第1章:大模型基础认知
AI 即人工智能,是模拟人类智能、让机器自主执行任务的交叉学科。大语言模型(LLM)作为 AI 核心方向,依托机器学习和深度学习,因硬件进步、算法优化等因素兴起,具备数据、规模、算力、参数量大等特点,分为开源和闭源两类,各有透明度、定制化等维度的优劣。常见大模型有 DeepSeek、通义千问、GPT 等,版本编号、参数量(如 72B)、上下文窗口(如 1M)等是其核心区分标识。大模型已赋能金融、政
AI大模型实战营
本章:大模型基础认知
下章:提示工程特训和实战
沉淀分析成长⭐,我们一起进步❗️
人工智能演进与大模型兴起
什么是AI?
- AI是人工智能的缩写,它是一种模拟人类智能的技术;
- 使机器能够像人一样学习,思考和做出决策,从而能够自主地执行各种任务;
- 时至今日,人工智能的内涵已经大大扩展,是一梦交叉学科。
AI1.0到2.0的变迁:
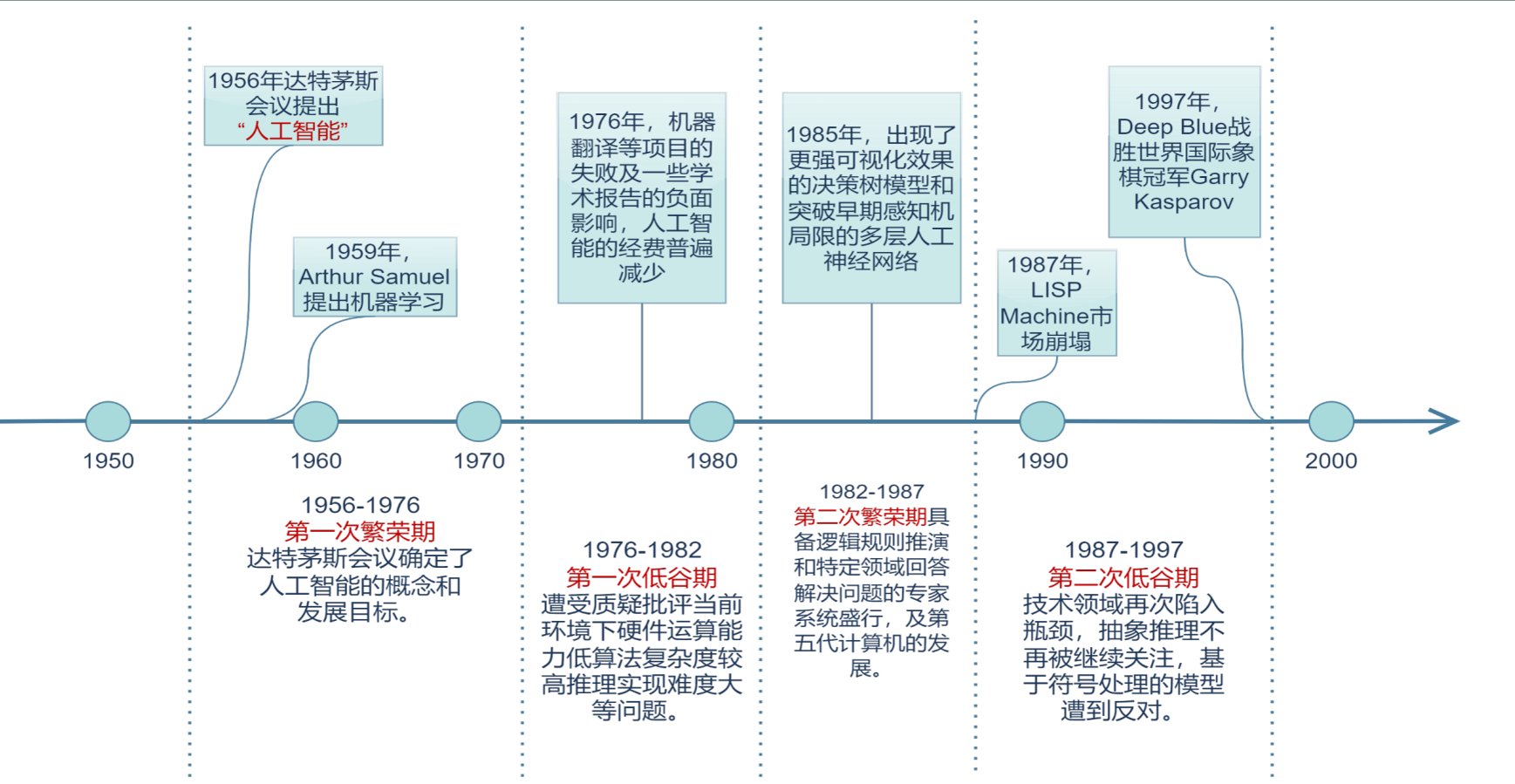
|
工业革命(18世纪末-19世纪初) |
蒸汽机 |
提供了新的动力来源,推动了运输、制造业等领域的机械化。 |
|
第二次工业革命(19世纪末-20世纪初) |
电力 |
