别再只关注KV Cache了! LLM稀疏性新洞察:为何模型越深越稀疏?UNCOMP从矩阵熵给出答案
我们进一步分析发现,最佳的压缩性能和最终的准确率的权衡并非来自于寻找最优的累计注意力分布,而是来自于对“信息流模式”的模仿。这不仅完美解释了深层网络的稀疏化现象,也为我们的压缩策略提供了坚实的理论基础。我们不仅提出了一个高效的推理框架,更重要的是,我们提供了一个全新的理论视角来理解LLM内部的信息动态。当压缩后KV Cache的逐层熵变趋势,与原始全尺寸Cache的趋势高度相似时,模型性能最好。我
作者:熊璟,香港大学二年级博士生,师从黄毅教授和孔令鹏教授。已在ICLR、ICML、NeurIPS、ACL、EMNLP、TMLR等顶级会议/期刊发表论文,研究方向为高效大语言模型推理与自动定理证明。担任NAACL、EMNLP、ACL、ICML、ICLR、NeurIPS、COLING、AISTATS等会议审稿人。个人主页:https://menik1126.github.io/
我们都知道LLM中存在结构化稀疏性,但其底层机制一直缺乏统一的理论解释。为什么模型越深,稀疏性越明显?为什么会出现所谓的“检索头”和“检索层”?
我们非常荣幸地宣布,我们试图回答这些问题的论文 UNCOMP 已被 EMNLP 2025 主会接收!我们不仅提出了一个高效的推理框架,更重要的是,我们提供了一个全新的理论视角来理解LLM内部的信息动态。
核心洞察:一个关于熵的悖论与新解
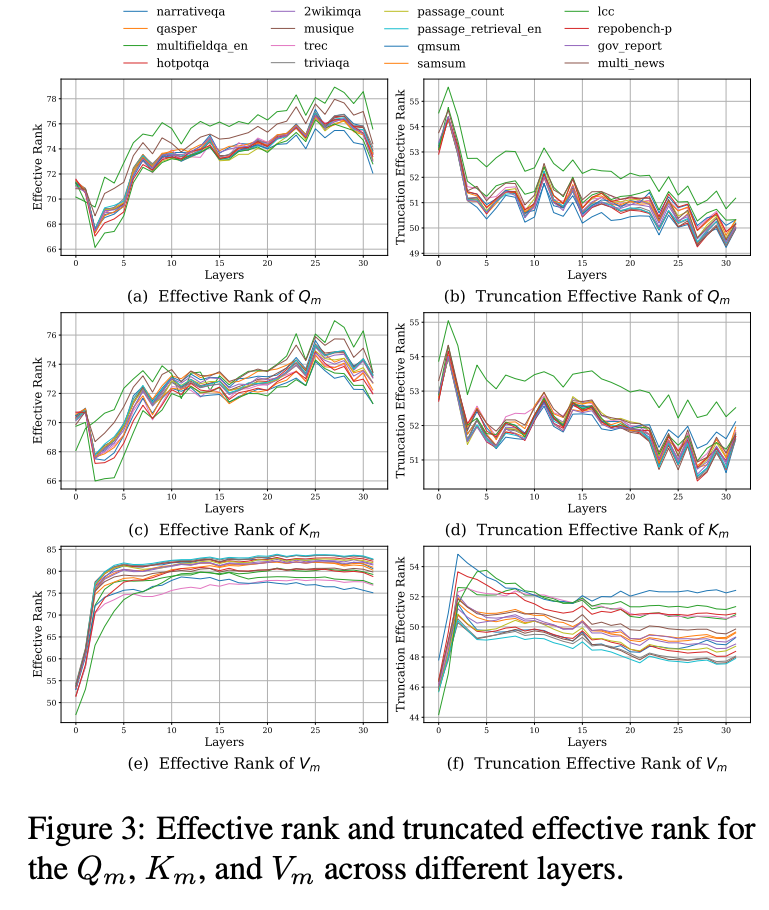
传统的矩阵熵 (Matrix Entropy) 分析存在一个悖论:它显示信息熵随着层数加深是逐层增加的。这与我们观察到的“模型越深越稀疏”的现象相矛盾。如果信息在不断累积,又何来稀疏一说?🧐
我们的关键突破在于引入了截断矩阵熵 (Truncated Matrix Entropy)。通过分析Token矩阵协方差奇异值分布的“拐点”,我们只关注最重要的主成分。惊人的发现是:
截断矩阵熵随着层数加深,呈现出明显的逐层递减趋势!
