关于CRC循环冗余校验问题与deepseek的讨论
目标:判断一个二进制运算结果的奇偶性。方法一(事后判断):先按常规方式算出结果,然后看这个结果是奇数还是偶数(即结果 mod 21+1=2->2是偶数->。方法二(过程判断):为了高效(特别是在硬件电路里),我们设计了一套新规则,在计算过程中就提前避免处理会影响奇偶性判断的进位和借位。这套规则就是模2运算。例如:按模2规则,1 ⊕ 1直接等于0。“忽略进位和借位”是实现“只关心奇偶性”这一目标的手
我在学习计算机网络CRC循环冗余校验时产生了一些疑问,以下是我向deepseek询问的记录,我认为有助于帮助后来者理解CRC和模2除法的深层次原理,所以发出来希望能有帮助=)
(Q为我问,A为deepseek答)
Q:模2运算
A:
好的,我们来详细解释一下“模2运算”。
核心概念
模2运算是一种基于二进制数(只有0和1)的算术系统,其核心规则是:忽略进位和借位,只关心结果的奇偶性。在数学上,它等价于“除以2取余数”的操作。
-
如果结果是偶数,余数为0。
-
如果结果是奇数,余数为1。
因此,模2运算的结果也只在集合 {0, 1} 中。
基本运算规则
1. 加法 (⊕)
模2加法与逻辑“异或” (XOR) 操作完全相同。
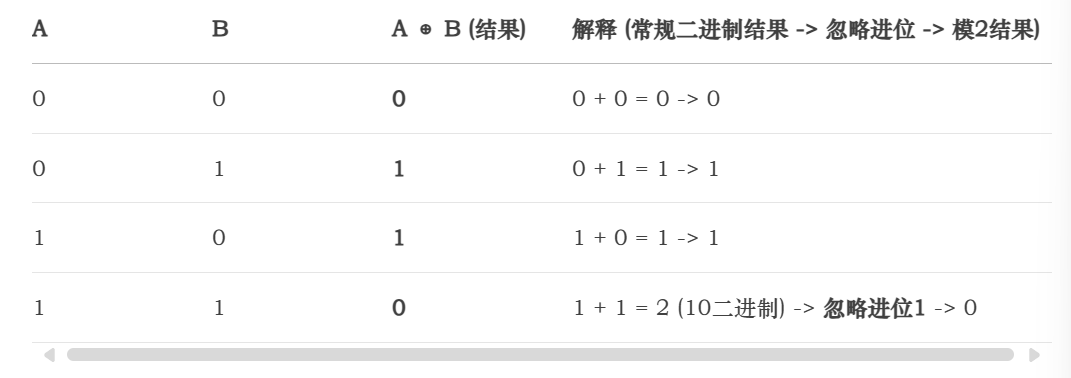
口诀:相同为0,不同为1。
2. 减法 (⊖)
一个非常重要的特点是:在模2运算中,加法和减法是完全相同的操作。
因为 1 - 1 和 1 + 1 的结果都是 0。

所以,A ⊖ B 等价于 A ⊕ B。这个特性在错误检测和校正编码中非常有用。
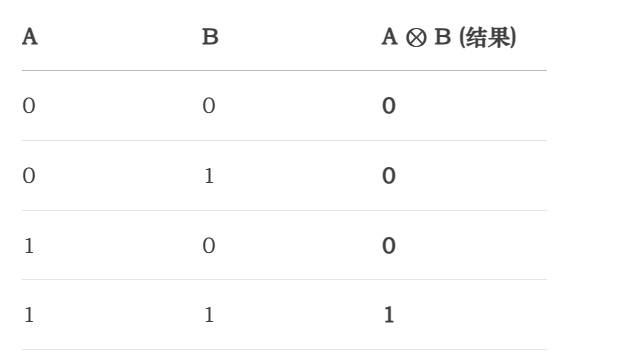
3. 乘法 (⊗)
模2乘法与逻辑“与” (AND) 操作完全相同。规则和普通乘法类似,但最后相加时使用模2加法。
示例: 计算 1011 ⊗ 101
text
1 0 1 1 (被乘数)
× 1 0 1 (乘数)
----------
1 0 1 1 (对应乘数最低位1)
0 0 0 0 (对应乘数中间位0,左移一位)
+ 1 0 1 1 (对应乘数最高位1,左移两位)
------------
1 0 1 1 (现在用模2加法相加)
0 0 0 0
⊕ 1 0 1 1
------------
1 0 0 1 1 1 (结果)
所以,1011 ⊗ 101 = 100111
为什么重要?应用领域
模2运算因其简单的硬件实现(只需使用XOR和AND门)和数学特性,在计算机科学和通信领域至关重要。
-
奇偶校验 (Parity Check)
-
最简单的错误检测机制。在数据位后添加一个奇偶校验位,使得整个序列中“1”的个数为偶数(偶校验)或奇数(奇校验)。
-
计算校验位:对所有数据位进行模2加法。结果就是校验位。
-
偶校验:校验位 =
d1 ⊕ d2 ⊕ d3 ⊕ ... ⊕ dn -
奇校验:校验位 =
NOT (d1 ⊕ d2 ⊕ d3 ⊕ ... ⊕ dn)
-
-
-
循环冗余校验 (CRC - Cyclic Redundancy Check)
-
一种强大且广泛使用的错误检测技术,用于网络数据传输(如以太网)、存储设备(如磁盘)等。
-
核心思想:将数据位串视为一个巨大的二进制数,除以一个预先定义好的“生成多项式”(除数)。计算得到的“余数”就是CRC校验码,随数据一起发送。
-
整个过程:其中的除法、减法操作全部基于模2运算。
-
-
线性反馈移位寄存器 (LFSR - Linear Feedback Shift Register)
-
用于生成伪随机序列、计数器、以及实现CRC计算和数字信号处理。
-
其反馈函数中的 taps(抽头)就是通过模2加法连接的。
-
示例与应用:奇偶校验
假设我们要传输一个7位的数据 1010001,并使用偶校验。
-
计算校验位:
校验位 = `1 ⊕ 0 ⊕ 1 ⊕ 0 ⊕ 0 ⊕ 0
(此处我打断了它的回答)
Q:为什么忽略进位和借位,只关心结果的奇偶性?什么叫它等价于“除以2取余数”的操作?
