【论文阅读】Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
下一尺度预测——视觉自回归方法VAR论文讲解
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
-
原文摘要
-
核心创新点
-
范式转变:
- VAR将图像的自回归学习从传统的"下一token预测"重新定义为"从粗到细的下一尺度/分辨率预测"。
- 这种直观的方法通过分层生成图像(如先低分辨率后逐步细化),显著提升了自回归模型的效率和生成质量。
-
超越现有技术:
- VAR首次使GPT风格的自回归模型在图像生成任务上超越Diffusion Transformer,在速度、质量和可扩展性方面均表现出优势。
-
关键实验结果
-
ImageNet 256×256基准测试:
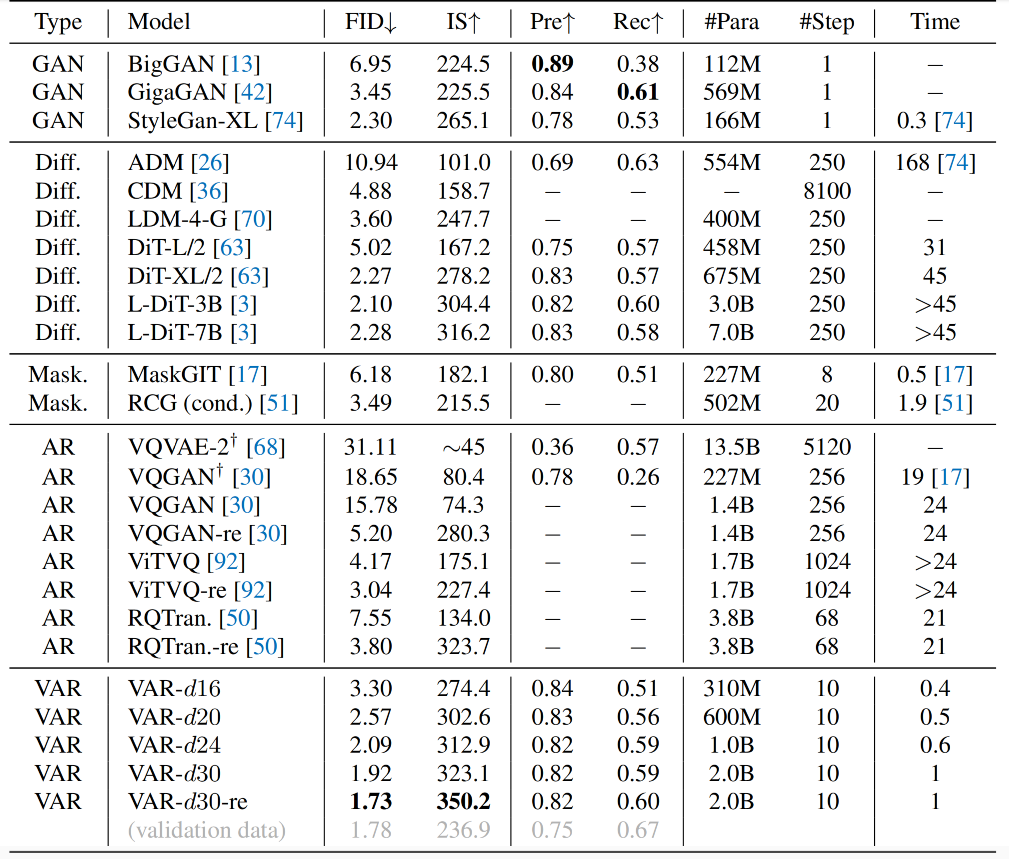
- Fréchet Inception Distance FID:从基线AR模型的18.65显著提升至1.73(数值越低越好)。
- Inception Score IS:从80.4跃升至350.2(数值越高越好)。
- 推理速度:比传统AR模型快20倍。
-
与DiT的对比:
-
VAR在以下维度全面优于扩散变换器(DiT):
-
图像质量(FID/IS)
-
推理速度(20倍加速)
-
数据效率(更少数据达到更好性能)
-
可扩展性(模型规模扩大时性能持续提升)。
-
-
-
-
类LLM的特性验证
-
缩放定律(Scaling Laws):
- VAR模型在扩大规模时表现出与LLMs相似的幂律缩放规律,线性相关系数接近-0.998,证明其性能随参数增加可预测地提升。
-
零样本泛化能力:
- VAR在以下下游任务中无需微调即可表现优异:图像修复、外绘、编辑。
-
这表明VAR初步具备了类似LLMs的两大关键特性:缩放定律和零样本泛化。
-
-
-
1. Introduction
-
自回归语言模型的启发
- 背景:
-
GPT系列及同类自回归LLMs的崛起标志着AI领域的新纪元。
-
尽管存在幻觉等问题,这些模型展现出的通用性和适应性被视为迈向AGI的重要一步。
-
核心机制:其成功源于简单的自监督策略——“下一token预测”。
-
关键特性:
- 可扩展性(Scaling Laws):通过缩放定律,可从小模型预测大模型性能,指导资源分配。
- 泛化能力:零样本/少样本学习证明其能适应未见任务,体现了从无标注数据中学习的潜力。
-
意义:这些特性使AR模型成为AGI研究的核心范式。
-
- 背景:
-
视觉领域自回归模型的困境
-
现状:视觉领域尝试构建类似的自回归或世界模型(如VQGAN、DALL-E),但存在两大问题:
-
性能差距:当前视觉AR模型显著落后于扩散模型。
-
未充分探索的缩放定律:缺乏类似LLMs的缩放规律研究。
-
