Transformer手撕(附完整代码)|大模型
 耗时许久完成了纯手搓的Transformer结构(除了测试和注释),按照原论文同时做了一些现在更常用的小修改(如Pre-Norm、激活函数等),总体都是使用了最基础结构,也做了笔记和批注,主要是从头到尾分析了tensor维度变化➕一些思考🧐
耗时许久完成了纯手搓的Transformer结构(除了测试和注释),按照原论文同时做了一些现在更常用的小修改(如Pre-Norm、激活函数等),总体都是使用了最基础结构,也做了笔记和批注,主要是从头到尾分析了tensor维度变化➕一些思考🧐
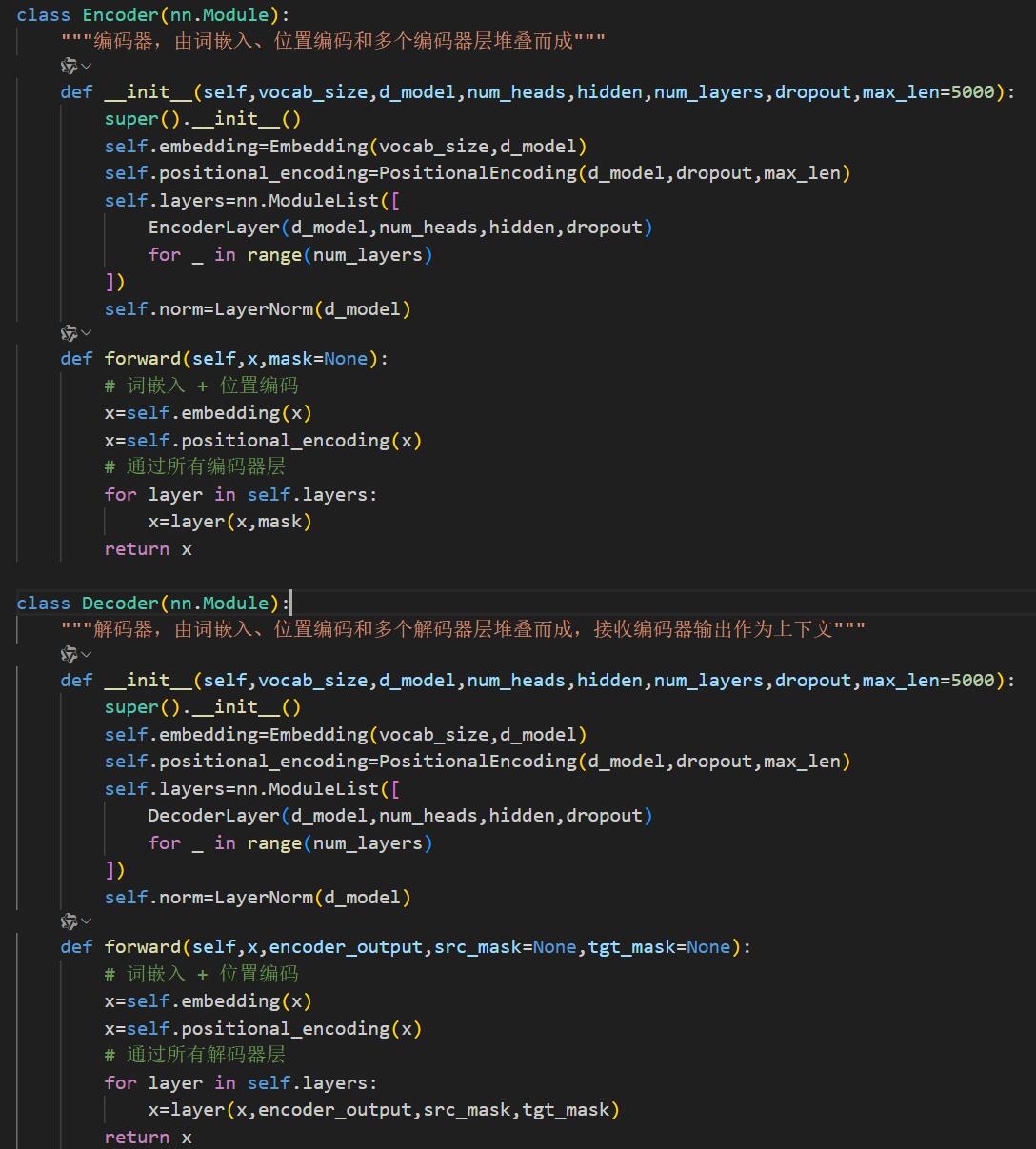
1️⃣基础嵌入与位置编码
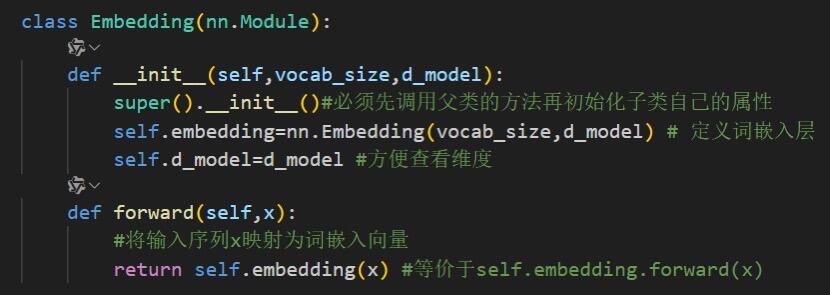
Embedding层:将输入映射为高维向量,即词嵌入。含独立的编码器和解码器嵌入层,以支持不同词表(如翻译中的源/目标语言)