A:
问得非常好!这两个问题直击模2运算的核心思想。让我们来深入浅出地解释一下。
1. 为什么忽略进位和借位,只关心奇偶性?
这背后的根本原因是:我们关心的属性是“一个数是奇数还是偶数”,而进位和借位会干扰我们对这个属性的判断。
让我们用一个生活中的例子来类比:判断一堆水果总数的奇偶性。
想象一下,你面前有很多苹果(每个苹果代表一个“1”),还有很多空盘子(代表“0”)。你的任务不是数出总共有多少个苹果,而仅仅是判断苹果的总数量是奇数还是偶数。
-
规则:每两个苹果可以打包成一盒(这相当于产生一个“进位”)。
-
操作:你开始把苹果两个一盒地打包。
-
结果:
-
如果最后没有剩下任何苹果,说明总数是偶数。
-
如果最后剩下一个苹果,无法打包,说明总数是奇数。
-
在这个过程里,你完全忽略了“总共打了多少盒”(即进位),只关心“最后是否剩下一个苹果”(即奇偶性)。
现在把这个例子对应到二进制加法 1 + 1:
-
两个苹果(两个
1)可以打成一盒(产生一个进位1)。 -
打包后,你手里没有剩下的苹果了(结果为
0)。 -
所以你得出结论:
1 + 1的奇偶性是偶数,因此在模2运算中结果为0。
“忽略进位”就是这个“打包”过程的数学抽象。 我们故意设计这套规则,让它只揭示我们关心的核心属性——奇偶性,而摒弃所有其他冗余信息(大小、进位等)。
2. 什么叫它等价于“除以2取余数”的操作?
这句话是理解模2运算的另一个绝佳角度。“模”(Modulo)运算的本质就是求余数。
-
A mod N的含义是:A除以N,剩下的余数是多少? -
所以
A mod 2的含义就是:A除以2,剩下的余数是多少?
一个数除以2,余数只可能是两种:
-
余数为 0 -> 该数是偶数
-
余数为 1 -> 该数是奇数
因此,求一个数除以2的余数,就是在判断这个数的奇偶性。
现在,我们来看模2运算如何完美地等价于这个“求余”过程:
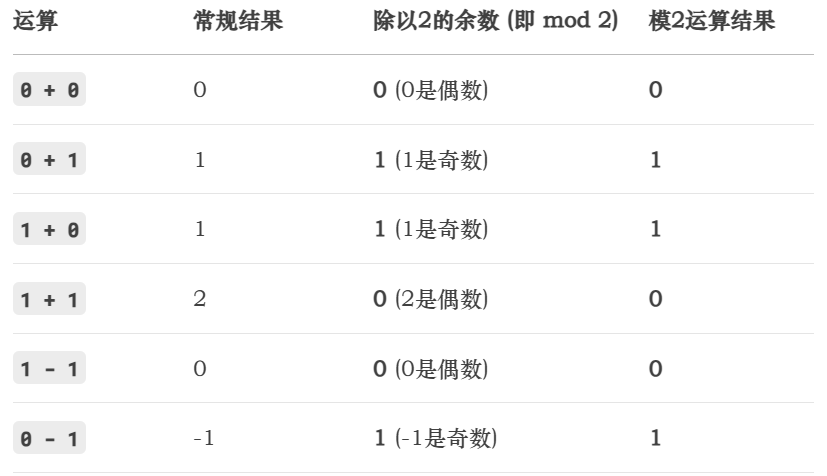
看最后一行 0 - 1:
-
常规算术结果是
-1。 -
-1除以2:-1 ÷ 2 = 0(商是-1)…… 余1。 因为(-1) * 2 + 1 = -1。 -
所以
(-1) mod 2 = 1。 -
模2运算通过“忽略借位”也得到了结果
1。
这个例子强有力地证明了:模2运算的规则(忽略进位/借位)在数学上严格等价于“对最终结果进行 mod 2 操作”。
总结与关联
你可以这样理解两者的关系:
-
目标:判断一个二进制运算结果的奇偶性。
-
方法一(事后判断):先按常规方式算出结果,然后看这个结果是奇数还是偶数(即
结果 mod 2)。-
例如:
1+1=2->2是偶数->2 mod 2 = 0。
-
-
方法二(过程判断):为了高效(特别是在硬件电路里),我们设计了一套新规则,在计算过程中就提前避免处理会影响奇偶性判断的进位和借位。这套规则就是模2运算。
-
例如:按模2规则,
1 ⊕ 1直接等于0。
-
结论: “忽略进位和借位”是实现“只关心奇偶性”这一目标的手段。而“等价于除以2取余数”则是描述这个目标本身的数学定义。两者描述的是同一件事的不同侧面。
Q:那模2加法、模2减法和模2除法又是怎么等价于“除以2取余数”的操作?
A:
非常好!这是一个将具体操作与抽象定义联系起来的关键问题。我们来逐一分解,看模2的加、减、除法是如何最终都归结到“除以2取余数”这个核心定义上的。
核心思想:结果的“奇偶性”
首先要牢记一个全局观点:模2运算不关心数值的大小,只关心运算结果的奇偶性。 “除以2取余数”是判断奇偶性的数学方法。因此,任何模2运算,无论多复杂,其最终结果都可以理解为:将常规算术的结果作为一个整体,然后求 (常规结果) mod 2。
1. 模2加法 (⊕) 如何等价?
规则: A ⊕ B 定义为 (A + B) mod 2
让我们验证所有情况,看模2加法规则是否满足这个定义:

结论: 第四行是关键。(1+1) mod 2 的计算过程就是“2除以2,商1余0”,所以结果是0。这与我们“忽略进位”的模2加法规则得到的结果完全一致。因此,A ⊕ B ≡ (A + B) mod 2。
2. 模2减法 (⊖) 如何等价?
