【文献阅读||2025|上】Controlling diverse robots by inferring Jacobian fields with deep networks
视觉运动雅可比场直接将任意三维点映射到其对应的系统雅可比,通过深度学习直接从输入图像中重构雅可比场而不是在专家设计的状态表示上进行条件化,这种做法绕过了传统流程中间复杂步骤(定义状态、建立动力学模型、计算雅可比);在传统的系统雅可比描述的是抽象状态。而本文的雅可比场是物理空间中具体的3D点的运动,这样使得我们可以查询机器人身上或周围。
论文来源:https://doi.org/10.1038/s41586-025-09170-0 (nature)
概要
在传统的机器人(由刚性材料制造)控制中,通过高精度传感器对机器人建模来精确的确定其行动,但是在仿生机器人或者软体机器人中用同样的方式成本会高很多,不仅因为这些制造材料由弹性,存在非线性行为,难以建模,同时缺乏内置传感器获取实时状态信息,本文作者介绍了一种使用深度神经网络将机器人的视频流映射到其视觉运动雅克比场(所有3D点对机器人执行器的灵敏度)的方法。简单来说就是用点构成机器人表面结构,然后让AI随机组合驱动电机,然后AI自己观察这些点会出现怎么样的运动,判断哪些点在电机驱动下会产生较大影响或者较小影响(敏感程度)。
比如现在我们需要让机器人做出目标动作,可以给出不同指令通过视觉运动雅可比场来知道每个点的移动情况,然后不断调整优化,以更好的做出目标动作。也就是AI自己看自己学。
要理解这个方法的革新性,我们先知道传统的方法是如何做的。
首先,专家需要给机器人手动设置状态向量q,在刚性机器人中就是所有关节角度的集合,其次,建立动力学模型函数q* = f(q,u)来描述由当前状态q和执行命令u所确定的下一个状态q*,最后计算雅可比,对这个函数线性化,得到雅可比矩阵J,它描述微小的指令u如何影响其状态q的变化。
在软体机器人上存在瓶颈:
- 对于软体机器人,如何定义状态向量,无法用有限的q来表示
- 动力学模型如何构建?软体机器人中的软性材料变形极其复杂,难以构建。
- 软体机器人缺乏内置传感器,无法精确反馈实时状态。
本文的革新性在于它抛弃了状态向量q和函数f,将机器人视为一个3D完整状态,而视觉运动雅可比场就是直接学习机器人形状的运动规则。
传统机器人建模与控制方法
1.定义状态(State-)
是一个状态向量,完整地描述了机器人在某一时刻的配置。例如: 对于一个简单的机械臂,
就是所有关节角度的集合。比如
,其中
是基座角度,
是肘部角度,等等。
就是机器人的自由度数量。
2.定义动态(Dynamics-)
,这是一个动力学方程,描述了机器人的物理行为。输入当前状态
和命令
,输出下一个状态
。这个方程的作用就是告诉当前状态和指令,它能预测出下一个状态。
3.系统雅可比矩阵(The System Jacobian-)
是在点
附近线性化(切线代替曲线)后得到关于指令
变化和状态
变化的矩阵,它表示在当前状态
下,如果微调指令
,那么状态
会发生多大的变化
,其中
。 因为
通常是非线性的、复杂的,直接用它来规划控制很困难。而雅可比矩阵
在局部提供了一个简单的线性关系,使得我们可以用高效的优化算法来计算出实现特定
所需的
具体控制运作的方式:在当前状态下执行这个最优的微小指令,然后执行这个指令到达新的状态,重新进行线性化操作执行最优的微小指令
。这是许多高级控制算法(如逆动力学控制、模型预测控制)的基础。
对于传统机器人是可行的,但是对于混合软刚性、传感器不足和欠驱动系统,难以编写状态和动力学方程。
框架构成
视觉运动雅可比场(The visuomotor Jacobian field):视觉指的是摄像头的图像,因为要观察机器人的运动情况,所以需要摄像头拍摄机器人表面的图像;运动指的是机器人表面上的点的移动;雅可比是一个数学术语,可以理解为灵敏系数比,当电机驱动后会告诉你机器人指尖在x、y、z轴下移动多少毫米;场表示空间中每个点都有意义的量。结合起来视觉运动雅可比场就是机器人表面的灵敏地图,也就是告诉你在控制指令下每个点会向哪个方向运动了多少距离。它帮助我们确定更好的优化方向。
