Spring AI Advisor类源码学习笔记 [更新至1.0.0-M6]
本文章对Spring AI的Advisor类进行源码讲解,截至目前,官方文档已更新至1.0.0-M6版本,官方的release版本也有望于今年发布。本文章基于M6版本的源码进行本人学习时的笔记记录。认识和了解Spring AI的Advisors机制非常重要且是首要的,他是Spring AI在Prompt工程里非常关键的增强实现技术Advisors和AOP的思想类似,其功能是面向切面(提示词)对应用
前言
本文章对Spring AI的Advisor类进行源码讲解,截至目前,官方文档已更新至1.0.0-M6版本,官方的release版本也有望于今年发布。本文章基于M6版本的源码进行本人学习时的笔记记录。
认识和了解Spring AI的Advisors机制非常重要且是首要的,他是Spring AI在Prompt工程里非常关键的增强实现技术
Advisors和AOP的思想类似,其功能是面向切面(提示词)对应用程序(请求/响应体)进行增强;在请求的流程中,Advisor以链式结构维持执行顺序,各个Advisor都有可能对该次请求响应进行处理。
介绍
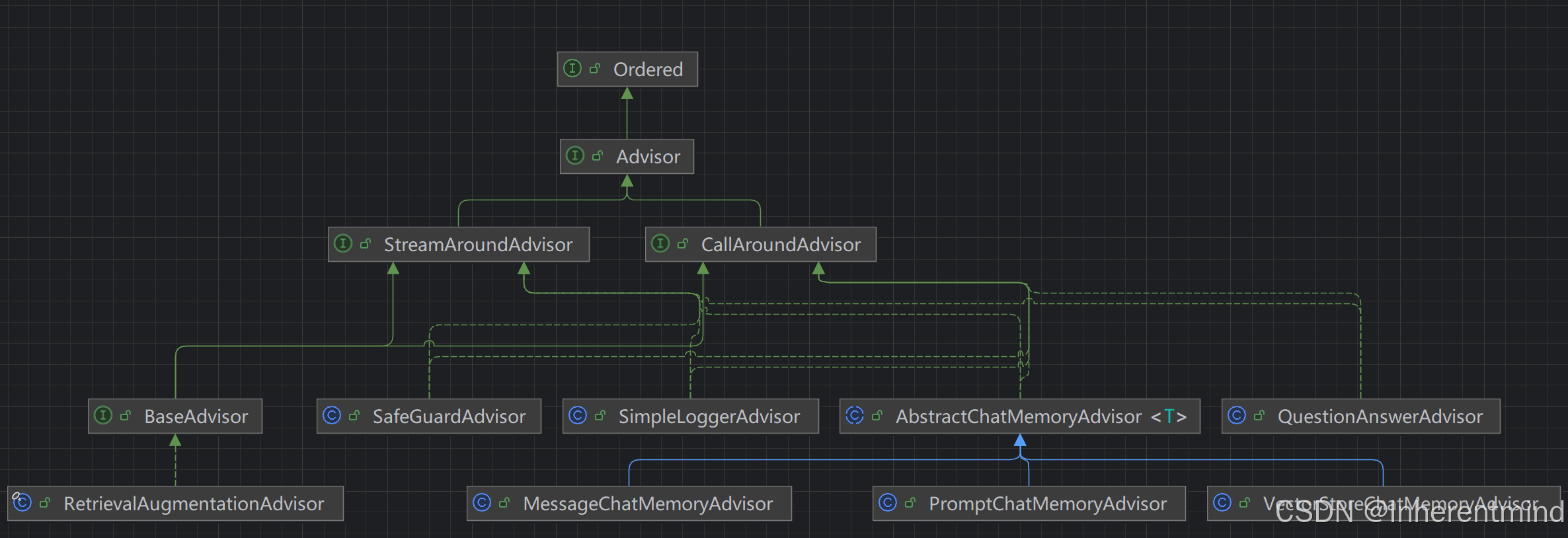
本章将包含以下类的讲解,以及官方提供的类实现继承树图如下[1.0.0-M6] (右下角被挡住的类名为VectorStoreChatMemoryAdvisor)
Advisor工作流程
官方提供的Advisors工作流程图如下
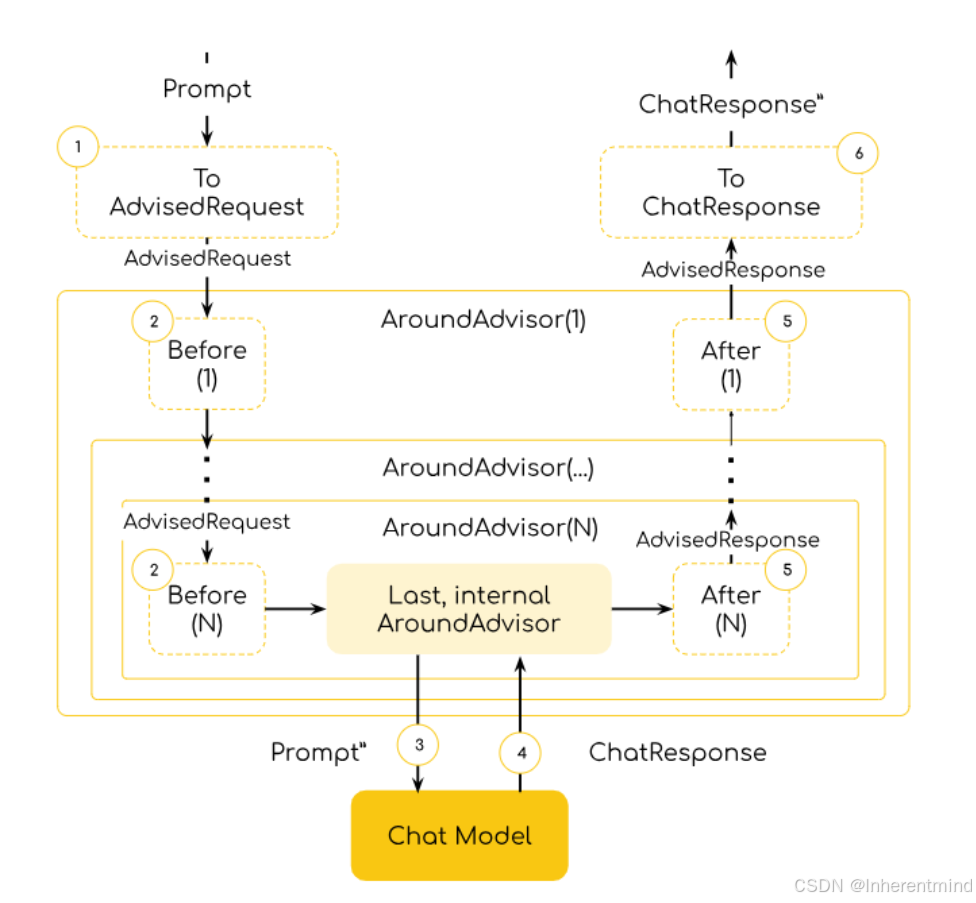
可以看出,Advisor机制的核心参与者是AroundAdvisor,每个Advisor会在请求流抵达时,对请求进行处理并转发给链中的下一个Advisor,在抵达了原子性组件即Chat Model(就是封装了LLM通信响应能力的类)并得到响应后,将会沿着链路原路返回(通过递归调用实现),最终返回一个AdvisedResponse(增强后的响应)交给客户端。
Advisor实现类
接着我们来看RequestResponseAdvisor 【自1.0.0-M6版本起正式弃用】 Advisor及其所有实现类
Advisor
在M5版本之后,RequestResponseAdvisor正式弃用(废除),而是抽成了更为泛用的Advisor,在此之上又有不同的实现。
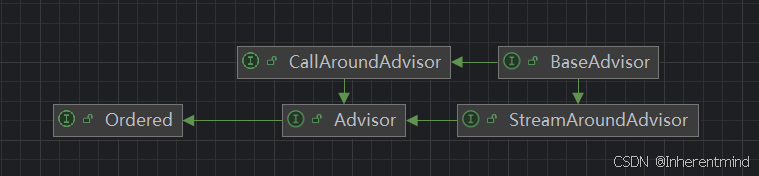
Advisor实现自Ordered接口,便于自定义编排Advisor的执行优先级。
在Advisor类中,设置了一个默认的优先级值(默认聊天记忆类Advisor优先级)为最小整数值(默认最后执行);
从Advisor又实现了两个接口,分别为CallAroundAdvisor和StreamAroundAdvisor,其在AroundAdvisor链上返回的响应类型为AdvisedResponse和Flux<AdvisedResponse>