-
根本原因:传统方法将图像通过Tokenizer离散化为1D token序列,直接套用语言模型的"下一token预测"范式,忽略了图像的空间层次性。
-
-
VAR的核心创新
-
人类视觉启发:人类观察/创作图像遵循从全局结构到局部细节的层次化过程(多尺度、由粗到细)。
-
方法论突破:
- 提出"下一尺度预测"(next-scale prediction)替代传统"下一token预测"。
- 具体流程:
- 将图像编码为多尺度token图(multi-scale token maps)。
- 自回归过程从1×1分辨率开始,逐步预测更高分辨率token图(每步基于之前所有尺度的信息)。
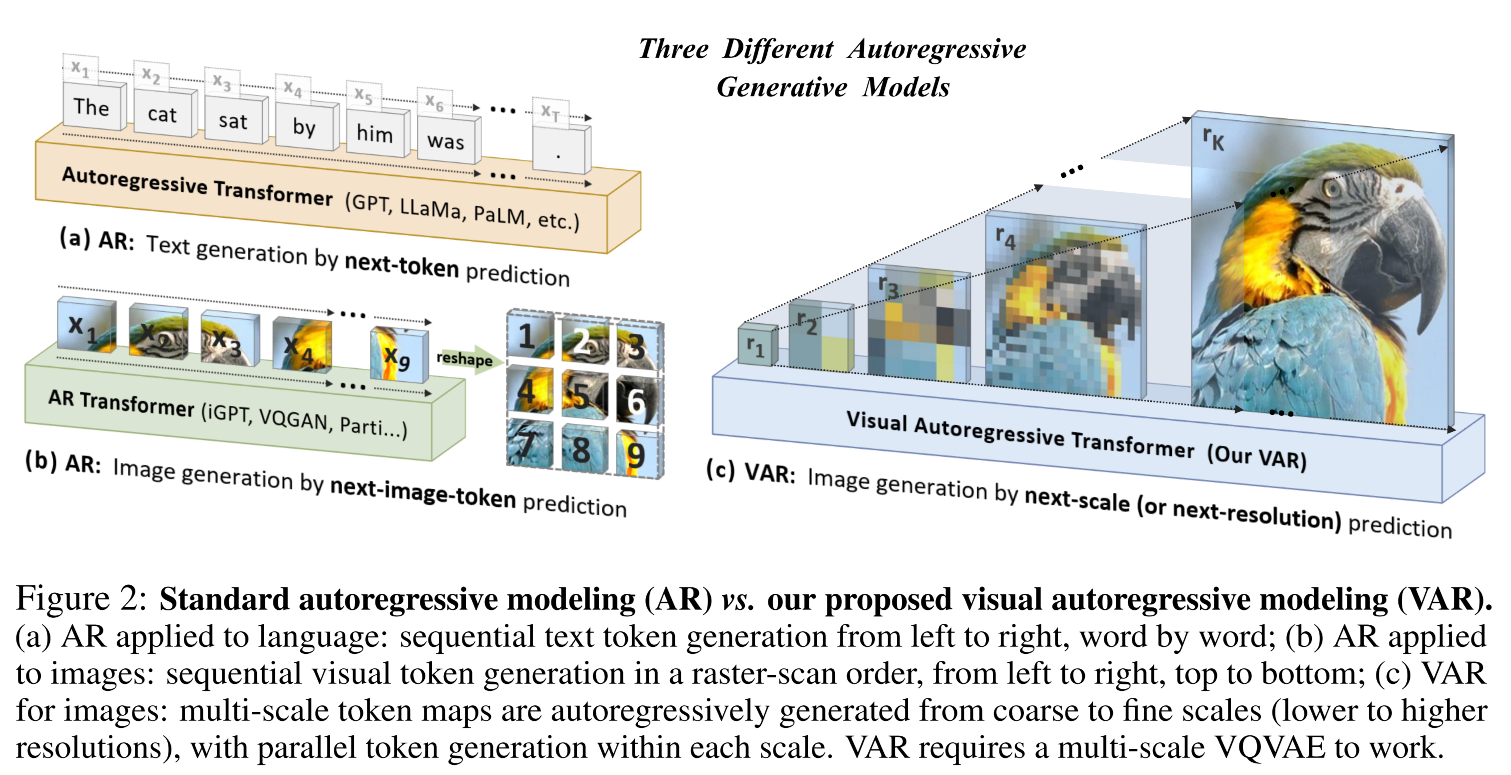
- 优势:更贴合图像本质,解锁AR模型在视觉领域的潜力。
-
-
VAR的突破性成果
-
性能指标(ImageNet 256×256):FID 1.73、IS 350.2,推理速度比AR基线快20倍。
-
对比DiT:在以下维度全面超越DiT(如Stable Diffusion 3.0和SORA):
- 图像质量(FID/IS)、数据效率、推理速度、可扩展性
-
类LLM特性验证:
- Scaling Laws:展现与LLMs相似的幂律缩放规律(线性相关系数接近-0.998)。
- 零样本泛化:支持图像修复、外绘、编辑等任务。
-
意义:首次实现GPT风格AR模型在图像生成上超越扩散模型。
-
-
本文的核心贡献总结
-
新框架:提出多尺度自回归范式(next-scale prediction),为视觉AR算法设计提供新视角。
-
特性验证:实证VAR具有LLMs的两大关键特性——缩放定律与零样本泛化。
-
性能突破:首次使AR模型在图像合成中超越扩散模型。
-
开源推动:发布完整代码库(含VQ Tokenizer和AR训练流程),促进视觉AR学习发展。
-
2. Related Work
2.1 大型自回归语言模型的特性
2.1.1 缩放定律
- 定义:自回归语言模型中发现的幂律关系,描述模型规模(参数、数据量、计算量等)与测试集交叉熵损失之间的关联。
- 作用:
- 通过小模型性能预测大模型表现,优化资源分配。
- 证明LLMs性能可随规模增长持续提升(无饱和现象),这是GPT系列成功的关键。
2.1.2 零样本泛化
- 定义:模型(尤其是LLMs)在未经专门训练的任务上表现的能力。
- 视觉领域的进展:
- 基础模型:CLIP 、SAM、Dinov2展现零样本与上下文学习能力。
- 扩展工作:Painter、LVM通过视觉提示器(visual prompters)实现视觉上下文学习。
2.2 视觉生成模型
2.2.1 逐行扫描自回归模型
- 核心思想:将2D图像编码为1D token序列,按行扫描顺序生成(类似语言模型)。
- 演进脉络:
- 早期工作:直接生成RGB像素;通过多网络叠加实现超分。