视觉运动雅可比场是一张覆盖机器人表面全身的地图,这些地图不是表示地理位置,而是在某种指令下,机器人上面的每一个点会怎么动。
作者的模型框架包含两个关键的部分:基于深度学习的状态估计模型;逆动力学控制器。它完整描述了一个“感知—控制”闭环系统。状态估计模型负责观察机器人,对其状态有精确的理解;逆动力学控制器负责决策,表示为了达到目标应该如何驱动。
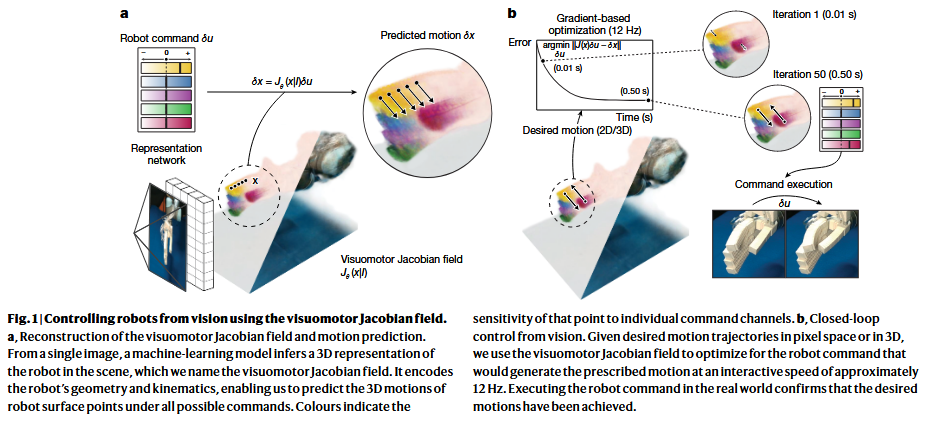
上图是利用视觉运动雅可比场对机器人进行视觉控制。
图a表示视觉运动雅可比场的重构和运动预测:从单张图片推导机器人在场景下的3D表示,也就是视觉运动雅可比场,对机器人的几何模型和运动学进行编码,使我们在所有的命令下预测机器人表面的三维运动。
颜色表示该点对单个命令通道的敏感程度,用一种独特的颜色来代表机器人的每一个独立的控制通道(即每一个执行器或电机),颜色越鲜艳、越亮,表示这个执行器对当前点的控制力越强;颜色越暗淡或者越接近黑色/白色,表示影响越弱甚至没有。对于给定的一个3D点 是一个
的矩阵,其中
是执行器的数量,这个矩阵的每一列都对应一个执行器,描述了该执行器命令变化如何影响点
在3D空间中的运动。
图b表示闭环视觉控制,给定像素空间或3D中的期望运动轨迹,使用雅可比场来优化机器人指令。
基于深度学习的状态估计模型
目标:能够完全理解机器人的3D状态和运动规则。
状态估计是一个深度学习框架,将机器人的单张图片映射为3D神经场景表示,这种3D表示法将任意3D坐标映射为描述机器人在该点坐标的几何和运动学特性的特征。即输入一张图像,输出神经辐射场和视觉运动雅可比场的3D表示。
编码3D几何:实现从2D图像中重构得到3D机器人的形状。采用神经辐射场。这是一个3D形状重建模型。输入一张机器人的照片,它能在脑海里生成这个机器人的完整3D全息投影。从任意角度查看这个投影,它都知道每个3D点是什么颜色、以及这个点是属于机器人实体还是空白空间。
神经辐射场将3D坐标映射到其密度和辐射度,作为机器人几何形状的表示。其输入一个3D坐标输出辐射度(颜色和亮度通常是一个3维向量 (R, G, B))和密度
(透明度一个1维标量)。
编码微分运动学:采用视觉运动雅可比场实现机器人工作空间的 “命令-运动”灵敏度3D地图。对于空间中的每一个点,视觉运动雅可比场都能描述在微小的控制指令下每个点移动的距离和方向。
视觉运动雅可比场将3D中的每一个点都映射到一个线性算子上,该算子将该点的3D运动表示为机器人执行器命令的函数。也就是建立该点运动到命令的映射关系。
论文中重点介绍视觉运动雅可比场,这是最核心的创新点。
视觉运动雅可比场直接将任意三维点映射到其对应的系统雅可比,通过深度学习直接从输入图像
中重构雅可比场而不是在专家设计的状态表示
上进行条件化,这种做法绕过了传统流程中间复杂步骤(定义状态、建立动力学模型、计算雅可比);在传统的系统雅可比描述的是抽象状态
。而本文的雅可比场是物理空间中具体的3D点的运动,这样使得我们可以查询机器人身上或周围任何一个点的运动灵敏度。不过本文中的雅可比场和传统方法中的雅可比场作用是相同的,即都是一个将控制指令变化
转换为状态变化
的线性算子。
注入归纳偏置:这是机器学习中的一个核心概念。指的是内置在模型架构中的、用于引导模型学习方向的“假设”或“偏好”。一个好的归纳偏置可以让模型用更少的数据学得更好,并具有更强的泛化能力。
本文用到了两种关键的归纳偏置:
线性:模型被强制用这种线性关系来描述执行器状态
的变化如何与三维运动在坐标x处的变化相联系,这使我们可以使用它来密集地预测空间中任意点的三维运动。注本文雅可比场的精确定义:
,它是一个偏导数,数学上清晰地表达了其“灵敏度”或“变化率”的本质。
为什么左边没有 u,右边却在对 u 求导?