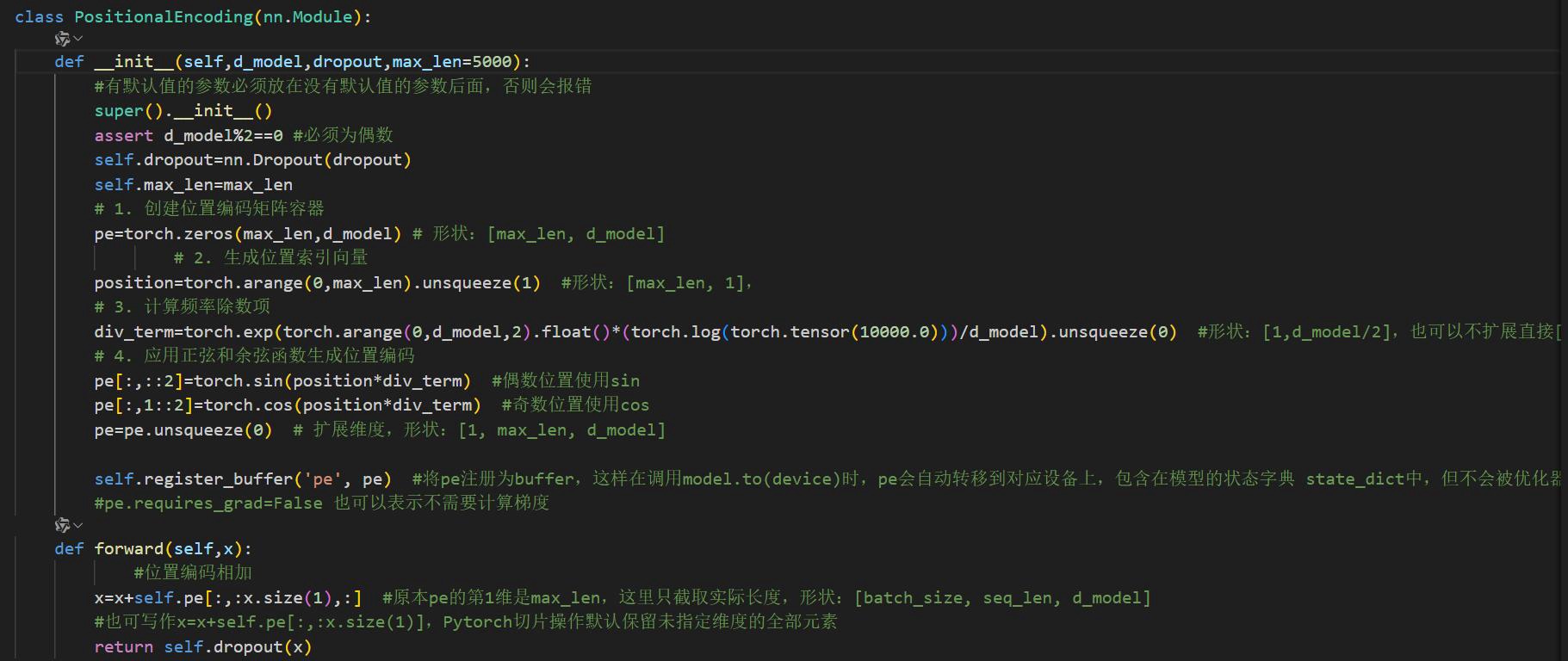
PositionalEncoding层:通过正弦/余弦函数生成位置编码,与词嵌入相加,为并行处理的Transformer注入序列顺序信息
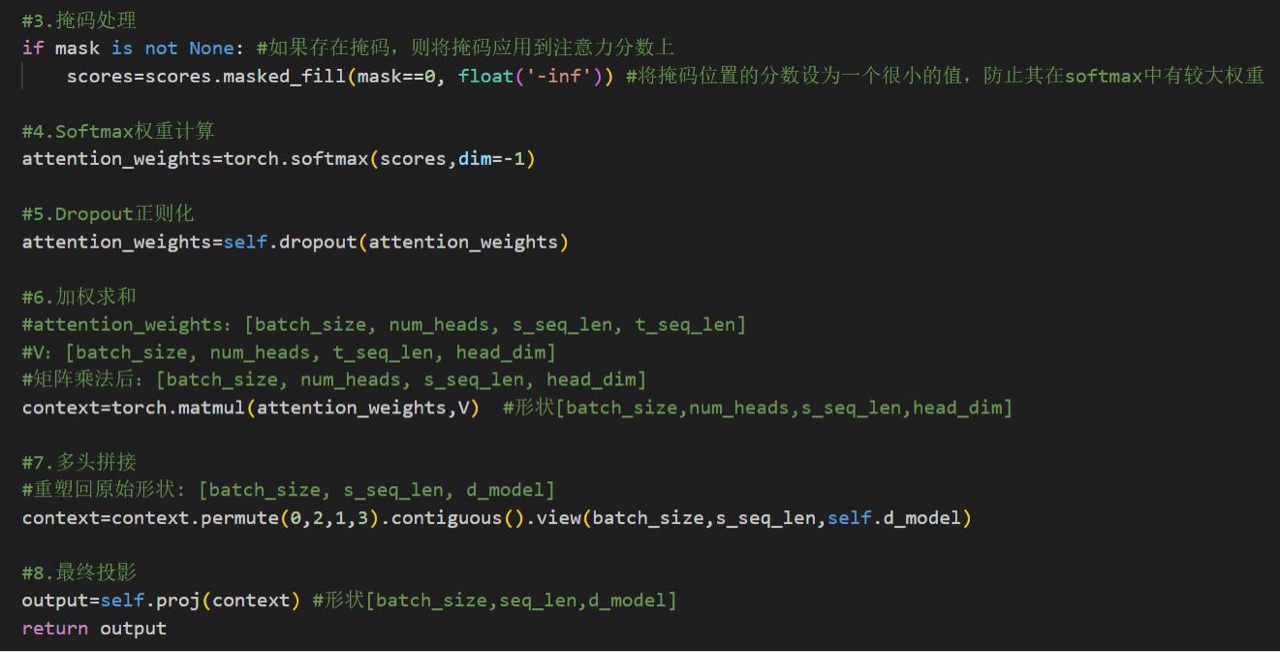
2️⃣核心注意力机制
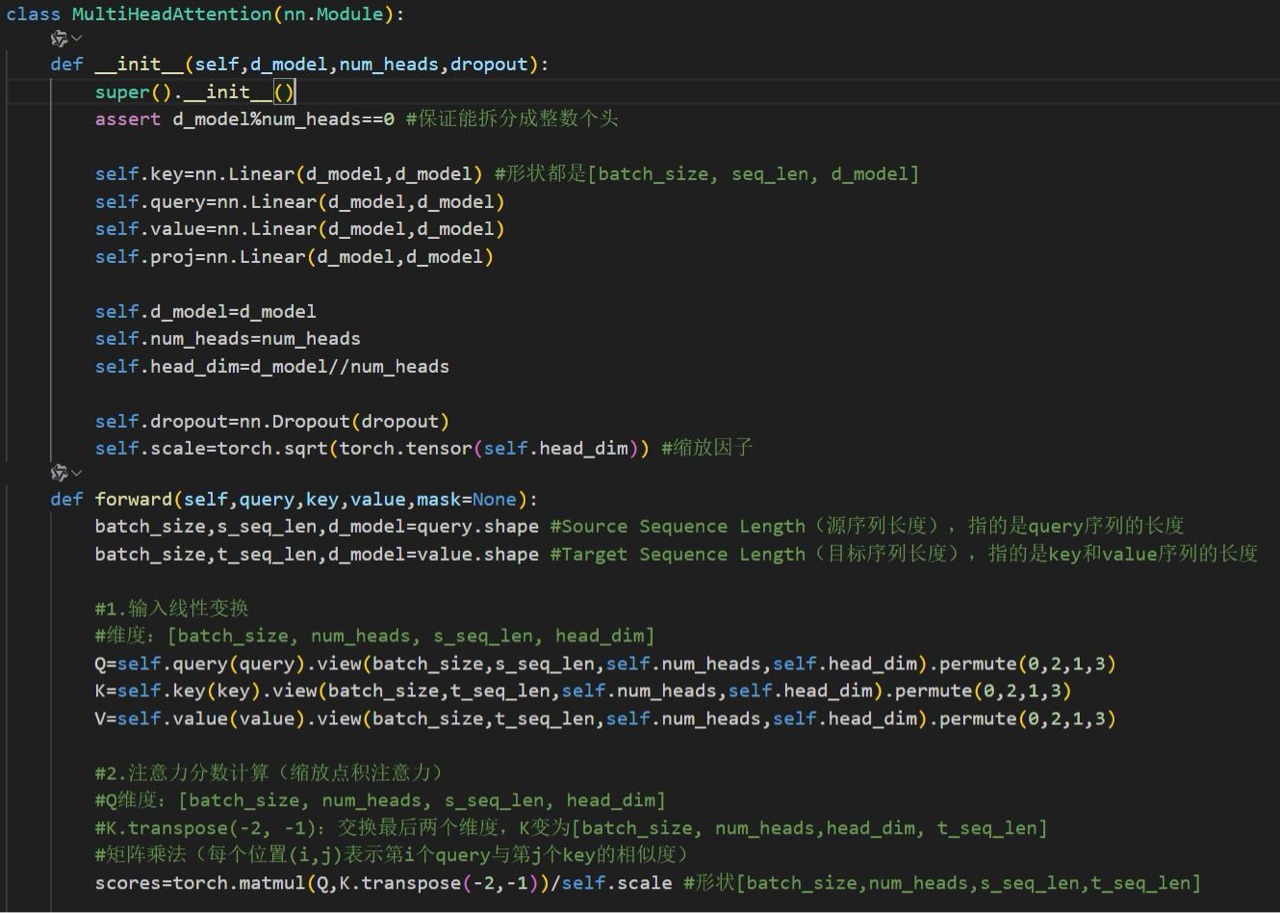
