object o, List<ChatMessage> list)
{
//更新会话消息
//把list数据转换为json数据
String s = ChatMessageSerializer.messagesToJson(list);
//把json数据存储到mysql中
Messages messages = new Messages();
messages.setMemoryId(o.toString());
messages.setJsonText(s);
QueryWrapper qw = new QueryWrapper<>();
qw.eq("memory_id",o);
messagesService.saveOrUpdate(messages,qw);
}
@Override
public void deleteMessages(Object o) {
QueryWrapper qw = new QueryWrapper<>();
qw.eq("memory_id",o);
messagesService.remove(qw);
}
}
配置ChatMemoryStore接口的实现类
@Configuration
public class ComponentConfig
{
@Autowired
MysqlChatMemoryStore mysqlChatMemoryStore;
@Bean
public ChatMemoryProvider chatMemoryProvider()
{
return new ChatMemoryProvider() {
@Override
public ChatMemory get(Object o) { //这个o就是消息ID唯一标识
return MessageWindowChatMemory.builder()
.id(o) //唯一标识
.maxMessages(5)
.chatMemoryStore(mysqlChatMemoryStore) //配置提供ChatMemoryStore接口
.build();
}
};
}
}
RAG(检索增强生成)知识库
RAG(Retrieval-Augmented Generation)是一种结合信息检索与文本生成的技术架构,广泛应用于问答系统、对话机器人和知识密集型任务中。下面我将全面介绍RAG知识库的核心概念、技术实现和最佳实践。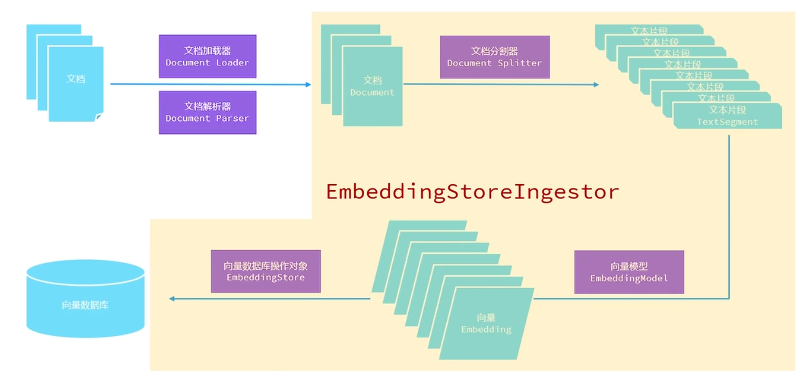
快速入门
引入依赖
<!-- RAG-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.0.1-beta6</version>
</dependency>
创建知识文档
创建md类型文件,其它的文件也行
里面是一些近几年的高考数据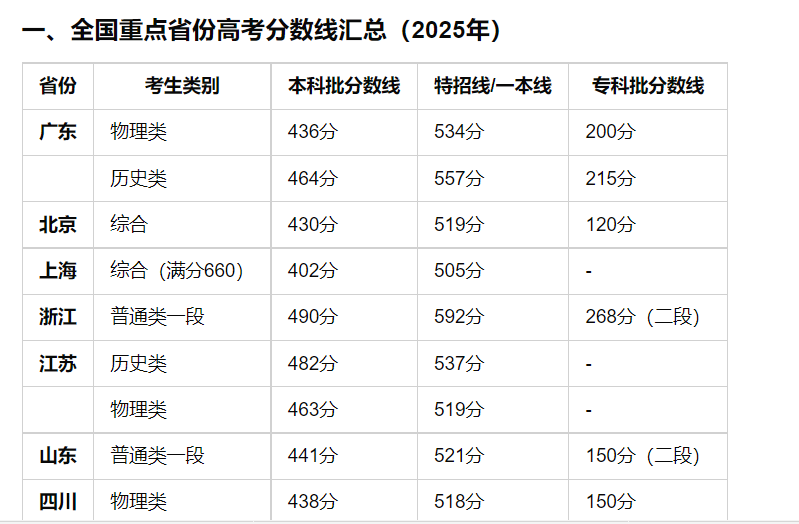
构建向量数据库操作对象
//构建向量数据库操作对象
@Bean
public EmbeddingStore store()
{
//加载文档中的内容进入内存
List<Document> text = ClassPathDocumentLoader.loadDocuments("text");
//构建向量数据库操作对象
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
//构建一个EmbeddingStoreIngestor对象 完成数据切割、向量化、存储
EmbeddingStoreIngestor build = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.build();
build.ingest(text);
return store;
}
构建向量数据库检索对象
//构建向量数据库检索对象
@Bean
public ContentRetriever contentRetriever(EmbeddingStore store)
{