改变了照明、通信、制造等多个行业的运作方式,极大地提高了生产效率。 |
|
20世纪中叶 |
计算机 |
开启了信息处理的新纪元,对科学研究、商业管理、教育等领域产生了深远影响。 |
|
信息时代(20世纪末-至今) |
互联网 |
连接全球的信息网络,改变了人们的沟通、学习、工作及娱乐方式,成为现代社会的基础架构之一。 |
|
数字时代(21世纪) |
人工智能(AI) |
正在改变多个行业的工作流程,从医疗保健到金融服务,再到自动驾驶汽车等,展现了巨大的潜力和广泛的应用前景。 |
机器学习:
- 专门研究计算机怎么样模拟和实现人类的学习行为;
- 以获取新的知识或技能;
- 重新组织已有的知识结构使之不断改善自身的性能。
深度学习:
- 深度学习的概念源于人工;
- 神经网络的研究,深度学习模仿人脑的机制来解释数据;
- 例如图像,声音和文本。

大模型
大模型的全称为大语言模型,英文为Large Language Model ,也叫LLM
- 是一种基于机器学习和自然语言处理技术的模型;
- 它通过对大量的文本数据进行训练,来学习服务人类语言的理解和生成的能力。
大模型的特点:
- 数据量大;
- 规模大;
- 算力大;
- 参数量大;