这不仅完美解释了深层网络的稀疏化现象,也为我们的压缩策略提供了坚实的理论基础。熵的减少意味着信息变得更加集中和稀疏,为压缩创造了空间。
从理论到实践:信息流的指引
这个理论工具让我们能“看透”模型的内部运作:
-
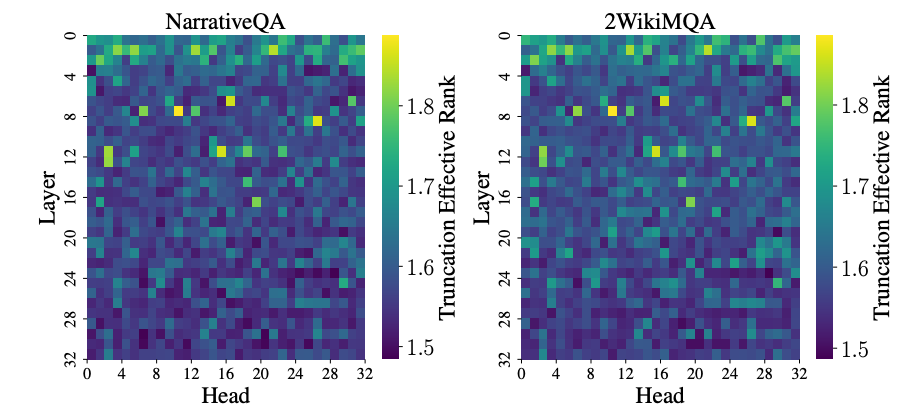
识别关键结构:中间层信息熵的异常波动点,精准地对应了负责信息聚合的检索层 (Retrieval Layers)和负责长程记忆的检索头 (Retrieval Heads)。我们不再是盲目压缩,而是有理论指导的结构化剪枝。

-
最优压缩的奥秘:我们进一步分析发现,最佳的压缩性能和最终的准确率的权衡并非来自于寻找最优的累计注意力分布,而是来自于对“信息流模式”的模仿。我们用皮尔逊相关系数证明:当压缩后KV Cache的逐层熵变趋势,与原始全尺寸Cache的趋势高度相似时,模型性能最好。 这意味着,我们的压缩策略成功地保留了模型原有的信息压缩模式。

-
Group Query Attention结构中呈现出明显的头共享的稀疏模式,
首创:从隐藏状态压缩到KV Cache优化
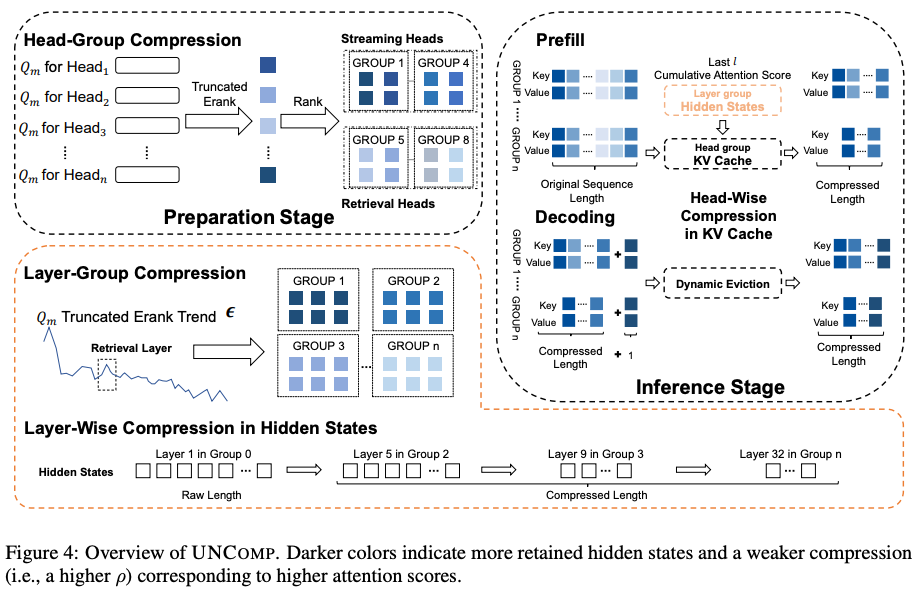