答:这个雅可比矩阵 J 描述的是一个“瞬时”的、与当前状态相关的“灵敏度函数”,而不是 u 本身的函数。
-
J(x, I)中不显式包含u,因为它表示的是一个在当前状态下的、瞬时的灵敏度属性,它本身不是u的函数。u是它的输入变量,而不是它的参数。 -
∂x/∂u是它的数学定义,指明了J这个函数所扮演的角色——它是一个将u的变化映射到x的变化的线性算子
这虽然不是物理世界的完全精确描述(物理世界是非线性的),但在微小变化的假设下是一个极其有效的近似。这个偏置迫使模型学习一个简洁、可解析的运动表示,而不是一个混乱的黑箱函数,这使得后续的优化控制成为可能。
空间局部性:模型被引导去相信,一个执行器的动作通常只影响机器人的某个局部区域。例如,驱动拇指的电机应该主要影响拇指上的点,而对小指上的点影响甚微。这个偏置帮助模型理清不同执行器与空间区域之间的对应关系,避免了学习到“动一下拇指,整个机器人都在乱动”这种不符合物理直觉的模型。
如果没有这些偏置,一个纯粹的、任意的深度网络可能会学习到一个在训练数据上表现完美,但遇到新姿势或新指令时就完全失效的复杂函数。这些物理启发的偏置确保了学到的模型遵守基本的物理规则,从而能够泛化。
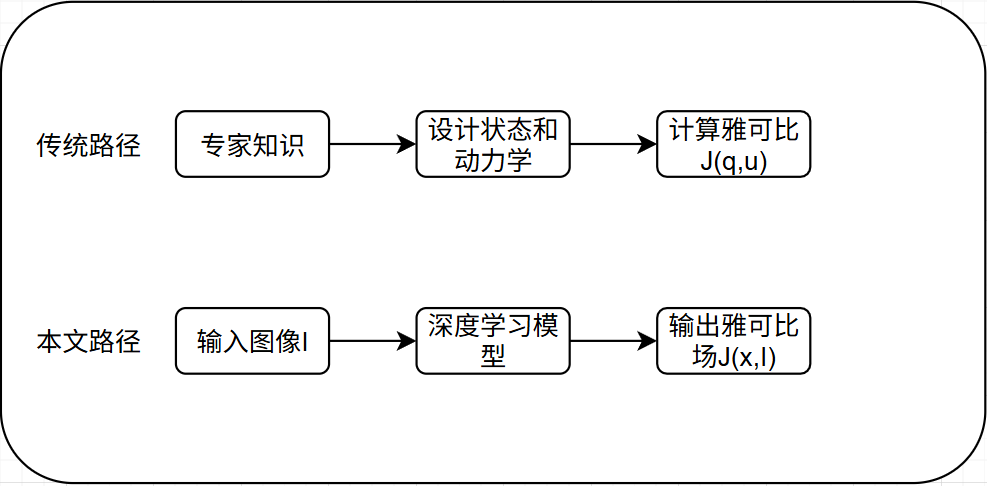
控制器的核心公式:。给定一个期望的微小运动,控制器可以求解这个方程得到对应的微小指令。这个公式密集地预测空间中任何点的3D运动,这是相对于传统方法而言的又一个巨大优势。传统雅可比
只告诉你抽象状态
下图展示在多种真实机器人平台(气动手、Allegro手、HSA平台)上,将预测的运动(实线圆)与真实观察到的运动(虚线圆)进行对比,证明了这个公式在现实世界中的高度准确性。
重建视觉运动雅可比场和辐射场:使用一个神经单视图到3D的模块,来同时重构机器人的几何(形状)和运动学(运动规则),“神经单视图到3D的模块”是总体架构,神经辐射场和视觉运动雅可比场是这个架构同时产出的两个并行结果。 它们共享同一个特征提取器(用于理解输入图像),但最后有一个小小的分叉网络来分别预测几何属性和运动属性。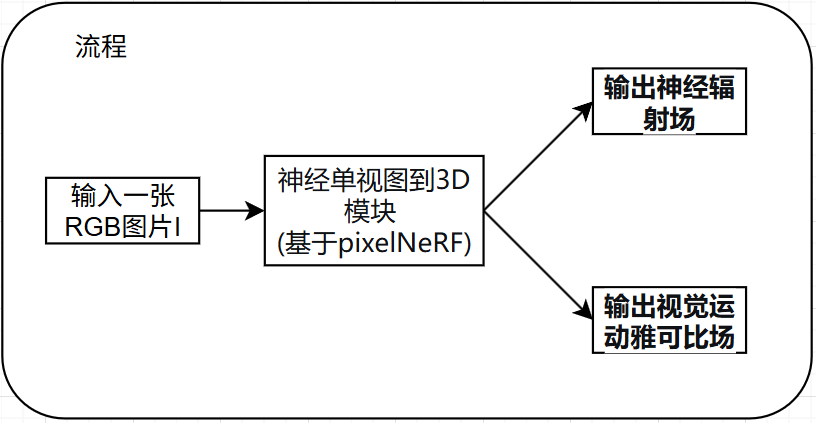
通过相机观测中重建机器人的几何和运动学,作者的状态估计模型对嵌入在机器人中的传感器是不可知的,因此不需要专家建模几何和运动学关系,而是从数据中学习回归这种关系。
逆动力学控制器
目标:利用状态估计模型提供的雅可比场,找到一个能让机器人完成我们指定任务的正确指令。这其中有两个部分:参数化期望运动,反推期望运动的命令。
1. 在2D图像空间或3D中密集地参数化期望运动。参数化指的是用数学的方式描述期望运动,而密集地则是不是只关注一个点,而是表面上一大堆点甚至所有点的运动。因为对于软性机器人结构只关注一个点会造成其他点的乱动,降低了精确性。
