KV cache原理
文章摘要:本文介绍了decoder-only transformer的生成流程及KV cache优化技术。首先,输入prompt经过tokenizer和embedding层转换为词向量矩阵,再通过线性变换得到Q、K、V矩阵。在多头注意力机制中,通过mask保留注意力矩阵的下三角部分,与V矩阵相乘后得到上下文信息。KV cache通过缓存K和V矩阵,避免重复计算历史token的注意力分数,仅对新to
decoder-only transformer 过程
在学习KV cahe之前必须要清楚decoder-only transformer的整个详细流程。
首先prompt经过tokenizer会被划分成一个个token。
其次tokens会经过embedding层变为一个个word vector,这些vector组成了matrix。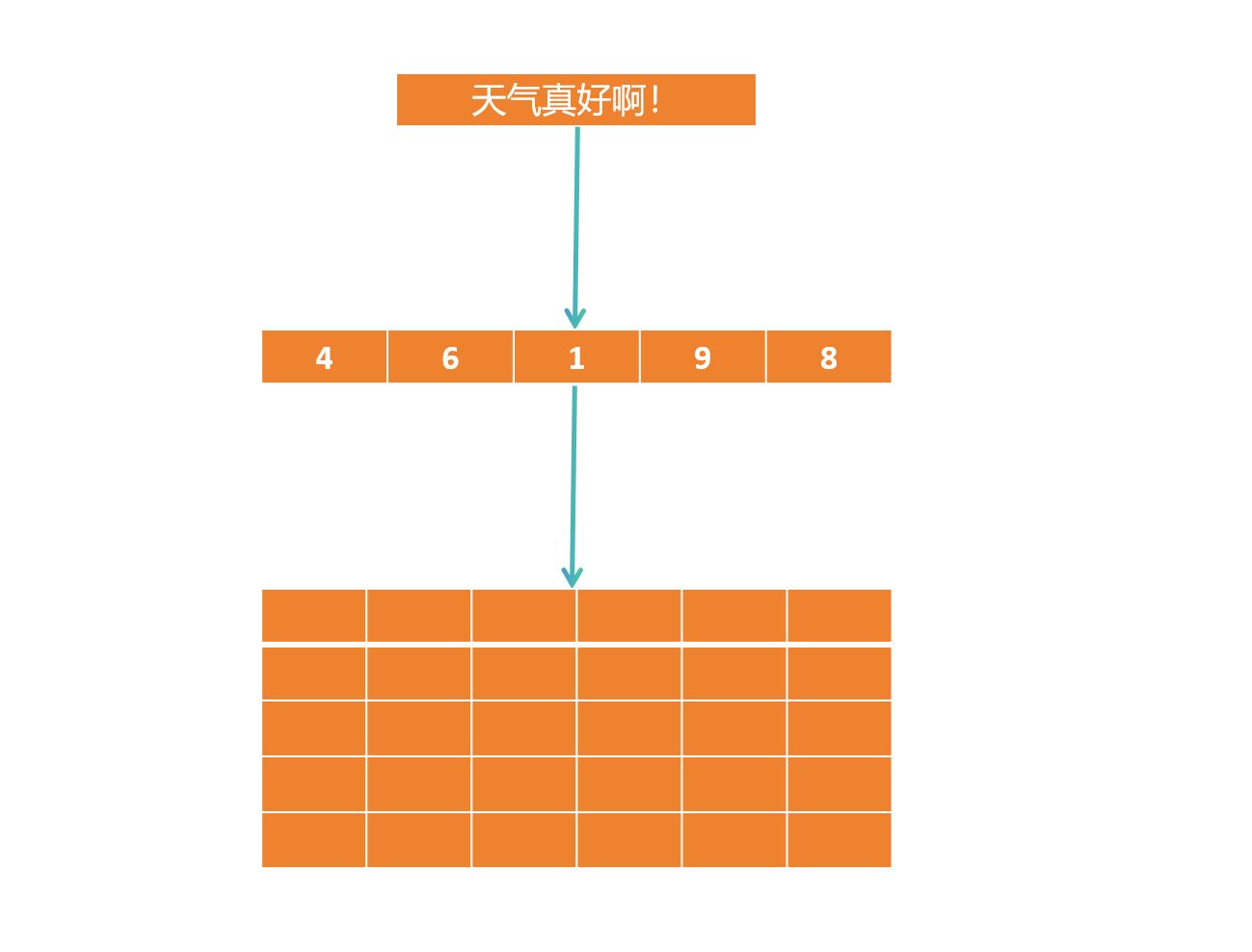
