Baichuan-Omni:首个开源 7B 全模态大语言模型
本文是对论文《BAICHUAN-OMNI TECHNICAL REPORT》的深度解读。在全模态大模型领域,开源方案常存在模态覆盖不全、交互体验不佳的问题。Baichuan Inc. 联合西湖大学、浙江大学团队推出的 Baichuan-Omni,是首个开源 7B 参数全模态 MLLM,支持文本、图像、视频、音频四模态并发处理,通过 “全模态数据构建→多模态对齐预训练→多任务微调” 流程,及 Con
在 GPT-4o 凭借卓越的多模态能力和交互体验重塑人机交互范式的同时,开源社区长期缺乏一款能与之抗衡的全模态基础模型 —— 现有开源方案要么局限于单一 / 少数模态,要么在交互流畅性、跨模态理解精度上存在显著短板。Baichuan Inc. 联合西湖大学、浙江大学推出的Baichuan-Omni,填补了这一空白:它是首个开源的 7B 参数全模态大语言模型(MLLM),支持文本、图像、视频、音频四种模态的并发处理与分析,同时具备先进的实时交互能力和领先的基准测试性能。
原文链接:https://arxiv.org/pdf/2410.08565
代码链接:https://github.com/westlake-baichuan-mllm/bc-omni
沐小含持续分享前沿算法论文,欢迎关注...
一、背景与核心贡献
1.1 核心定位
Baichuan-Omni 的核心目标是:构建一款开源、高性能、支持多模态实时交互的基础模型,打破闭源模型(如 GPT-4o)在全模态领域的垄断,为开源社区提供可复用的技术基线。
1.2 三大核心贡献
- 全模态覆盖与开源开放:首个支持文本、图像、视频、音频四模态并发处理的开源 7B MLLM,提供中英双语支持,开源模型权重、训练代码及评估脚本。
- 创新的实时交互架构:通过预测音频输入边界、流式处理视觉数据(图像 / 视频)、延迟注入音频特征的方式,实现音视频流式输入与实时推理,提升交互自然度。
- 端到端训练框架:设计了 “全模态数据构建→多模态对齐预训练→多任务微调” 的完整流水线,在 200 + 任务、600k 实例的数据集上完成训练,确保跨模态理解与指令跟随能力。
二、全模态 LLM 的技术痛点与解决方案
2.1 技术背景与行业现状
- MLLM 的演进:从纯文本 LLM(如 LLaMA、Baichuan)到视觉 - 语言模型(VLMs,如 Qwen2-VL)、音频 - 语言模型(ALMs,如 Qwen-Audio),AI 模型正逐步突破单模态局限,但 “全模态统一处理” 仍是难点。
- 闭源 vs 开源的差距:GPT-4o 等闭源模型已实现 “文本 + 图像 + 视频 + 音频” 的深度融合与自然交互,但开源模型存在两大短板:
- 模态覆盖不全:多数开源 MLLM 仅支持 2 种模态(如图文、音文),缺乏全模态统一建模能力;