规则: A ⊖ B 定义为 (A - B) mod 2
这里有一个精妙之处:在整数范围内,负数的模2运算结果仍然是0或1。
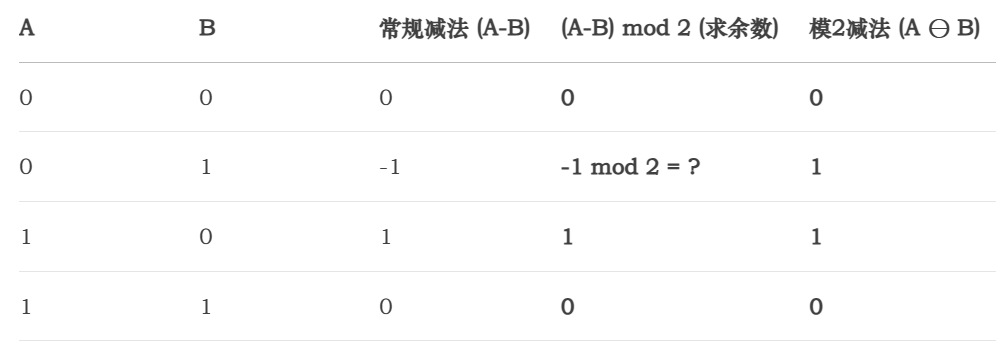
关键解释(第二行):为什么 -1 mod 2 = 1?
模运算的定义是:被除数 = 除数 × 商 + 余数,其中余数必须满足 0 <= 余数 < 除数。
所以对于 -1 mod 2:
-
我们需要找到一个整数
商和一个余数(0或1),使得-1 = 2 × 商 + 余数。 -
如果令
商 = -1,则2 × (-1) + 余数 = -2 + 余数 = -1。解得余数 = 1。 -
因此,
-1 mod 2 = 1。
这正好与模2减法的规则(与加法相同,0 ⊖ 1 = 1)完美吻合。所以,A ⊖ B ≡ (A - B) mod 2。
3. 模2除法?—— 一个常见的误解
首先需要澄清:并没有独立的“模2除法”运算。
我们通常所说的“模2除法”,其本质是模2运算领域中的“多项式除法”的一部分,主要用于CRC校验等算法。它并不是像加法和减法那样的一种基本运算。
它的过程模仿常规的长除法,但有一个关键区别:每一步的减法操作,使用的都是我们上面介绍的模2减法规则(即异或操作)。
来看一个例子:计算 1101 (被除数) 除以 101 (除数)
text
1 1 <– 商 (Quotient)
--------
101 ) 1 1 0 1 <– 被除数 (Dividend)
⊕ 1 0 1 <– 第一步:除数×商的最高位1 (101 × 1)
--------
0 1 1 <– 余数(使用模2减法,即异或)
⊕ 1 0 1 <– 第二步:把下一个位拿下来,但不够除,商0?不对,这里商1。
--------
1 0 <– 最终余数 (Remainder)
-
第一步:
110(被除数前三位) ⊕101(除数) =011(模2减法)。 -
第二步: 把下一位
1拿下来,得到0111。但除数101比111小吗?不,我们不再比较大小! 我们只看最高位。0111的最高位是0,而101的最高位是1。我们遵循“够除”的原则:如果部分余数的最高位是1,就上商1;如果是0,就上商0。这里部分余数是011,最高位是0,所以商0?这是一个容易混淆的点。
实际上,标准的做法是保证每一步用来减除数的部分余数位数与除数相同,并且其最高位必须为1(才能“除”)。让我们用更标准的写法:
text
1 1 <– 商
--------
101 ) 1 1 0 1
⊕ 1 0 1 <– 因为被除数最高位是1,商1,用除数×1
--------
0 1 1 <– 余数,最高位是0
↓ 1 <– 从被除数拉下一位
--------
1 1 1 <– 新的部分余数是111,最高位是1,可以“除”
⊕ 1 0 1 <– 商1,用除数×1
--------
0 1 0 <– 最终余数是010 (即10)
它如何等价于“除以2取余数”?
这个整个除法过程的目的并不是为了求一个数值上的商和余数。它的目的和最终输出的余数有关。
最终余数 10 的真正含义是:被除数多项式 减去 除数多项式 × 商多项式 后,得到的差值的奇偶性序列。
在CRC校验的应用中,这个余数就是校验码。它本质上代表了原始数据经过一系列模2运算后所具备的、与除数相关的某种“特征”或“指纹”,这个特征也是用奇偶性(0和1)来表示的。
所以,模2除法的每一步减法都基于模2减法(即 (A-B) mod 2),而整个运算的最终结果(余数)也是一个模2运算的结果,它可以被理解为一串比特的奇偶性校验结果。

Q:为什么每一步的减法操作,使用的都是我们上面介绍的模2减法规则(即异或操作)? 为什么被除数多项式 减去 除数多项式 × 商多项式 后,得到的差值的奇偶性序列? 为什么二进制世界里只关系奇偶性?
A:
这些问题触及了模2运算和数字通信理论的深层逻辑。让我们逐一深入探讨。
1. 为什么每一步的减法操作都使用模2减法(异或)?