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.maxResults(3) //最大数据
.minScore(0.6) //相似度
.build();
}
@AiService注解添加contentRetriever配置
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, //手动装配
chatModel = "openAiChatModel", //阻塞 指定模型
streamingChatModel = "openAiStreamingChatModel", //流式 指定模型
chatMemoryProvider = "chatMemoryProvider",
contentRetriever = "contentRetriever" //配置向量数据库检索对象
)
RAG核心API
文档加载器
1. 文件系统加载器
FileSystemDocumentLoader - 加载本地系统中的文档
List<Document> text = FileSystemDocumentLoader.loadDocuments("C:\\Users\\Xiri\\Desktop\\Learn_LangChain4j\\LangChain-RAG\\src\\main\\resources\\text");
2.类路径(classpath)加载文档
指定类路径下的文件路径(相对 resources 目录的路径)
List<Document> text = ClassPathDocumentLoader.loadDocuments("text");
3. URL 加载器(网络加载)
//网络链接加载
//湖北省2025年普通高校招生录取控制分数线 网址
Document text = UrlDocumentLoader.load("https://jyt.hubei.gov.cn/zfxxgk/zc_GK2020/qtzdgkwj_GK2020/202506/t20250626_5706550.shtml", new ApacheTikaDocumentParser());
ApacheTikaDocumentParser文本解析器(几乎解析所有格式文档)
询问:湖北省2025年普通高校招生录取控制分数线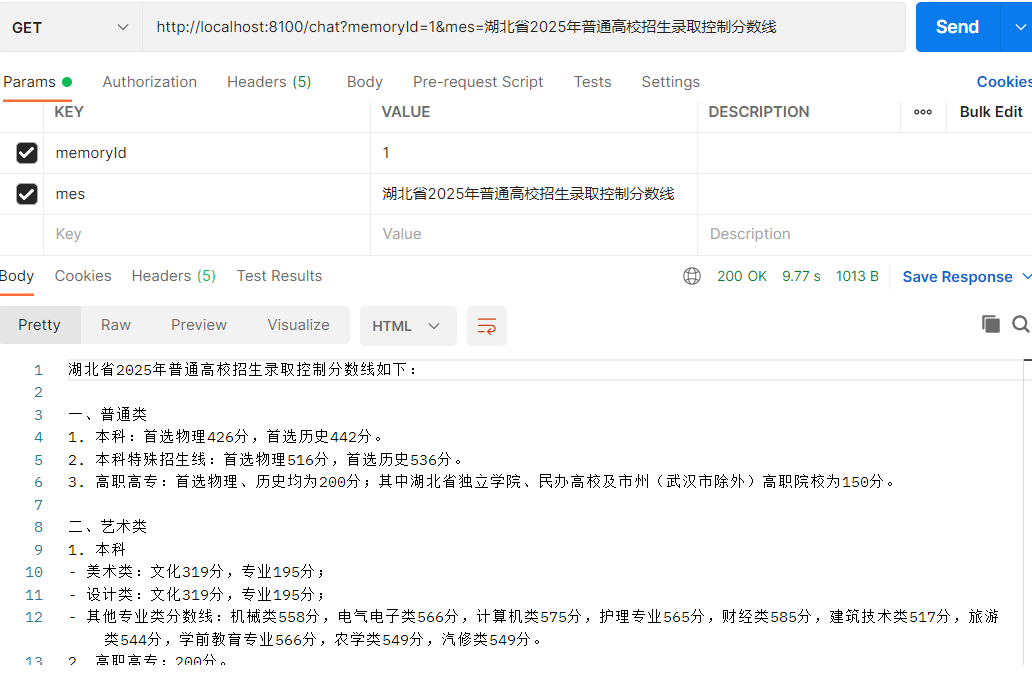
和官网对比
文档解析器
1.默认解析器
ApacheTikaDocumentParser可以解析大部分文件
new ApacheTikaDocumentParser()
2.文本解析器
new TextDocumentParser();
3.PDF文件解析器
引入依赖
<!--pdf解析器-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
<version>1.0.1-beta6</version>
</dependency>
使用ApachePdfBoxDocumentParser解析器
Document text = FileSystemDocumentLoader.loadDocument("C:\\Users\\Xiri\\Desktop\\Learn_LangChain4j\\LangChain-RAG\\src\\main\\resources\\text\\2025hbgk.pdf",new ApachePdfBoxDocumentParser());
4.办公文档解析器
<!--处理办公文档等解析器-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-poi</artifactId>
<version>1.0.1-beta6</version>
</dependency>
ApachePoiDocumentParser解析器
new ApachePoiDocumentParser()
使用解析器
使用ApachePdfBoxDocumentParser解析器