- 具备强大泛化能力的预训练模型。
为什么大模型会兴起?
- 硬件进步:GPU,TPU等高性能计算设备的普及,使得训练大模型成为可能;
- 算法优化:如Transformer架构的提出,极大提升了模型处理长序列数据的能力;
- 数据爆炸:互联网文本,图像,视频等数据量激增(部分数据集达到PB级),为大模型训练提供燃料;
- 分布式训练:大规模分布式计算框架(如PyTorch,TensorFlow)的成熟,支持高效训练大模型。
大模型和通用人工智能:
- 通用人工智能:简称AGI,是指一种智能,能够理解,学习和应用知识和技能,需要能够处理极其广泛的问题和环境,具有很高的适用性,自主性和创造性。
- AIGC:是利用人工智能技术能够自动生成文本,图像,音频,视频等内容;
- AIGC的快速发展为AGI提供了部分技术积累,但AGI需要突破认知,推理等更高层能力。
常见大模型
- 目前国内外提供的大模型很多,OpenAI、文心(百度)、通义千问(阿里)、DeepSeek、星火(科大讯飞)、盘古(华为)等等。
- 国外大模型GPT等,在访问上需要额外处理,在目前大环境下不是我们的最好选择,而且性价比不高。
|
模型名称 |
开源 or 闭源 |
