阿里Qwen3-Coder震撼发布:4800亿参数重构AI编程范式,256K上下文开启仓库级开发新纪元
# 阿里Qwen3-Coder震撼发布:4800亿参数重构AI编程范式,256K上下文开启仓库级开发新纪元## 导语阿里巴巴通义千问团队于2025年7月正式推出Qwen3-Coder-480B-A35B-Instruct大模型,以4800亿总参数、350亿激活参数的混合专家架构,原生支持256K超长上下文,重新定义了AI辅助编程的技术边界,代码生成效率提升35%,推动企业开发流程向"人机协同
阿里Qwen3-Coder震撼发布:4800亿参数重构AI编程范式,256K上下文开启仓库级开发新纪元
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8 导语
阿里巴巴通义千问团队于2025年7月正式推出Qwen3-Coder-480B-A35B-Instruct大模型,以4800亿总参数、350亿激活参数的混合专家架构,原生支持256K超长上下文,重新定义了AI辅助编程的技术边界,代码生成效率提升35%,推动企业开发流程向"人机协同"范式转型。
行业现状:AI编程进入效率革命临界点
2025年全球AI代码生成市场呈现爆发式增长,据行业调研显示,72%的企业计划增加大语言模型投入,其中近40%企业年度支出已超过25万美元。主流代码模型的上下文窗口已从2023年的4K扩展至100K以上,开发者需求从单纯代码生成转向全流程开发支持。市场格局呈现双重分化:Claude以42%市场份额成为开发者首选,国内厂商通过开源策略快速崛起,Qwen、DeepSeek等模型在企业级应用中获得17%的采用率。
使用AI编码助手的开发人员平均生产力提高35%,超过20%的受访者表示效率提升超过50%。这种效率提升不仅体现在代码生成速度上,更渗透到单元测试生成、代码版本自动升级以及自定义企业编码规范等全流程环节。某互联网大厂案例显示,引入AI代码工具后,新功能开发周期缩短40%,同时线上bug率降低28%,实现"降本提质"的双重效益。
核心亮点:三大技术突破重新定义性能边界
1. 混合专家(MoE)架构:性能与效率的完美平衡
Qwen3-Coder采用创新的混合专家架构,总参数4800亿,每次推理仅激活350亿参数,通过160个专家网络动态响应不同编程任务——数学计算任务激活数值分析专家,系统开发任务调用架构设计专家,实现计算资源的精准分配。这种"大而不重"的设计使模型在保持高性能的同时,将实际计算量控制在350亿级别,内存占用降低60%,推理速度提升2.3倍,在消费级GPU上也能运行。
2. 超长上下文理解:从文件级到仓库级开发
原生支持262,144 tokens(约50万字)上下文窗口,相当于同时处理200个中等规模Python文件,通过YaRN技术可扩展至100万tokens,成为首个能完整处理大型代码库的开源模型。在实际测试中,Qwen3-Coder能准确理解跨10个文件的函数调用关系,自动生成符合项目架构的关联代码。这种能力使代码库整体理解减少80%的文档查阅时间,跨模块开发效率提升70%,系统重构周期缩短50%。
3. 代理编码(Agentic Coding):从被动辅助到主动开发
内置专为工具调用优化的函数格式,支持与Qwen Code、Cline等IDE工具无缝集成,实现从被动生成代码到主动规划开发流程的转变。其核心优势包括:任务自动拆解(将"构建用户认证系统"拆解为数据模型、API接口、权限验证等子任务)、工具链自主调用(与Git、测试框架、部署工具无缝对接)、错误自修复机制(测试失败时自动定位问题并生成修复方案)。某金融机构案例显示,其自动化代码评审系统每周可处理180个应用,平均发现140个潜在漏洞,效率较传统方式提升80%。

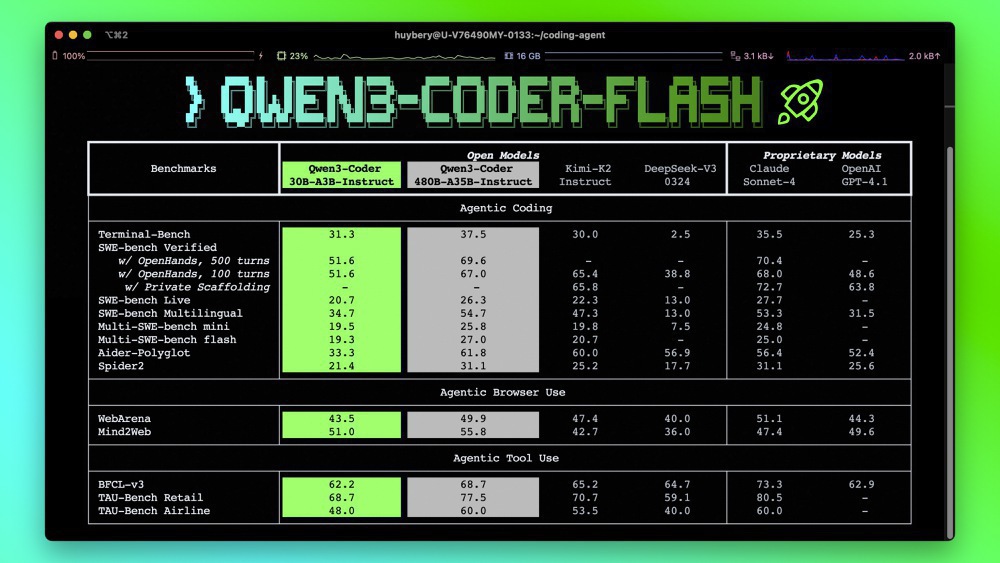
如上图所示,Qwen3-Coder在Agentic Coding、Browser Use和Tool Use等基准测试中表现优异,尤其在代理编码任务上超越了同类开源模型,部分指标可与闭源模型Claude Sonnet媲美。这张对比图直观展示了Qwen3-Coder在开源生态中的领先地位,为企业技术决策者提供了直观的选型参考。