CallAroundAdvisor & StreamAroundAdvisor
Advisor在AdvisorChain上返回类型的约束接口,其只包含aroundCall/aroundStream方法及返回类型的声明(AdvisedResponse和Flux<AdvisedResponse>)。
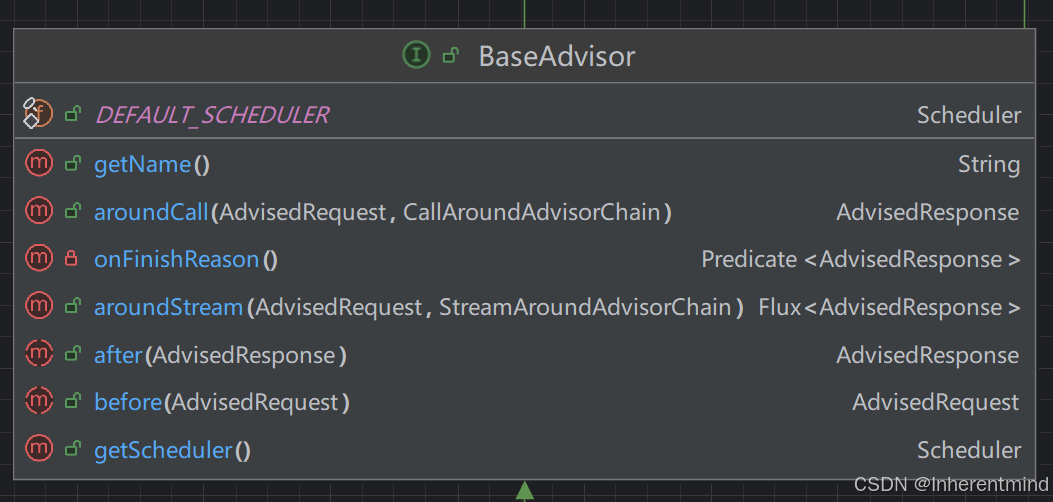
BaseAdvisor
官方定义了一个扩展接口也就是BaseAdvisor,提供了aroundCall和aroundStream的默认实现,也就是Advisor的执行顺序实现(包括aroundStream的线程调度Scheduler),使你只需要关注before和after的处理逻辑的实现即可。
AbstractChatMemoryAdvisor<T>
嵌入对话历史记录的Advisor,此类AroundAdvisor一般在before环节对提示词进行增强。此处的泛型T是成员变量chatMemoryStore的类型,看完后文可以发现其支持VectorStore和chatMemory接口,或者你自己实现的话,可以添加其他类作为历史记录的仓储服务。
成员变量
-
CHAT_MEMORY_CONVERSATION_ID_KEY
对话记录的id,用于advisor与chatMemoryStore交互查询历史记录
-
CHAT_MEMORY_RETRIEVE_SIZE_KEY
历史记录的最大条数,限制此整型数值可以一定程度上限制上下文的token数
-
chatMemoryStore
Advisor与历史记录的交互组件,advisor通过与该组件交互获得历史记录列表
-
DEFAULT_CHAT_MEMORY_RESPONSE_SIZE
默认的对话历史检索大小
-
protectFromMemoryBlocking [默认值为true]判断是否启用线程模型保护的布尔变量,在使用Reactor编程模型时,当该Advisor中涉及阻塞IO时(如JDBC),会将后续操作切换到弹性调度器线程池执行,防止阻塞操作影响响应式流的非阻塞线程
protected Flux<AdvisedResponse> doNextWithProtectFromBlockingBefore(...) { return this.protectFromBlocking ? Mono.just(advisedRequest) .publishOn(Schedulers.boundedElastic()) // 切换线程池 .map(beforeAdvise) .flatMapMany(request -> chain.nextAroundStream(request)) : chain.nextAroundStream(beforeAdvise.apply(advisedRequest)); // 直接执行 }
方法
-
