ICLR 2025 | 无需训练!巧用模型自身梯度图,南加大开源ViCrop让LLaVA看清“像素级”细节,准确率暴涨!
本文研究发现多模态大语言模型(MLLM)在感知微小视觉细节方面存在明显局限,其性能与视觉对象尺寸呈负相关。通过实验证实,MLLM即使回答错误时也能准确定位目标区域,表明问题根源在于感知而非定位。基于此,作者提出无需训练的ViCrop方法,利用模型自身的注意力图和梯度图自动裁剪关键区域进行增强。在7个视觉问答基准上的测试表明,ViCrop显著提升了LLaVA-1.5和InstructBLIP等模型的
一、导读
多模态大语言模型(MLLM) 在视觉识别任务中取得了显著进展,但其在感知微小视觉细节方面的能力仍存在局限。本文深入研究了这一问题,发现MLLM在处理有关小尺寸视觉主题的问题时,其性能会显著下降。通过干预研究,本文证实了这种尺寸效应的因果关系。有趣的是,研究进一步发现,即使MLLM给出错误答案,其内部的注意力机制通常也能准确定位到图像中的相关区域,这表明问题根源在于感知(Perception)而非定位(Localization)。基于此洞察,本文提出了一系列无需训练的视觉干预方法(ViCrop),利用模型自身的注意力图和梯度图来自动裁剪图像,从而增强对微小细节的感知能力。实验证明,这些方法能显著提升现有MLLM在多个视觉问答基准上的准确率,为解决MLLM在细节敏感型应用中的风险提供了有效途径。
二、论文基本信息

基本信息
-
论文标题:MLLMs Know Where to Look: Training-Free Perception of Small Visual Details with Multimodal LLMs
-
作者:Jiarui Zhang, Mahyar Khayatkhoei, Prateek Chhikara, Filip Ilievski
-
作者单位:University of Southern California, USA; Vrije Universiteit Amsterdam, The Netherlands
摘要精炼
本文旨在研究并解决多模态大语言模型(MLLM)在感知微小视觉细节方面的性能瓶颈。研究首先通过定量分析和干预实验,证实了模型性能与其被问及的视觉对象的尺寸存在明确的因果关系:对象越小,准确率越低。接着,通过分析模型的内部注意力模式,论文发现即使在回答错误的情况下,MLLM通常也能“知道”应该关注图像的哪个区域,这表明其主要局限在于感知细节而非定位对象。基于这一核心发现,论文提出了一套名为ViCrop的无需训练的视觉干预方法。该方法利用模型自身的注意力图或梯度图来自动识别并裁剪出图像中的关键区域,再将裁剪后的高分辨率图像与原图一同输入模型。在七个视觉问答基准上的评估结果表明,ViCrop能够显著提升两大主流MLLM(LLaVA-1.5和InstructBLIP)的准确率,尤其是在对细节敏感的任务上,证明了利用模型内部状态进行视觉干预是提升其感知能力的有效策略。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/rGxwLXQ9_OEVB1EtTjCOsA
https://mp.weixin.qq.com/s/rGxwLXQ9_OEVB1EtTjCOsA
三、研究背景与相关工作
研究背景
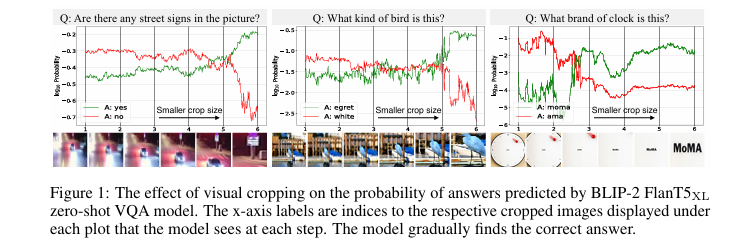
随着多模态大语言模型(MLLM)在机器人、生物医学、自动驾驶等关键领域的应用日益广泛,理解并解决其潜在的局限性变得至关重要。一个普遍存在但未被充分研究的痛点是,这些模型在处理需要关注微小视觉细节的任务时表现不佳。例如,在识别图像中小尺寸的文字、标志或物体时,模型准确率会大幅下降。如 图1 所示,通过手动缩放图像(视觉裁剪),模型的回答正确率会随之提升,这暗示了问题的根源在于模型对小尺寸对象的感知能力不足。当前研究迫切需要系统性地量化这一问题,探明其内在原因(是定位失败还是感知失败),并提出可扩展、低成本的解决方案,以降低MLLM在实际应用中的风险。