//构建向量数据库操作对象
@Bean
public EmbeddingStore store() //名字配置为store,如果配置名为embeddingStore会重名,有一个默认的
{
//使用解析器
Document text = FileSystemDocumentLoader.loadDocument("C:\\Users\\Xiri\\Desktop\\Learn_LangChain4j\\LangChain-RAG\\src\\main\\resources\\text\\2025hbgk.pdf",new ApachePdfBoxDocumentParser());
//构建向量数据库操作对象
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
//构建一个EmbeddingStoreIngestor对象 完成数据切割、向量化、存储
EmbeddingStoreIngestor build = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.build();
build.ingest(text); //设置文本
return store;
}
文档分割器

默认使用DocumentSplitters.recursive()DocumentSplitters.recursive() 是 LangChain4j 提供的递归文档分割器的核心 API,用于将长文档智能拆分为语义连贯的文本片段
构建文本分割器对象
//构建文档分割器对象
DocumentSplitter recursive = DocumentSplitters.recursive(
500,//每个片段最大能容纳的字符
100//两个片段之间重叠字符个数
);
设置文本分割器对象
@Bean
public EmbeddingStore store() //名字配置为store,如果配置名为embeddingStore会重名,有一个默认的
{
Document text = FileSystemDocumentLoader.loadDocument("C:\\Users\\Xiri\\Desktop\\Learn_LangChain4j\\LangChain-RAG\\src\\main\\resources\\text\\2025hbgk.pdf",new ApachePdfBoxDocumentParser());
//构建文档分割器对象
DocumentSplitter recursive = DocumentSplitters.recursive(
500,//每个片段最大能容纳的字符
100//两个片段之间重叠字符个数
);
//构建向量数据库操作对象
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
//构建一个EmbeddingStoreIngestor对象 完成数据切割、向量化、存储
EmbeddingStoreIngestor build = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.documentSplitter(recursive)//设置文档分割器
.build();
build.ingest(text); //设置文本
return store;
}
关键参数documentSplitter配置
向量模型
向量模型将数据(如单词、句子、文档)映射到高维向量空间,每个维度代表数据的某种特征(如词频、语义等)。相似的数据在向量空间中距离较近,反之则较远
例如:
“猫”的向量可能是 [0.8, 0.2, 0.6],而“狗”的向量是 [0.7, 0.3, 0.5],两者余弦相似度高;
“桌子”的向量可能是 [0.1, 0.9, 0.0],与“猫”差异显著。
余弦相似度:
最常用的相似度计算方法,通过向量夹角余弦值衡量相关性(范围:0~1)
配置向量模型
