大模型+目标检测+手部关键点检测:让AI看懂世界,为你讲述万物之美
本文介绍了一种融合大模型与视觉识别技术的人机交互系统,通过目标检测(YOLO)、手部关键点识别和BLIP大模型,实现AI对世界的智能描述。用户可通过手势圈选特定区域,系统会实时分析并生成语音描述(如"手机屏幕上显示着一只猫"),还能自定义描述细节。该技术方案实现了"视觉理解-语言生成-语音输出"的完整交互闭环,源代码支持有偿获取。
·
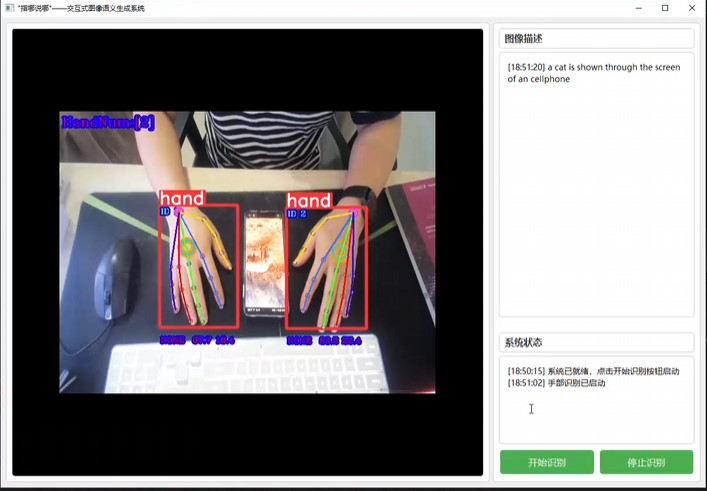
结合大模型技术,通过人机交互,让计算机具备“看”与“说”的能力,让AI去给你“描述”世界。效果如下:
大模型+目标检测+手部关键点检测:让AI看懂世界,为你讲述万物之美
借助手势交互识别画面特定区域,通过大模型分析区域内容并生成语音描述。例如,当用户用手势圈选手机屏幕时,系统会智能识别并语音播报:"手机屏幕上显示着一只猫"。当然,你还可以去控制描述的细节与内容~
使用算法:
1.BLIP
2.YOLO
3.手部关键点
如果需要源代码可与我联系(有偿)~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)