- 交互体验不佳:难以支持流式输入(如实时音视频),响应延迟高,无法满足实际应用场景。
- Baichuan-Omni 的切入点:以 “全模态覆盖 + 实时交互” 为核心,基于 7B 轻量化架构,平衡性能与部署成本,打造开源社区的全模态基础模型标杆。
2.2 模型核心架构概览
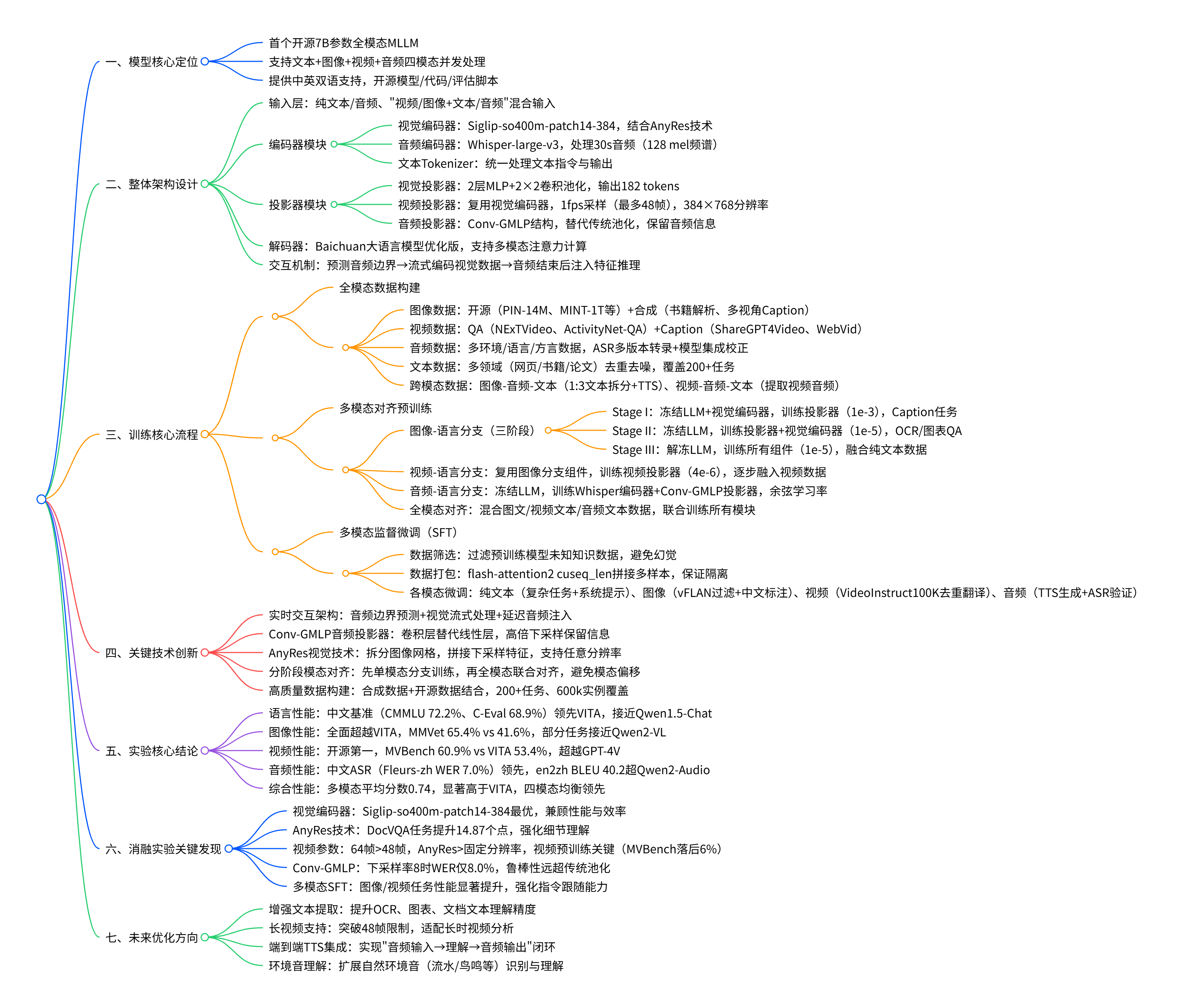
Baichuan-Omni 的架构设计围绕 “多模态统一编码 + 流式交互” 展开,如图 2 所示:
架构关键组件解读
- 输入层:支持纯文本 / 音频输入,或 “视频 / 图像 + 文本 / 音频” 混合输入;
- 编码器模块:
- 视觉编码器(图像 / 视频):采用 Siglip-384px,结合 AnyRes 技术支持任意分辨率输入;
- 音频编码器:基于 Whisper-large-v3,输出 1280 维特征;
- 文本 Tokenizer:统一处理文本指令与输出;
- 投影器(Projector):
- 视觉投影器:2 层 MLP+2×2 卷积池化,将图像特征映射到 LLM 嵌入空间;
- 视频投影器:基于图像投影器扩展,处理帧序列特征;
- 音频投影器:创新的 Conv-GMLP 结构,替代传统池化,保留更多音频细节;
- 解码器(Baichuan-Omni Decoder):基于 Baichuan 大语言模型优化,支持多模态特征的注意力计算与生成;
- 交互机制:先预测音频输入的起止边界,期间流式编码视觉数据并计算注意力,音频输入结束后注入音频特征完成推理,实现音视频流式处理。
三、相关工作:全模态 LLM 的技术演进脉络
论文系统梳理了多模态模型的发展历程,明确了 Baichuan-Omni 的技术定位:
3.1 三大技术分支的局限性
| 模型类型 | 核心能力 | 代表模型 | 局限 |
|---|---|---|---|
| 纯文本 LLM | 自然语言理解与生成 | LLaMA、Baichuan、Qwen1.5 | 无视觉 / 音频理解能力 |
| 视觉 - 语言模型(VLMs) | 图文对齐与视觉问答 | LLaVA、Qwen2-VL、InternVL | 仅支持图文模态,缺乏音视频处理 |
| 音频 - 语言模型(ALMs) | 语音识别与音频问答 | Qwen-Audio、SALMONN | 仅支持音文模态,不具备视觉理解 |
| 闭源全模态模型 | 多模态统一处理 | GPT-4o、Gemini 1.5 Pro | 不开源,无法二次开发 |
| 开源全模态模型 | 多模态交互 | VITA | 模态对齐精度不足,中文性能弱,交互性差 |
3.2 Baichuan-Omni 的差异化优势
- 突破模态局限:首次在开源模型中实现 “文本 + 图像 + 视频 + 音频” 四模态统一建模;
- 强化中文能力:针对中文场景优化数据与训练,在中文基准(如 CMMLU、C-Eval)上大幅超越现有开源模型;