找一个文本向量模型使用,并且配置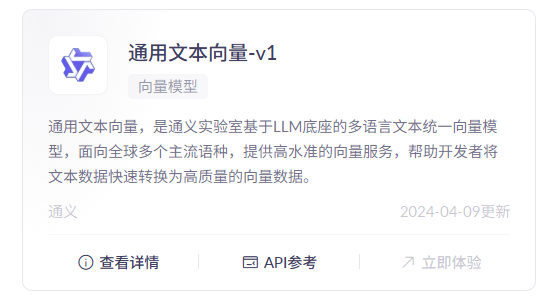
#配置langchain4j
langchain4j:
open-ai:
embedding-model: #向量模型
api-key: ${API-KEY} #使用环境变量配置
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 #基地址
model-name: text-embedding-v1 #文本向量模型
log-requests: true #请求
log-responses: true #响应
设置向量模型
@Autowired
EmbeddingModel embeddingModel;
//构建向量数据库操作对象
@Bean
public EmbeddingStore store() //名字配置为store,如果配置名为embeddingStore会重名,有一个默认的
{
Document text = FileSystemDocumentLoader.loadDocument("C:\\Users\\Xiri\\Desktop\\Learn_LangChain4j\\LangChain-RAG\\src\\main\\resources\\text\\2025hbgk.pdf",new ApachePdfBoxDocumentParser());
//构建文档分割器对象
DocumentSplitter recursive = DocumentSplitters.recursive(
500,//每个片段最大能容纳的字符
100//两个片段之间重叠字符个数
);
//构建向量数据库操作对象
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
//构建一个EmbeddingStoreIngestor对象 完成数据切割、向量化、存储
EmbeddingStoreIngestor build = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.documentSplitter(recursive)//设置文档分割器
.embeddingModel(embeddingModel) //设置向量模型
.build();
build.ingest(text); //文本
return store;
}
//构建向量数据库检索对象
@Bean
public ContentRetriever contentRetriever(EmbeddingStore store)
{
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.maxResults(3) //最大数据
.minScore(0.6) //相似度
.embeddingModel(embeddingModel) //设置向量模型
.build();
}
存储和检索都使用向量模型:
设置EmbeddingStoreIngestor和EmbeddingStoreContentRetriever的embeddingModel方法
运行
看到向量数据就代表成功了
向量数据库
之前向量数据库都是放在内存上了,服务器关机就没有了,使用Chroma持久化
运行Chroma
使用Chroma:0.4.20
运行Chroma
引入依赖
<!-- 向量数据库-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-chroma</artifactId>
<version>1.0.1-beta6</version>
</dependency>
创建Bean
//构建Chroma向量数据库
@Bean
public ChromaEmbeddingStore chromaEmbeddingStore()
{
return ChromaEmbeddingStore.builder()
.baseUrl("http://localhost:8000") // Chroma 服务地址