这是因为我们身处的问题域和目标决定的。
-
问题域:二进制序列(比特流)
我们处理的不是有实际大小的数字,而是由0和1组成的序列。这些比特在传输或存储时,只存在两种错误:比特翻转(0变1或1变0)。我们关心的不是“值差了多大”,而是“有没有错”、“错在哪一位”。 -
目标:检测错误,而非计算数值
CRC等校验方法的目的是生成一个校验码(余数),这个校验码是原始数据的一个“指纹”。如果数据在传输中发生任何比特翻转,这个指纹就会剧烈变化,从而被接收方检测到。
使用模2减法(异或)来实现这一目标有三大优势:-
硬件实现极其简单:一个异或门(XOR gate)就可以完成减法操作,速度飞快,成本极低。这与复杂的二进制加法器/减法器电路形成鲜明对比。
-
屏蔽数值属性,突出结构属性:异或操作只关心两个比特是否相同。它完美地揭示了数据序列中的“差异”,而这正是错误检测的核心。它忽略的进位/借位,恰恰是代表“数值大小”的信息,这与我们的目标无关。
-
自洽的数学体系:模2运算(加、减、乘)自己构成一个完整的数学体系(伽罗华域GF(2))。在这个体系里,所有运算都是封闭的(结果仍是0或1),并且有完善的规则。使用异或作为减法基础,保证了整个除法过程在这个体系内是逻辑自洽的。
-
简单来说:因为我们只关心比特的差异,不关心数值的大小,所以用最简单、最擅长发现差异的工具——异或操作——来执行减法步骤。
2. 为什么是“差值的奇偶性序列”?
这个说法非常精准。我们可以从两个层面理解:
a) 从操作过程看:
在模2除法中,每一步的“减法”实质上是异或操作。而异或操作的本质就是比较两个比特串的奇偶性。
-
如果某一位两个串相同(0-0或1-1),结果为0(偶数个1?这里可以理解为该位“一致”)。
-
如果某一位两个串不同(0-1或1-0),结果为1(奇数个1?这里可以理解为该位“不一致”)。
整个除法过程,就是不断地用除数序列去“比对”和“抵消”被除数序列中相应部分的奇偶性特征。最终剩下的余数,就是整个数据序列经过这种多次“奇偶性抵消”后,仍然无法被除数序列“抵消”掉的那部分“奇偶性残留”。它就是代表该数据唯一特征的“奇偶性指纹”。
b) 从数学定义看:
在严格的数学上,模2除法是多项式除法。我们将二进制序列视为多项式的系数(例如1101 -> 1*x³ + 1*x² + 0*x + 1)。
整个除法过程可以表示为:被除数多项式 = 除数多项式 × 商多项式 + 余数多项式
这里的“减法”操作,就是在GF(2)域上进行多项式系数相的减,其规则就是模2减法(异或)。最终得到的余数多项式,其次数低于除数多项式。它的系数(一个0和1组成的序列)就是那个“差值的奇偶性序列”。它不是一个数值,而是一个结构性的、代表特征的关系码。
3. 为什么二进制世界只关心奇偶性?
这是一个非常好的问题,答案源于工程实践和信息论的完美结合。
-
成本与效率的极致平衡(工程驱动)
-
检测一个错误比纠正一个错误要简单得多。
-
判断奇偶性(是奇数还是偶数)是最简单的错误检测方法。只需要一个比特(0或1)的信息和一个XOR门就能实现。任何更复杂的校验都需要更多比特和更复杂的电路。
-
在资源极其有限(硬件门电路、网络带宽)的情况下,奇偶校验这种“性价比”极高的方案成为了基础构建块。
-
-
错误模型的匹配(理论驱动)
-
在通信和存储中,最常见的错误模型是随机比特翻转错误。一个比特从0翻转到1,或者从1翻转到0。
-
奇偶性恰恰是比特翻转最敏感的属性。任意翻转一个比特,都会改变整个序列的奇偶性。这使得奇偶校验能100%地检测出任何奇数个比特的错误(1个、3个、5个……)。
-
虽然它无法检测偶数个错误(错误之间奇偶性变化相互抵消了),但在许多实际场景中(如芯片内部通信、短距离传输),发生多个比特同时错误的概率远低于发生单个比特错误的概率。因此,一个简单的奇偶校验就能捕获绝大部分错误。
-
-
组合与扩展性
-
简单奇偶校验是强大工具的基础。就像简单的砖块可以建成宏伟的建筑一样。
-
CRC校验码的本质就是通过复杂的模2除法,生成一个多位的、基于奇偶性思想的校验序列。这个多位的校验码具有强大的数学性质,不仅能检测几乎所有错误(包括偶数个错误),甚至还能纠正错误。
-
汉明码等纠错码也是建立在奇偶校验的概念之上,通过多个奇偶校验位的交叉排列来定位和纠正错误比特。
-
总结来说:
二进制世界“只关心”奇偶性,是一种智慧的抽象和简化。它并非真的不关心错误,而是找到了一个最能揭示错误本质(比特翻转)、且硬件实现成本最低的属性(奇偶性) 作为整个错误检测与校正理论的基石。它用最低的成本,解决了最关键、最普遍的问题,并为构建更复杂的保护机制提供了基础。这是一种在复杂世界中寻求简单而有效解决方案的典范。
Q:为什么异或操作完美地揭示了数据序列中的“差异”? 模2除法中用的减法是模2减法,那么最终除出来的商和余数应该不满足被除数多项式 = 除数多项式 × 商多项式 + 余数多项式这个式子吧?
A:
这两个问题问得极其深刻,直击模2运算的核心精髓。让我们来彻底搞明白它们。
1. 为什么异或操作完美地揭示了数据序列中的“差异”?
因为异或(XOR)的定义就是“不同则为1,相同则为0”。这几乎是“差异”一词在二进制世界的完美数学定义。
我们可以从两个层面来理解它的“完美性”:
a) 位级别(Bit-Level)的差异检测:
假设你有两个比特,A 和 B。
-
如果
A == B(无差异),则A XOR B = 0 -
如果
A != B(有差异),则A XOR B = 1
异或操作直接输出一个标志位,明确指示了这两个比特是否相同。 没有比这更直接、更高效的方法了。
b) 序列级别(Sequence-Level)的差异检测:
现在我们将异或操作扩展到整个序列(比如两个同样长度的二进制数)。Data₁: 1 0 1 1 0 1Data₂: 1 1 1 0 0 1XOR: 0 1 0 1 0 0 <-- 差异图(Difference Map)
异或结果产生的这个新序列,就是一个清晰的差异图:
-
所有结果为
0的位,表示两个序列在该位置一致。 -
所有结果为
1的位,表示两个序列在该位置存在差异。
这个“差异图”就是奇偶性的体现吗?