- 优化实时交互:创新的流式处理架构,解决开源模型 “非流式输入” 的交互瓶颈。
四、训练框架:全模态能力的构建流程
Baichuan-Omni 的训练分为三大核心阶段:高质量全模态数据构建→多模态对齐预训练→多任务微调(SFT),形成端到端的技术闭环。
4.1 高质量全模态数据构建
数据是多模态模型的基础,Baichuan-Omni 构建了涵盖 “单模态→跨模态” 的大规模高质量数据集,总计 600k 实例、200 + 任务,具体构成如下:

4.1.1 图像数据
- 数据类型:分为 Caption(图像描述)、Interleaved 图文(交错图文)、OCR 数据、图表数据四类;
- 数据来源:
- 开源数据:Stage I(图像 - 语言预训练)用 PIN-14M、MINT-1T、LAION5B 等;Stage II/III(微调)用 Cauldron、Monkey、ArxivQA 等;
- 合成数据:从书籍 / 论文中解析生成交错图文、OCR、图表数据(知识密集型);训练专用模型生成多视角高质量图像描述;
- 处理流程:数据清洗→采样平衡→格式标准化。
4.1.2 视频数据
- 任务类型:视频分类、动作识别、时序定位、视频 QA、视频 Caption;
- 数据来源:
- QA 数据:NExTVideo、ActivityNet-QA(训练集);
- Caption 数据:ShareGPT4Video(GPT-4 生成)、WebVid、YouTube 视频(GPT-4o 生成描述);
- 采样策略:按数据集规模分配采样比例,确保视频类型、任务、领域的均衡覆盖。
4.1.3 音频数据
- 数据多样性:覆盖不同录制环境、语言(中英)、口音、方言、说话人,包含人声、音效、背景音;
- 处理流水线:说话人录音→方言识别→口音识别→音效检测→质量评估→筛选;
- 音频 - 文本对齐:用内部 ASR 系统 + 开源模型(如 Whisper-large-v3)生成多版本转录文本,通过模型集成进行错误校正,提升对齐精度。
4.1.4 文本数据
- 数据来源:网页、书籍、学术论文、代码等多领域数据;
- 处理标准:
- 多样性:覆盖不同主题、语言风格;
- 高质量:去重、去噪,提升知识密度;
- 任务类型:知识问答、数学推理、代码生成、文本创作、安全相关任务。
4.1.5 跨模态交互数据
为提升多模态协同理解能力,构建了 “图像 - 音频 - 文本”“视频 - 音频 - 文本” 混合数据集:
- 图像 - 音频 - 文本:将文本按 1:3 拆分,1/4 文本通过 TTS(44 种音色)转为音频,任务提示如 “听音频描述图像后,结合图像补充信息”,模型需预测剩余 3/4 文本;
- 视频 - 音频 - 文本:直接提取视频中的音频作为跨模态组件,结合视频帧与文本指令构建任务。
4.2 多模态对齐预训练
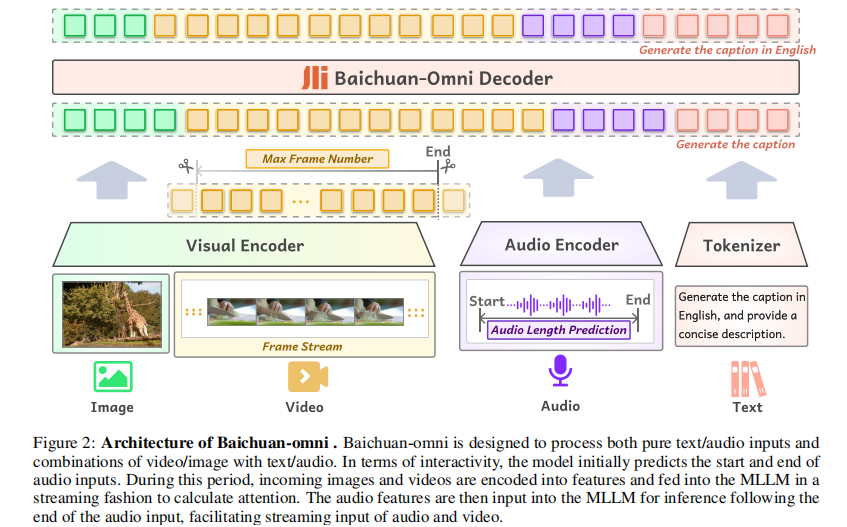