下达指令的方式:例如在2D图像中画一条直线,让机器人的某一部分沿着这条直线移动,或者在三维坐标中标出一段路径移动。
2. 以交互速度找到机器人命令。这是一个逆动力学问题,指的是给定期望运动反推下达的指令是多少?而推导指令就需要状态估计提供的雅可比场运动和命令直接的映射关系。
自我监督训练流程
自我监督训练流程,它在没有任何人工标注的情况下,让模型自己学会了3D几何和运动规则。
数据收集
- 方法:让机器人执行大量随机的、安全的微小电机指令
。
- 记录: 同时使用12个RGB-D相机从不同角度拍摄它在执行指令前和执行指令后的状态。
- 输出:生成一个巨大的数据集,包含无数个这样的四元组(执行前图像
,,执行后图像
,执行的指令
创建自我监督信号
这是最关键的一步,因为没有任何人来告诉模型什么是对的。模型必须自己找到“监督信号”。
- 几何监督信号:就是相机直接拍到的 RGB-D图像(颜色+深度)。
- 运动监督信号: 使用现成的光流算法(如RAF),计算连续两帧视频之间的 2D光流场。这个光流场清晰地显示了每个像素从
训练循环
- 随机选择
从12个相机中随机选一个作为源相机,将其
从另外11个相机中随机选一个作为目标相机。模型的任务是预测这个目标相机看到的画面。 - 向前传播
模型接收源相机的图像,输出整个3D空间的神经辐射场和雅可比场。
给它真实的指令。
预测几何: 模型使用神经辐射场,通过体积渲染,生成一张它预测的目标相机应该看到的RGB-D图像。
预测运动: 模型使用雅可比场和指令。然后,同样通过体积渲染,将这个3D运动场渲染成它预测的目标相机应该看到的2D光流图。
- 计算损失与反向传播
几何损失: 将模型预测的目标视图RGB-D图像,与真实的目标视图RGB-D图像进行对比(计算L2损失)。
运动损失: 将模型预测的目标视图光流,与真实的目标视图光流进行对比(计算L2损失)。
反向传播: 总损失 = 几何损失 + 运动损失。通过反向传播,这个总损失会同时更新神经辐射场和雅可比场的参数。
该训练流程的优点:迫使模型学习3D一致性,模型不能只理解输入视图,为了准确预测另一个随机视角的图像和光流,它必须在内部形成一个精确且一致的3D场景表示;将指令与运动关联,为了准确预测光流,模型必须发现和
之间的因果关系;可微分渲染, 整个流程的桥梁是可微分体积渲染。它允许我们将3D场(辐射场、雅可比场)的误差,直接传递回3D场本身的参数上,从而实现端到端的训练。
可微分渲染 是一种特殊的渲染技术,它允许我们将2D图像空间的误差反向传播到3D场景表示的参数上。它不仅能从3D模型生成2D图片,还能计算生成图片中每个像素的颜色相对于3D模型参数的梯度。这表示他能告诉你如何能更好的优化。
光流:描述一个视频中,从一帧到下一帧,每个像素点的运动方向和速度。
