DianJin-R1:评估和增强大型语言模型中的金融推理能力
我们提出了DianJin-R1,一个旨在通过推理增强监督和强化学习来解决这些挑战的推理增强框架。我们方法的核心是DianJin-R1-Data,一个从CFLUE、FinQA以及专有合规语料库(中文合规检查,CCC)构建的高质量数据集,它结合了多样化的金融推理场景与经过验证的标注。我们的模型DianJin-R1-7B和DianJin-R1-32B基于Qwen2.5-7B-Instruct和Qwen2

基础信息
- DianJin-R1:评估和增强大型语言模型中的金融推理能力
- DianJin-R1: Evaluating and Enhancing Financial Reasoning in Large Language Models
- 2025年4月

摘要
有效推理仍然是金融领域大型语言模型(LLMs)面临的核心挑战,该领域任务通常需要领域特定知识、精确数值计算以及严格遵守合规规则。我们提出了DianJin-R1,一个旨在通过推理增强监督和强化学习来解决这些挑战的推理增强框架。 我们方法的核心是DianJin-R1-Data,一个从CFLUE、FinQA以及专有合规语料库(中文合规检查,CCC)构建的高质量数据集,它结合了多样化的金融推理场景与经过验证的标注。我们的模型DianJin-R1-7B和DianJin-R1-32B基于Qwen2.5-7B-Instruct和Qwen2.5-32B-Instruct进行微调,采用能够同时生成推理步骤和最终答案的结构化格式。 为进一步提升推理质量,我们应用了群组相对策略优化(GRPO),这是一种结合了双重奖励信号的强化学习方法: 一个鼓励生成结构化输出,另一个奖励答案的正确性。 我们在五个基准测试上评估了我们的模型:三个金融数据集(CFLUE、FinQA和CCC)以及两个通用推理基准测试(MATH-500和GPQA-Diamond)。实验结果表明,DianJin-R1模型持续优于其非推理对应模型,尤其在复杂的金融任务上表现突出。此外,在实际的CCC数据集上,我们的单次调用推理模型达到了甚至超越了需要显著更高计算成本的多智能体系统的性能。这些发现证明了DianJin-R1通过结构化监督和奖励对齐学习在增强金融推理方面的有效性,为实际应用提供了一种可扩展且实用的解决方案。
OCR 任务困境
- 大型语言模型难以处理需要领域专业知识和精确计算的专业金融推理任务
- 现有的金融合规性检查方法计算成本高昂,且缺乏强大的推理能力
解决思路
- 结合推理增强型金融数据上的监督微调和强化学习的两阶段训练
- 包含来自多个金融来源的经过验证的推理链的自定义数据集(DianJin-R1-Data)
- 采用格式和准确性奖励信号的组相对策略优化
结果
- 在所有金融推理任务上均优于非推理对应的模型
- 在合规性检查方面达到了与多智能体系统相当的性能
- 成功将推理能力应用于真实的中国金融合规场景
- 证明了监督学习与强化学习相结合在特定领域推理中的有效性
分析
- 在多样化的金融数据集上进行训练能够产生更强大的推理能力
- 具有明确推理步骤的结构化输出格式提高了模型性能
- 单模型方法能够以更低的计算成本匹敌甚至超越多智能体系统
论文解析

图 1:DianJin-R1 中使用的多智能体系统和推理数据生成过程,其中智能体分析合规性问题并生成结构化推理步骤。
DianJin-R1 利用两种关键方法来增强金融推理:推理增强监督和具有双重奖励的强化学习。通过专注于显式的中间推理步骤,而不是仅仅关注最终答案,模型可以学习分解复杂的金融问题并更准确地执行计算。
数据集构建
DianJin-R1 方法的基础是一个高质量的数据集(DianJin-R1-Data),专门为金融推理而设计。该数据集结合并增强了现有资源和新组件:
-