预训练的核心目标是:让 LLM 学会理解视觉(图像 / 视频)和音频特征,实现 “模态间语义对齐”。分为三个单模态分支训练 + 全模态联合对齐,流程如图 4 所示:
4.2.1 图像 - 语言分支(三阶段训练)
- 视觉编码器:选用 Siglip-so400m-patch14-384(428M 参数,384×384 分辨率),结合 AnyRes 技术支持任意分辨率输入(拆分图像为网格,拼接下采样特征提供全局上下文);
- 视觉投影器:2 层 MLP+2×2 卷积池化,输出 182 个 token;
- 训练细节:
阶段 训练目标 冻结策略 学习率 训练数据 Stage I 图像 - 文本初始对齐 冻结 LLM + 视觉编码器,训练投影器 1e-3 大规模图像 - 文本对(Caption 任务) Stage II 强化视觉理解(OCR / 图表) 冻结 LLM,训练投影器 + 视觉编码器 1e-5 VQA、130k OCR / 图表 QA、交错图文 Stage III 提升图文协同性能 解冻 LLM,训练所有组件 1e-5 VQA、图像 Caption、交错图文、纯文本
4.2.2 视频 - 语言分支
- 基础依赖:复用图像 - 语言分支的视觉编码器(Siglip-384px)和 LLM 骨干,仅训练视频投影器;
- 视频处理:
- 帧采样:1fps,最多 48 帧 / 视频;
- 分辨率:调整为 384×768(平衡质量与效率);
- 特征处理:投影器前加 2×2 卷积层,控制 token 序列长度(182~546 tokens);
- 训练策略:
- 先用图像 - 文本数据强化视觉基础;
- 逐步融入混合图文对 + 视频 - 文本对,避免直接训练导致的模态偏移。
4.2.3 音频 - 语言分支
- 音频编码器:采用 Whisper-large-v3,处理 30s 音频(128 mel 频谱),输出 1280 维特征;
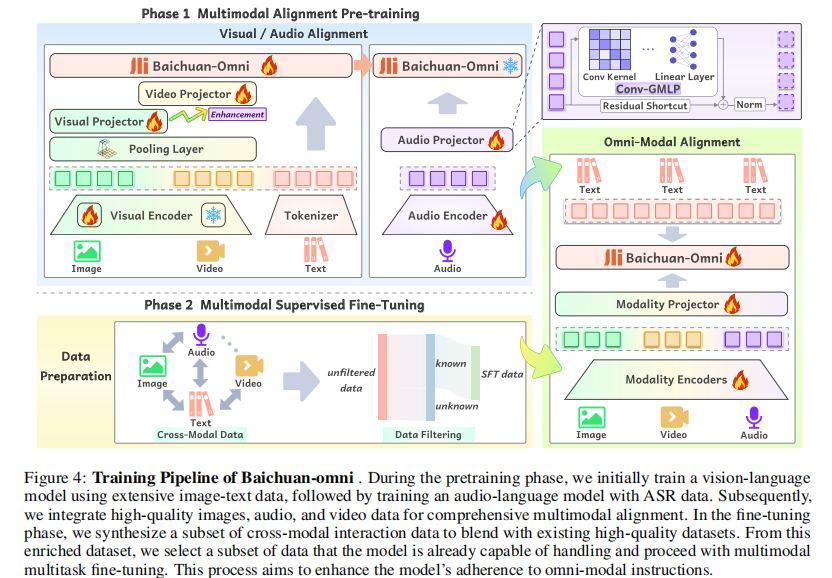
- 音频投影器(核心创新):用 Conv-GMLP 替代传统池化,解决高倍下采样导致的信息丢失问题:
- Conv-GMLP 结构(图 5):类似门控 MLP,但用卷积层替代线性层,包含两个卷积层(下采样 n 倍)+ 残差连接,下采样时同步扩展特征通道数(如 n=4 时,序列长度缩为 1/4,通道数扩为 4 倍);
- 优势:在高倍下采样(如 n=8)时仍能保留关键音频信息,提升 ASR 与音频理解鲁棒性;
- 训练细节:冻结 LLM,仅训练音频编码器 + 投影器,用长音频 - 文本序列(最长 4K tokens),采用余弦学习率调度器。
4.2.4 全模态对齐(Omni-Alignment)
在三个单模态分支训练完成后,将所有组件联合训练,输入混合数据集(图像 - 文本 + 视频 - 文本 + 音频 - 文本),实现文本、图像、视频、音频四模态的全局语义对齐,为跨模态交互奠定基础。
