上海交大:LLM知识编辑强化学习框架
如何在大语言模型(LLM)中实现有效的知识编辑,同时保持推理的真实性和完整性?论文提出了Reason-KE++框架,通过阶段感知奖励机制在知识编辑过程中强化推理过程的可信度,进而提高模型在多跳问答任务中的表现。
📖标题:Reason-KE++: Aligning the Process, Not Just the Outcome, for Faithful LLM Knowledge Editing
🌐来源:arXiv, 2511.12661
🌟摘要
对齐大型语言模型 (LLM) 以忠实于复杂多跳推理任务中的新知识是一项关键但尚未解决的挑战。我们发现基于 SFT 的方法,例如 Reason-KE (Wu et al., 2025b),虽然最先进的技术存在“忠实差距”:它们针对格式模仿而不是声音推理进行了优化。这一差距使LLM强大的参数先验能够覆盖新的上下文事实,从而产生关键的事实幻觉(例如,尽管显式编辑,但从“NASA”错误地推理“Houston”)。为了解决这个核心LLM对齐问题,我们提出了Reason-KE++,这是一个SFT+RL框架,它灌输了过程级别的忠实度。它的核心是一种阶段感知的奖励机制,它为中间推理步骤(例如分解、子答案正确性)提供密集监督。至关重要的是,我们发现幼稚的仅结果 RL 是 LLM 对齐的欺骗性陷阱:它折叠推理完整性(例如,19.00% Hop acc),同时表面上提高了最终的准确性。我们的过程感知框架在 MQUAKE-CF3k (+5.28%) 上设置了 95.48% 的新 SOTA,这表明对于复杂的任务,对齐推理过程对于构建值得信任的 LLM 至关重要。我们的代码将在以下网址获得:https://github.com/YukinoshitaKaren/Reason-KE。
🛎️文章简介