- 潜在空间改进:VQGAN在VQVAE潜在空间进行AR学习,使用GPT-2风格Transformer。
- 多尺度扩展:VQVAE-2、RQ-Transformer保留行扫描但引入多尺度或堆叠编码。
- 大规模模型:Parti基于ViT-VQGAN架构,将参数量扩展至20B,擅长文本到图像生成。
2.2.2 掩码预测模型
- 代表工作:
- MaskGIT:结合VQ自编码器与类BERT的掩码预测Transformer,通过贪心算法生成token。
- 视频扩展:MagViT适配视频生成;MagViT-2改进VQVAE支持图像/视频。
- 规模突破:MUSE将MaskGIT扩展至3B参数。
2.2.3 扩散模型
- 技术方向:
- 学习/采样优化:改进训练或采样效率。
- 引导技术:提升生成可控性。
- 潜在学习:在潜在空间进行扩散。
- 架构革新:DiT 和U-ViT 用Transformer替代U-Net,成为Stable Diffusion 3.0、SORA [14]、Vidu等前沿系统的基础。
3. Methods
3.1 Preliminary:NTP的AR
3.1.1 自回归模型的形式化定义
-
序列建模:给定离散token序列 x=(x1,x2,…,xT)x = (x_1, x_2, \dots, x_T)x=(x1,x2,…,xT)(xt∈[V]x_t \in [V]xt∈[V],词汇表大小为 VVV),自回归模型假设当前token xtx_txt 的概率仅依赖于其前缀 (x1,…,xt−1)(x_1, \dots, x_{t-1})(x1,…,xt−1)。
-
似然分解:序列的联合概率可分解为条件概率的连乘:
p(x1,…,xT)=∏t=1Tp(xt∣x1,…,xt−1). p(x_1, \dots, x_T) = \prod_{t=1}^T p(x_t \mid x_1, \dots, x_{t-1}). p(x1,…,xT)=t=1∏Tp(xt∣x1,…,xt−1).- 通过优化条件概率 pθ(xt∣x1,…,xt−1)p_\theta(x_t \mid x_1, \dots, x_{t-1})pθ(xt∣x1,…,xt−1) 训练模型,生成新序列。
3.1.2 图像Token化流程
-
挑战:图像是2D连续信号,需离散化为token并定义1D顺序。
-
量化自编码器 VQVAE:
-
编码:图像 im\text{im}im 通过编码器 E(⋅)\mathcal{E}(\cdot)E(⋅) 得到特征图 f∈Rh×w×Cf \in \mathbb{R}^{h \times w \times C}f∈Rh×w×C。
-
量化:通过量化器 Q(⋅)\mathcal{Q}(\cdot)Q(⋅) 将 fff 映射为离散token网格 q∈[V]h×wq \in [V]^{h \times w}q∈[V]h×w,每个token q(i,j)q^{(i,j)}q(i,j) 对应码本 Z∈RV×CZ \in \mathbb{R}^{V \times C}Z∈RV×C 中最近的码向量(欧式距离最近):