CFLUE (Chinese Financial Language Understanding Evaluation,中文金融语言理解评估):研究团队过滤了 CFLUE 数据集,以获取高质量、具有挑战性的示例,并将多项选择题转换为开放式格式,以促进更深入的推理。
-
FinQA: 该数据集侧重于金融文档中的数字推理,为定量金融分析提供了坚实的基础。
-
Chinese Compliance Check (CCC,中国合规性检查):一个专有数据集,包含基于真实金融服务交互的合规性验证场景。
开发过程涉及几个关键步骤:
- 过滤:删除低质量或模棱两可的示例,以确保数据集的完整性
- 转换:将多项选择题转换为开放式格式,以便进行更彻底的推理
- 推理标注:使用 DeepSeek-R1 和 GPT-4o 生成推理步骤,然后进行验证
- 多智能体生成:对于 CCC 数据集,采用多智能体系统来模拟监管专家并生成中间推理步骤
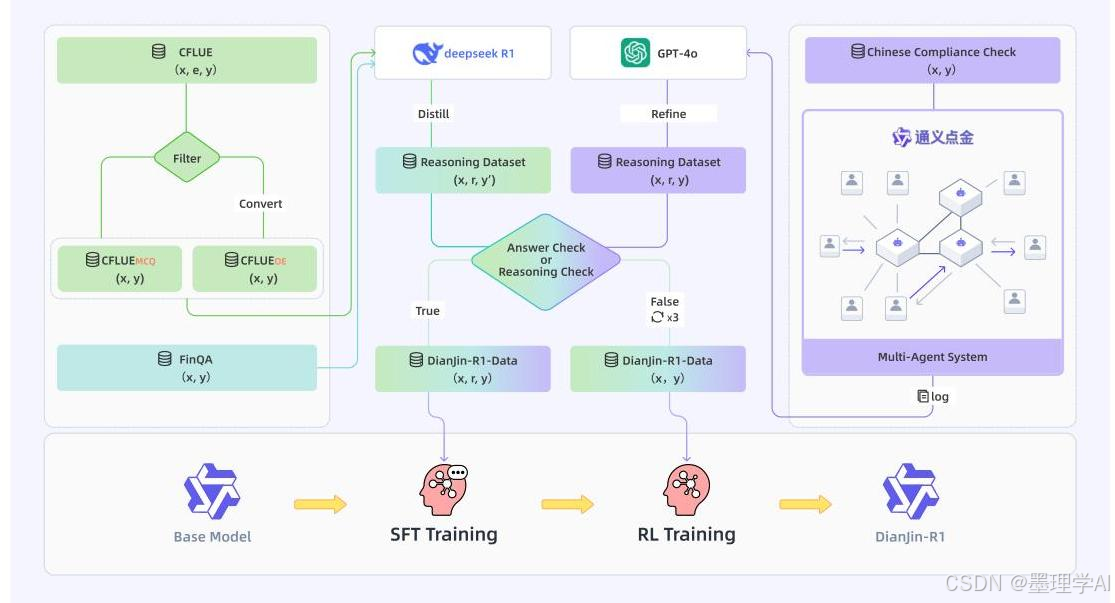
图 2:完整的 DianJin-R1 框架,展示了数据集构建、监督式微调 (SFT) 和强化学习 (RL) 阶段。
这种细致的数据集构建创建了两个关键集合:
- 具有显式中间步骤的推理增强数据集 (R_CFLUE_MCQ, R_CFLUE_OE, R_FinQA, R_CCC)
- 用于强化学习的困难的、非推理数据集 (G_CFLUE_MCQ, G_CFLUE_OE, G_FinQA, G_CCC)
方法
DianJin-R1 采用两阶段方法来增强金融推理:
1. 推理增强监督式微调 (SFT)
第一阶段涉及使用推理增强数据集对基础模型(Qwen2.5-7B-Instruct 和 Qwen2.5-32B-Instruct)进行微调。训练重点是教模型:
- 使用
<think>标签生成显式的推理过程 - 使用结构化的
<answer>标签生成最终答案 - 将复杂的金融问题分解为可管理的步骤
- 执行精确的计算和逻辑推导
这种结构化的方法有助于模型学习金融推理的过程,而不仅仅是记忆模式。
2. 强化学习 (RL)
在监督式微调之后,模型通过群体相对策略优化 (GRPO) 进一步改进,该优化使用两个关键的奖励信号:
- 格式奖励: 鼓励模型生成结构化的输出,清晰地分离推理和答案
- 准确性奖励: 通过奖励准确的最终答案来提高答案的正确性
RL 阶段主要使用来自 CFLUE 多项选择题的硬性、非推理数据集 (G_CFLUE_MCQ),重点关注需要复杂推理的挑战性问题。
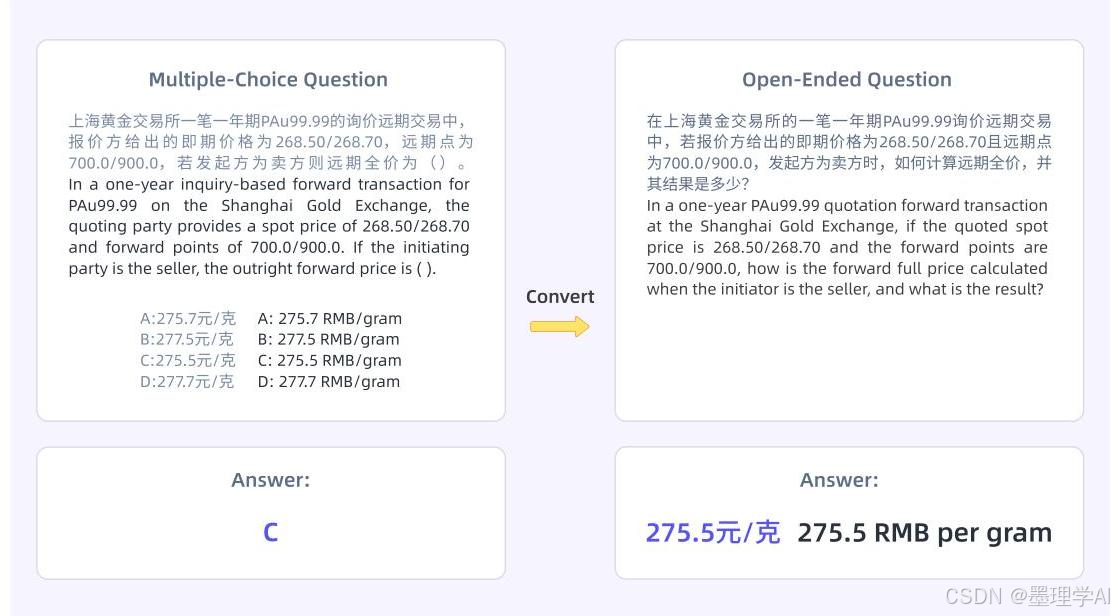
图 3:数据集中多项选择题和开放式金融问题的示例,展示了格式转换如何创建更具挑战性的推理任务。
训练过程
训练过程实施了几个技术优化:
-
结构化输出格式: 训练模型使用特定的标签(
<think>和<answer>)来区分推理步骤和最终答案。 -
数据混合策略: 仔细平衡不同数据集的比例,以确保在各种金融领域进行全面的学习。
-
质量控制: 实施验证机制,以确保生成的推理步骤在逻辑上是合理的,并能得出正确的答案。
-
RL 微调: 在监督学习之后,使用强化学习来改进模型输出,重点关注格式的遵守和答案的正确性。
DianJin-R1 模型变体包括:
- DianJin-R1-7B: 从 Qwen2.5-7B-Instruct 进行微调
- DianJin-R1-32B: 从 Qwen2.5-32B-Instruct 进行微调
- DianJin-R1-7B-RL: 通过强化学习进一步优化
评估结果
DianJin-R1 模型在五个基准上进行了评估:
- CFLUE: 中文金融语言理解基准
- FinQA: 专注于金融数值推理的数据集
- CCC: 中国合规检查数据集
- MATH-500: 数学推理基准