4.3 多模态监督微调(SFT)
微调的核心目标是:提升模型的指令跟随能力,适配复杂多模态任务场景。
4.3.1 数据筛选与处理
- 筛选标准:基于预训练模型的知识覆盖度,过滤 “未知知识” 数据(避免幻觉);
- 数据多样性:覆盖 200 + 任务,包含文本、音频、图文、视频文本、图像 - 音频交互数据;
- 打包优化:用 flash-attention2 的 cuseq_len 实现多样本拼接,批量训练时保证样本隔离,提升训练效率与内存利用率。
4.3.2 各模态微调数据细节
- 纯文本:包含复杂多步任务、系统提示类数据,强化逻辑推理与指令理解;
- 图像理解:
- 基础数据:vFLAN(损失过滤 + 中英翻译 + 人工重标注)、synthdog-en/zh、手写 OCR、街景 OCR 等;
- 优化处理:ImageInWords 数据集要求明确实体名称(如 “萨摩耶犬” 而非 “狗”);生成多模态数学题(结合图像的数学推理);
- 视频理解:基于 VideoInstruct100K,对指令进行语义去重 + 中文翻译,提升任务多样性;
- 音频理解:
- 合成音频:从文本 / 图文 / 视频数据中提取提示词,用 TTS 生成音频,ASR 验证转录准确性;
- 真实音频:包含方言、口音、背景音的人类录制音频;
- 专项数据:构建 ASR 数据集(开源数据 + 内部日志),筛选高难度样本强化训练。
五、实验结果:全模态性能全面领先
论文在语言、图像、视频、音频四大模态的主流基准上进行了零样本评估,对比了闭源模型(GPT-4o、Gemini 1.5 Pro)与开源模型(VITA、Qwen2-VL 等),结果显示 Baichuan-Omni 在开源模型中表现突出,部分任务超越闭源模型。
5.1 语言性能评估
评估基准
- 中文基准:CMMLU(52 个学科,中文知识与推理)、C-Eval(13948 道选择题,中文多领域);
- 通用基准:MMLU(57 个任务,多领域知识)、AGIEval(人类资格考试,认知能力)。
实验结果
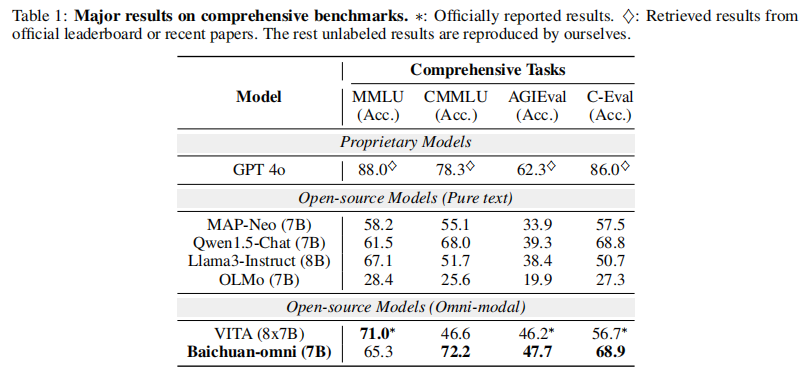
关键结论
- Baichuan-Omni 在中文基准上大幅领先开源全模态模型 VITA(CMMLU 72.2% vs 46.6%,C-Eval 68.9% vs 56.7%),接近开源纯文本模型 Qwen1.5-Chat;
- 在 AGIEval 上超越 VITA(47.7% vs 46.2%),体现了全模态训练对语言能力的保护与提升。
5.2 图像理解性能评估
评估基准
- 多选择 / 是非题:MMBench-EN、MMBench-CN、M3GIA、SEED-IMG、MME、MMMU、HallusionBench;
- VQA 任务:RealWorldQA、MMVet、MathVista-mini、TextVQA、ChartQA、OCRBench;