发布公司 |
主要特点 |
关键技术 |
|
DeepSeek |
开源 |
深度求索 |
专注于视觉与语言多模态结合,支持图像生成与推理 |
多模态学习、Transformer架构 |
|
通义千问(Qwen) |
开源 |
阿里巴巴 |
开源大模型,支持中文理解与生成,具备强大的推理能力 |
GPT-3架构优化 |
|
智谱清言(GLM) |
开源 |
智谱科技 |
聚焦中文NLP,强大的跨行业能力 |
自监督学习、Transformer架构 |
|
豆包(Doubao) |
闭源 |
字节跳动 |
生成式AI产品,强调多轮对话和情感理解,生成符合上下文的文本 |
GPT-3架构、知识增强 |
|
混元(Tencent Hunyuan) |
开源 |
腾讯 |
提供多模态AI能力,支持文本、图像、视频等多种数据类型的处理 |
多模态融合、深度学习 |
|
Kimi |
开源 |
月之暗面 |
专注于自然语言处理,提供高效的文本生成和理解能力 |
自监督学习、Transformer架构 |
|
GPT |
闭源 |
OpenAI |
强大的自然语言处理能力,支持多种语言任务 |
Transformer架构、大规模预训练 |
|
Claude |
闭源 |
Anthropic |
专注于生成安全和可靠的文本,支持长文本生成 |
Constitutional AI、Transformer架构 |
|
LLama |
开源 |
Meta |
开源大模型,支持多种语言任务,注重效率和可扩展性 |
Transformer架构、自监督学习 |
|
Gemini |
闭源 |
|
多模态模型,支持文本、图像和视频处理 |
多模态学习、Transformer架构 |
开源大模型 VS 闭源大模型
|
维度 |
开源大模型 |
闭源大模型 |
|
透明度 |
代码、数据、训练流程公开,可审查模型行为 |
黑箱操作,用户无法验证内部逻辑或数据来源 |
|
定制化能力 |
支持微调、领域适配,灵活适应特定任务 |
仅限API功能,无法修改模型结构或调整底层参数 |
|
成本控制 |
可本地部署,长期成本固定(硬件投入为主) |
按使用量付费(如Token计费),大规模应用成本高 |
|
性能上限 |
受限于社区资源,通常弱于头部闭源模型 |
依托大厂算力与数据,推理、多模态等能力更强 |
|
维护复杂度 |
需自行管理基础设施、安全更新和技术支持 |
供应商负责运维,用户无需关心底层技术细节 |
