【一周论文速度笔记】推理步骤对COT数据的正确性+如何挑选质量好的数据
包括本周速读的三篇文章,LLMs Can Easily Learn to Reason from DemonstrationsStructure, not content, is what matters!Predictive Data Selection: The Data That Predicts Is the Data That Teaches,和Compression Represent
这周速读就三篇。
LLMs Can Easily Learn to Reason from Demonstrations
Structure, not content, is what matters!
一句话总结
作者通过扰动实验发现,针对COT训练数据,增删改推理步骤的结构对模型性能影响很大,而改变推理步骤中的数值、答案或关键词(激发revise等步骤的措辞)对性能影响较小。
关键细节
- 17k的数据能把Qwen2.5-32B+Lora 训练到o1的水平
这个观点有同行佐证:LIMO的文章中用的800多条数据也把Qwen训练得很好。但是这两篇文章观点的前提都一样——【是因为站在了巨人的肩膀上】。他们都用的是Qwen2.5-32B 。Qwen2.5系列的模型都是被大量数学推理任务磨过的,这两篇文章体现出来的轻巧不是独立成立的,没有Base模型的强大,这个结论也难以成立。 - 【COT的全局结构的正确性】对模型性能的影响远比【答案】和【中间步骤结果】的正确性要大
这是作者的核心观点,也是这篇文章的价值所在(虽然大部分同行对这个结论有预判,但没有对应的定量分析)
下面表里都是数学推理任务的常见数据集,第一列相对简单,第二列开始的几个数据集都有难度。左边第一列标明了作者对COT的<扰动+侵蚀>时使用的方法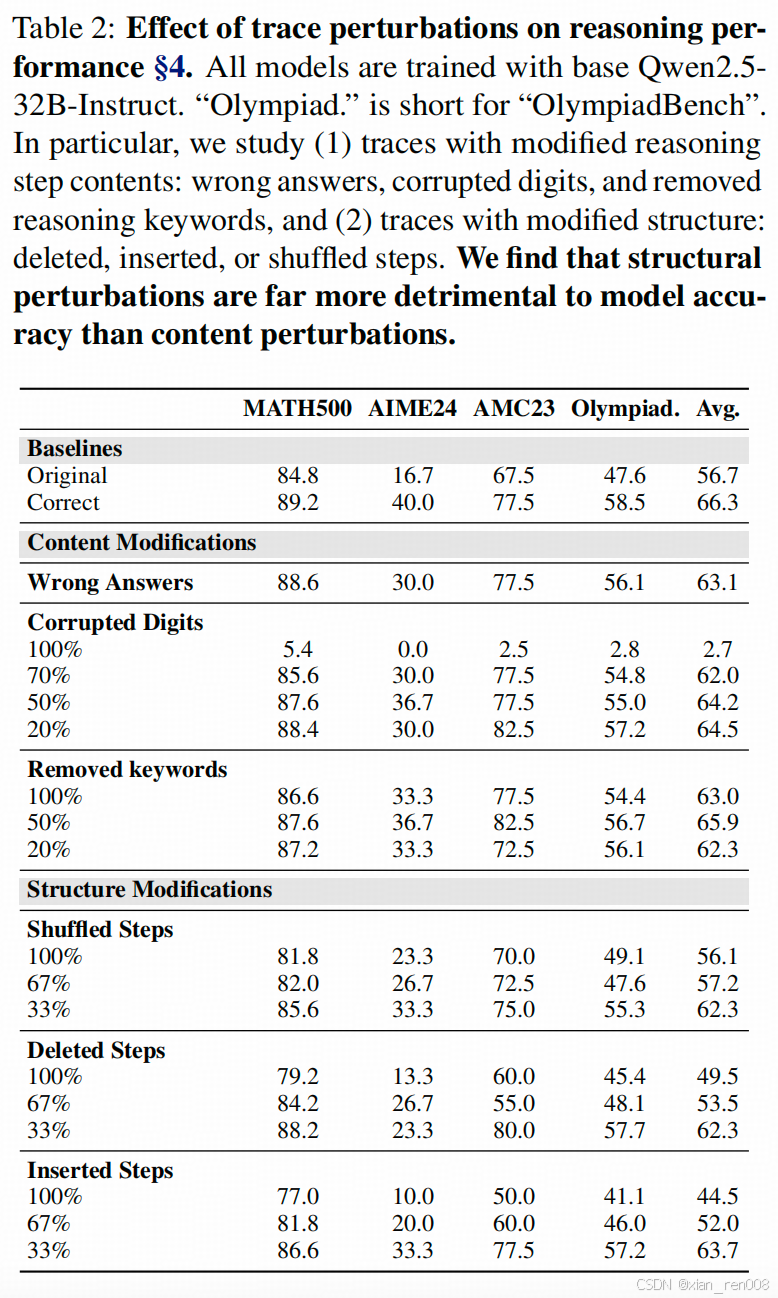
