【AI论文】:nablaNABLA:邻域自适应块级注意力机制
摘要:本研究提出NABLA——一种新型邻域自适应块级注意力机制,用于优化视频扩散Transformer的计算效率。该方法通过块平均降采样和自适应阈值选择动态调整稀疏模式,在保持视频生成质量(CLIP/VBench分数与基线相当)的同时,实现最高2.7倍加速。NABLA无需定制底层算子,可无缝集成PyTorch框架。实验验证其在512×512分辨率下具有更优训练效率,但存在阈值敏感性和复杂场景适应性
摘要:基于Transformer架构的近期研究进展在视频生成任务中取得了显著成效。然而,全注意力机制所具有的二次复杂度,仍是制约其发展的关键瓶颈,尤其是对于高分辨率和长时长的视频序列而言。在本文中,我们提出了NABLA——一种新颖的邻域自适应块级注意力机制,该机制能够动态适应视频扩散Transformer(DiTs)中的稀疏模式。通过利用基于块的注意力机制以及自适应的稀疏性驱动阈值,NABLA在保持生成质量的同时降低了计算开销。我们的方法无需定制低层算子设计,且可与PyTorch的Flex Attention算子无缝集成。实验表明,与基线方法相比,NABLA在几乎不牺牲量化指标(CLIP分数、VBench分数、人工评估分数)和视觉质量的前提下,实现了最高达2.7倍的训练和推理加速。代码和模型权重可在此处获取:Github。Huggingface链接:Paper page,论文链接:2507.13546
研究背景和目的
研究背景:
近年来,基于Transformer的架构在视频生成任务中取得了显著进展,特别是扩散Transformer(Diffusion Transformers, DiTs)的引入,使得视频生成的质量和效率得到了大幅提升。然而,全注意力机制(Full Attention Mechanisms)的二次复杂度成为了制约高分辨率和长时间视频序列生成的关键瓶颈。全注意力机制在处理长序列时,计算复杂度随序列长度的平方增长,导致计算资源消耗巨大,限制了其在实时或大规模视频生成应用中的使用。
尽管已有多种简化注意力机制的方法被提出,如滑动窗口注意力(Sliding Window Attention)、稀疏注意力(Sparse Attention)等,但这些方法大多依赖于静态的稀疏模式或需要特定的低层算子设计,难以动态适应不同视频内容的稀疏性需求。特别是在处理复杂空间和时间关系的视频时,静态稀疏模式往往无法有效捕捉长距离依赖关系,导致生成质量下降。
研究目的:
本研究旨在提出一种新颖的邻域自适应块级注意力机制(Neighborhood Adaptive Block-Level Attention, NABLA),以动态适应视频扩散Transformer中的稀疏模式,从而在保持生成质量的同时降低计算开销。具体目标包括:
- 降低计算复杂度:通过引入自适应的块级稀疏注意力机制,减少全注意力机制的计算量。
- 保持生成质量:确保在降低计算复杂度的同时,不牺牲视频的生成质量,包括定量指标(如CLIP分数、VBench分数)和视觉质量。
- 无缝集成:设计一种无需定制低层算子的方法,能够与现有深度学习框架(如PyTorch)无缝集成。
- 动态适应:使注意力机制能够根据输入视频的动态内容自适应调整稀疏模式,捕捉长距离依赖关系。
研究方法
1. 邻域自适应块级注意力机制(NABLA):
NABLA机制的核心在于动态选择注意力块,通过以下步骤实现:
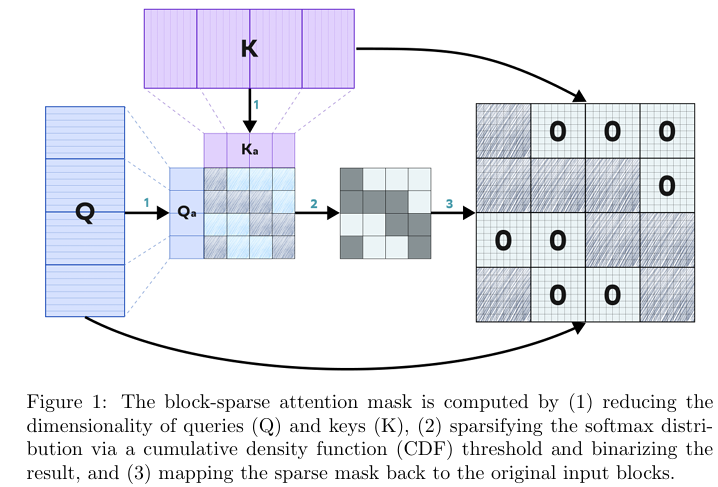
- 块平均降采样:将查询(Query)和键(Key)张量划分为多个块,并对每个块内的值进行平均,得到降采样后的查询和键张量。这一步骤显著减少了后续计算的复杂度。
- 计算降采样后的注意力图:使用降采样后的查询和键张量计算注意力图,并通过softmax操作和累积分布函数(CDF)阈值进行二值化,得到稀疏的注意力掩码。