q(i,j)=(argminv∈[V]∥lookup(Z,v)−f(i,j)∥2)∈[V] q^{(i,j)} = \left(\arg\min_{v \in [V]} \|\text{lookup}(Z, v) - f^{(i,j)}\|_2\right) \in [V] q(i,j)=(argv∈[V]min∥lookup(Z,v)−f(i,j)∥2)∈[V]- 对特征图中的每一个像素,它的特征长度为CCC
- 它和码本ZZZ中的每一个代码向量(向量长度为CCC)计算欧式距离
- 欧式距离最短的,就是当前特征像素的代码向量
- 这个代码向量对应的token,就是当前像素的token
- 也就是说最后qqq的每一个元素是一个token,而不是向量
-
重建:通过解码器 D(⋅)\mathcal{D}(\cdot)D(⋅) 从量化特征 f^=lookup(Z,q)\hat{f} = \text{lookup}(Z, q)f^=lookup(Z,q) 重建图像 im^=D(f^)\hat{\text{im}}=\mathcal{D}(\hat{f})im^=D(f^),优化复合损失:
L=∥im−im^∥2+∥f−f^∥2+λPLP(im^)+λGLG(im^), \mathcal{L} = \|\text{im} - \hat{\text{im}}\|_2 + \|f - \hat{f}\|_2 + \lambda_P \mathcal{L}_P(\hat{\text{im}}) + \lambda_G \mathcal{L}_G(\hat{\text{im}}), L=∥im−im^∥2+∥f−f^∥2+λPLP(im^)+λGLG(im^),- 其中 $\mathcal{L}_P $为感知损失和 LG\mathcal{L}_GLG为对抗损失,分别控制感知质量和对抗性。
- lookup操作就是把每个token变换回原来的代码向量
-
3.1.3 图像Token的序列化问题
- 顺序定义:图像token网格 qqq 需展平为1D序列 xxx(如行优先扫描、螺旋顺序等 )。
- 传统方法缺陷:
- 数学前提违背:
- 矛盾点:图像特征 f(i,j)f^{(i,j)}f(i,j) 本质是双向相关的,但自回归模型强制单向依赖(xtx_txt 仅依赖前缀),导致建模偏差。
- 零样本泛化受限:
- 例子:无法根据图像下半部分预测上半部分(需双向推理)。
- 结构退化:
- 空间局部性破坏:展平后,相邻token q(i,j)q^{(i,j)}q(i,j) 与 q(i±1,j±1)q^{(i\pm1,j\pm1)}q(i±1,j±1) 的2D空间关系被1D序列稀释,削弱模型对局部结构的捕捉能力。
- 效率低下:
- 计算复杂度:生成 n×nn \times nn×n 图像需 O(n2)O(n^2)O(n2) 自回归步,传统Transformer自注意力成本达 O(n6)O(n^6)O(n6)。
- 数学前提违背:
3.2 Next-scale prediction的视觉自回归

3.2.1 核心重构:Next token to Next scale
-
自回归单元变革:
- 传统方法:以单个token为单元(如VQGAN的1D序列)。
- VAR创新:以整个token图(token map)为单元,按分辨率从低到高生成多尺度序列 (r1,r2,…,rK)(r_1, r_2, \dots, r_K)(r1,r2,…,rK),其中 rKr_KrK 匹配原图分辨率 h×wh \times wh×w。
-
似然分解:
p(r1,r2,…,rK)=∏k=1Kp(rk∣r1,…,rk−1) p(r_1, r_2, \dots, r_K) = \prod_{k=1}^K p(r_k \mid r_1, \dots, r_{k-1}) p(r1,r2,…,rK)=k=1∏Kp(rk∣r1,…,rk−1)- 每个 rk∈[V]hk×wkr_k \in [V]^{h_k \times w_k}rk∈[V]hk×wk 是第 kkk 尺度的token图,生成时并行预测所有 hk×wkh_k \times w_khk×wk 个token
- 条件依赖于前缀 r≤k−1r_{\leq k-1}r≤k−1 和位置嵌入
- 作为条件的token map同样还是展成一维序列放入transformer中
- 每个 rk∈[V]hk×wkr_k \in [V]^{h_k \times w_k}rk∈[V]hk×wk 是第 kkk 尺度的token图,生成时并行预测所有 hk×wkh_k \times w_khk×wk 个token
-
图示:上图右侧展示VAR的多尺度生成流程。
-
训练与推理优化
-
训练:使用块状因果注意力掩码,确保 rkr_krk 仅关注前缀 r≤kr_{\leq k}r≤k。
-
推理:无需掩码,通过KV缓存加速自回归生成。
-
3.2.2 解决传统AR模型的四大问题
| 问题 | VAR的解决方案 | 效果 |
|---|---|---|
| 数学前提违背 | 约束 rkr_krk 仅依赖前缀 r≤k−1r_{\leq k-1}r≤k−1,符合人类视觉的由粗到细特性。 | 建模逻辑自洽,避免双向依赖冲突。 |
| 零样本泛化受限 | 多尺度结构支持局部条件生成(如给定低分辨率生成高分辨率)。 | 实现图像补全、编辑等任务。 |
| 结构退化 | 取消1D展平操作,保留token图的2D结构;多尺度设计增强空间相关性。 | 生成图像细节更自然。 |
| 效率低下 | 并行生成每尺度token图,计算复杂度从 O(n6)O(n^6)O(n6) 降至 O(n4)O(n^4)O(n4) | 支持高分辨率生成(如256×256),推理速度提升20倍。 |