怎么评价
- 做此类定量分析能够很好的给人形成什么对训练数据更重要的印象,这点我很喜欢。
- 论文附录里展示了数学推理的数据的样式,值得看看。
- 只有一个问题,这个是一个从必要性的角度进行研究,缺少对推理步骤的分类定义和发散性的研究(倒不是要求作者应该做),这样就使得,什么是推理更必要的数据,什么样的结构是更合理的COT结构,这些问题还是得不到回答。相比R1中【详略得到】和【zero发挥】这两个点,这篇文章就缺少了一些启发性。(仍然不是说作者的设计有问题,而是这类研究方法都有这样的问题。)
Predictive Data Selection: The Data That Predicts Is the Data That Teaches
一句话总结
作者为获更优<预训练数据>,借助多 LLM 模型生成评分标签,用 fasttext 学习后筛选语料,并达到了比较好的效果 。
就基础思路而言,这个其实跟active learning中的基于不确定性选择数据的原则正好相反。
关键细节
- 作者设计了一个规则来选取数据,
- 用一个fasttext模型来模拟这个规则,
- 选fasttext评分高的数据做预训练。
原则是什么?
答:用于预训练的语料,如果和下游任务关联越高,对提升预训练模型的能力就越有价值。
怎么从数值上体现这个原则的?
答: 作者找的一系列在leaderboard上有排名的大模型,用这些大模型对这个语料算lm的loss,查看各个模型的<loss的排序> 与<leaderboard的排名>顺序的一致性。
这个东西比较绕,不是loss的绝对数值,而是loss的排序和能力排序的的一致性。一致性越高,(作者认为)语料越有价值
fasttext的(X,Y)分别是什么?
X 是预训练语料,作者用的common crew; Y是用leaderboard上的模型打的评分一致率
怎么评价
-
依赖的原则靠谱吗?——靠谱但不太实用。