getChatMemoryStore : 对继承类提供的chatMemory的getter
-
doGetConversationId :从上下文中获取会话ID
-
doGetChatMemoryRetrieveSize : 从上下文中获取检索到的历史记录的大小
继承类
聊天历史的Advisor中,Spring AI官方提供了以下三种实现(截至1.0.0M6),区别在于chatMemoryStore的类型不同,以及Advisor与chatMemoryStore的交互方式不同
VectorStoreChatMemoryAdvisor
成员变量
VectorStore:用于存储和检索对话记忆的向量数据库
systemTextAdivse:包含{longtermmemory}占位符的系统提示模板
messageType:标识处理信息的类型(用户、助手、工具)
方法
-
aroundCall:接收一个AdvisedRequest以及CallAroundAdvisorChain,执行自身的before方法后,调用链上下一个advisor;
-
⭐ before:接收AdvisedRequest,将请求中的SystemText拿出来后,添加上历史记忆的提示词,然后从向量库内检索相关的记忆,并将记忆注入系统参数(前面的占位符);最后保存当前用户信息到向量库内;
-
⭐ observeAfter:链路返回到当前Advisor时的函数,也就是将Aide回复保存到向量库当中。
总地来看,和官方给出的流程图一样,AroundAdvisor在整个过程中共执行两次,分别是在用户请求之前[before],插入历史记录到Prompt中;第二次是在响应回到该Advisor时[after],将助手回复的内容保存到向量库中。
MessageChatMemoryAdvisor
了解过向量库的Advisor后,其他的ChatMemoryAdvisor逻辑基本一致。
方法
- ⭐ before:该Advisor中,不是通过构建提示词的方式嵌入历史记录,而是利用AdvisedRequest的请求参数直接添加消息对象列表messages。
private AdvisedRequest before(AdvisedRequest request) {
//从上下文获取会话ID
String conversationId = this.doGetConversationId(request.adviseContext());
//从上下文获取历史记录限制数量
int chatMemoryRetrieveSize = this.doGetChatMemoryRetrieveSize(request.adviseContext());
//从ChatMemory(可以理解为消息记录仓储)获取当前所有消息记录
List<Message> memoryMessages = ((ChatMemory)this.getChatMemoryStore()).get(conversationId, chatMemoryRetrieveSize);