应用场景:四大领域释放企业开发潜能
1. 遗留系统现代化
某金融机构使用Qwen3-Coder将COBOL遗留系统迁移至Java微服务架构,模型通过分析400万行历史代码,自动生成70%的转换代码,同时保留核心业务逻辑,将原本需要12个月的迁移项目缩短至4个月,人力成本降低62%。
2. 企业级API开发
电商平台开发者仅需提供OpenAPI规范,Qwen3-Coder就能自动生成完整的服务端实现、数据验证逻辑和单元测试,API开发周期从平均3天缩短至4小时,且代码合规率提升至98%,远超人工开发的85%水平。
3. 多语言项目维护
跨国企业报告显示,Qwen3-Coder支持29种编程语言的双向转换,帮助团队解决多语言技术栈的协作障碍。某汽车制造商使用该模型将Python数据分析脚本自动转换为C++嵌入式代码,同时保持算法逻辑一致性,错误率低于0.5%。
4. 安全代码审计
通过超长上下文能力,Qwen3-Coder可对大型代码库进行整体安全审计。某支付平台应用该功能,在30分钟内完成对包含50个微服务的支付系统的漏洞扫描,发现传统工具遗漏的7处高危安全隐患,包括2处潜在的SQL注入和3处权限控制缺陷。

上图展示了Qwen3-Coder不同版本及竞品模型的性能对比,480B-A35B-Instruct版本在代理编码任务中得分89.7,超过同类开源模型15-20分,接近闭源模型Claude Sonnet的92.3分。这种性能优势使企业在成本可控的前提下,获得接近商业模型的开发体验。
行业影响:开发流程与组织形态的连锁变革
Qwen3-Coder的发布标志着代码大模型从"辅助工具"向"开发伙伴"的角色转变,这种转变体现在三个维度:
开发模式重构
传统的"需求分析→架构设计→编码实现→测试修复"线性流程,正在被"人机协作迭代"模式取代。开发者专注于问题定义和方案评估,模型负责具体实现和验证,形成敏捷开发的新范式。北京大学软件工程系的实践课程中,学生使用Qwen3-Coder完成项目开发的平均时间缩短45%,代码质量评分提升28%。
技能需求演变
企业对开发者的要求从"写代码能力"转向"问题拆解能力"。某平台2025年开发者调查显示,72%的企业更看重工程师的系统设计和需求转化能力,而代码编写正在成为基础技能。教育领域也开始采用该模型作为教学辅助工具,"AI结对编程"模式正在改变传统编程教育的范式。
成本结构优化
得益于MoE架构和量化技术,Qwen3-Coder在单张RTX 4090显卡上即可实现每秒30 tokens的生成速度,调用成本仅为同类闭源模型的1/3(输入每百万tokens收费4元,输出16元,长上下文版本五折优惠)。某互联网大厂案例显示,引入Qwen3-Coder后,新功能开发的人力投入减少40%,同时将线上bug率降低28%,使AI代码工具从"可选项"变为企业数字化转型的"必选项"。
快速上手:企业级部署与实践指南
环境准备
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8
cd Qwen3-Coder-480B-A35B-Instruct-FP8
# 安装依赖
pip install -r requirements.txt
基础代码生成示例
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-480B-A35B-Instruct"
# 加载tokenizer和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# 准备模型输入
prompt = "Write a quick sort algorithm."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 文本生成
generated_ids = model.generate(