这里我们简化过程忽略掉位置编码这一过程的处理,假设已经经过位置编码(相对、绝对均可)。
于是下一步会对这些词向量进行线性变换,得到变换后的Q,K,V矩阵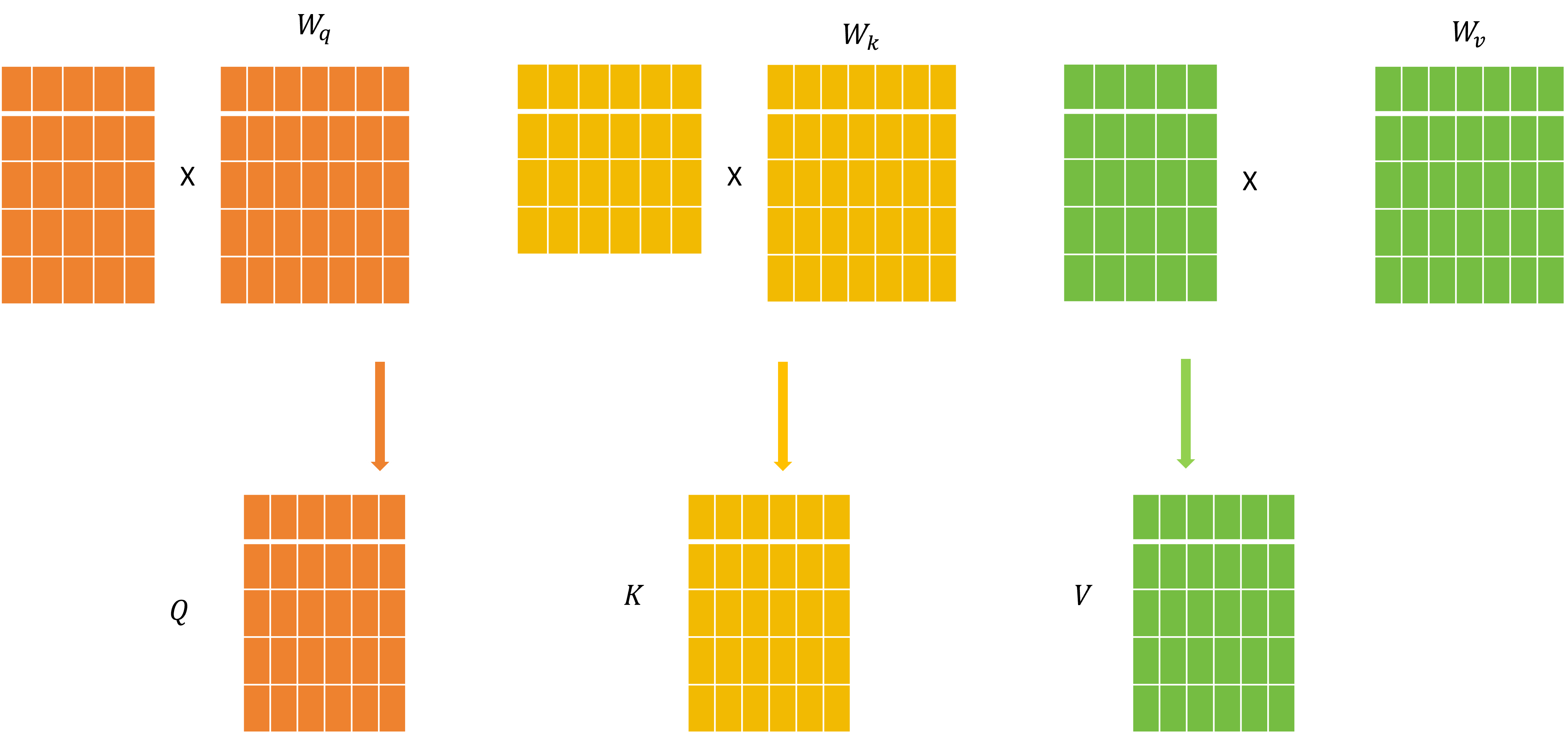
然后下一步需要进入多头注意力机制,于是就需要将Q、K、V矩阵拆分得到m组Q、K、V。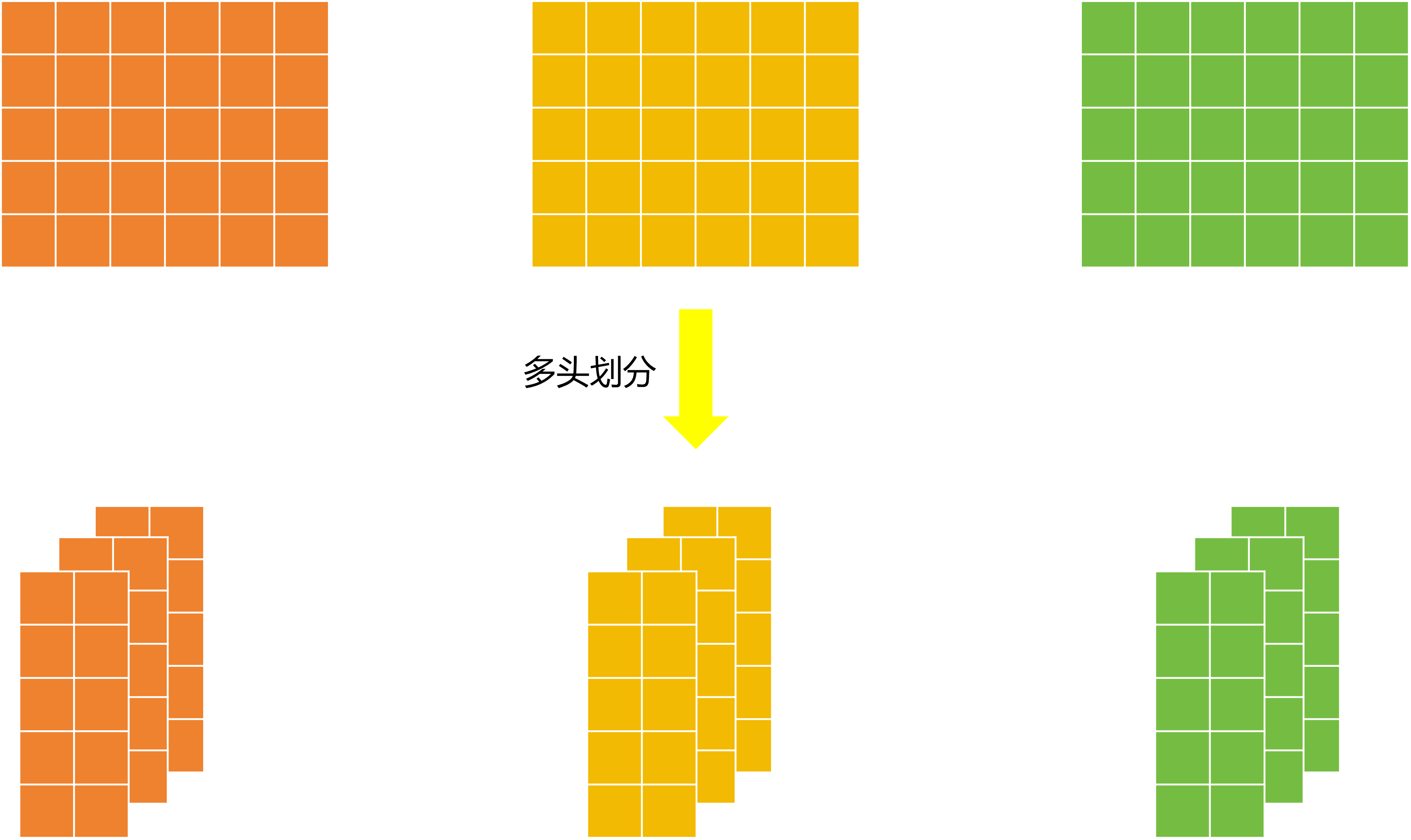