//增强后的消息列表->增强
List<Message> advisedMessages = new ArrayList(request.messages());
advisedMessages.addAll(memoryMessages);
//通过AdvisedRequest自带的属性messages附加消息对象的列表
AdvisedRequest advisedRequest = AdvisedRequest.from(request).messages(advisedMessages).build();
//将当前请求的用户消息记录到ChatMemory内,并通过ChatMemory存储。
UserMessage userMessage = new UserMessage(request.userText(), request.media());
((ChatMemory)this.getChatMemoryStore()).add(this.doGetConversationId(request.adviseContext()), userMessage);
return advisedRequest;
}
- ⭐ observeAfter:和向量库的记忆实现逻辑都一样,只是将生成的助手消息以对象的形式传给ChatMemory,交由ChatMemory去实现存储。但需要注意的是,不是所有的LLM模型都支持直接操作message对象的记忆、解析和读取。
PromptChatMemoryAdvisor
顾名思义,是通过将ChatMemory内嵌到提示词(Prompt)中实现记忆的类,实际上就是和VectorStore的嵌入方式是一样的:将历史记录转换成字符串,作为SystemText嵌入请求中,这样的好处就是不论LLM模型是否支持Request附带messages参数,都能够支持嵌入聊天记录了,但是具体在token消耗方面有怎样的区别,还有待考究。
方法
-
⭐ before:也是通过chatMemoryStore的接口方法去获取会话id对应的聊天记录,然后序列化成字符串。
String memory = memoryMessages != null ? (String)memoryMessages.stream().filter((m) -> { return m.getMessageType() == MessageType.USER || m.getMessageType() == MessageType.ASSISTANT; }).map((m) -> { String var10000 = String.valueOf(m.getMessageType()); return var10000 + ":" + m.getText(); }).collect(Collectors.joining(System.lineSeparator())) : "";注意,在Spring AI提供的官方实现中,prompt仅对USER和ASSISTANT消息类型进行处理(如上代码)。