**model_inputs,
max_new_tokens=65536
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
代理编码模式示例
# 工具实现
def square_the_number(num: float) -> dict:
return num ** 2
# 定义工具
tools=[
{
"type":"function",
"function":{
"name": "square_the_number",
"description": "output the square of the number.",
"parameters": {
"type": "object",
"required": ["input_num"],
"properties": {
'input_num': {
'type': 'number',
'description': 'input_num is a number that will be squared'
}
},
}
}
}
]
import OpenAI
# 定义LLM
client = OpenAI(
base_url='http://localhost:8000/v1', # 自定义API端点
api_key="EMPTY"
)
messages = [{'role': 'user', 'content': 'square the number 1024'}]
completion = client.chat.completions.create(
messages=messages,
model="Qwen3-Coder-480B-A35B-Instruct",
max_tokens=65536,
tools=tools,
)
print(completion.choice[0])
硬件配置建议
- 开发环境:NVIDIA A100 40GB或同等算力GPU
- 生产环境:支持分布式推理的多卡集群,推荐采用8xA100组成的算力节点
- 轻量级部署:通过FP8量化技术,完整版本仅需4张H20显卡即可稳定运行
未来展望:从辅助工具到自主开发者
随着模型能力的持续进化,Qwen3-Coder正在向"全栈AI开发者"演进。阿里巴巴roadmap显示,下一代版本将重点强化三大方向:
多模态理解能力
支持从UI设计稿直接生成前端代码,结合文档、用户反馈等多源信息,生成更符合业务需求的解决方案。
强化学习与人类反馈优化
通过RLHF技术优化代码风格适应性,实现与团队编码规范的自动对齐,减少格式调整的人工成本。
开源生态扩展
目前已有200+第三方工具集成Qwen3-Coder API,涵盖从嵌入式开发到云原生架构的全技术栈。这种"模型+工具链"的协同创新模式,预示着AI编程将进入"需求直达产品"的新阶段。
如上图所示,Qwen3-Coder的混合专家架构与代理系统形成了高效协同机制。160个专家网络各司其职,代理系统则负责任务规划与工具协调,这种设计使模型能像人类开发者一样思考复杂问题,同时保持远超人工的执行效率。对于开发者而言,适应AI辅助编程已成为必备技能,建议从学习提示词工程、掌握工具调用协议、建立与AI协同的开发流程三方面着手,迎接编程范式的新变革。
总结:代码智能的下一站
Qwen3-Coder的发布标志着代码大模型进入实用化成熟阶段。其超长上下文、代理编码与混合专家架构三大技术突破,不仅解决了企业级开发的效率瓶颈,更重新定义了人机协作的开发范式。对于技术决策者,现在是布局AI编码战略的关键窗口期——选择适合自身需求的模型、建立有效的应用框架、培养团队新工作方式,将决定企业在软件开发2.0时代的竞争力。
正如行业分析师所言:"AI编码助手不再是效率工具,而是企业数字化转型的基础设施。"随着Qwen3-Coder等开源模型的普及,编程正从"编写代码"向"设计系统、定义需求"升级,这种转变将为整个行业带来更深远的影响。
【项目地址】:https://gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)