技术实现:输入连续的两帧图像 和
。输出一个光流场,这是一个和图像尺寸一样的数组,每个位置存储一个
( 向量,表示该像素从第一帧到第二帧的移动。,
)
论文中的作用:光流是训练视觉运动雅可比场的监督信号。模型预测的3D运动被渲染成2D光流后,要与这个真实的、从视频中计算出来的光流进行对比,从而判断模型预测得准不准。
点跟踪: 点跟踪是光流的一个特例,它不关心整个画面的运动模式,而是专注于追踪视频序列中某些特定、有意义的点的轨迹。
技术实现:首先,在图像中检测出一些有代表性的“关键点”(通常是角点、边缘等纹理丰富的区域),然后,在后续帧中,寻找这些关键点的新位置,最后,输出一系列轨迹,每条轨迹记录了一个特定点在视频中随着时间变化的位置
论文中的作用:在控制阶段,点跟踪被用来从演示视频中提取参考轨迹。例如,我们可以跟踪机器人指尖上的一个点,把它的运动路径记录下来。然后,我们的控制器就努力让真实的机器人指尖复现这条轨迹。
体绘制:体绘制是一种从3D体积数据生成2D图像的技术。它不像传统渲染那样处理物体表面,而是把3D空间想象成一块充满“发光雾”的区域,通过计算所有光线穿过这块“雾”累积的效果来生成图像。
想象一个充满发光彩色烟雾的玻璃立方体,有些地方的烟雾很浓(高密度),光线穿不过去,有些地方的烟雾很稀薄(低密度),光线可以轻松穿透,烟雾本身有颜色(例如,红色区域、蓝色区域)。
站在这个立方体前面,用相机对着它拍照。体绘制就是模拟你相机里最终成像的过程:从相机发射无数条光线,穿过这个玻璃立方体,每条光线在穿过烟雾时,会不断地与烟雾“互动”,对于稀薄的烟雾,光线吸收一点颜色,但大部分继续前进,对于浓厚的烟雾,光线被大量吸收或散射,无法继续深入,因此它后面的东西你就看不见了,最终,每条光线携带的累积颜色和亮度,就形成了你相机中一个像素的颜色。
论文中的作用:论文中有两个并行的体绘制过程。
渲染几何(从神经辐射场到RGB-D图像):
-
3D体积数据:神经辐射场。对于任何3D点
x,它给出颜色c(x)和密度σ(x)。 -
体绘制过程:模拟上述“发光烟雾”的过程。对于每个像素,发射一条光线,沿着光线采样一堆3D点,获取它们的颜色和密度,然后通过积分公式(论文中的公式3, 4)合成出该像素的最终颜色和深度。
-
结果:生成一张预测的2D RGB-D图像。
渲染运动(从雅可比场到2D光流):
-
3D体积数据:视觉运动雅可比场
J(x, I)。给定指令δu,可以计算出每个3D点的运动δx = J * δu。 -
体绘制过程:这是一个非常巧妙的操作。
-
对一条光线上的每个3D样本点,用雅可比场计算它的运动
δx。 -
然后,用同样的体绘制权重,将这些3D运动
δx加权平均,得到一个综合的3D位移。 -
最后,将这个3D位移投影到2D图像平面上,就得到了这个像素的2D光流向量。
-
-
结果:生成一张预测的2D光流图。