依赖的原则来自另外一篇论文,另外一篇论文也会放到后面的论文总结里。 -
作者在选择指标的时候为什么这么绕
一来是 直接用loss的比较,意义不大,毕竟不同模型对不同模型
二来是 用loss 打平均分估计作者也试过,因为各个模型本身的训练语料的不同,loss平均化也不是一个好的思路。
这个ranker的想法估计就是前两个思路死了之后,作者想出来的。
其实这也是种挺好的思路。 -
怎么用
诚然,这个场景已经是训练数据的二次过滤场景了,这种逻辑是行得通的。但是在实践中,考虑用小模型来拟合大模型评议结果,可以作为pipeline中的一环。
Compression Represents Intelligence Linearly
上一篇文章的前置文章
一句话总结
作者发现了一个香蕉大香蕉皮也大一样的规律
如果模型对代码文本的学得好,那下游代码任务也做的好。
关键细节
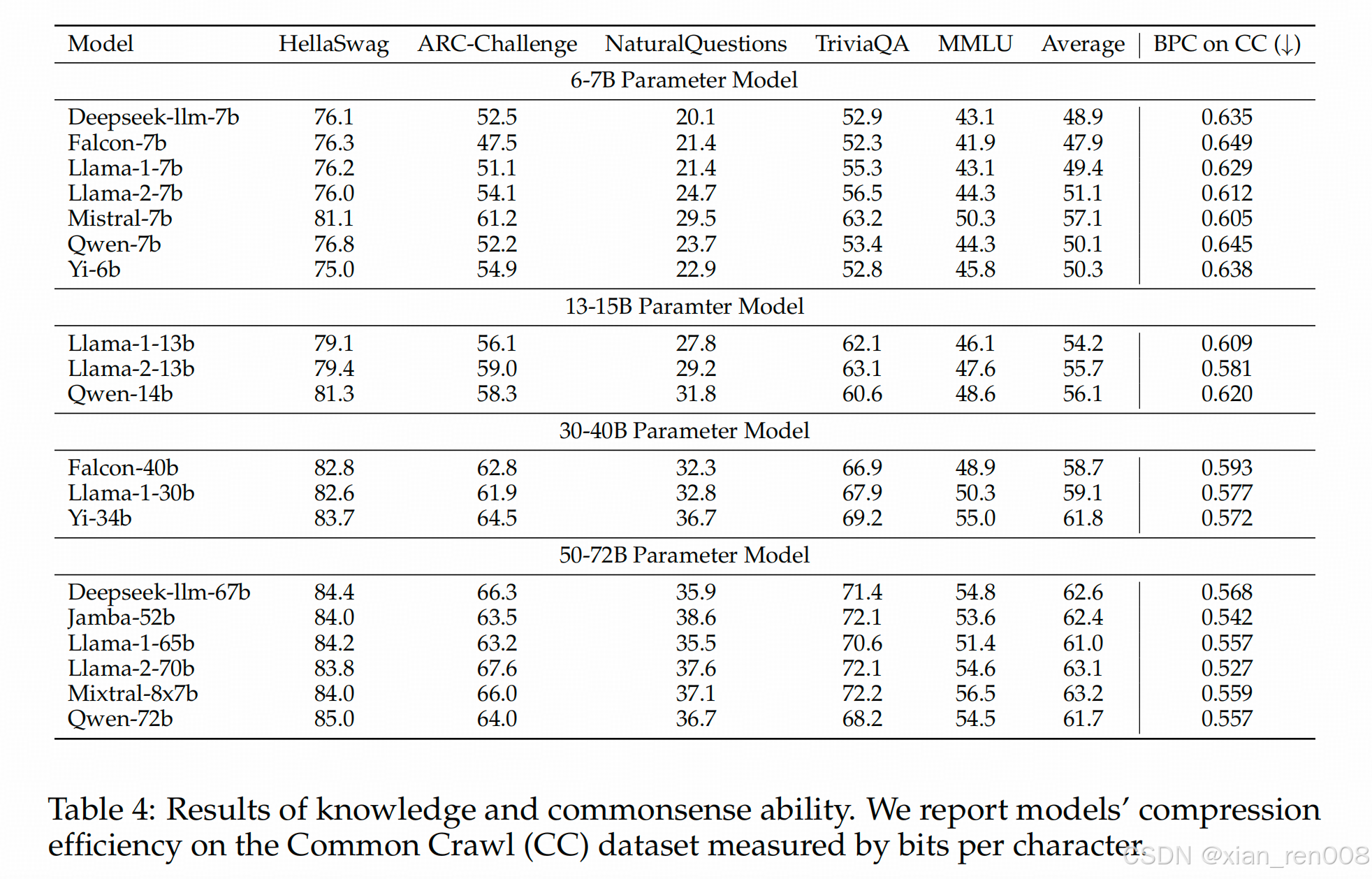
- 作者用于评价学得好的指标是一个跟loss比较相近的东西 BPC(bits per charactor)
实际上BPC这个名字很容易混淆理解,这个BPC的公式就是
这差不多是个平均生成熵的概念,其实跟你看PPL,看loss,没有本质区别。 - 作者计算相关性用的就是下面这种模式,文中的表4/6/8 是在common senese,code 和 math三个任务上,看模型在对应任务的benchmark集上的表现,和(表最后一列)在对应任务同质的数据集上的BPC。因为本身BPC就跟loss一样,反应了模型对某些文本的熟悉程度。而大部分模型的训练集里都或多或少掺了对应的训练数据。最后得到的就是一个香蕉大香蕉皮也大的结论。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 33
33 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)