然后m组Q和K进入注意力机制层进行注意力分数的计算,得到m个注意力矩阵。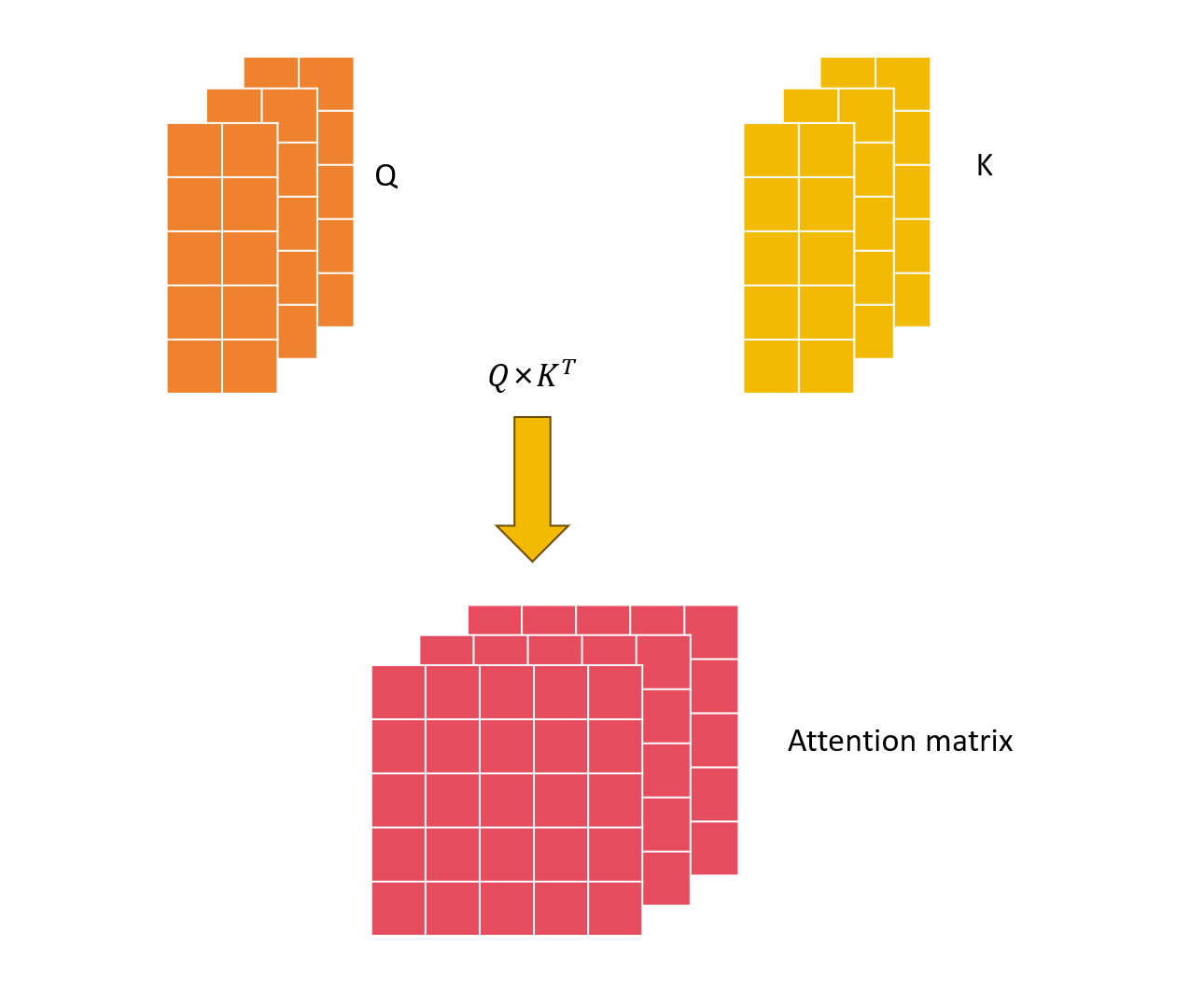
然后会对这个attention矩阵进行mask,只保留下三角的内容。
下一步将Attention matrix和V相乘得到的结果在进行拼接,得到的结果就是加入了语音信息的sequence。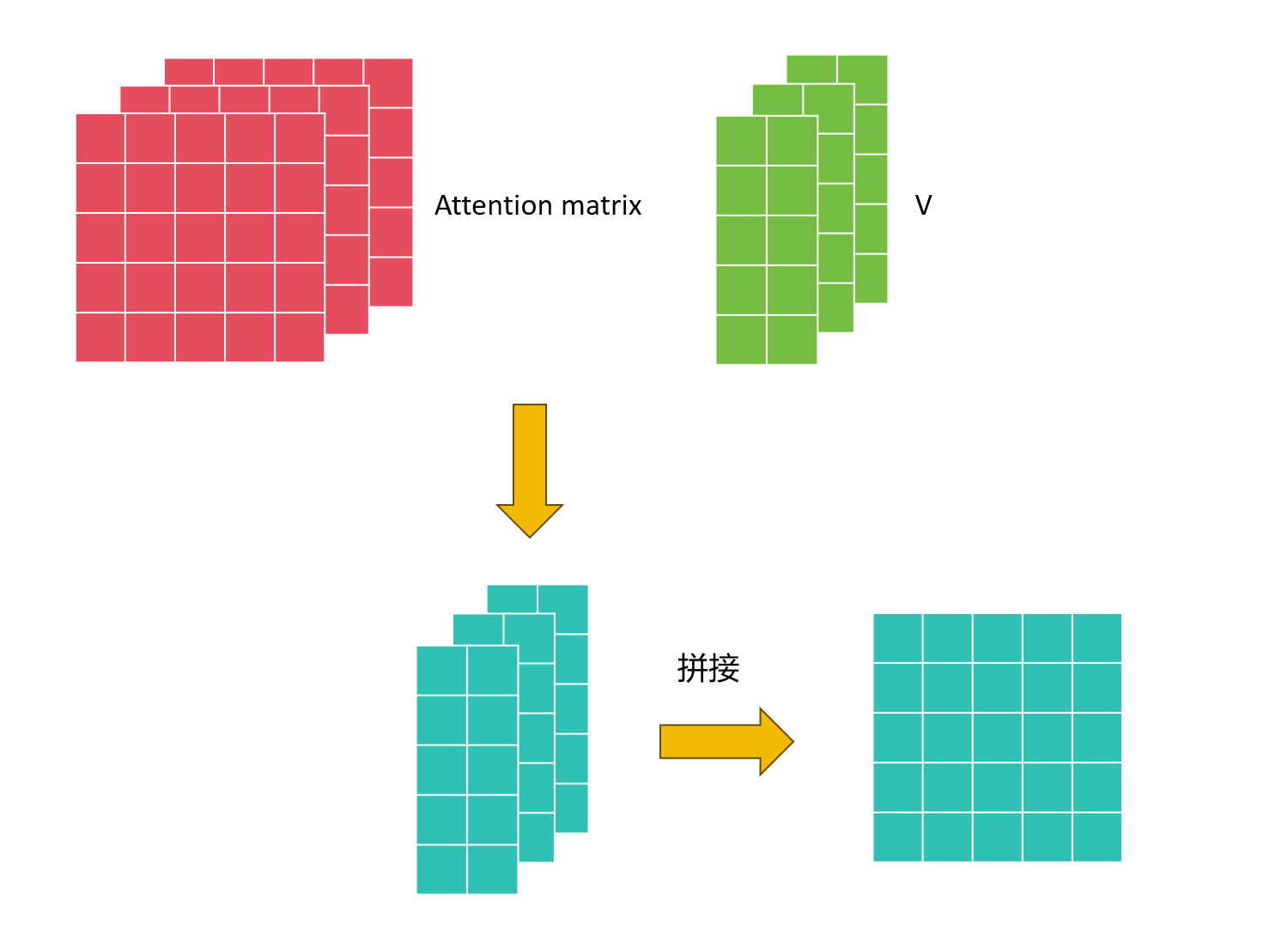