|
合规与隐私 |
数据完全本地化,满足严格隐私要求 |
依赖第三方API,数据需上传至外部服务器,存在泄露风险 |
常见大模型版本区分
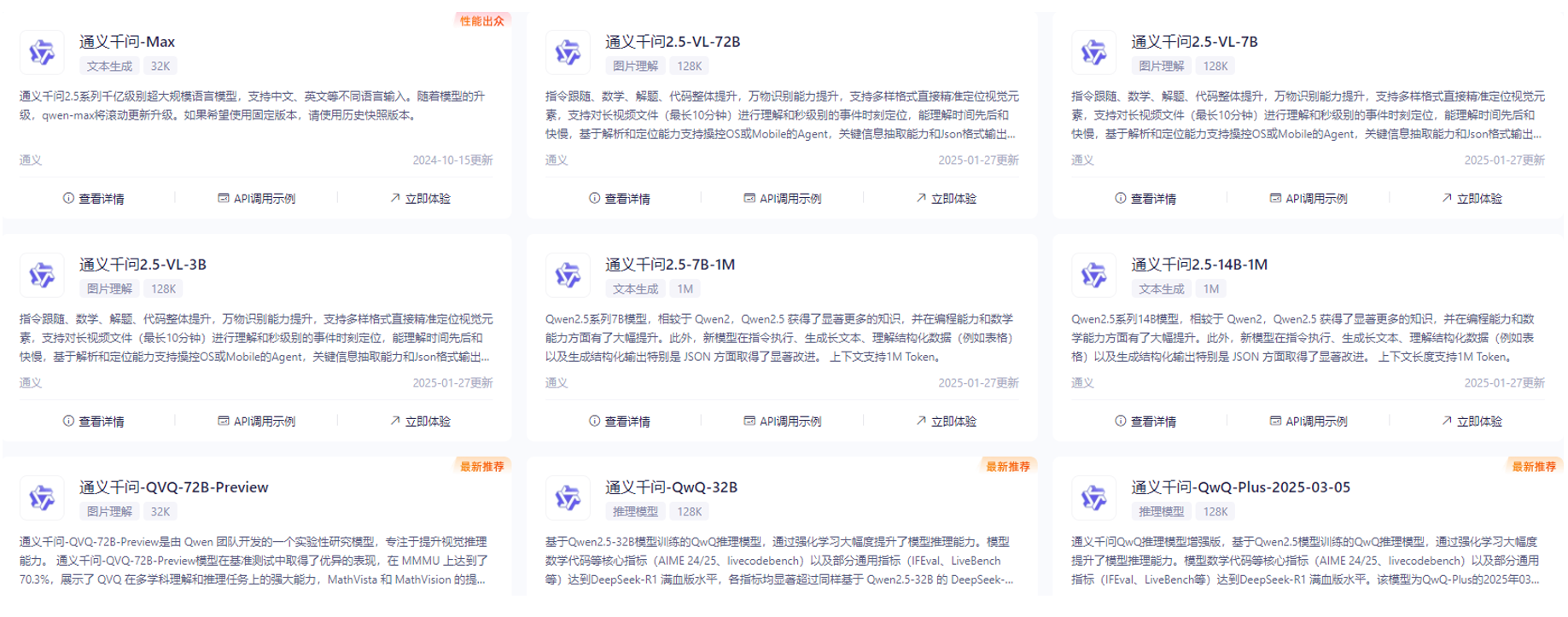
- 通义千问 2.5:这是通义千问第 2.5 代通用模型;
- 版本编号 (如 0314、2025-03-05):这些数字通常代表模型的发布或修订日期;
- 72B:指大模型的内部参数量,比如还有 DeepSeek 满血版 DeepSeek-671B,1 个 B 为 10 亿;
- 1M:这个标签通常指的是模型处理文本时的最大 token 数(或“上下文窗口”大小)。32k 意味着模型能够在一个实例中处理最多 32,000 个 token。这对于处理长文本特别有用;
- Turbo:这可能指的是模型的一个优化版本,旨在提高速度和效率,可能在保持生成质量的同时减少了资源消耗;
- Preview:这通常意味着该模型是供早期访问、测试或预览的版本。它可能不是最终的商业版本,但提供了对即将发布功能的早期查看;
- 带 V 字:这意味着模型被设计或优化以处理视觉数据,比如图像或视频。
大模型行业赋能