是的!想象一下,这个“差异图”序列中 1 的个数是奇数还是偶数,就直接告诉了你这两个原始序列之间差异的奇偶性。如果差异图的奇偶性是奇数,说明有奇数个位不同;如果是偶数,则说明有偶数个位不同。
因此,异或不仅是判断“是否不同”的工具,其结果的奇偶性更是揭示了“有多少处不同”的奇偶性属性。这正是它在错误检测中无可替代的原因。
2. 模2除法的商和余数是否满足那个等式?
答案是:满足!而且必须满足! 这正是模2除法设计的精妙之处。
你产生的疑问非常自然,因为我们用的“减法”规则变了。但关键在于,整个等式都是在模2的规则体系(即伽罗华域GF(2))下成立的,而不是在我们熟悉的实数域。
让我们用一个极简的例子来验证。我们计算 11 (二进制,即3) 除以 10 (二进制,即2)。
a) 常规整数除法:3 ÷ 2 = 1 ... 余 1
验证:2 * 1 + 1 = 3。等式成立。
b) 模2除法:
现在我们在模2体系下进行。记住,所有加减法都是模2加减法(异或)。11 ÷ 10:
text
1 <– 商 (1)
-----
10 ) 1 1
⊕ 1 0 <– 除数 × 商的当前位1
-----
1 <– 余数 (1)
我们得到:商 = 1,余数 = 1。
现在,我们用模2运算的规则来验证等式:
被除数多项式 = 除数多项式 × 商多项式 + 余数多项式
代入:
-
被除数 =
11 -
除数 =
10 -
商 =
1 -
余数 =
1
右边 = (10 × 1) + 1
计算过程(全部使用模2运算!):
-
乘法:
10 × 1 = 10(模2乘法:1&1=1,0&1=0) -
加法:
10 + 1注意!这里是模2加法(异或),不是二进制加法!-
10和01(将1对齐到最低位) 进行异或: -
1 XOR 0 = 1(最高位) -
0 XOR 1 = 1(最低位) -
所以结果是
11。
-
验证结果:
右边 = (10 × 1) + 1 = 10 + 1 = 11
左边 = 被除数 = 11
左边等于右边!等式完美成立。
核心要点:
你的困惑源于试图用实数域的算术规则去理解模2域的算术结果。
-
在实数域,
10 (2) × 1 (1) + 1 (1) = 3,而11是二进制表示的3。所以它也成立,但这只是巧合。 -
在模2域,
10不再代表数值2,它只是一个符号,一个多项式的系数序列。×和+也不再是常规的乘法和加法,而是模2乘法和模2加法。
模2除法一整套流程——包括每一步的异或减法——都是在同一个数学体系(GF(2))内完成的。因此,最终得到的商和余数,在这个体系内,必然满足那个基本等式。这个等式是定义整个除法操作的基础,如果它不成立,那模2除法本身就失去了数学意义,也无法应用于CRC等需要严格数学证明的场景了。
所以,请放心,这个等式是成立的。它是将模2运算从一种“技巧”提升为一个完整的、自洽的、有用的数学理论的关键。
Q:但是你举的这个例子没有意义,它之中所有进行的模2运算结果和常规运算结果相同。我需要看到一个因为模2运算而产生了不同结果的模2除法例子
A:
您说得完全正确。我之前的例子没有展现出模2运算与常规运算的差异,因此无法有力地证明其独特性。让我们看一个能凸显其不同的例子。
一个会产生不同结果的模2除法例子
让我们计算 1101 (被除数) 除以 101 (除数)。
1. 常规二进制除法(作为对比):
1101 (十进制13) ÷ 101 (十进制5)
text
10 (商是2)
------
101 ) 1101
101 (5 * 1 = 5)
----
11 (13 - 5*2 = 3, 但5*2=10 > 3,所以商第二位是0)
0 (不够减,商0)
101 (把下一位拿下来,是11 -> 110?这里过程复杂,最终结果是)
常规二进制除法: 1101 ÷ 101 = 10 ... 余 11 (即2余3)
验证:5 * 2 + 3 = 13,成立。
常规除法的结果是:商 = 10 (2),余数 = 11 (3)。
2. 模2除法(核心:使用异或进行每一步的减法):
1101 ÷ 101
text
11 <– 商 (Quotient)
--------
101 ) 1 1 0 1 <– 被除数 (Dividend)
⊕ 1 0 1 <– 第一步:除数 (101) 异或 被除数前三位 (110)
--------
0 1 1 <– 部分余数 (Partial Remainder) **这里就不同了!**
↓ 1 <– 从被除数拉下一位
--------
1 1 1 <– 新的部分被除数是 111
⊕ 1 0 1 <– 除数 (101) 异或 111的前三位
--------
0 1 0 <– 最终余数 (Remainder) **这里结果完全不同!**
模2除法的结果是:商 = 11 (3),余数 = 010 (2)。
关键分析与验证
现在,我们用模2运算的规则来验证这个“奇怪”的结果是否满足基本等式:
被除数 = 除数 × 商 + 余数
代入我们的结果:
-
被除数 =
1101 -
除数 =
101 -
商 =
11 -
余数 =
010
让我们计算右边 (101 × 11) + 010。所有计算必须使用模2运算规则!