- 映射回原始块:将二值化后的稀疏注意力掩码映射回原始输入块,确定需要计算的注意力块。
2. 结合滑动瓷砖注意力(STA):
为了进一步提升生成质量,本研究将NABLA与滑动瓷砖注意力(Sliding Tile Attention, STA)结合使用。STA通过预定义的窗口大小在固定的3D邻域内计算注意力,有效捕捉了局部空间和时间关系。NABLA与STA的结合,既利用了STA的强先验掩码,又通过NABLA动态适应了稀疏模式,从而在保持效率的同时提升了生成质量。
3. 实现与集成:
NABLA机制通过PyTorch的Flex Attention算子实现,无需定制低层CUDA内核,便于与现有深度学习框架无缝集成。实验中使用PyTorch 2.7版本的Flex Attention实现,确保了方法的通用性和可复现性。
研究结果
1. 计算效率提升:
实验结果表明,NABLA机制在保持生成质量的同时,显著提升了训练和推理速度。具体来说,NABLA在视频生成任务中实现了最高达2.7倍的训练和推理加速,相较于全注意力基线方法,计算效率大幅提升。
2. 生成质量保持:
在定量指标方面,NABLA机制在CLIP分数、VBench分数和人工评估分数上均与全注意力基线方法相当,甚至在某些配置下略有提升。这表明NABLA在降低计算复杂度的同时,成功保持了视频的生成质量。
3. 视觉质量评估:
通过人工评估实验,参与者对NABLA生成的视频在视觉质量、动态自然性和语义一致性三个方面进行了评价。结果显示,NABLA在高稀疏度(如80%)下仍能保持与基线方法相当的视觉质量,进一步验证了其有效性。
4. 预训练阶段验证:
在预训练实验中,NABLA机制在512×512分辨率下的训练收敛速度优于全注意力方法,且每个训练迭代的时间更短。这表明NABLA不仅适用于微调阶段,还能在预训练阶段有效提升计算效率。
研究局限
尽管NABLA机制在视频生成任务中取得了显著成效,但仍存在以下局限:
1. 阈值选择的敏感性:
NABLA机制的性能在一定程度上依赖于二值化阈值的选择。虽然实验中通过累积分布函数自动确定了阈值,但在某些特定场景下,阈值的选择可能仍需人工调整以优化性能。
2. 复杂场景下的适应性:
对于包含多个复杂对象和空间关系的视频场景,NABLA机制可能无法完全捕捉所有长距离依赖关系。尽管结合STA可以缓解这一问题,但在极端复杂场景下,生成质量仍可能受到影响。
3. 硬件依赖性:
虽然NABLA机制无需定制低层算子设计,但其性能仍受限于硬件加速能力。在硬件资源有限的情况下,NABLA的加速效果可能受到一定限制。
未来研究方向
针对NABLA机制的局限性和视频生成领域的挑战,未来研究可从以下几个方面展开:
1. 自适应阈值调整:
探索更加智能的自适应阈值调整方法,使NABLA机制能够在不同场景下自动优化阈值选择,进一步提升其鲁棒性和适应性。
2. 多尺度稀疏注意力:
研究多尺度稀疏注意力机制,将NABLA应用于不同空间和时间尺度的视频块,以更好地捕捉复杂场景下的长距离依赖关系。
3. 跨模态稀疏注意力:
将NABLA机制扩展至跨模态视频生成任务,如文本到视频、图像到视频的生成,探索其在多模态条件下的稀疏注意力模式。
4. 硬件优化与加速:
针对NABLA机制,研究专门的硬件优化和加速技术,如定制化CUDA内核、FPGA加速等,以进一步提升其在资源受限环境下的性能。
5. 实际应用与部署:
将NABLA机制应用于实际视频生成场景,如影视制作、虚拟现实、游戏开发等,验证其在实际应用中的有效性和实用性。同时,探索其与其他视频生成技术的结合,以推动视频生成领域的整体进步。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献228条内容
已为社区贡献228条内容

所有评论(0)