- 评估工具:统一使用 VLMEvalKit,确保可复现性。
实验结果
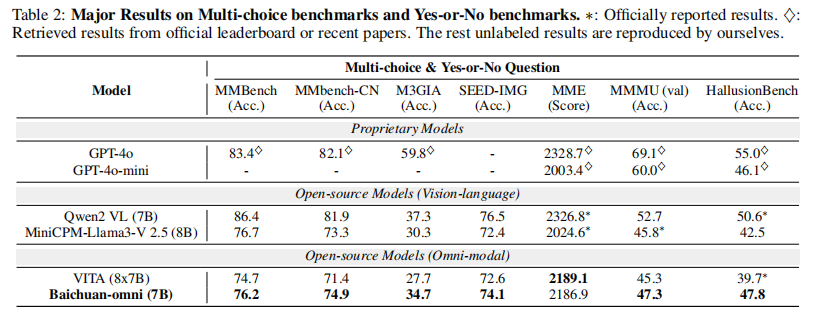
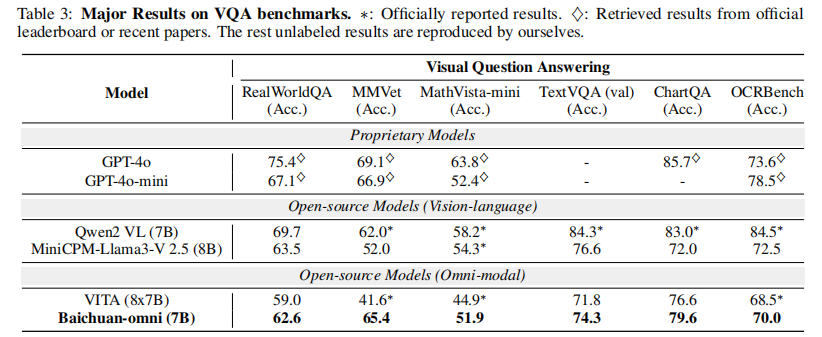
关键结论
- 全面超越开源全模态模型 VITA:在 MMBench-CN、MMMU、MMVet 等核心基准上均有显著优势(如 MMVet 65.4% vs 41.6%);
- 对标开源专用 VLMs:在抽象视觉任务(如 OCR、图表理解)上接近 MiniCPM-Llama3-V 2.5,部分任务(如 HallusionBench)超越;
- 与闭源模型差距:在高分辨率图像理解、复杂推理任务上仍有提升空间,但在中文场景下表现更优。
5.3 视频理解性能评估
评估基准
- 通用视频 QA:MVBench、Egoschema、VideoMME(w/o subs)、Perception-Test(top-1 准确率);
- 开放式视频 QA:ActivityNet-QA、MSVD-QA(用 GPT-3.5-Turbo 评估答案正确性(Acc.)与质量(Score 0-5))。
实验结果
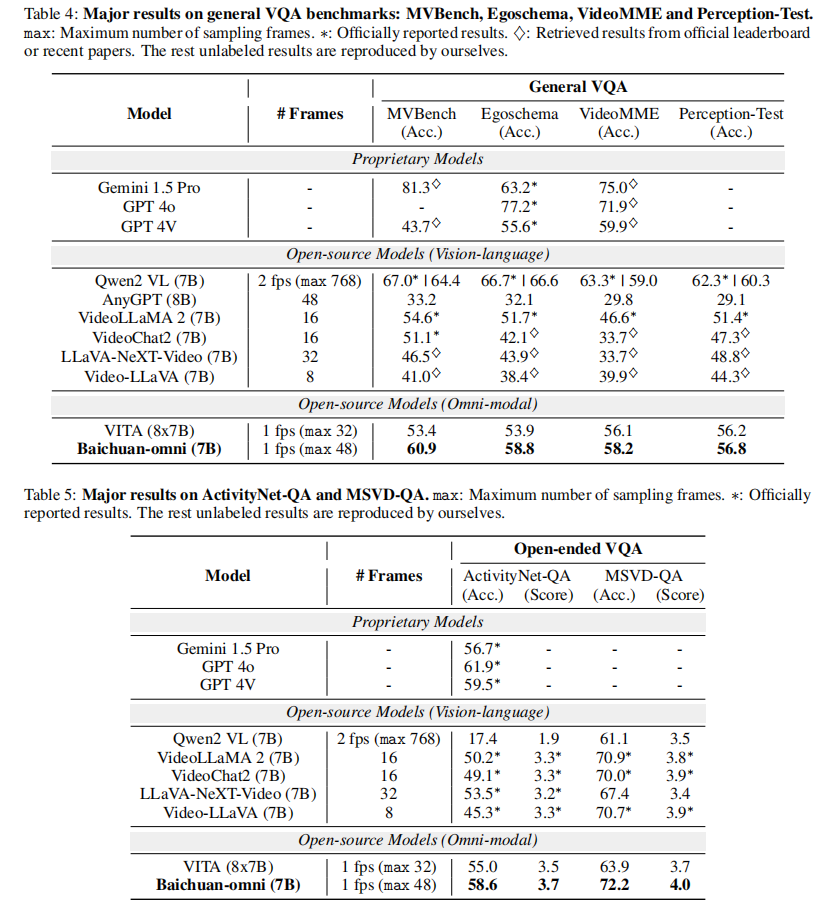
关键结论
- 通用视频 QA:超越开源模型 VITA(平均提升 4%),在 MVBench(60.9% vs 53.4%)、Egoschema(58.8% vs 53.9%)上领先,且超越闭源模型 GPT-4V;
- 开放式视频 QA:开源模型中排名第一,ActivityNet-QA(58.6%)超越 Gemini 1.5 Pro(56.7%),MSVD-QA 的答案质量(Score=4.0)更优,体现强描述生成能力;
- 效率优势:仅 7B 参数,帧采样数(48 帧)少于 Qwen2-VL(768 帧),但性能相当,部署成本更低。
5.4 音频理解性能评估
评估任务
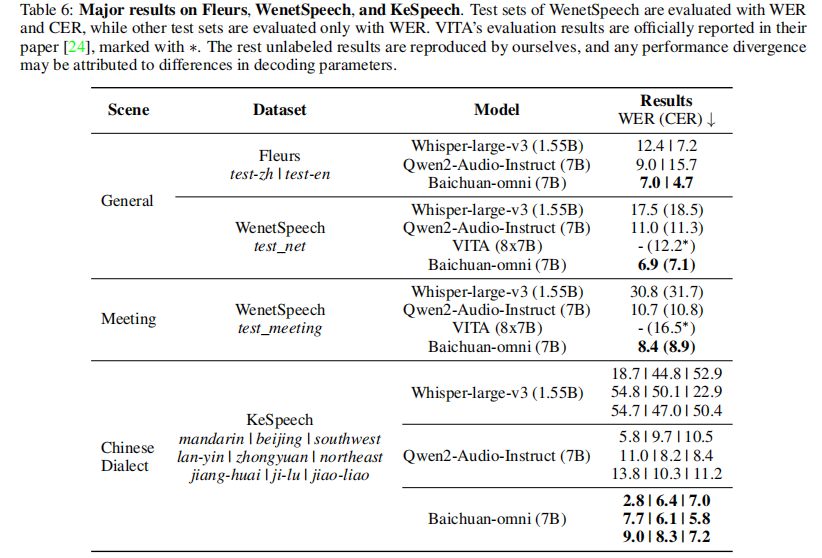
- ASR(语音识别):通用场景(Fleurs-zh/en、WenetSpeech test_net)、复杂场景(WenetSpeech test_meeting、KeSpeech 方言),指标为 WER(词错误率)、CER(字符错误率);
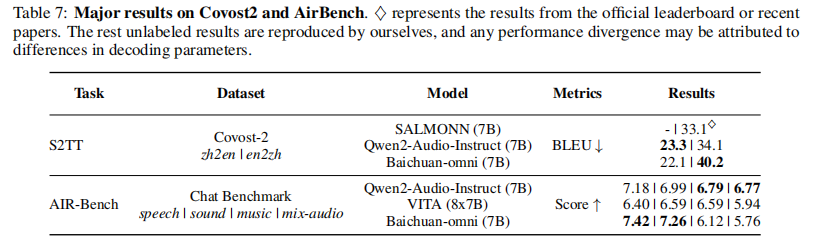
- S2TT(语音翻译):Covost2 zh2en/en2zh,指标为 BLEU;
- 音频指令跟随:AIR-Bench,指标为 Score。
实验结果
关键结论
- ASR 性能:中文场景大幅领先(Fleurs-zh WER 7.0% < Qwen2-Audio-Instruct 9.0%),方言识别(KeSpeech 平均 CER 6.7%)表现优异,会议场景(WenetSpeech test_meeting CER 8.9%)超越 VITA(16.5%);