🔸研究问题:如何在大语言模型(LLM)中实现有效的知识编辑,同时保持推理的真实性和完整性?
🔸主要贡献:论文提出了Reason-KE++框架,通过阶段感知奖励机制在知识编辑过程中强化推理过程的可信度,进而提高模型在多跳问答任务中的表现。
📝重点思路
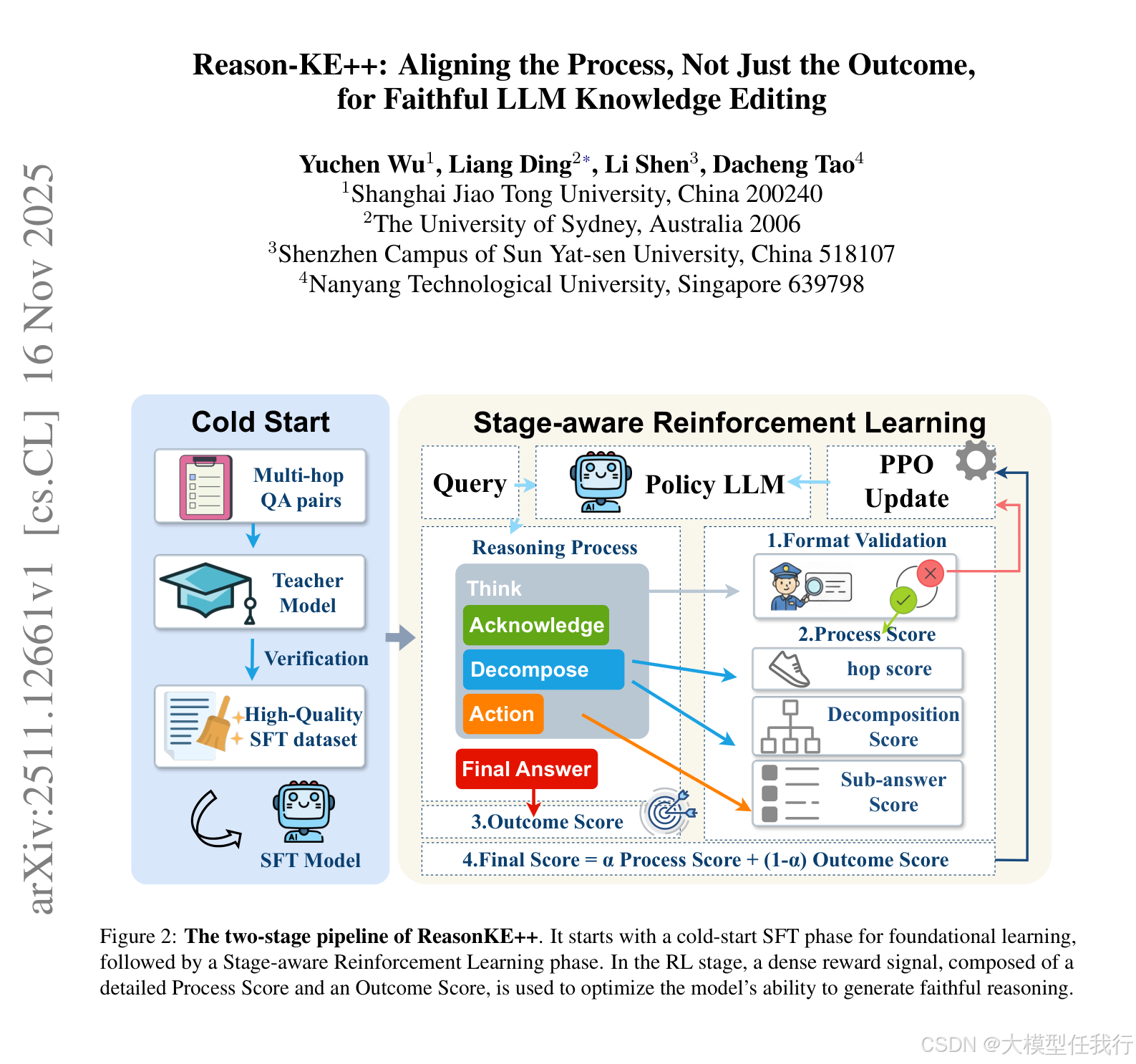
🔸提出Reason-KE++,一个两阶段的框架,包括冷启动的监督微调(SFT)和后续的强化学习(RL)阶段,旨在教会LLM基本的推理模式。
🔸设计阶段感知奖励机制,分解复杂的推理过程为多个可评估的阶段,提供逐步的监督反馈,确保推理过程的精准。
🔸在训练过程中使用PPO算法,以优化模型在整个推理链中的表现,而不仅仅是最终结果。
🔸使用结构化的提示模板和规范化的格式验证,以促进模型生成有条理的推理步骤并减少格式错误。
🔎分析总结
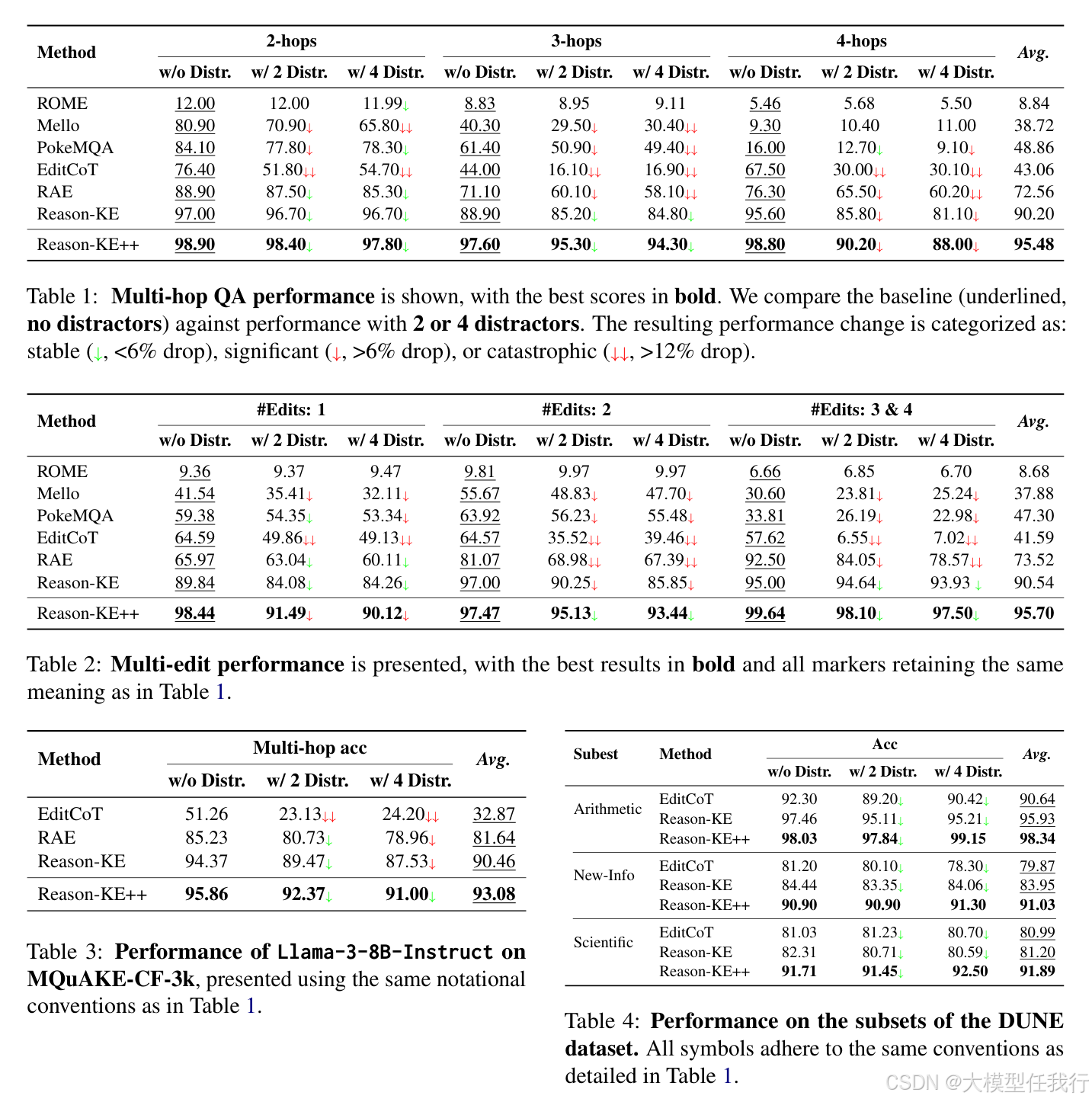
🔸Reason-KE++在多个知识编辑基准上表现卓越,实现了95.48%的多跳问答准确率,较之前的方法提高了5.28%。
🔸通过实验表明,标准的结果导向的强化学习是“欺骗性陷阱”,它可能导致推理完整性崩溃,而Reason-KE++则通过多维的反馈机制有效避免了这一问题。
🔸论文的结果显示,Reason-KE++显著增强了模型在面对干扰信息时的鲁棒性,即使在引入严重的干扰时,性能下降也仅为5.06%。
🔸确立了通过监督处理整个推理过程而非仅关注结果对于构建高效可信的推理模型的重要性。
💡个人观点
论文提出了阶段感知奖励机制,不仅关注模型的最终回答,还强调推理过程的每一个步骤。
🧩附录

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献305条内容
已为社区贡献305条内容

所有评论(0)