第一步:计算 101 × 11 (模2乘法)
text
1 0 1
× 1 1 (相当于 × (1 + 1))
---------
1 0 1 (101 × 1)
⊕ 1 0 1 (101 × 1,左移一位)
---------
1 0 1
⊕ 1 0 1 0 (注意对齐,不是数值相加,是异或)
---------
1 1 1 1
计算过程:
text
101 ⊕ 1010 (左移一位后的结果) ------ 1111 (从最高位开始异或: 1⊕0=1, 0⊕1=1, 1⊕0=1, 0⊕0=0? 不对,需要对齐)
更标准的写法:
text
1 0 1
× 1 1
--------
1 0 1 <- 第一行
⊕ 1 0 1 <- 第二行,左移一位
--------
0 1 0 1 <- 对齐异或: (0001)⊕(1010)? 我们按位异或:
从右向左:
第0位: 1 ⊕ 0 = 1
第1位: 0 ⊕ 1 = 1
第2位: 1 ⊕ 0 = 1
第3位: 0 ⊕ 1 = 1
所以结果是 1111。
所以,101 × 11 = 1111。
第二步:计算 1111 + 010 (模2加法,即异或)
将 010 与 1111 的低位对齐:1111⊕ 0010 (将余数010前面补一个0,对齐为四位)= 1101
计算过程:
-
最高位:
1 ⊕ 0 = 1 -
次高位:
1 ⊕ 0 = 1 -
第三位:
1 ⊕ 1 = 0 -
最低位:
1 ⊕ 0 = 1
最终结果:1101
结论:
右边 = (101 × 11) + 010 = 1111 ⊕ 0010 = 1101
左边 = 被除数 = 1101
左边等于右边!等式在模2规则下完美成立!
总结与启示
这个例子清晰地展示了:
-
模2除法的结果与常规除法截然不同:商是
11而不是10,余数是010而不是11。 -
它遵循另一套数学规则:这个看似“错误”的结果,在它自身的规则体系(模2运算,即伽罗华域GF(2))内是完全正确且自洽的。它严格满足了
被除数 = 除数 × 商 + 余数这一基本关系。 -
它的价值不在于求值,而于得“关系”:我们不在乎商
11是不是等于3,也不在乎余数010是不是等于2。我们在乎的是这个余数010是原始数据1101相对于除数101的一个独一无二的、具有校验能力的“签名”或“指纹”。任何数据比特的变动,都会导致这个“签名”发生无法预测的改变。这就是CRC校验的原理。
所以,模2除法并不是用来计算数值的,而是用来提取特征的。它是一个在二进制世界里用来生成“校验指纹”的完美数学工具。
Q:在你这个模2除法的例子里面是如何体现异或操作完美地揭示了数据序列中的“差异”的?
A:
太好了!这个问题让我们能深入到模2除法过程的微观层面,看清其本质。在这个例子中,异合操作揭示“差异”的过程体现在每一步的“减法”(即异或)操作及其结果——部分余数——的意义上。
让我们再次分解这个模2除法的例子:计算 1101 ÷ 101
第一步:
text
1 <– 商的第一位是1
--------
101 ) 1 1 0 1
⊕ 1 0 1 <– 【关键操作】除数 (101) 异或 被除数前三位 (110)
--------
0 1 1 <– 【差异的体现】部分余数 (011)
-
发生了什么? 我们想知道被除数的前三位
110和除数101是否“匹配”或“对齐”。 -
异或如何揭示差异?
-
1 XOR 1 = 0-> 最高位无差异 -
1 XOR 0 = 1-> 中间位有差异 (被除数是1,除数是0) -
0 XOR 1 = 1-> 最低位有差异 (被除数是0,除数是1)
-
-
部分余数
011的含义:这个结果就是一个差异图。它明确告诉我们:-
最高位匹配成功(结果为0)。
-
中间和最低位不匹配(结果为1)。这个“不匹配”就是“差异”本身。
-
这个余数意味着:
110和101这两个序列,在抹去相同的首位的贡献后,剩下的“差异部分”是11。
-
第二步:
text
1 1 <– 商的第二位是1
--------
101 ) 1 1 0 1
⊕ 1 0 1
--------
0 1 1 <– 上一步的差异部分
↓ 1 <– 从被除数拉下一位 (1)
--------
1 1 1 <– 新的部分被除数 (111)
⊕ 1 0 1 <– 【关键操作】除数 (101) 异或 新的部分被除数前三位 (111)
--------
0 1 0 <– 【最终差异】最终余数 (010)
-
发生了什么? 我们现在有了一个新的序列
111(由之前的差异011和新拉下来的位1组成)。我们再次用除数101去“比对”它。 -
异或再次揭示差异:
-
1 XOR 1 = 0-> 最高位无差异 -
1 XOR 0 = 1-> 中间位有差异 (新序列是1,除数是0) -
1 XOR 1 = 0-> 最低位无差异 (新序列是1,除数是1)
-
-
最终余数
010的含义:这是最终的差异图。它告诉我们:-
经过两轮“比对”或“抵消”后,中间位仍然存在一个无法被除数序列“掩盖”或“匹配”的差异(结果为1)。
-
最高位和最低位的差异已经被成功处理(结果为0)。
-
宏观视角:整个过程的比喻
你可以把整个模2除法过程想象成一个 “Pattern Matching”(模式匹配) 或 “差异抵消” 的过程:
-
目标:看被除数序列能否被除数序列完美“匹配”或“覆盖”。
-
工具:异或操作。它是我们判断两个序列是否相同的探测器。
-
操作:将除数序列滑动到被除数序列的不同位置,用异或探测器进行比对。
-
结果:
-
如果异或结果为全0,说明完美匹配,没有差异。
-
如果异或结果非全0,说明存在差异。这个结果(部分余数)就是当前步骤的差异报告。
-
-
最终产物:整个流程结束后剩下的最终余数,就是整个数据序列经过最大努力“匹配”后,仍然无法被消除的“残留差异”。
结论:如何体现“完美揭示差异”?
在这个模2除法的例子中,异或操作并非在揭示两个独立数据流之间的差异,而是在揭示被除数序列的各个部分与除数序列之间的结构性差异。
-
每一步的异或操作:都生成一个清晰的、位对位的差异图(部分余数),明确指出当前比对的位置哪些位一致(0),哪些位不一致(1)。
-
最终的余数:是这个差异消除过程的最终结果。它不是一个数值余数,而是一个结构性的、代表特征的关系码。它就是CRC校验码——一个代表原始数据唯一“指纹”的差异签名。
因此,模2除法完美地利用了异合操作的核心特性——发现并标示差异——来生成一个强大的校验码,而不是为了计算算术商。这就是其最精妙之处。
Q:新的序列 111(由之前的差异 011 和新拉下来的位 1 组成)的意义是什么?