然后再经过一个FFN,将特征维度映射到词表大小,最后经过一个softmax分类头就能得到下一次词的概率。
KV cache
kv cache顾名思义就是缓存K和V。
不难发现随着序列增长,attention matrix的计算量是平方增长的。
对于新生成一个token,attention中需要重新计算的内容其实只有新token与其他token的注意力分数,而前面已经生成的token之间的注意力分数其实并不需要计算。
于是我们将K矩阵进行缓存,然后将新来的token,分别与 W q 、 W k 、 W k W_q、W_k、W_k Wq、Wk、Wk相乘得到一组线性变换的向量。
然后将这组向量与缓存的K矩阵相乘即可得到新token与前面所有token的注意力分数(形状1×n),(得到的注意力权重,其实就是上下文信息,也就是和其他token相关的权重),然后还需要V来和分数加权,所以这里需要缓存V矩阵。
KV cache的本质感觉更像一种增量算法,因为后面生成的内容不会对前面的token的产生影响,所有只需要维护新增内容即可。
前面将新token的vector经过与 W q 、 W k 、 W k W_q、W_k、W_k Wq、Wk、Wk进行线性变换,并进行多头划分。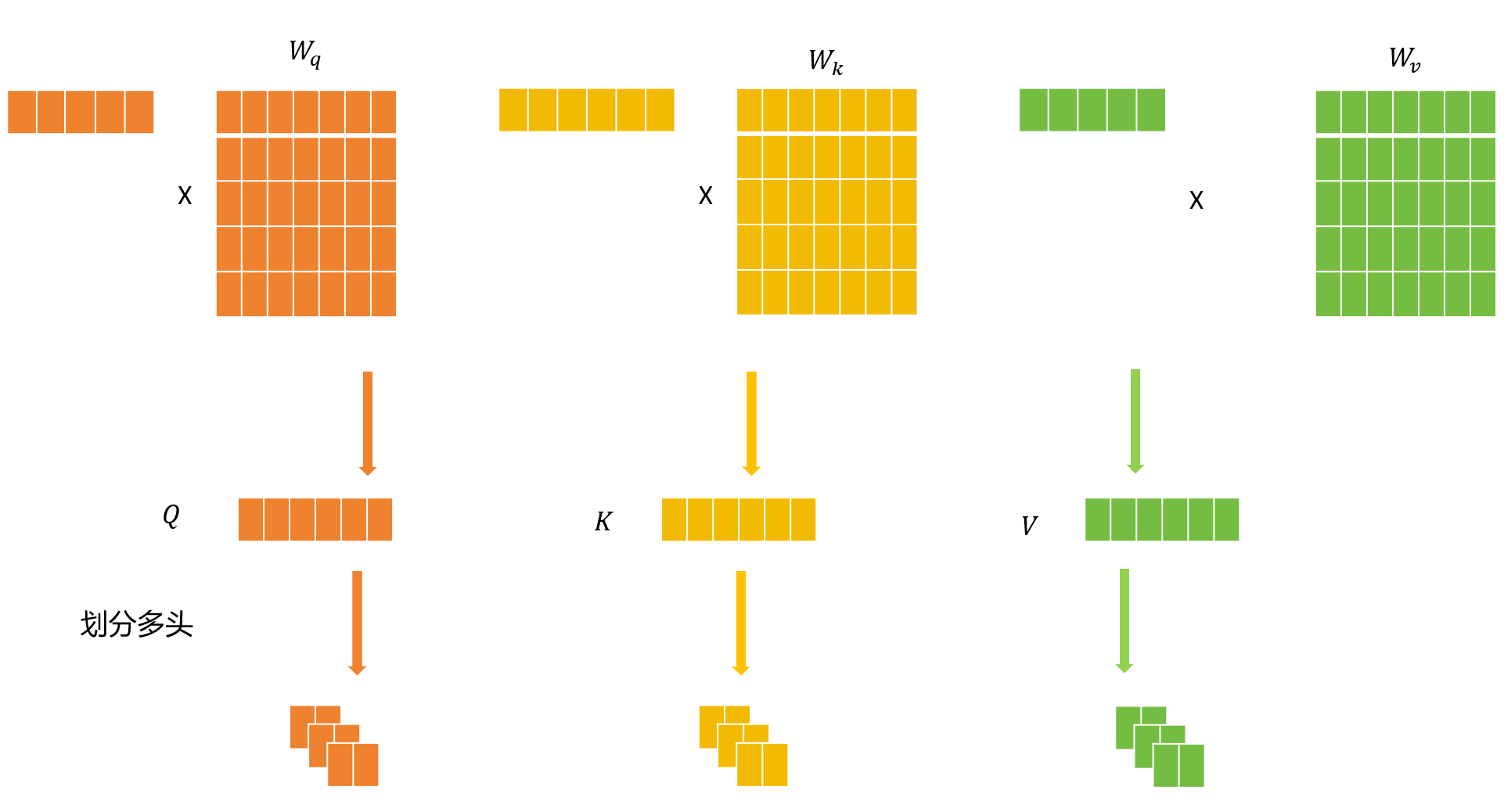
将Q和缓存的K值进行注意力计算。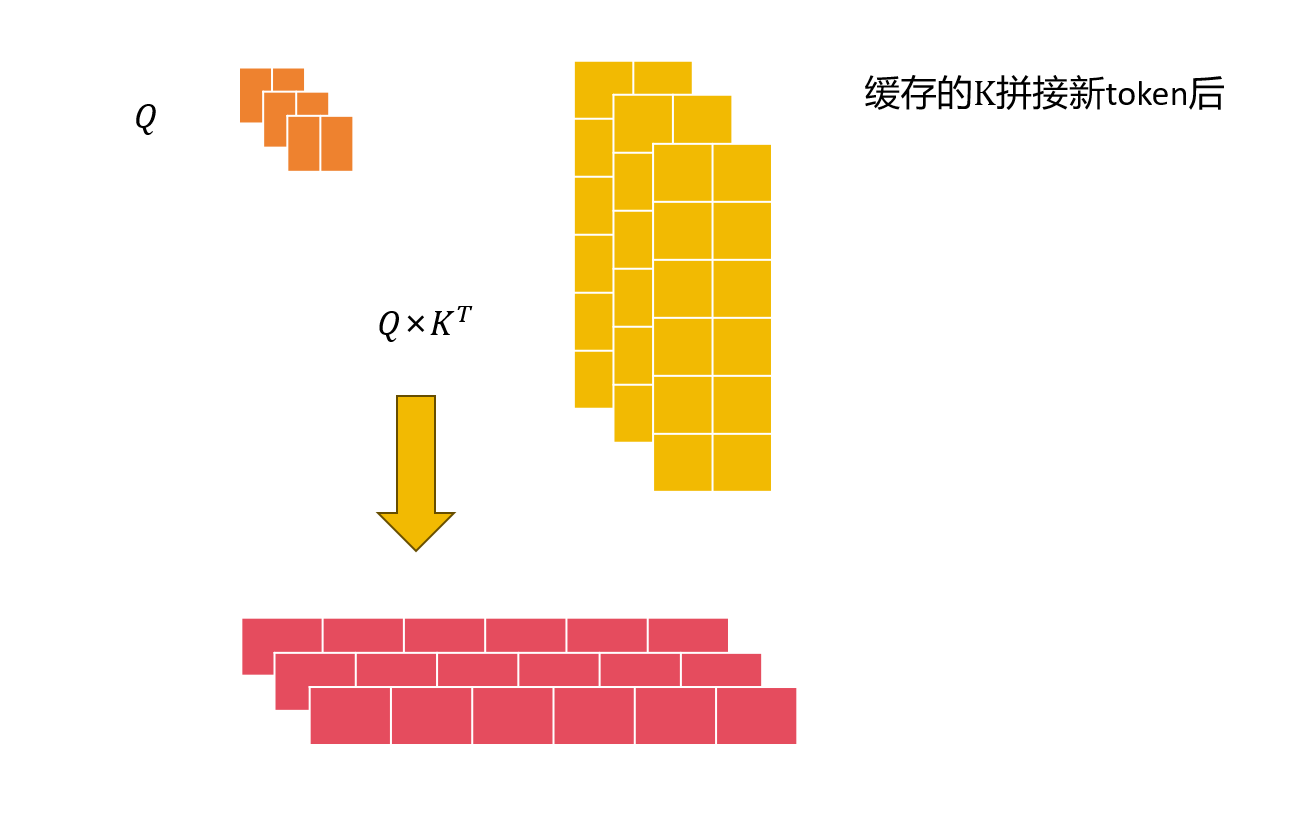
然后进行注意力权重和V的加权,最后再进行线性变换称为(1×vocab