MultiHeadAttention层:将输入线性投影至多个子空间,并行计算注意力后拼接并投影输出。多头机制可同时捕捉不同语义特征(如语法、指代关系)
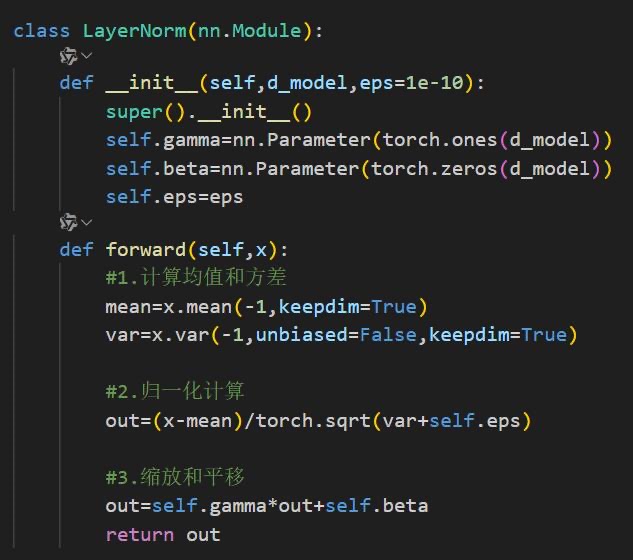
3️⃣归一化与残差连接
ResidualConnection层:通过输入与输出的直接相,缓解梯度消失,提升深层网络优化。每个编码/解码层含两个残差连接