- S2TT 性能:en2zh 翻译 BLEU 40.2,领先 Qwen2-Audio-Instruct 7 个点;
- 指令跟随:AIR-Bench 得分 7.42,超越 Qwen2-Audio-Instruct,体现强音频交互能力。
5.5 多模态综合性能
论文通过归一化处理(\(x_{norm}=(x-x_{min}+10)/(x_{max}-x_{min}+10)\))展示了各模型在图像、视频、音频模态的综合表现(图 1):
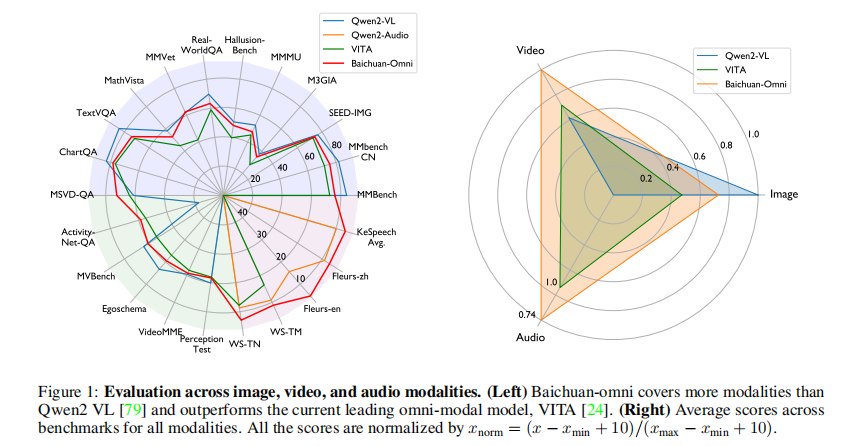
- 左图:Baichuan-Omni 覆盖文本、图像、视频、音频四模态,而 Qwen2-VL 仅支持图文,VITA 虽支持全模态但性能落后;
- 右图:Baichuan-Omni 的多模态平均分数(0.74)显著高于 VITA,体现全模态均衡性与领先性。
六、消融研究:关键技术的有效性验证
论文通过消融实验验证了各核心模块的贡献,为模型设计提供了实证支撑。
6.1 图像 - 语言分支关键组件
6.1.1 视觉编码器选择
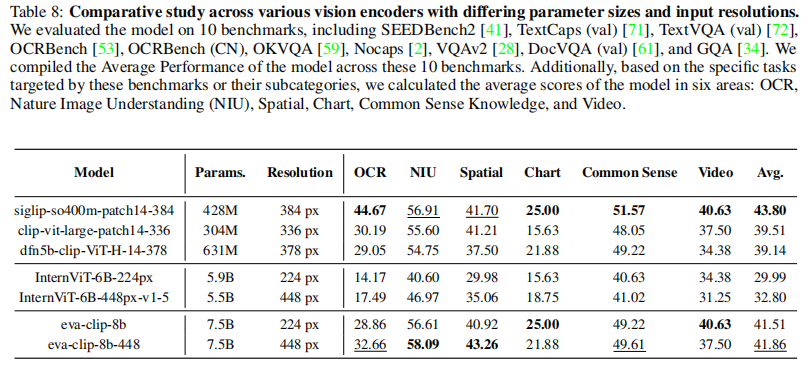
对比 5 类视觉编码器(CLIP、Siglip、DFN、InternViT、EVA),结果显示:
- 分辨率影响:同模型下高分辨率(如 eva-448 vs eva-224)提升性能,但参数规模与性能无直接正相关;
- 最优选择:Siglip-so400m-patch14-384(428M 参数)在 OCR、自然图像理解等 6 项任务中 4 项最优,平均分数 43.80,兼顾性能与效率。
6.1.2 AnyRes 技术的影响

- 结论:AnyRes 技术显著提升依赖图像细节的任务(如 DocVQA 提升 14.87 个点),支持任意分辨率输入的同时保留细节信息。
6.1.3 视觉投影器类型
对比 4 种投影器:
| 投影器类型 | 中文 OCR 理解能力 | 通用图像理解 | 参数效率 |
|---|---|---|---|
| MLP | 最优(0.75 轮拟合) | 良好 | 中等 |
| Mean Pool | 次优 | 良好 | 最优 |
| Concat | 较差 | 良好 | 较差 |
| C-abs | 最差(无法学习) | 良好 | 中等 |
- 选择:Mean Pool(兼顾 OCR 能力、参数效率与通用性能)。
6.2 视频 - 语言分支关键因素
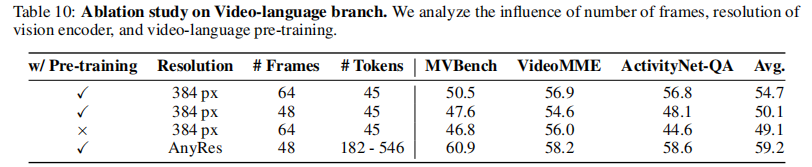
- 结论:
- 帧数量:64 帧性能优于 48 帧,但 48 帧已能满足大部分场景(平衡效率);
- 分辨率:AnyRes 优于固定 384px(平均提升 5%);
- 视频预训练:关键(无预训练时 MVBench 落后 6%)。