_size),然后经过一个softmax分类头得到一个概率分布,即为基于前面所有token信息,对下一个token的概率分布的预测。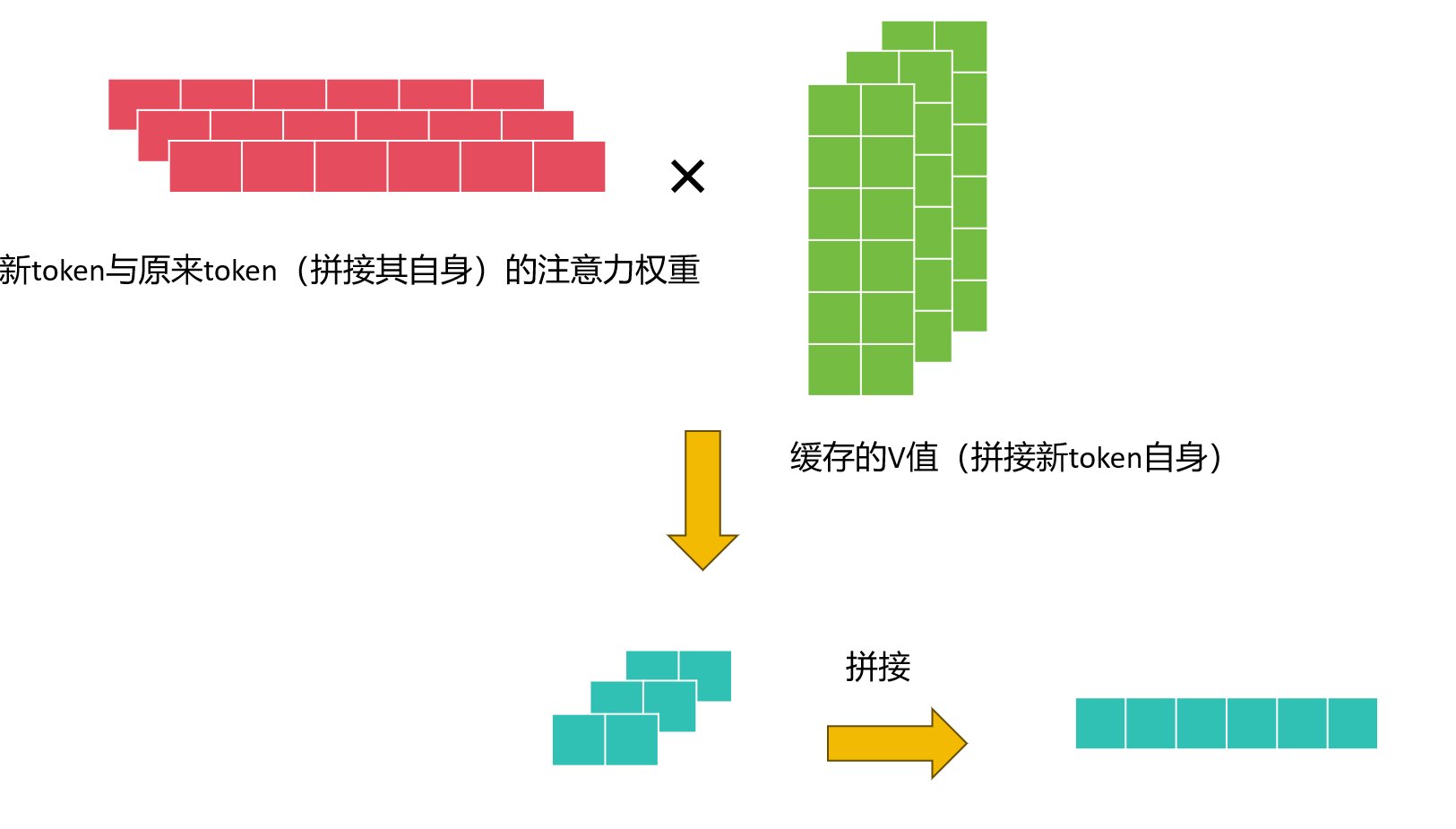
总结
KV cache本质上是一种增量算法,避免了attention中大量的重复计算,大大减少了计算量。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)