-
observeAfter:和MessageChatMemoryAdvisor的实现一模一样,不过多赘述
SafeGuardAdvisor
官方提供的敏感词过滤的Advisor示例,它更像是一个拦截器,因为如果敏感词监测不通过,会直接不继续执行下一步的Advisor,而是直接返回Response
成员变量
-
failureResponse:由于敏感监测不通过而拒绝回答时的失败响应
-
sensitiveWords:一个String的List,表示敏感词
-
DEFAULTFAILURERESPONSE:默认的拒绝回答提示词
-
DEFAULT_ORDER:默认的执行顺序(0),在官方的实现类里是最高优先级别的存在
方法
- ⭐ aroundCall:和对话历史的增强不同,此处如果敏感词监测不通过,会直接返回失败请求,并不继续执行Advisor链上的下一内容,也就不会传递给chatModel了(如果在其之前还有Advisor,还是会触发上一个Advisor的after方法的,因此如果需要做敏感词触发的日志记录,执行顺序要比该Advisor早);
该Advisor不需要before和after方法,仅仅只对request进行一个过滤的作用。此处实现的敏感词检测还是比较简易的,如果需要自己实现更复杂的检测逻辑,可以参照SafeGuardAdvisor的实现逻辑,自行实现。
QuestionAnswerAdvisor
实现RAG的Advisor,根据问题在向量库中进行检索并对提示词进行增强
成员变量
-
RETRIEVED_DOCUMENTS :检索到的文档内容
-
FILTER_EXPRESSION : 过滤表达式参数的存储键
-
vectorStore:向量存储的接口,用于执行相似性搜索
-
userTextAdvise:用户的提示词模板
-
searchRequest:相似性搜索的配置参数,包含返回结果数、相似度阈值等
方法
- before:会先从上下文中获取用户的消息,以及过滤的表达式(该存储键似乎并没有暴露出来,可能是AI模型提供的),然后根据传入的searchRequest配置以及过滤表达式,在向量数据库中执行搜索,并存储至两个地方:第一个是上下文,以文档类形式存储(包含文档的元数据,方便后续链路处理);另一个是解析成字符串后,拼接到用户的纯文本提示词内,以questionanswercontext为键存储在用户的对话参数里。
private AdvisedRequest before(AdvisedRequest request) {
//获取上下文
HashMap<String, Object> context = new HashMap(request.adviseContext());
String var10000 = request.userText();