6.3 音频 - 语言分支:Conv-GMLP 下采样率影响
测试不同下采样率(2、4、8)对 ASR 平均 WER 的影响(图 6):
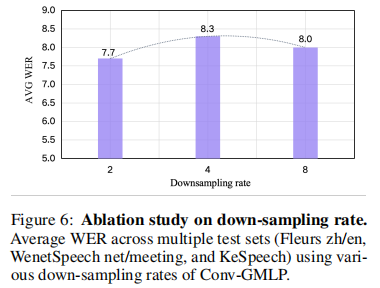
- 下采样率 = 2 时:WER 最低(7.7%),性能最优;
- 下采样率 = 4/8 时:WER 仅轻微上升(8.3%/8.0%),远优于传统池化;
- 关键发现:Conv-GMLP 在高倍下采样(如 8 倍)时仍能保留核心音频信息,鲁棒性极强。
6.4 多模态 SFT 的影响
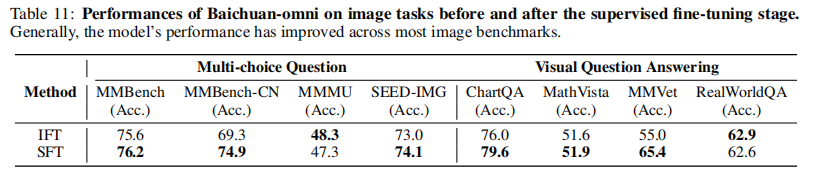
对比仅指令微调(IFT)与多模态 SFT 的性能差异:
- 图像任务(表 11):SFT 后 MMBench-CN(74.9 vs 69.3)、MMVet(65.4 vs 55.0)等均显著提升;
- 视频任务(表 12):SFT 后 ActivityNet-QA(58.6 vs 55.4)、MSVD-QA(4.0 vs 3.8)性能提升,验证了高质量 SFT 数据对指令跟随能力的强化。
七、结论与未来方向
7.1 核心总结
Baichuan-Omni 通过 “高质量数据构建→分阶段模态对齐→多任务微调” 的完整框架,实现了 7B 参数全模态模型的突破:
- 模态覆盖:支持文本、图像、视频、音频四模态并发处理;
- 性能表现:开源模型中多模态综合性能领先,中文场景与音频理解优势显著;
- 交互体验:创新的流式处理架构,支持音视频实时交互;
- 开源价值:提供完整的模型、代码与评估脚本,为开源社区提供全模态研究基线。
7.2 未来改进方向
论文明确了后续优化的四大方向:
- 增强文本提取能力:提升 OCR、图表、文档等场景的文本理解精度;
- 支持更长视频理解:突破当前 48 帧限制,适配长时视频分析;
- 端到端 TTS 集成:实现 “音频输入→文本理解→音频输出” 的闭环交互;
- 环境音理解:扩展音频处理范围,支持流水声、鸟鸣、碰撞声等自然环境音的识别与理解。
八、技术启示与展望
Baichuan-Omni 的成功验证了 “轻量化架构 + 高质量数据 + 精细化对齐” 的全模态模型构建路径,为开源社区提供了重要参考:
- 数据层面:多模态数据的 “多样性 + 高质量对齐” 是核心,合成数据与开源数据结合可有效提升任务覆盖度;
- 架构层面:专用投影器(如 Conv-GMLP)与模态适配技术(如 AnyRes)能显著提升模态理解精度;
- 交互层面:流式处理是全模态模型落地的关键,需平衡实时性与性能。
随着全模态技术的发展,未来模型将进一步突破 “模态隔阂”,实现更自然的人机交互,推动 AGI 向更贴近人类感知的方向演进。Baichuan-Omni 的开源,无疑将加速这一进程。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)