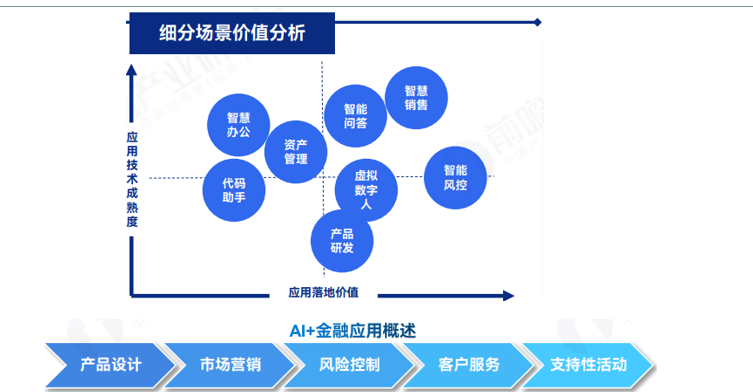
大模型+金融

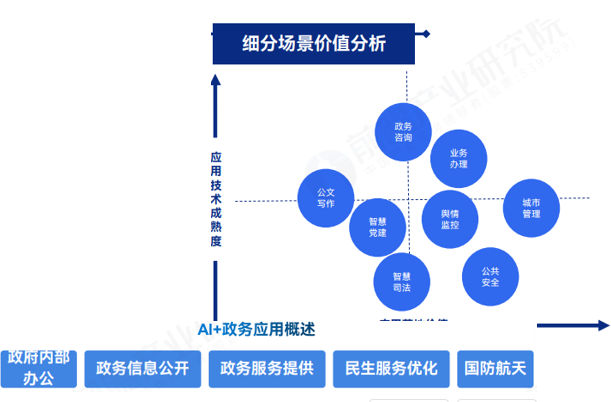
大模型+政务
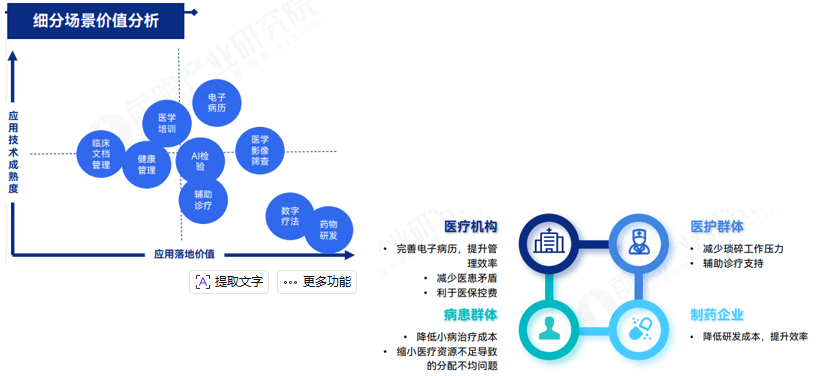
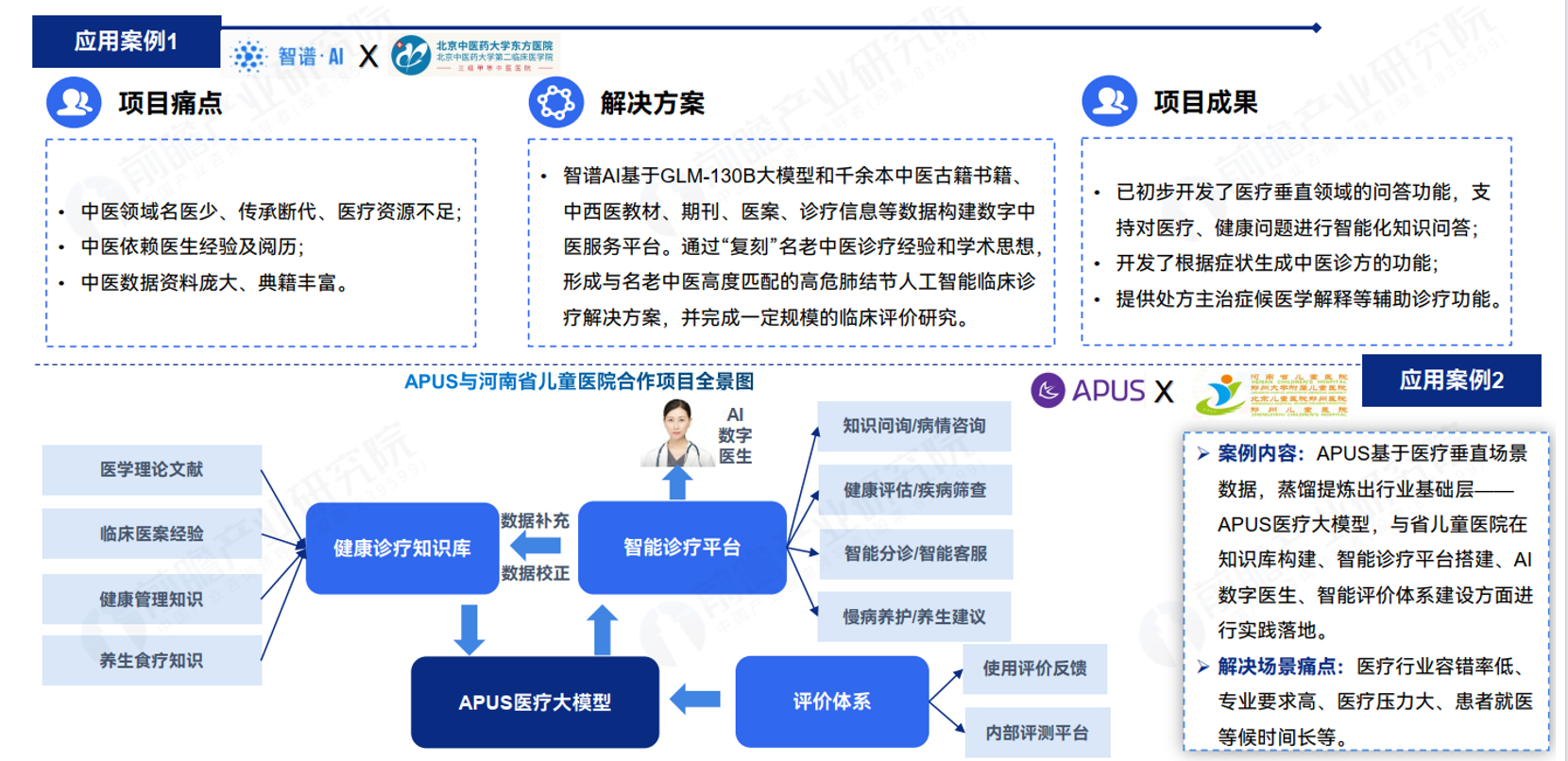
大模型+金融
大模型+法律/游戏
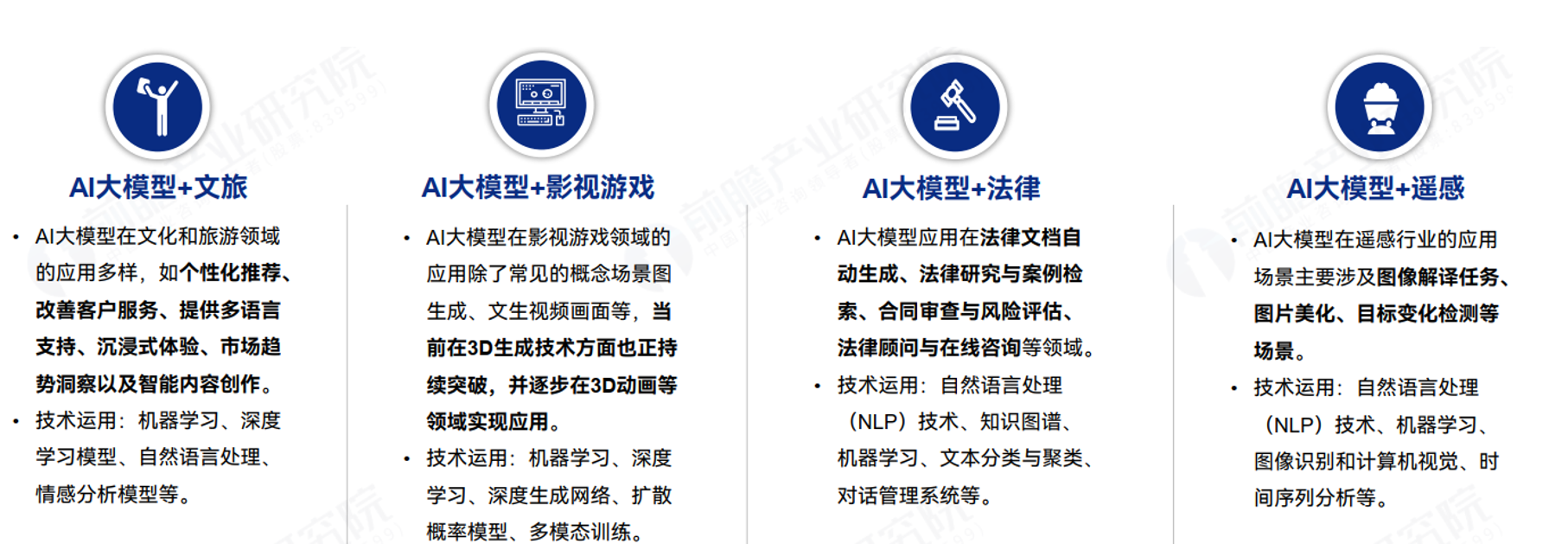
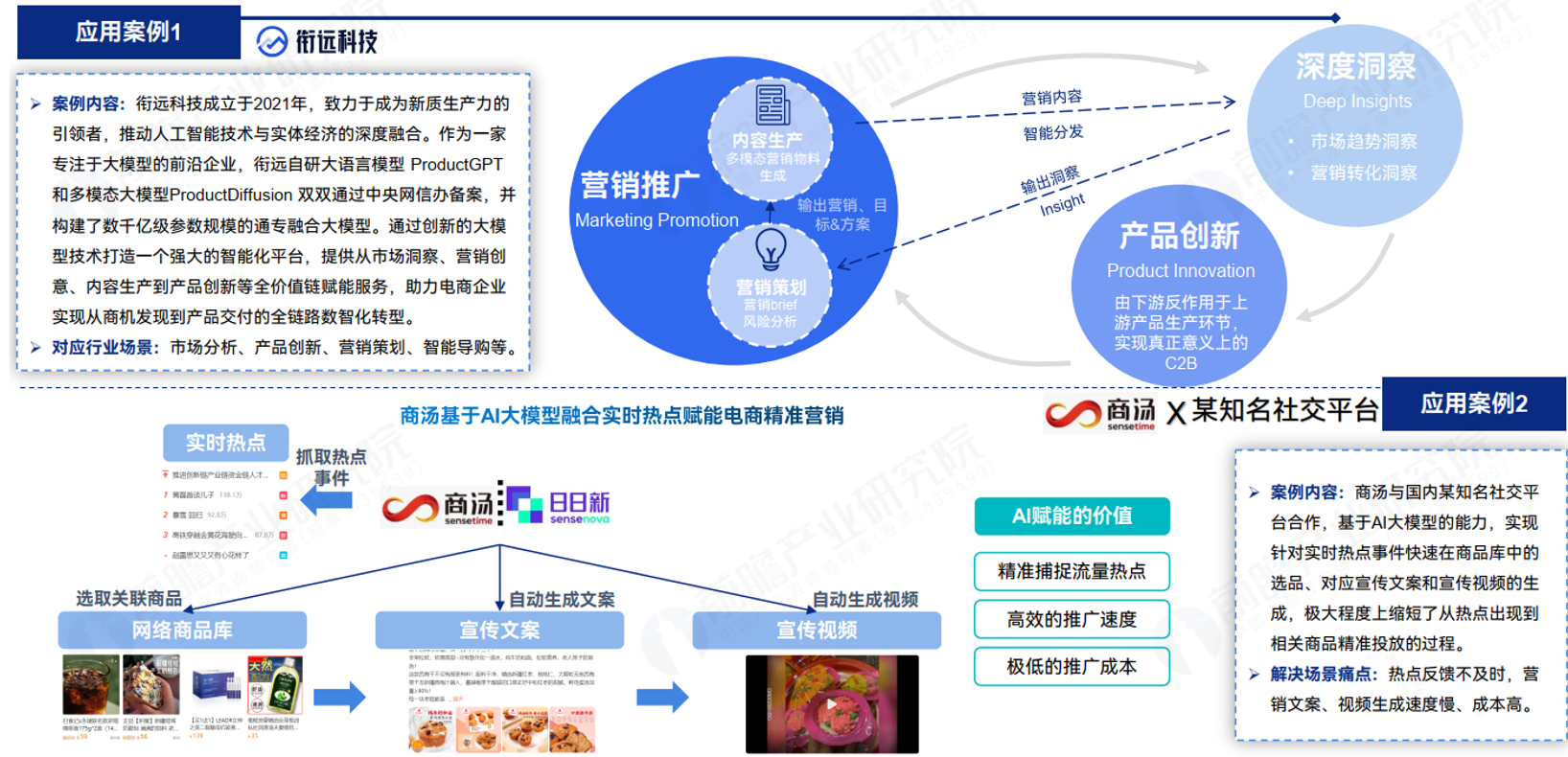
大模型+电商
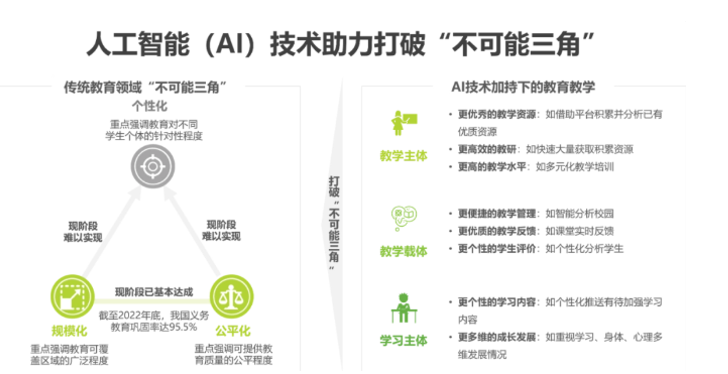
大模型+教育
大模型的趋势和挑战
发展趋势:
- 技术突破:更大、更高效、更智能
-
- 模型规模的进一步扩大;
- 模型效率的提升;
- 多模态能力的增强;
- 可解释性和透明性的提升。
- 应用落地:垂直化与普惠化模型规模的进一步扩大
-
- 定制化和专用化,行业大模型爆发;
- 边缘端部署;
- UGC+AIGC生态融合。
大模型的挑战:
- 安全问题
-
- 伦理和安全问题;
- 数据和模型的治理;