相关工作
相关工作主要分为两大流派。第一类是多模态大语言模型(MLLM) 的架构演进,包括从早期的端到端预训练模型到当前主流的模块化预训练模型(如BLIP-2, LLaVA, Qwen-VL)。这些模型通过连接器(Connector)将预训练的视觉编码器与大语言模型(LLM)结合,但大多在标准分辨率下工作,并未专门解决小目标感知问题。第二类是视觉定位方法,包括需要密集标注的专用模型(如YOLO, SAM)和利用模型内部梯度的无监督方法(如Grad-CAM)。已有工作尝试将Grad-CAM应用于BLIP模型,但依赖于其特定的图文匹配网络(ITM)。与这些方法不同,本文不依赖外部工具或特定模型架构,而是证明了MLLM自身就具备定位能力,并提出利用其内部状态(注意力、梯度)进行自引导的视觉增强,这是一种无需额外训练、更具通用性的解决方案。
四、主要贡献与创新
-
因果性论证:首次通过干预研究(
human-CROP)建立了MLLM性能与视觉对象尺寸之间的因果关系,证明了模型在小目标上的性能下降确实是由尺寸过小导致的。 -
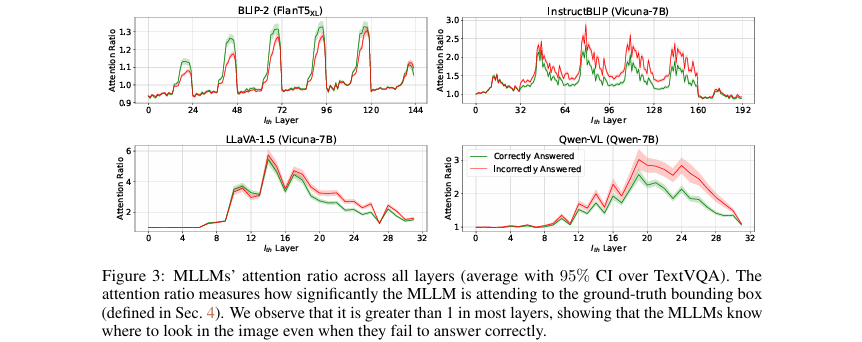
“感知而非定位”的核心洞察:通过量化分析模型的内部注意力,发现即便是回答错误时,MLLM也能准确地“看向”正确区域(如 图3 所示),从而揭示了问题的本质是感知局限而非定位失败。
-
提出无需训练的ViCrop方法:基于上述洞察,设计了一套完全无需训练的自动视觉裁剪框架(ViCrop),利用模型自身的注意力和梯度作为内部知识,实现了对关键区域的自适应聚焦。
-
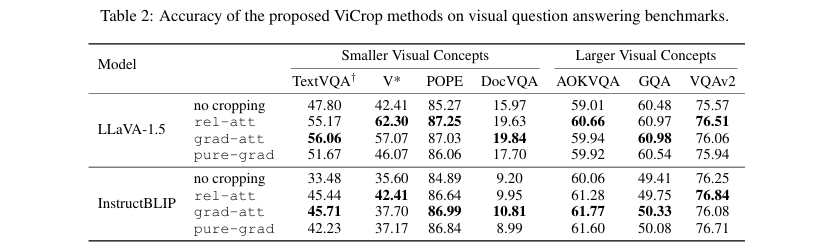
通用性与有效性验证:在两大类共七个VQA基准上验证了ViCrop方法的有效性。实验结果(如 表2 所示)表明,该方法不仅显著提升了模型在细节敏感任务上的准确率,且不会损害其在常规任务上的性能,展示了良好的通用性和即插即用特性。
五、研究方法与原理
总体框架与核心思想
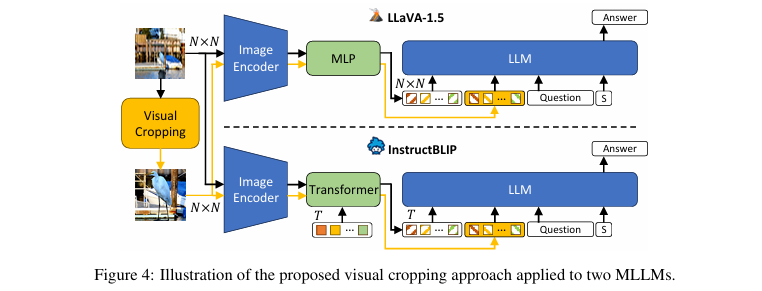
本文方法的核心思想是:利用MLLM自身在推理过程中产生的内部状态(注意力或梯度)作为“向导”,自动识别并裁剪出图像中与问题最相关的区域,然后将这个“放大”后的区域作为额外信息,与原始图像一同输入模型,从而在不进行任何模型训练的情况下,增强其对微小细节的感知能力。这一过程如 图4 所示,通过将裁剪后的图像编码为新的视觉Token,并与原始图像Token拼接,让模型同时拥有全局概览和局部特写两种视野。
关键实现与评估原理
关键实现细节 本文提出了三种具体的ViCrop实现方式,它们都利用了模型的内部动态来生成一个重要性图(importance map),用于指导裁剪。
-
Relative Attention ViCrop (rel-att): 该方法计算模型对当前问题(
q)的答案-图像注意力与对一个通用问题(q',如“描述这张图片”)的注意力的比值,从而过滤掉通用的、与问题无关的注意力。其核心公式为: -
Gradient-Weighted Attention ViCrop (grad-att): 该方法利用模型决策(最高概率的输出token)对注意力分数的梯度来对注意力进行加权,从而突出对最终答案有贡献的注意力。负梯度被置零。其核心公式为:
-
Input Gradient ViCrop (pure-grad): 该方法直接计算模型决策对输入图像的梯度,以定位图像中的敏感区域。为避免梯度集中在无意义的平坦区域,该方法结合了高通滤波器来强调边缘信息。其核心公式为:
在获得重要性图后,通过滑动窗口策略来确定最佳裁剪框。
核心评估原理与指标
-
核心评估原理:通过对比应用ViCrop方法前后,MLLM在多个视觉问答(VQA)基准上的性能变化,来评估该方法的有效性。实验分为两类:一类是包含大量小目标的细节敏感型数据集,用于验证方法的提升效果;另一类是常规的通用型数据集,用于验证方法是否会损害模型的通用能力。