LayerNorm层:对特征维度归一化以稳定训练。标准架构采用后归一化(Post-Norm),但Pre-Norm(子层前归一化)也被证明更易训练
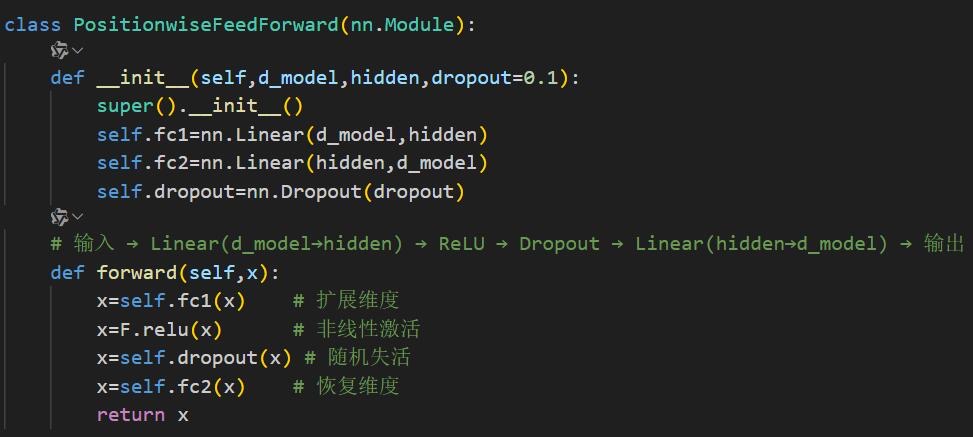
4️⃣前馈网络与层堆叠
PositionwiseFeedForward层:对序列各位置独立进行线性变换+非线性激活,实现特征非线性转换与维度调整
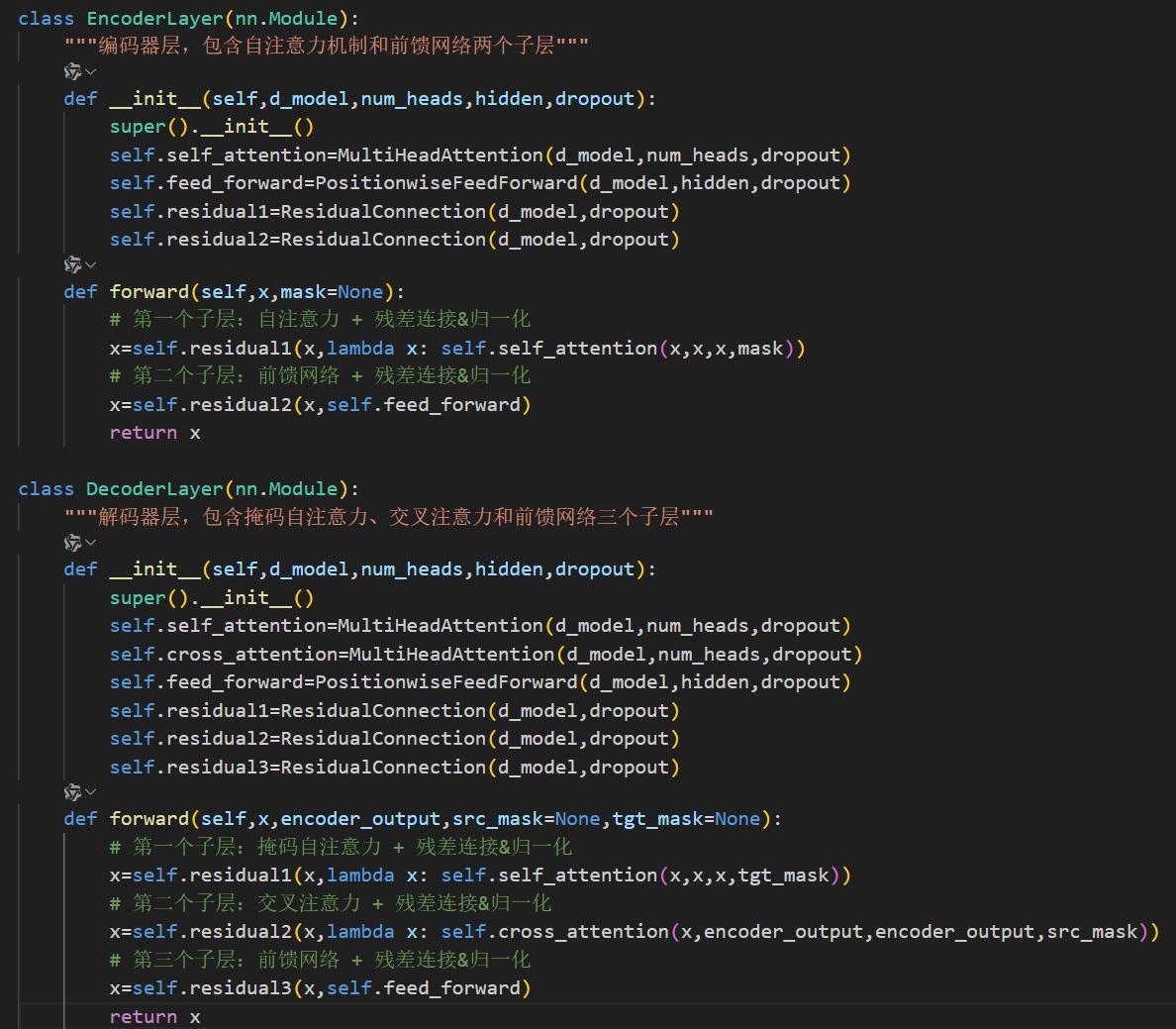