正是体绘制这座桥梁,使得模型能够通过比较渲染出来的2D图像/光流与真实观测到的2D图像/光流之间的差异,来反向调整其内部的3D表示(辐射场和雅可比场),最终学会仅从单张图片就能精准推断机器人的3D几何与运动学。
部署
部署阶段的核心思想是:利用已经训练好的、强大的“状态估计模型”,仅使用一个普通的单目RGB摄像头,实现对各种机器人的实时、精准控制。
当部署时,这篇论文的框架可以解决实现给定的3D或2D图像空间运动轨迹的命令,从而实现机器人操作中的两个应用。
应用一:2D图像空间轨迹跟踪
这是最直观的应用方式,非常适合模仿学习。
-
任务来源:有一段演示视频(比如,专家操作机器人的录像)。
-
轨迹生成:使用点跟踪算法(如TAPIR),在视频中跟踪机器人身上的一些关键点(如指尖),从而得到一系列在2D图像像素坐标中的运动轨迹。
-
控制目标:让真实机器人身上的对应点,在当前的相机画面中,严格地复现演示视频中的2D轨迹。
-
优势:
-
极其方便:无需3D建模,直接使用2D视频作为编程接口。
-
对变化鲁棒:即使机器人的动力学发生改变(如抓取物体后负载变化)、出现物理磨损或被部分遮挡,系统依然能完成跟踪。因为它依赖的是当前的视觉反馈,而不是一个预设的、不变的模型。
-

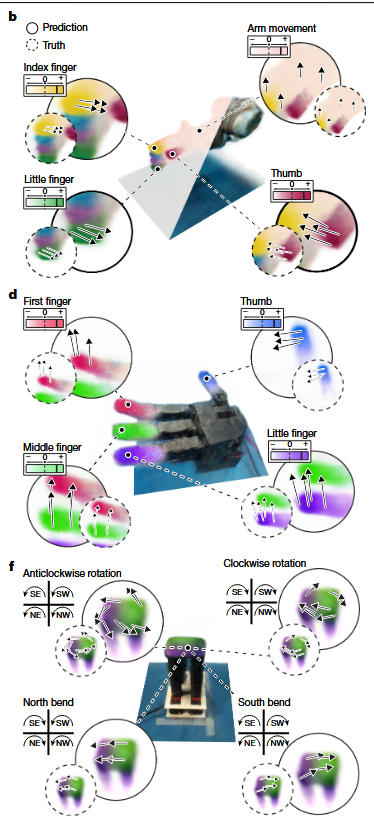
上图就是从视觉上对多样化机器人进行闭环控制。
| 子图 | 机器人 | 任务 | 关键 |
| a | 3D打印气动手 | 抓握物体;在有遮挡物下运动 | 展示了在软体机器人上的成功控制及对视觉干扰的鲁棒性。 |
| b | Allegro Hand | 精确控制每个手指闭合握拳 | 展示了在高自由度刚性系统上的精确控制能力 |
| c | HSA 平台 | 执行复杂的旋转和弯曲运动 | 展示了在难以建模的超材料平台上的控制能力。 |
| d | 气动手+UR5臂 | 从杯中取工具并用其推苹果 | 展示了复合技能的长时序任务能力 |
| e,f | Poppy Ergo Jr. | 在空中绘制字母“MIT” | 极具说服力:该机器人成本低、背隙大,难以建模。此任务证明方法能克服硬件缺陷,完成精确轨迹跟踪。 |
应用二:3D轨迹跟踪与视角迁移
这个应用更强大,展示了3D表示的真正价值。
-
任务来源:同样是一段演示视频,但这段视频是从另一个视角拍摄的,这个视角在部署时可能无法获得(比如,演示时是俯拍,部署时是侧拍)。
-
轨迹生成:
-
提升到3D:对于演示视频的每一帧,使用训练好的神经辐射场,将2D图像提升为一个3D点云。这个过程相当于理解了“在这个视角下,机器人的3D形状到底是什么样的”。
-
形成3D轨迹:将这些连续的3D点云连接起来,就得到了一条与视角无关的3D轨迹。
-
-