-
核心评估指标:主要使用VQA-score(适用于大多数数据集)和Accuracy(适用于GQA数据集)来衡量模型的回答准确率。
六、实验结果与分析
实验设置
- 数据集:
-
细节敏感型: TextVQA, V*, POPE, DocVQA
-
通用型: AOKVQA, GQA, VQAv2
-
-
评估指标: VQA-score, Accuracy
-
对比基线: 原始的MLLM模型(
no cropping),包括LLaVA-1.5 (Vicuna-7B)和InstructBLIP (Vicuna-7B)。 -
关键超参: 对于
rel-att和grad-att,选择了一个在验证集上表现最佳的特定注意力层;对于高分辨率图像(V*数据集),采用了两阶段裁剪策略。
核心实验与结论
-
实验目的: 该实验旨在全面评估三种ViCrop方法在不同类型的VQA任务上对MLLM性能的影响,验证其是否能在提升细节感知能力的同时,不损害其通用性能。
-
关键结果: 如表2所示,所有三种ViCrop方法(rel-att, grad-att, pure-grad)均在细节敏感型数据集上显著提升了两个基线模型的准确率。以LLaVA-1.5在TextVQA上的表现为例,
no cropping的准确率为47.80%,而rel-att和grad-att分别将其提升至55.17%和56.06%。在V*数据集上,rel-att更是带来了近20个百分点的巨大提升(从42.41%到62.30%)。与此同时,在通用型数据集(如AOKVQA, GQA, VQAv2)上,ViCrop方法的准确率与基线模型持平或有轻微提升,未出现性能下降。 -
作者结论: 作者基于此实验结果得出结论:ViCrop作为一个无需训练的、即插即用的推理时优化方法,能够有效且安全地提升MLLM的视觉感知能力。它在处理小目标和细节问题时能带来显著收益,同时不会以牺牲模型在常规任务上的性能为代价,证明了该方法的实用性和鲁棒性。
七、论文结论与启示
总结
本文系统性地研究了多模态大语言模型(MLLM)在感知微小视觉细节方面的局限性。研究首先通过定量实验证明了模型性能与视觉对象尺寸之间存在显著的负相关性,并利用干预研究确认了其因果关系。核心发现是,即使在回答错误时,模型的内部注意力机制也能准确定位到相关区域,表明这是一个“感知”而非“定位”的瓶颈。基于此,论文提出了一系列名为ViCrop的自动化、无需训练的视觉裁剪方法,通过利用模型自身的注意力和梯度信息来引导模型聚焦于关键区域。在多个VQA基准上的实验表明,ViCrop能够显著提升模型在细节敏感任务上的准确率,且不影响其通用性能,为解决MLLM的感知局限性提供了一条有效且可扩展的路径。
展望
根据论文的讨论,未来可能的研究方向包括:
-
多区域聚焦: 当前的ViCrop方法一次只能聚焦于一个区域,未来可以探索扩展该方法以同时处理涉及多个图像区域的复杂关系或计数问题。
-
推理效率优化: 尽管ViCrop的开销合理,但仍有优化空间。未来可以通过模型量化、低精度计算等技术进一步减少其在推理时的计算开销。
-
与可变视觉上下文结合: 结合如Matryoshka Query Transformer (MQT)等技术,使ViCrop能够适应动态变化的视觉上下文大小,从而在不同硬件条件下实现成本和性能的平衡。
-
方法融合: 由于不同的ViCrop方法(rel-att, grad-att, pure-grad)表现出互补的优势,未来可以研究如何根据问题的类型或模型的不确定性来动态地组合使用这些方法,以达到最佳效果。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/rGxwLXQ9_OEVB1EtTjCOsA
https://mp.weixin.qq.com/s/rGxwLXQ9_OEVB1EtTjCOsA

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)