基于以上理论,我们设计了UNCOMP框架,并首次通过直接压缩Prefill阶段的隐藏状态,来间接优化KV Cache,实现了计算与内存的联合优化。
-
层级压缩 (Layer-wise): 在Prefill阶段压缩隐藏状态,加速计算。
-
头级压缩 (Head-wise): 在Decoding阶段压缩流式头的KV Cache,保留检索头,节省内存。
实验结果亮点
-
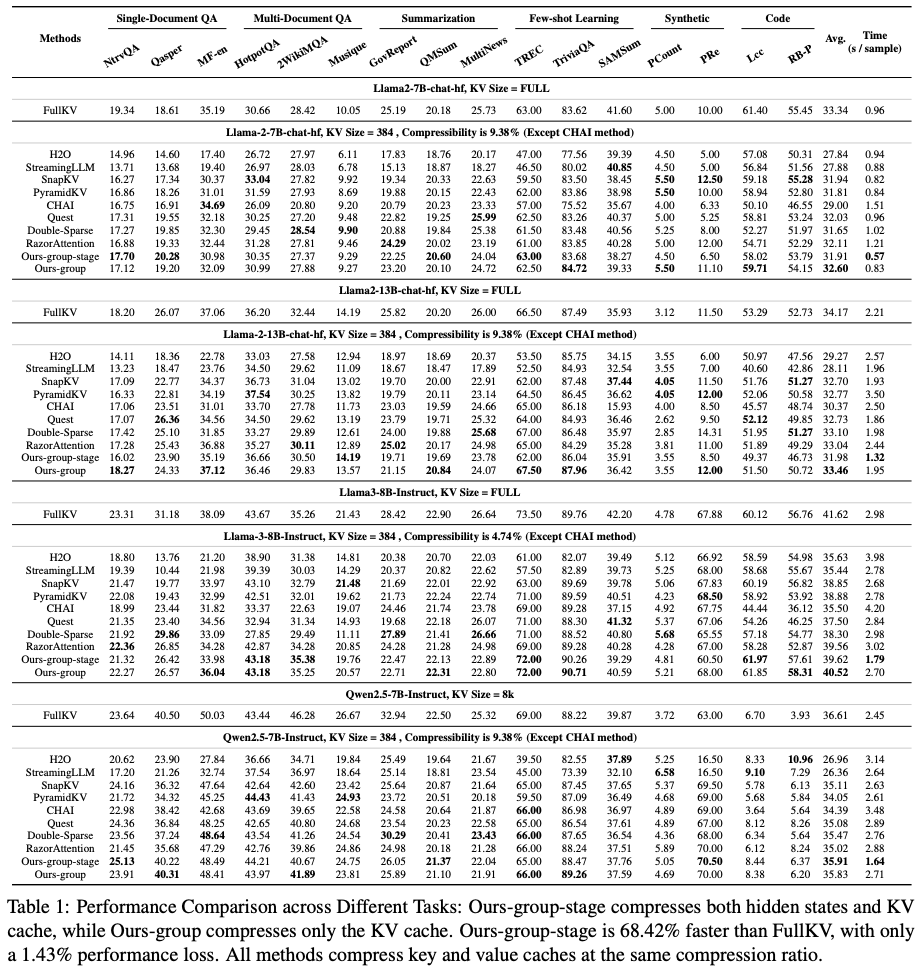
Prefill阶段加速60%
-
吞吐量提升6.4倍
-
KV Cache压缩至4.74%
-
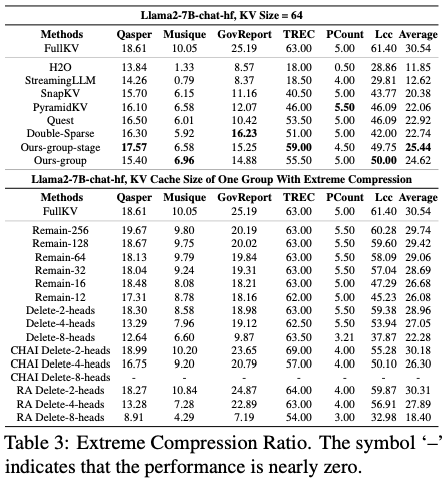
极端压缩率下依旧保证模型的性能
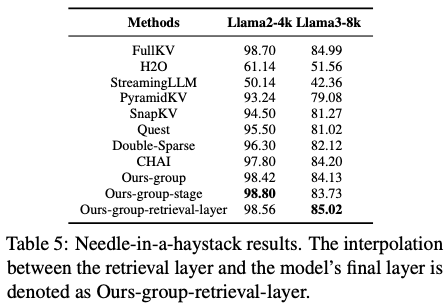
-
通过合并检索层和最后的层大海捞针性能几乎无损,在特定任务上超越全尺寸基线。
我们相信,UNCOMP不仅是一个工具,更是一扇窗口,帮助我们理解LLM内部复杂的信息压缩行为。
欢迎大家深入探讨、引用和 star!



火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)