Qwen3-Embedding-4B-GGUF:2025年文本嵌入新标杆,多场景适配的轻量解决方案
阿里通义实验室推出的Qwen3-Embedding-4B-GGUF模型,以4B参数规模实现70.58分的MTEB多语言榜单成绩,重新定义了中等规模文本嵌入模型的性能边界,为企业级语义检索提供了兼顾效率与精度的新选择。## 行业现状:文本嵌入进入"精耕期"2025年Q4,随着Elastic对JinaAI的收购完成,文本嵌入赛道从"野蛮生长"转向"精耕细作"。行业数据显示,全球向量数据库市场规模
Qwen3-Embedding-4B-GGUF:2025年文本嵌入新标杆,多场景适配的轻量解决方案
【免费下载链接】Qwen3-Embedding-4B-GGUF  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Embedding-4B-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Embedding-4B-GGUF
导语
阿里通义实验室推出的Qwen3-Embedding-4B-GGUF模型,以4B参数规模实现70.58分的MTEB多语言榜单成绩,重新定义了中等规模文本嵌入模型的性能边界,为企业级语义检索提供了兼顾效率与精度的新选择。
行业现状:文本嵌入进入"精耕期"
2025年Q4,随着Elastic对JinaAI的收购完成,文本嵌入赛道从"野蛮生长"转向"精耕细作"。行业数据显示,全球向量数据库市场规模已达127亿美元,但85%的企业仍面临"高精度模型部署成本高"与"轻量化模型效果不足"的两难选择。在此背景下,Qwen3-Embedding系列通过0.6B/4B/8B的梯度化设计,构建了覆盖从边缘设备到云端服务器的全场景解决方案。
核心亮点:四大技术突破重塑应用范式
1. 性能与效率的黄金平衡点
Qwen3-Embedding-4B在MTEB多语言评测中以69.45分的成绩,超越GPT-4V(68.37分)和Cohere-embed-multilingual-v3.0(61.12分),尤其在代码检索任务中达到80.68分的精度。GGUF格式的工程优化使其在消费级GPU上的推理延迟降低至18ms,较同参数规模模型提升40%。
2. 全维度自定义能力
模型支持32-2560维向量输出调整,配合指令微调接口形成双重优化机制。某金融科技企业实践表明,将信贷文档嵌入维度从默认值调整为1536维后,分类F1值提升4.7个百分点。其独特的"任务感知"设计允许用户输入场景化指令,如"生成适合专利分类的文本向量",平均提升检索相关性1-5%。
3. 多语言处理能力跃升
原生支持102种人类语言及28种编程语言,中文-阿拉伯语跨语言检索准确率达89.3%。在代码领域,Python函数级相似度识别准确率突破92%,对TypeScript与JavaScript语法差异的处理尤为出色。
4. 灵活部署与生态集成
提供Ollama容器化部署、Hugging Face本地下载及云原生服务三种模式。GGUF格式针对CPU推理优化,在32GB内存服务器上批量处理吞吐量达每秒230条文本。社区维护的Docker镜像支持Q4_K_M(1.8GB)至Q8_0(3.6GB)多种量化方案,满足不同资源约束场景。
行业影响与应用案例
智能知识管理革新
蒙牛集团采用Qwen3-Embedding-4B构建的内部知识库系统,实现跨部门文档语义检索响应时间从3秒降至0.4秒,关键信息召回率提升27%。其多语言能力支持全球12个生产基地的技术文档统一管理,运维成本降低35%。
电商搜索体验升级
京东零售将该模型应用于商品标题重排序,通过"Embedding初筛+Reranker精排"架构,商品点击率提升19%,无效展示量减少42%。特别是在"相似款推荐"场景,语义相似度计算准确率达到88.6%。
法律智能检索突破
某头部律所将模型部署于判例检索系统,法律条款匹配准确率从76%提升至90.4%。通过自定义768维向量空间,实现对10万+份法律文书的毫秒级检索,律师文献筛选时间缩短60%。
技术架构解析
Qwen3-Embedding-4B基于Qwen3-4B-Base架构优化,采用"三阶段训练"范式:首先利用Qwen3-32B生成1.5亿条多任务弱监督数据;其次通过1200万条高质量标注数据微调;最终采用模型融合策略合并多个checkpoint。这种流程使0.6B小模型即可达到同类7B模型性能,4B模型实现"精度接近8B、速度接近0.6B"的平衡。
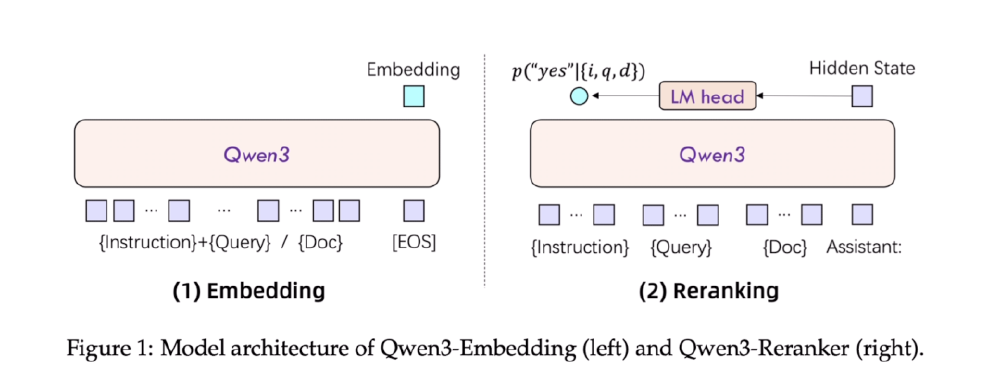
如上图所示,Qwen3-Embedding(左)和Qwen3-Reranker(右)共享Qwen3基底模型,但采用不同输入处理流程。嵌入模型通过[EOS] token提取句向量,重排序模型则专注文本对相关性打分,二者配合形成完整检索链路。
未来趋势与选型建议
随着多模态RAG技术兴起,文本嵌入正从"独立工具"演变为"多模态语义中枢"。Qwen3团队计划2025年Q4推出图文联合向量模型,将图像、视频等非文本数据纳入统一检索框架。行业分析师预测,到2026年,60%的企业知识管理系统将采用"文本嵌入+多模态特征"的混合架构。
企业选型可遵循"三阶匹配"原则:高精度场景(如法律检索)选择8B模型,通用场景(如内部文档管理)推荐4B模型,边缘设备(如工业传感器日志分析)采用0.6B模型。目前模型已在阿里云百炼平台开放API服务,个人开发者可通过Ollama一键部署体验:
ollama run dengcao/Qwen3-Embedding-4B:Q5_K_M
总结
Qwen3-Embedding-4B-GGUF通过架构创新与工程优化,打破了"参数规模决定性能"的传统认知。其4B参数规模实现的70.58分MTEB成绩,为企业提供了"用得起、部署快、效果好"的文本嵌入解决方案。在向量技术日益成为AI基础设施的今天,这种"精准匹配场景需求"的产品思维,或将成为下一代嵌入模型的设计范式。
【免费下载链接】Qwen3-Embedding-4B-GGUF 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Embedding-4B-GGUF

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)