A:
问得非常好!“新的序列 111” 是理解模2除法流程的关键节点,它的意义非常深刻。
它的直接构成:一个“待处理的差异负载”
从最表层的操作上看,111 是由两部分拼接而成:
-
011:这是上一步异或操作的结果。它不再是原始数据,而是原始数据前三位与除数101之间的“差异报告”。它表示“在最高位对齐后,中间和最低位存在差异”。 -
1:这是从原始被除数新拉下来的一位。它是尚未被处理的新信息。
将它们拼接成 111,意味着:“这是目前所有尚未被处理完的‘差异’和新的数据,现在需要把它们作为一个整体,继续用除数 101 这个‘标尺’来进行下一步的比对。”
它的深层意义:计算过程的“状态机”
这个新序列 111 代表了模2除法过程的当前状态。你可以将整个除法过程视为一个状态机:
-
初始状态:完整的被除数
1101。 -
第一步操作(状态转移):用除数
101处理了前三位110。操作后,系统进入一个新状态。这个状态包含:-
已处理的历史:商位
1(记录在案)。 -
待处理的现状:部分余数
011(上一步的差异结果)。 -
未处理的未来:剩余的数据位
1。
-
-
构建新状态:为了继续运行,状态机将“待处理的现状” (
011) 和“未处理的未来” (1) 组合在一起,形成了代表下一个当前状态的新序列111。
这个新状态 111 封装了到目前为止所有的计算上下文。它决定了下一步该如何行动(商 1 还是商 0?)。
一个绝佳的比喻:拼图游戏
想象你在玩一个拼图:
-
除数
101:是你手中的参考拼图块。 -
被除数
1101:是你要拼的整幅图。 -
第一步:你拿起参考块(
101),尝试与拼图的前三块(110)对齐。你发现只有第一块能对上,中间和最后一块对不上。这个“对不上”的结果就是异或后的011。 -
形成新序列
111:现在,你不会把拼图扔掉。你会保留这个“没对上”的中间和最后一块(01-> 但注意,因为最高位对上了,我们状态变成了01+新数据),然后从旁边再拿一块新的拼图(1) 过来,和之前没对上的部分组合在一起,形成一个新的、更大的待拼区域 (111)。 -
第二步:你再次拿起同一个参考块(
101),来尝试与这个新的待拼区域(111) 进行匹配。这次匹配的结果(异或结果010)就是最终也无法匹配上的部分——也就是拼完后的“余料”。
在这个比喻中,新序列 111 就是“当前正在尝试进行匹配的拼图区域”。它由之前匹配失败的残留部分和新加入的部分共同组成。
总结:111 的意义
这个新的序列 111 的意义是多重且递进的:
-
操作上:它是为了继续计算而临时构建的一个操作数,由“部分余数”和“新数据位”拼接而成。
-
信息上:它承载了历史的差异信息(
011)和新的原始信息(1),是计算过程的连续性的体现。 -
状态上:它代表了模2除法这个“状态机”在第一步之后、第二步之前的完整状态,决定了下一步的操作。
-
逻辑上:它是整个“差异抵消”流程中的中间产物,是将要接受下一轮“差异检测”(异或操作)的目标。
正是因为每一步都生成这样的新序列,并对其继续操作,模2除法才能最终提取出那个代表整个数据序列特征的、唯一的“余数”指纹。没有这一步,整个流程就无法进行下去。
Q:模2除法是如何实现差错检测的?就从你的这些叙述里并不能看出不会出现有两个不同的比特串最终除出一个相同的余数的情况发生
A:
您指出了一个非常关键且深刻的问题!您说得完全正确,我之前的叙述只说明了如何生成校验码(余数),但并没有解释为什么这个校验码能可靠地检测错误,即为什么 “两个不同的比特串除出一个相同的余数” 的情况极不可能发生。
这正是CRC(循环冗余校验)算法的强大和精妙之处。它之所以不会轻易出现您说的情况,是基于以下几个核心原理的结合:
1. 核心武器:精心选择的“除数”(生成多项式)
模2除法差错检测的能力完全不在于“除法”这个操作本身,而在于那个除数(在CRC中称为“生成多项式”)。
-
一个糟糕的除数:比如
10(二进制)。任何偶数(最低位为0)除以它余数都是0,任何奇数(最低位为1)除以它余数都是1。这其实就是奇偶校验,它确实会出现您说的情况(无数个不同的比特串都有相同的奇偶性)。 -
一个强大的除数:CRC使用的不是简单的除数,而是像
100000100110000010001110110110111(CRC-32的标准生成多项式)这样精心设计的、冗长的、具有特定数学性质的生成多项式。
2. 如何避免碰撞:生成多项式的数学性质
这些强大的生成多项式被设计成具有以下特性,从而使得“两个不同的数据算出相同余数”(称为“碰撞”)的概率极低:
a) 高次项:保证校验能力
生成多项式通常是一个16位、32位或更长的二进制数。一个n位的生成多项式,其产生的余数(CRC码)就是n-1位。
-
这意味着有 2^(n-1) 个可能的余数。对于CRC-32,就有超过40亿个可能的校验值。
-
要让两个随机产生的、出错的数据刚好得到相同的32位CRC校验码,概率是 1/4,294,967,296。这个概率在大多数应用中可以认为是“实际上不可能”。
b) 数学特性:确保检错能力
这些多项式不是随便选的长数字,它们是本原多项式或具有类似特性的多项式。这意味着:
-
它能检测所有奇数个比特的错误。(因为生成多项式包含因子
x + 1,即11,这使得所有奇数个错误无法被它整除)。 -
它能检测所有长度小于等于多项式阶数(位数-1)的突发错误。例如,一个16位的CRC可以检测所有长度小于等于16位的连续比特错误。
-
它能以极高的概率检测更长的突发错误。对于一个r次的生成多项式,无法检测的突发错误长度大于r的概率仅为
1/2^r。
3. 整个过程回顾:发送方与接收方
现在我们把所有概念串起来,看CRC如何实现差错检测:
-
发送方:
-
有一个原始数据
M(比如1101)。 -
双方预先约定好一个强大的生成多项式
P(比如101)。 -
在数据
M后面附加k个0(k是P的位数减一),得到新的序列M000...0。 -
对
M000...0和P进行模2除法。 -
得到余数
R(在我们的例子中是010)。这个R就是CRC校验码。 -
发送的不是原始数据
M,而是M和R拼接在一起的数据T(即1101+010=1101010)。
-
-
接收方:
-
收到数据
T’(如果没错误,T’ = T)。 -
用同样的生成多项式
P对收到的整个数据T’进行模2除法。 -
关键点来了:因为
T是由M和R拼接而成,且R是M000...0 ÷ P的余数,根据模2除法的定义,T = M000...0 + R必然能被P整除(余数为0)! -
因此:
-
如果计算余数为0,则认为传输无错误。
-
如果计算余数不为0,则断定传输肯定发生了错误。
-
-
结论:为什么不会出现“碰撞”?