String advisedUserText = var10000 + System.lineSeparator() + this.userTextAdvise;
String query = (new PromptTemplate(request.userText(), request.userParams())).render();
//构建查询配置
SearchRequest searchRequestToUse = SearchRequest.from(this.searchRequest).query(query).filterExpression(this.doGetFilterExpression(context)).build();
List<Document> documents = this.vectorStore.similaritySearch(searchRequestToUse);
//嵌入到上下文的检索文档内
context.put("qa_retrieved_documents", documents);
String documentContext = (String)documents.stream().map(Document::getText).collect(Collectors.joining(System.lineSeparator()));
Map<String, Object> advisedUserParams = new HashMap(request.userParams());
//嵌入到用户的对话参数内
advisedUserParams.put("question_answer_context", documentContext);
AdvisedRequest advisedRequest = AdvisedRequest.from(request).userText(advisedUserText).userParams(advisedUserParams).adviseContext(context).build();
return advisedRequest;
}- after:在该Advisor的after方法里,会将文档类嵌入到一个响应体里进行返回,作用也有可能是为了方便展示参考的文档来源。
private AdvisedResponse after(AdvisedResponse advisedResponse) {
// 1. 基于原始响应创建构建器
ChatResponse.Builder chatResponseBuilder = ChatResponse.builder()
.from(advisedResponse.response()); // 继承原始响应内容
// 2. 注入检索文档到元数据
chatResponseBuilder.metadata(
"qa_retrieved_documents", // 元数据键