3.2.3 多尺度Token化
- 量化自编码器改进:
- 架构基础:沿用VQGAN 但改进量化层,支持多尺度输出 R=(r1,…,rK)R = (r_1, \dots, r_K)R=(r1,…,rK)。
- 残差设计(Algorithm 1 & 2):
- 编码时,第 kkk 尺度 rkr_krk 仅依赖前缀 r1,…,rk−1r_1, \dots, r_{k-1}r1,…,rk−1。
- 解码时,使用 KKK 个额外卷积层 {ϕk}k=1K\{\phi_k\}_{k=1}^K{ϕk}k=1K 补偿上采样信息损失。
- 共享码本:所有尺度共用码本 Z∈RV×CZ \in \mathbb{R}^{V \times C}Z∈RV×C,确保token语义一致性。

4. 实现细节
4.1 VAR Tokenizer实现细节
-
基础模型:基于标准VQVAE架构,增加多尺度量化层(仅引入0.03M额外参数)。
-
码本共享:所有尺度共用码本,大小 V=4096V = 4096V=4096。
-
训练数据:在OpenImages上训练,空间下采样率16×。
-
损失函数:沿用之前的复合损失(MSE + 感知损失LPIPS + 对抗损失StyleGAN)。
4.2 VAR Transformer实现细节
-
架构选择
- 基础设计:采用GPT-2风格的解码器Transformer,未引入LLM高级技术。
-
关键组件:
- 自适应归一化(AdaLN):将类别嵌入作为起始token
[s]和AdaLN条件,稳定训练。 - 注意力优化:对Query和Key向量进行单位归一化,提升训练稳定性。
- 自适应归一化(AdaLN):将类别嵌入作为起始token
-
模型缩放规则
-
参数配置:模型宽度 www、头数 hhh、丢弃率 drdrdr 随深度 ddd 线性缩放:w=64d,h=d,dr=0.1⋅d/24.w = 64d, \quad h = d, \quad dr = 0.1 \cdot d/24.w=64d,h=d,dr=0.1⋅d/24.
-
参数量计算:N(d)=18dw2=73728d3N(d) = 18dw^2 = 73728d^3N(d)=18dw2=73728d3
- 其中自注意力层占 4w24w^24w2,前馈网络占 8w28w^28w2,AdaLN占 6w26w^26w2。
-
-
训练配置
- 优化器:AdamW($\beta_1=0.9 , \beta_2=0.95 $, 权重衰减=0.05)。
-
学习率:基础学习率 10−410^{-4}10−4(batch size=256时),实际batch size为768~1024。
-
训练周期:200~350轮(依模型规模调整)。
5. Empirical Results

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)