-
对于无错误的数据:只有唯一的一个数据
T能满足T mod P = 0。这个数据就是M和它对应的正确余数R的拼接。 -
对于有错误的数据:错误相当于在正确的数据
T上加(模2加,即异或)了一个错误模式向量E(E中为1的位就是出错的位)。 -
接收方计算的是
(T + E) mod P。 -
这个结果等于
(T mod P) + (E mod P) = 0 + (E mod P) = E mod P。 -
因此,余数是否为0,等价于错误模式
E是否能被P整除。
现在回答您的核心问题:“有两个不同的比特串最终除出一个相同的余数” 的情况会发生吗?
会的,但这恰恰意味着发生了无法检测的错误!这种情况发生的条件是:错误模式 E 恰好能被生成多项式 P 整除(即 E mod P = 0)。
而强大的生成多项式 P 被精心设计的目的,就是使得常见的错误模式(如奇数个错、短突发错误)都绝对无法整除它。对于那些非常罕见、恰好能被 P 整除的复杂错误模式,其出现的概率极低(如CRC-32是四十亿分之一)。
所以,CRC的实现差错的检测的秘诀在于:“除法”只是手段,“强大的生成多项式”才是核心。 是生成多项式的数学特性保证了,在真实世界的错误模型下,出现您所担心的“碰撞”的概率小到可以忽略不计。
Q:问一个“题外话”,我注意到这里的“碰撞”似乎与哈希算法中的“碰撞”有些类似(比如从碰撞概率的计算上),它们有什么联系吗
A:
您观察得非常敏锐!这绝非“题外话”,而是一个极其深刻的洞见。CRC校验中的“碰撞”与哈希算法中的“碰撞”在核心思想和数学本质上有着非常直接和紧密的联系。
事实上,您可以这样理解:CRC算法就是一种特定类型的、为检测错误而优化的非加密哈希函数(Hash Function)。
让我们来详细分解它们的联系与区别:
核心联系:都是“指纹”函数
-
共同目标:数据摘要
-
CRC:接收一个任意长的数据块(消息),生成一个固定长度(如16、32位)的校验码(余数)。这个校验码是数据的“指纹”,用于检测意外更改(错误)。
-
哈希函数:接收一个任意长的输入(消息),生成一个固定长度(如128、256位)的哈希值(摘要)。这个哈希值是数据的“指纹”,用于唯一标识一份数据,常见于校验、数字签名、数据结构(哈希表)等领域。
-
-
共同挑战:碰撞
-
碰撞定义:两个不同的输入,经过函数计算后,产生了相同的输出。
-
CRC碰撞:两个不同的消息
M1和M2,使用同一个生成多项式P计算后,得到相同的余数R。即CRC(M1) = CRC(M2)。这意味着错误无法被检测。 -
哈希碰撞:两个不同的输入
X和Y,经过哈希函数H计算后,得到相同的哈希值。即H(X) = H(Y)。
-
-
共同基础:数学原理
-
两者的计算过程都可以抽象为在有限域上对多项式求模。
-
CRC:明确是在伽罗华域 GF(2) 上,将数据视为多项式,除以生成多项式
P后取余数。CRC(M) = M(x) mod P(x)。 -
许多哈希函数(尤其是基于设计的):其内部结构同样可以建模为在某个大型有限域上进行复杂的多项式运算。它们的目标是让这个“求模”过程变得极其复杂和不可逆。
-
关键区别:设计目标与安全假设
尽管核心思想相似,但它们的设计侧重点完全不同,这导致了巨大的实现差异:


一个生动的比喻
-
CRC 像一个超市的商品条码扫描器。
-
目标:快速、准确地识别商品,防止意外扫错(比如光线不好、条码污损)。
-
设计:足够快,并且两个不同商品条码意外相同的概率极低。
-
安全性:完全不防伪。任何人都可以复制或打印一个条码。
-
-
加密哈希函数 像一个司法鉴定中的DNA检测。
-
目标:唯一性地、无可辩驳地确认一个人的身份,防止故意伪造。
-
设计:过程复杂且昂贵,但要确保世界上几乎不可能找到两个拥有完全相同DNA的人( collision抵抗)。
-
安全性:无法伪造,无法从DNA样本反向推导出这个人的完整长相(抗原像性)。
-
结论
您的联想是完全正确的。CRC和哈希函数是解决同一类问题(为数据生成摘要)的两种不同技术,它们处于同一个技术光谱上,但位于截然不同的端点。
-
CRC 是高效、轻量级的错误检测码,其安全性建立在随机错误概率 vs 精心设计的多项式特性的数学基础上。
-
加密哈希函数是复杂、重量级的密码学原语,其安全性建立在计算复杂性的理论基础上,旨在对抗智能对手的主动攻击。
所以,当您理解CRC的碰撞概率时,您已经在理解现代密码学中一个最核心概念(哈希函数)的道路上迈出了第一步。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)