advisedResponse.adviseContext().get("qa_retrieved_documents") // 从上下文获取文档列表
);
// 3. 构建增强后的响应
return new AdvisedResponse(
chatResponseBuilder.build(), // 包含文档元数据的新响应
advisedResponse.adviseContext() // 保留原始上下文
);
}
SimpleLoggerAdvisor
简易的Logger实现类示例,分别在before和after里用logger添加log信息
需要注意的就是官方给的示例基于Slf4j日志门面实现,如果你有别的框架,可以自己实现logger增强类,直接实现BaseAdvisor接口并实现before和after方法即可
能看到这说明你真的对Spring AI真的很感兴趣,那么接下来就是M6版本的最后一个官方提供的Advisor了(Ailbaba M5.1有基于灵积和百炼平台的其他实现,如果想要学习,可以参考)
RetrievalAugmentationAdvisor
这是Spring AI官方给出的较为复杂的RAG实现的增强类,比起QuestionAnswerAdvisor,他的功能更加地复杂,而非只是简单地在向量数据库内进行检索
成员变量
-
DOCUMENT_CONTEXT:在上下文中的存储键
-
queryTransformers:查询转换器链式处理
-
queryExpander:查询扩展(生成子查询)
-
documentRetriever:核心的文档检索组件(必要的)
-
documentJoiner:多查询结果合并策略
-
queryAugmenter:原始查询增强(注入文档上下文)
-
taskExecutor:并行任务执行器
-
scheduler:任务调度测类
从成员变量上来看,就能看出这个Advisor的实现类非常地复杂且功能强大了,其流程大约为: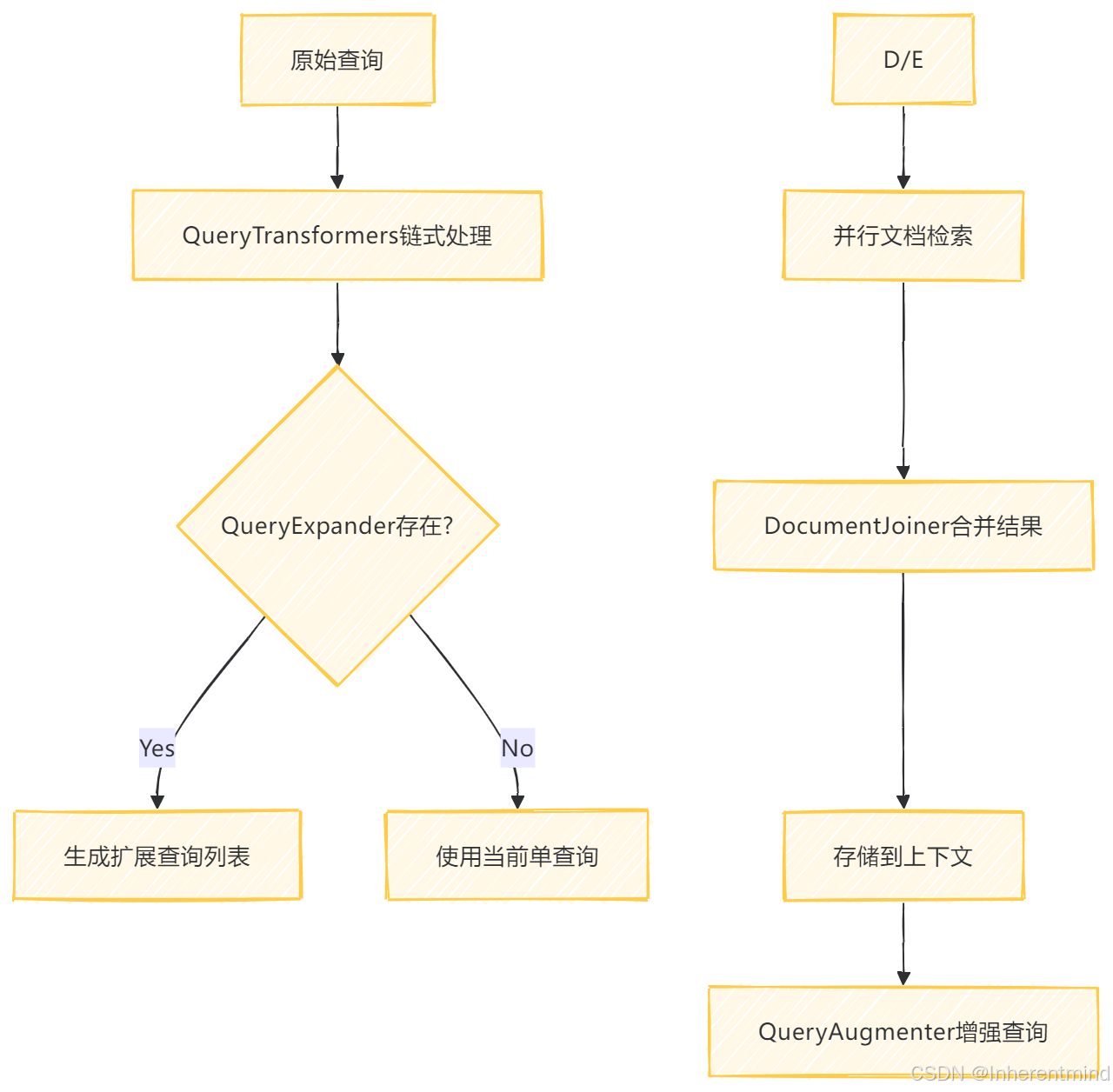
其各个环节主要的功能大概如下
-
原始查询构建:组合用户输入与历史消息
-
链式查询转换(如拼写校正、语义改写)
-
查询扩展生成多版本查询(如关键词变体)
-
并行异步检索(
CompletableFuture.supplyAsync) -
文档合并策略(默认拼接)
-
上下文注入与查询增强
在并行检索中,还支持并发控制机制:
-
线程池配置:
-
核心线程4个,最大16个(应对突发流量)
-
上下文传播装饰器(保证线程间上下文传递)
可以看出这里面又涉及到了很多Spring AI提供的RAG相关的组件类,可以说这就是一个很丰富的官方对于RAG的Advisor实现案例了,它将很方便地支持RAG的深度优化即查询重写+多路召回+结果融合等需求。这个类还是一个实验性类,等稳定下来后,我们再来对RAG做一个完整的学习。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)