控制目标:在部署的新视角下,让真实机器人的3D形状与演示的3D轨迹对齐。
-
如何实现:
-
控制器使用的代价函数从2D的像素距离,变成了3D形状距离(如Wasserstein距离、Chamfer距离)。
-
它优化指令
-
-
优势:
-
摆脱视角束缚:一次演示,任意视角复用。极大地提高了演示数据的利用效率。
-
更精确的3D控制:由于是在3D空间中进行规划,避免了2D图像中因视角造成的歧义。
-
闭环控制流程
无论是哪种应用,部署时都遵循一个实时闭环:
-
感知:单目RGB相机捕获当前图像
。
-
状态估计:状态估计模型处理
和 辐射场。
-
规划与优化:
-
控制器根据任务目标(2D或3D轨迹上的下一个点),利用雅可比场解决优化问题:
-
求解出当前最优的电机指令
。
-
-
执行:将指令
-
反馈:机器人运动后,相机捕获新的图像
。
-
循环:整个过程以 12Hz 的频率重复,形成一个高速的“感知-规划-行动”闭环,不断纠正误差,直至任务完成。
测试阶段
测试阶段的核心目标是验证训练好的系统在未知情况下的性能。作者从两个主要方面进行了评估:
-
感知与预测能力:系统重建3D几何和预测运动的准确性。
-
控制性能:系统在闭环控制中执行复杂任务的精确度、鲁棒性和通用性。
测试遵循一个核心原则:测试所用的机器人配置和任务,均未在训练数据中出现过,以检验模型的泛化能力。
定量分析与鲁棒性测试如下图所示,该图提供了坚实的定量证据,支撑了上图的定性展示,证明了方法的精确性、鲁棒性和物理一致性。
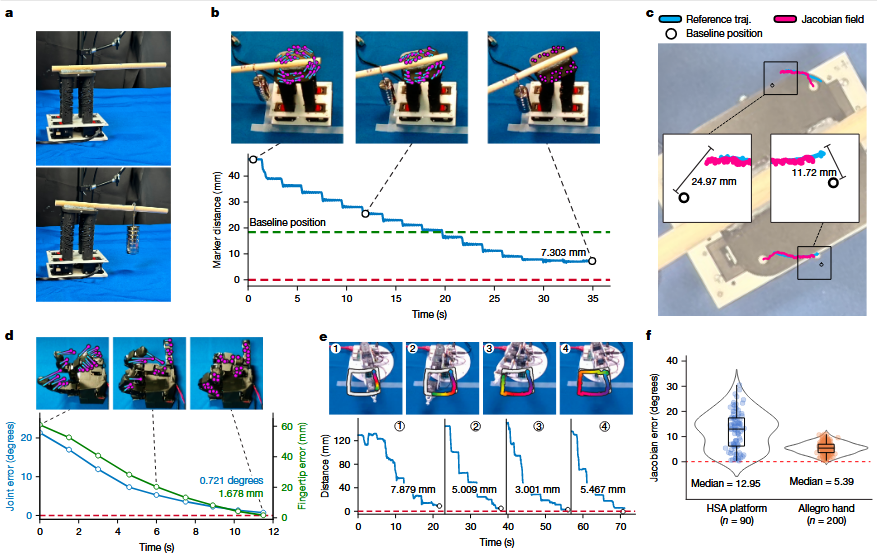
| 子图 | 详细说明 |
| a,b,c | 鲁棒性测试:主动改变系统动力学。 - a:在HSA平台上附加一根木棍和350g重物,使其静态平衡位置发生改变,动力学模型完全不同于训练时。 - b, c:尽管存在此外部扰动,系统依然控制平台完成了复杂的旋转运动,并最终达到目标,位置误差仅为7.3mm。这证明了控制器不依赖预设的动力学模型,而是基于实时视觉反馈进行调整。 |
| d | 精度测试:Allegro手。 绘制了执行轨迹过程中,关节角度误差和指尖位置误差随时间收敛的曲线。最终误差极小(关节<3°,指尖<4mm),证明了高精度控制能力。 |
| e | 精度测试:Poppy机械臂。 展示了机械臂在绘制方形轨迹时,末端执行器与目标点的距离随时间收敛的曲线。平均误差小于6mm,再次证明了对低成本、高背隙机器人的有效控制。 |
| f | 预测准确性验证。 将系统学习到的雅可比场与通过物理仿真器(Drake)计算出的解析雅可比进行对比。结果显示高度一致,证明系统从视频中真正学习到了物理上正确的运动学结构,而非仅仅记忆。 |

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)