- 人机协作的优化。
- 均衡问题
-
- 资源消耗和环境影响;
- 技术普及的不均衡。
大模型开发Hello World
基本步骤:
- 注册用户(阿里云注册地址);
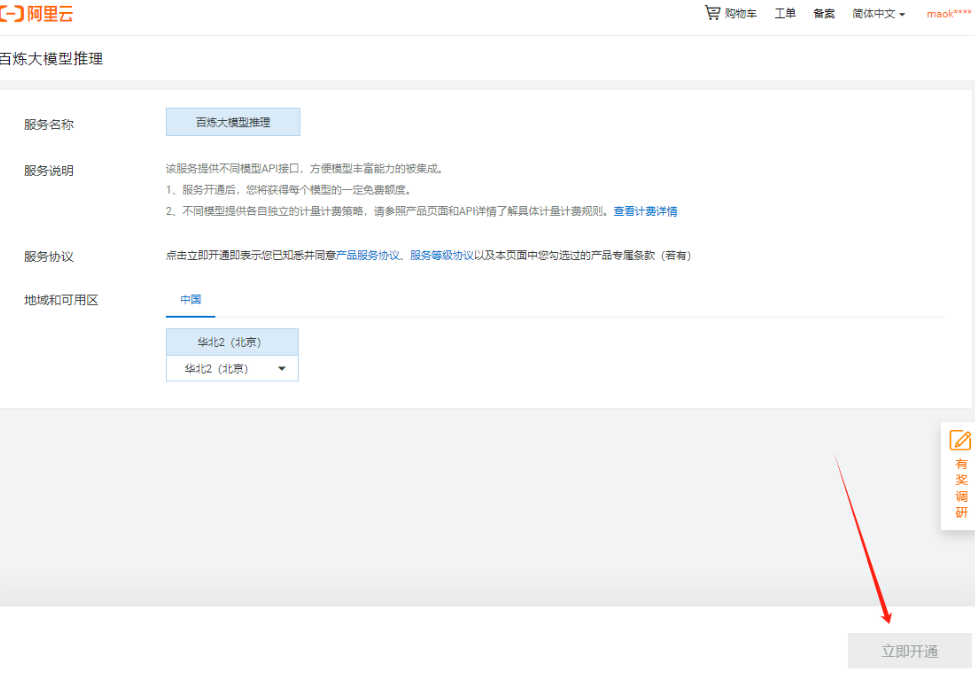
- 开通大模型功能;
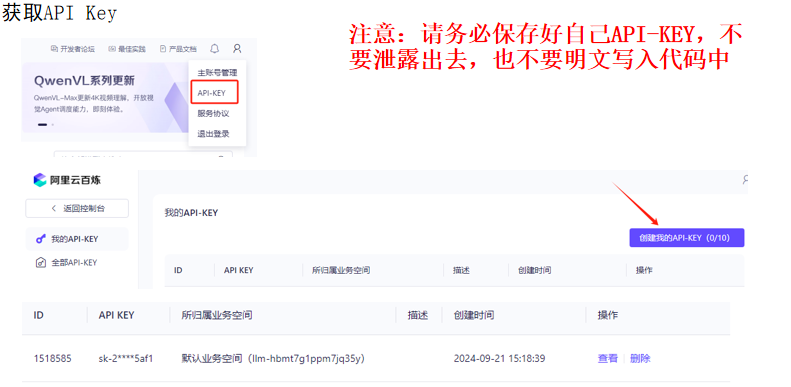
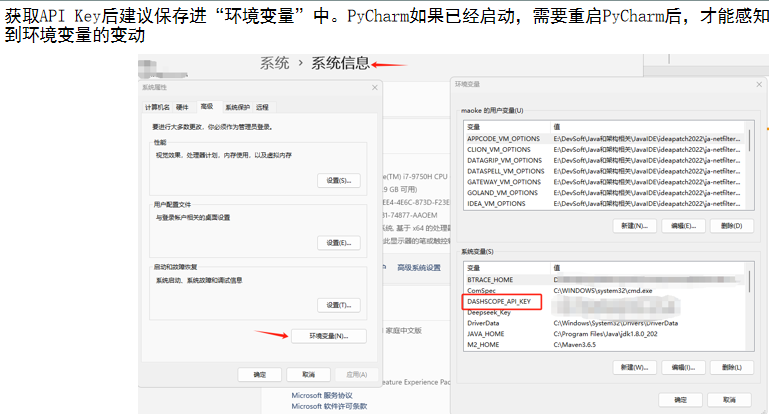
- 获取API Key,配置环境变量;
- 通过代码调用API 实现功能。
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model = "qwen-plus",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message.content)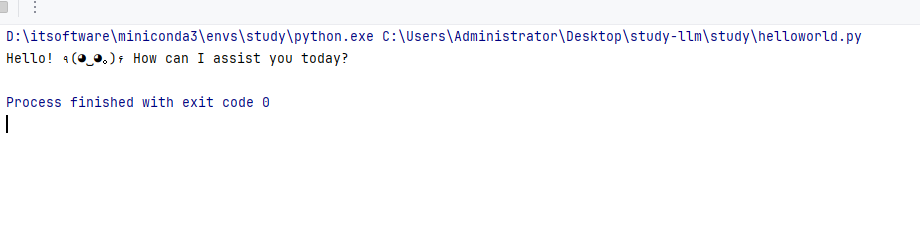
注意我们需要先安装openai依赖
pip install openai
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)