.collectionName("my-collection") // 向量集合名称
.logRequests(true) //请求日志
.logResponses(true) //响应日志
.build();
}
配置
//构建一个EmbeddingStoreIngestor对象 完成数据切割、向量化、存储
EmbeddingStoreIngestor build = EmbeddingStoreIngestor.builder()
.embeddingStore(chromaEmbeddingStore())
.documentSplitter(recursive)//设置文档分割器
.embeddingModel(embeddingModel) //设置向量模型
.build();
build.ingest(text);
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(chromaEmbeddingStore())
.maxResults(3) //最大数据
.minScore(0.6) //相似度
.embeddingModel(embeddingModel) //设置向量模型
.build();
配置EmbeddingStoreIngestor和EmbeddingStoreContentRetriever embeddingStore方法为之前创建的Bean:chromaEmbeddingStore()
结果

补充:只有第一次加载的时候需要完成数据切割、向量化、存储,之后不需要,可以将store方法的bean注释掉
Tools工具
创建工具方法
import dev.langchain4j.agent.tool.P;
import dev.langchain4j.agent.tool.Tool;
import org.springframework.stereotype.Component;
@Component
public class AiTool
{
@Tool("预约高考志愿填报信息服务")
public void addData(
@P("姓名") String name,
@P("性别") String sex,
@P("手机号") String phone
)
{
System.err.println("姓名:"+name+" 性别:"+sex+" 手机号:"+phone);
}
@Tool("取消预约高考志愿填报")
public void cancel()
{
System.err.println("已取消预约");
}
}
配置工具方法
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, //手动装配
chatModel = "openAiChatModel", //阻塞 指定模型
streamingChatModel = "openAiStreamingChatModel", //流式 指定模型
chatMemoryProvider = "chatMemoryProvider",
contentRetriever = "contentRetriever" //配置向量数据库检索对象
,
tools = "aiTool" //配置AI工具类,使用名字注入
)
给@AiService注解的tools属性配置以上创建的工具方法
效果
查看2025年高考分数线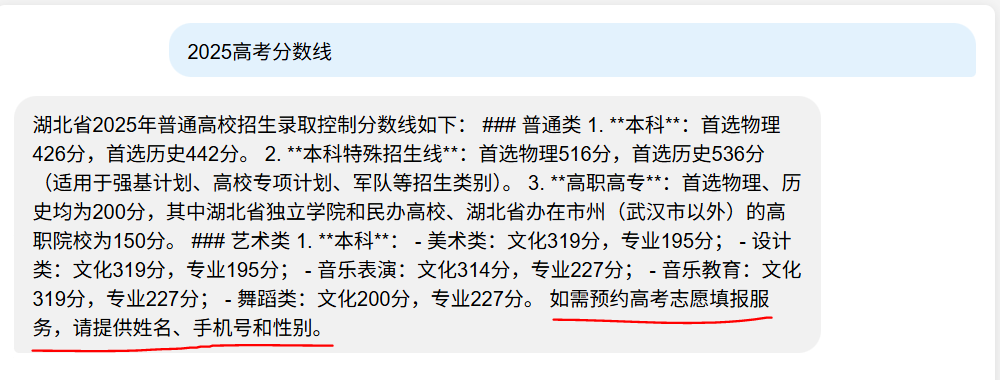
给他提供用户信息帮忙预约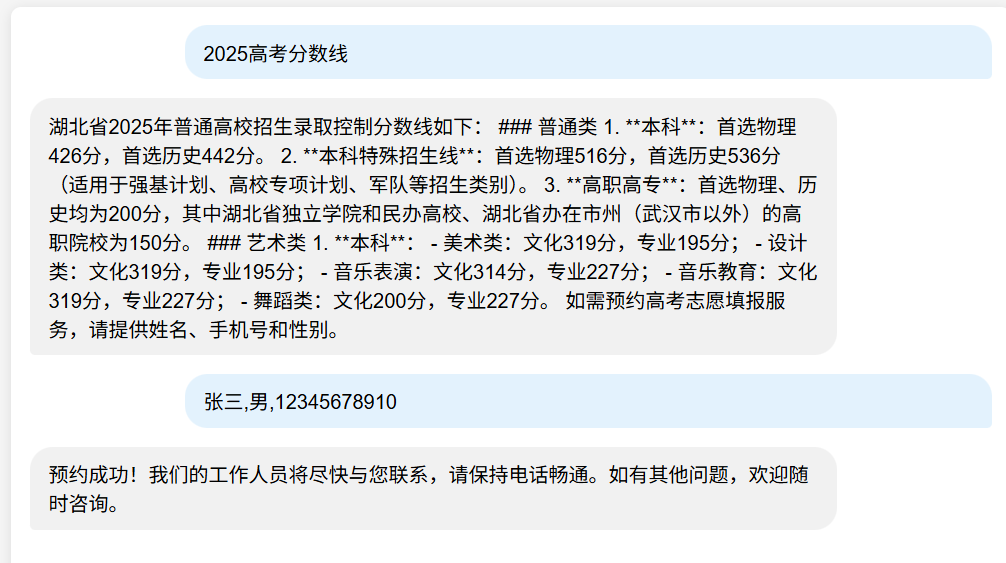
预约成功后发现ai调用了addData方法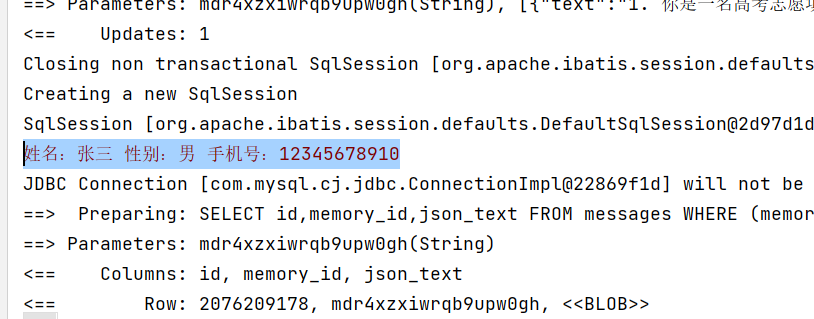

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 55
55 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)