EncoderLayer/DecoderLayer层:组合多组件构成单处理层。编码器层含自注意力和前馈网络;解码器层增加掩码自注意力及编码器-解码器交叉注意力
Encoder/Decoder层:堆叠N个处理层,底层关注局部特征,高层聚焦全局语义
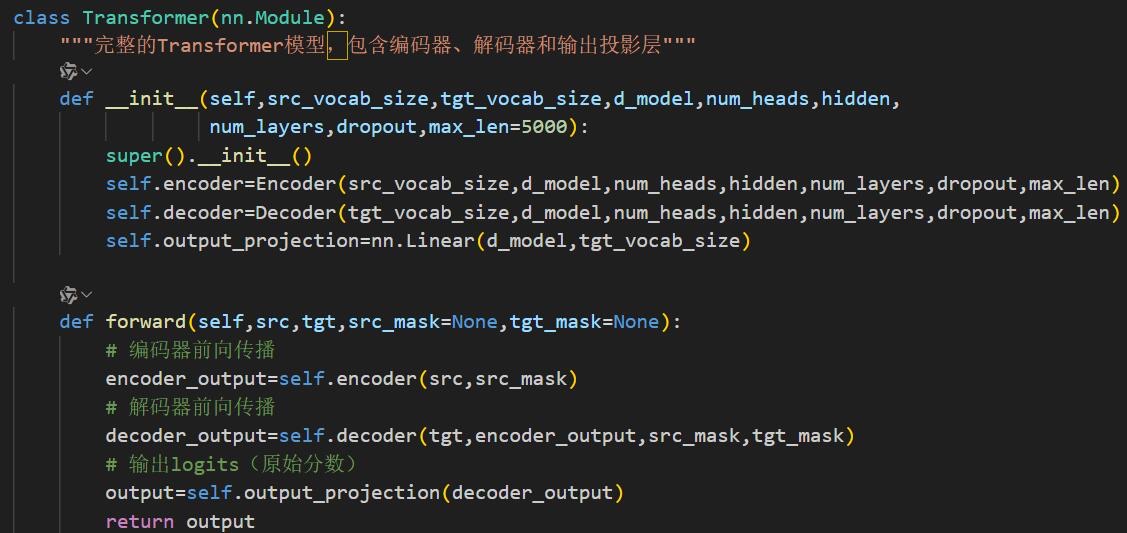
5️⃣完整Transformer
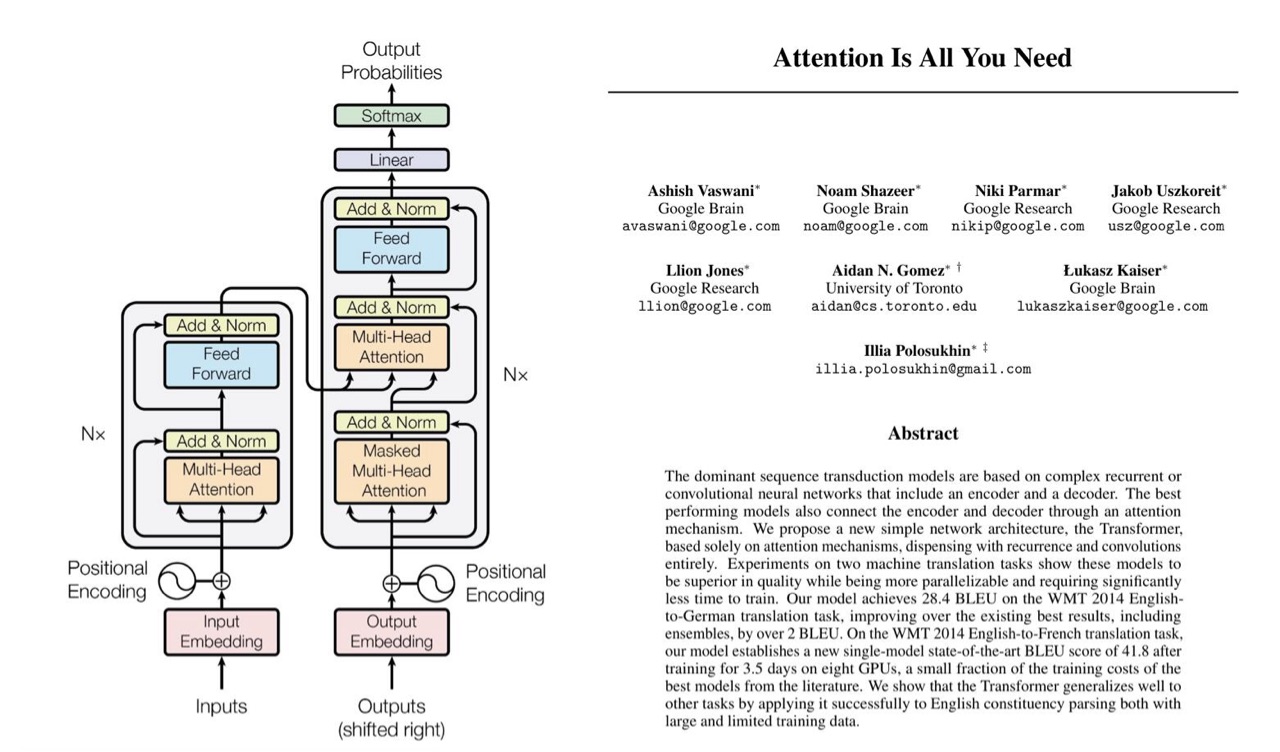
Transformer层:编码器将源序列编码为上下文记忆,解码器在训练时并行处理、推理时自回归生成,最终通过线性层与Softmax输出词概率分布
流程:输入经Encoder编码→Decoder接收目标序列与Encoder输出,通过交叉注意力建立关联→输出投影层得到概率分布


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)