【ICLR26匿名投稿】FuseAgent:让AI学会“看图融合”的视觉智能体
图像融合(Image Fusion)是自动驾驶、遥感、计算摄影等核心任务之一, 旨在将来自不同传感器或不同曝光条件的多张图像融合成一张视觉上最优的结果。同时,FuseAgent 在视觉效果上显著减少鬼影(ghosting)和结构畸变(distortion), 输出结果更清晰、自然、层次感更强。🔄 IQR 关注“图像自身是否好看”, RQR 关注“融合结果是否合理”, 二者结合,让智能体既追求质量
文章:FuseAgent: A VLM-driven Agent for Unified In-the-Wild Image Fusion
代码:暂无
单位:暂无
一、问题背景|Image Fusion 的“野外困境”
图像融合(Image Fusion)是自动驾驶、遥感、计算摄影等核心任务之一, 旨在将来自不同传感器或不同曝光条件的多张图像融合成一张视觉上最优的结果。
然而,在真实场景(in-the-wild)中,这一任务面临三大挑战:
-
🌫️ 复杂退化耦合(Coupled Degradations):现实图像往往同时存在低照度、模糊、对齐误差、动态伪影等多重问题;
-
🧩 固定管线脆弱(Static Pipelines):传统模型使用固定处理顺序(如去噪→配准→融合),对不同场景泛化性差;
-
🧠 缺乏智能决策能力(Lack of Adaptive Reasoning):现有All-in-One模型无法根据输入图像自动规划最优的融合策略。
换言之,以往的模型“只会算”,不会“思考”。 而 FuseAgent 试图让 AI 学会像人类专家一样“看、想、做”。

二、方法创新|Agentic Vision Fusion 框架
FuseAgent 是首个基于 Vision-Language Model (VLM) 的智能图像融合代理(Agent), 可自动感知输入图像的退化类型,规划最优工具链并执行融合操作。
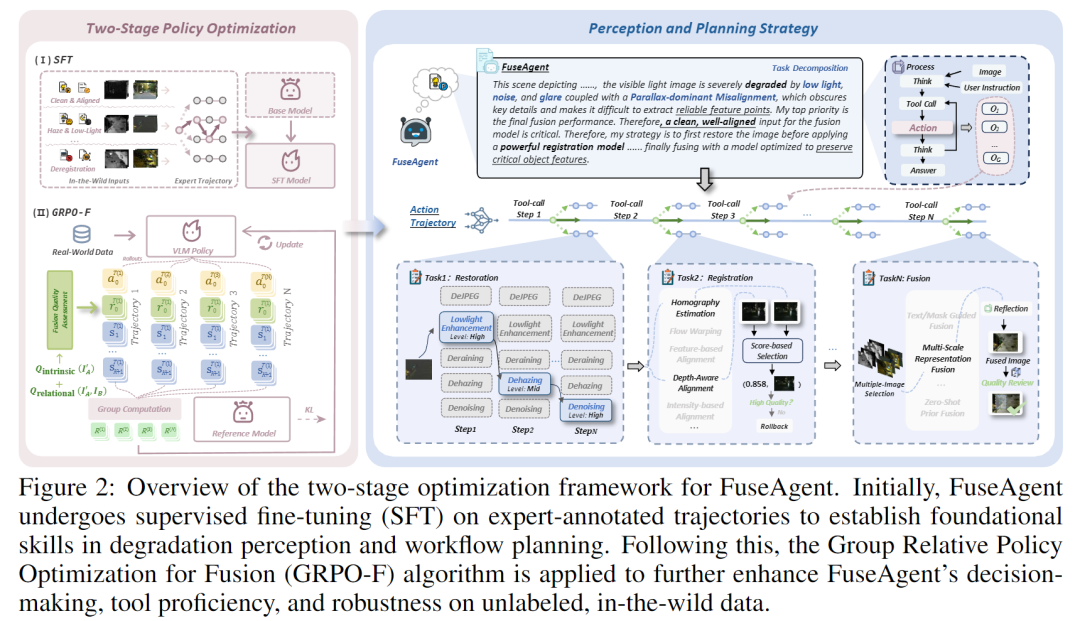
其核心创新体现在三大部分:
🧠 (1) 智能体核心:VLM-Driven Controller
-
以 Qwen2.5-VL-7B 作为基础控制器,赋予模型视觉感知与推理能力;
-
通过视觉分析 + 动态规划 + 工具调用三步走流程,实现端到端智能决策:
-
感知退化类型(degradation perception);
-
推理最优任务序列(reasoning & planning);
-
动态调用专家模型(expert orchestration)。
⚙️ (2) 两阶段训练:SFT + GRPO-F
FuseAgent 的训练分为两个阶段:
① Supervised Fine-Tuning (SFT)
-
利用专家标注的推理轨迹(Expert Trajectories)进行有监督学习;
-
模拟专家思维,学习退化识别与工具使用的基础技能。