- GPQA-Diamond: 通用物理知识基准
主要发现包括:
- 持续的性能提升: DianJin-R1 模型在金融任务上始终优于其基线同类产品。
- 规模很重要: 32B 模型比 7B 模型显示出显着的改进,证明了附加参数对于复杂推理的价值。
- 迁移到通用推理: 在金融推理数据上的训练甚至提高了在非金融推理任务(如 MATH-500)上的性能,显示出积极的迁移效果。
- RL 优势: 经过 RL 增强的模型显示出进一步的改进,尤其是在结构化输出生成和答案正确性方面。
- 效率提升: 在真实的 CCC 数据集上,单次调用推理模型在需要显着较少的计算资源的情况下,达到了或超过了多代理系统的性能。
最值得注意的是,DianJin-R1-32B 模型在金融基准上取得了最先进的结果,优于专门为推理任务设计的 DeepSeek-R1 等模型。
主要创新
DianJin-R1 框架引入了几个重要的创新:
-
推理增强训练: 通过显式地建模和监督推理过程,模型学会以结构化的方式分解复杂的金融问题。
-
双重奖励强化学习 (Dual-Reward RL): 同时使用格式和准确性奖励可以创建一个更平衡的优化目标,鼓励结构化输出和正确的答案。
-
特定领域数据集构建 (Domain-Specific Dataset Construction): 精心策划和增强金融数据集为训练专业的金融推理模型提供了坚实的基础。
-
单次调用效率 (Single-Call Efficiency): DianJin-R1 模型可以在单次调用中生成完整的推理链,避免了多智能体方法的计算开销和潜在的错误累积。
-
格式转换 (Format Conversion): 将多项选择题转换为开放式格式,鼓励更深层次的推理,而不是简单的分类。
实际应用
DianJin-R1 的能力对现实世界的金融应用具有重要意义:
-
监管合规 (Regulatory Compliance): 该模型在 CCC 数据集上的出色表现表明其在金融服务中自动化合规性检查的潜力,从而降低风险并确保符合法规。
-
金融分析 (Financial Analysis): 增强的数值推理能力使该模型适合分析金融文档、提取见解并以更高的准确性执行计算。
-
客户服务 (Customer Service): 推理复杂金融查询的能力可以实现更复杂的客户服务应用,从而可能减少在日常情况下对人工干预的需求。
-
金融教育 (Financial Education): 该模型生成的明确推理步骤可以用于教育目的,帮助用户理解金融概念和计算。
-
决策支持 (Decision Support): 金融专业人士可以使用该模型的推理能力来验证自己的分析或探索解决复杂问题的其他方法。
局限性和未来工作
尽管取得了成就,但 DianJin-R1 仍存在一些局限性和未来改进的领域:
-
领域覆盖 (Domain Coverage): 尽管全面,但训练数据集可能未涵盖金融的所有方面,尤其是在新兴领域或高度专业化的领域。
-
监管范围 (Regulatory Scope): CCC 数据集侧重于中国金融法规;扩展到国际监管框架将提高全球适用性。
-
实时更新 (Real-Time Updates): 金融法规和市场状况经常变化;保持模型的时效性需要不断更新。
-
多步计算准确性 (Multi-Step Calculation Accuracy): 虽然有所改进,但复杂的多步计算仍然具有挑战性,并且可以通过进一步改进来受益。
-
可解释性 (Explainability): 虽然推理步骤提供了一定的透明度,但在可解释性方面进行的额外工作将增强对高风险金融应用的信任。
未来的工作可以通过扩展数据集、实施持续学习机制以及开发更强大的金融推理评估框架来解决这些限制。
结论
DianJin-R1 代表了 LLM 在适应金融推理任务方面的重要进步。通过结合推理增强监督、强化学习和精心构建的数据集,该框架在金融基准测试中实现了最先进的性能,同时保持了计算效率。
该方法表明,显式建模推理过程可以显着提高特定领域任务的性能,并对一般推理产生积极的迁移效应。DianJin-R1 模型的单次调用效率使其特别适合实际应用,从而实现了性能和计算成本的平衡。
随着金融服务领域不断采用人工智能技术,像 DianJin-R1 这样的框架将发挥越来越重要的作用,以确保这些系统能够准确地进行推理,遵守法规,并为专业人士和消费者提供可信赖的输出。DianJin-R1-Data 数据集的开源进一步促进了研究社区的发展,从而能够在该关键领域进行更多的探索和进步。
相关引用
Jie Zhu, Junhui Li, Yalong Wen, 和 Lifan Guo. Benchmarking large language models on CFLUE - a Chinese financial language understanding evaluation dataset. In Findings of ACL, pp. 5673–5693, 2024.
- 本文介绍了 CFLUE,它是用于训练和评估 DianJin-R1 模型的主要数据集。其在金融推理问题上的规模和多样性使其对于开发模型的能力至关重要。
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, 和 William Yang Wang. FinQA: A dataset of numerical reasoning over financial data. In Proceedings of EMNLP, pp. 3697–3711, 2021.
- FinQA 是训练和评估中使用的另一个关键数据集。它提供了数值推理的例子,补充了 CFLUE,并增强了 DianJin-R1 在该特定领域的表现。
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. CoRR, abs/2501.12948, 2025. URL https://arxiv.org/abs/2501.12948.
- DeepSeek-R1 是一种专注于推理的 LLM,用于生成训练数据中的推理路径。其强大的推理能力有助于为 DianJin-R1 的学习过程建立真值。
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, 和 Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. CoRR, abs/2402.03300, 2024. URL https://arxiv.org/abs/2402.03300.
- 这项工作介绍了组相对策略优化 (GRPO) 算法,该算法是 DianJin-R1 强化学习阶段的核心。GRPO 通过结合格式和准确性奖励来帮助完善模型的推理。
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, et al. Qwen2.5 technical report. CoRR, abs/2412.15115, 2024. URL https://arxiv.org/abs/2412.15115.
- Qwen2.5 是构建 DianJin-R1 的基础模型。本文介绍了 Qwen2.5 的架构和训练,为理解 DianJin-R1 的起点和后续改进提供了背景。
❤️ 一起学AI
- ❤️ 如果文章对你有些许帮助、蟹蟹各位读者大大点赞、评论鼓励博主的每一分认真创作


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)