② Group Relative Policy Optimization for Fusion (GRPO-F)
-
无监督强化学习阶段,基于自设计的多维奖励信号优化策略;
-
奖励函数由两部分组成:
-
-
Intrinsic Quality Reward (IQR):衡量输出图像的感知质量;
-
Relational Quality Reward (RQR):度量输入图像间融合兼容性。
-
🔄 IQR 关注“图像自身是否好看”, RQR 关注“融合结果是否合理”, 二者结合,让智能体既追求质量,又追求一致性。
🧩 (3) Data Pipeline:合成 + 实景混合
为了训练智能体具备真实世界鲁棒性,团队构建了一个包含 43,000 对图像 的混合数据集,涵盖三类任务:
-
IVIF(红外–可见光融合)
-
MEF(多曝光融合)
-
MFF(多焦点融合)
并利用退化合成库生成复杂“多缺陷”场景,如低光+模糊+错位+雨雾叠加的极端情况。
三、实验结果|让AI在“野外”自我决策
FuseAgent 在 决策能力 与 融合质量 两方面全面领先。
🧭 (1) 智能决策评估
|
策略类型 |
HyperIQA↑ |
MUSIQ↑ |
CLIPIQA↑ |
|---|---|---|---|
|
Zero-shot VLM Planner |
0.6030 |
61.98 |
0.516 |
|
Human Expert |
0.6640 |
66.07 |
0.555 |
| FuseAgent (Ours) | 0.6769 | 68.23 | 0.591 |
FuseAgent 超越人类专家设计的固定管线,实现了真正的自适应智能融合。
🧪 (2) 多任务融合结果
|
任务类型 |
SOTA方法 |
FuseAgent |
提升 |
|---|---|---|---|
|
IVIF |
0.48 → 0.63 (HyperIQA) |
+31% |
|
|
MEF |
0.59 → 0.71 |
+20% |
|
|
MFF |
0.49 → 0.69 |
+40% |
同时,FuseAgent 在视觉效果上显著减少鬼影(ghosting)和结构畸变(distortion), 输出结果更清晰、自然、层次感更强。
四、优势与局限|Pros & Cons
✅ 优势
-
🤖 自主决策能力:能感知退化并动态规划最佳工具链;
-
🧩 多模态协同:融合 VLM 推理与低层视觉任务;
-
🔁 通用性强:可迁移至去噪、去雾、超分辨等多种视觉任务;
-
🚀 显著性能提升:在无监督条件下超越人类专家与SOTA模型。
⚠️ 局限
-
训练成本高(需多GPU + 长时间RL训练);
-
对极端未见退化仍可能出现误判;
-
工具库规模限制模型可操作空间。
🧭 一句话总结
FuseAgent 让图像融合从“静态算法”迈向“智能体时代”, 通过VLM驱动的决策与强化学习,让AI学会在复杂真实场景中自主思考与执行融合策略。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)