Microsoft VibeVoice:用于长语音、多发言者对话的最佳免费 TTS
按 Enter 键或单击以查看大图VIBEVOICE 是由 Microsoft Research 开发的长篇多说话人文本转语音 (TTS) 系统。它能够生成长达 90 分钟的对话式音频,具有多达4 个不同的扬声器,所有扬声器都是高质量的,并且具有自然的轮流。它建立在下一个令牌扩散框架之上,这意味着它通过扩散过程而不是传统的采样方法一次预测一个令牌的音频。这不是播客语音克隆噱头,它是为真实的对话结构
我对 2025 年非常好奇的一件事是音频 AI 的兴起。我们已经看到许多 TTS 模型、对话式 AI、音乐生成模型相继发布,现在一个大巨头 Microsoft 也加入了竞争并发布了 VibeVoice,这是 NotebookLM 的免费替代品,其形式包括非常长的演讲和多轮演讲者对话。
按 Enter 键或单击以查看大图
什么是 VIBEVOICE?
按 Enter 键或单击以查看大图
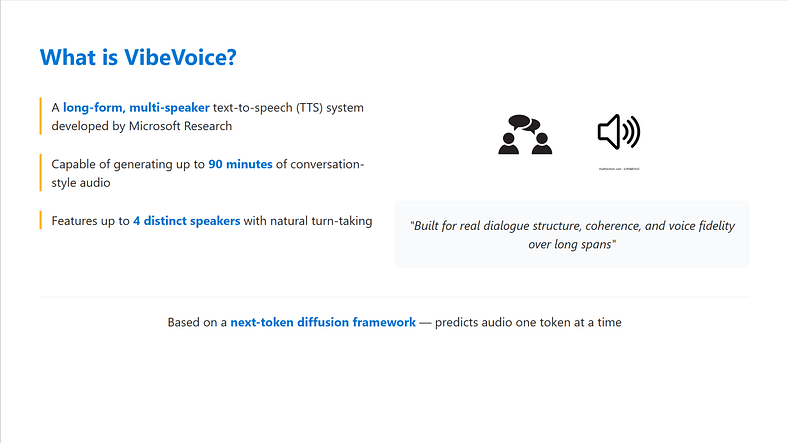
VIBEVOICE 是由 Microsoft Research 开发的长篇多说话人文本转语音 (TTS) 系统。
它能够生成长达 90 分钟的对话式音频,具有多达 4 个不同的扬声器,所有扬声器都是高质量的,并且具有自然的轮流。
它建立在下一个令牌扩散框架之上,这意味着它通过扩散过程而不是传统的采样方法一次预测一个令牌的音频。
这不是播客语音克隆噱头,它是为真实的对话结构、连贯性和长时间的语音保真度而构建的。
它有什么独特之处?
按 Enter 键或单击以查看大图

按 Enter 键或单击以查看大图

- 超长上下文:处理 64K 上下文窗口,支持长达 90 分钟的音频。
- 多扬声器支持:在一次会话中最多有 4 个不同的扬声器,具有真正的来回动态。
- 混合分词器系统:结合了声学(基于 VAE)和语义(基于 ASR)分词器。
- 压缩怪物:只需 7.5 个令牌/秒即可实现 3200 倍压缩,这意味着以非常低的计算量快速生成。
- 每个说话人没有单独的语音模型:它使用文本 + 语音提示 + 说话人 ID,所有这些都嵌入到单个流中。
- 下一个代币扩散:采用代币扩散头,通过更好的噪声建模实现更流畅、更高保真度的生成。
- 简单的输入设计:您可以向它提供语音提示嵌入和由说话者标记的文本脚本的串联输入。
模型上下文协议:面向初学者的高级 AI 代理(生成式 AI 书籍)
Amazon.com:模型上下文协议:面向初学者的高级 AI 代理(生成式 AI 书籍)电子书:Gupta、Mehul、Sen...
这个怎么运作
按 Enter 键或单击以查看大图
其核心:
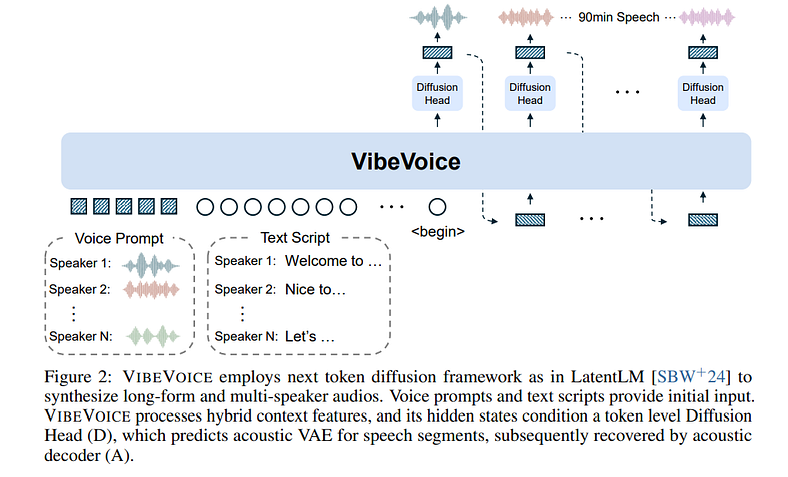
输入:你给它混合:
- 每个发言人的简短语音提示 (zN)
- 每个说话者的文本脚本 (TN)
- 标有角色 ID,如 Speaker 1、Speaker 2 等。
代币化:
- 音频由两个分词器处理:
- 声学分词器:一种 VAE(实际上是 σ-VAE 变体),可在保持质量的同时大量压缩音频。
- 语义分词器:像 ASR 模型一样进行训练,以捕获“什么”(内容),而不仅仅是“如何”(声音)。
语言模型 (LLM):
- 它使用 Qwen2.5(1.5B 或 7B),经过训练可以处理长多模态序列。
- 输入将通过此 LLM。
扩散解码器:
- 一个小型扩散头不是直接输出音频,而是获取每个标记的隐藏状态并迭代对其进行降噪。
- 最终音频通过解码器重建,解码器将 VAE 标记转换回波形。
输出:您可以获得干净、自然的语音,扬声器之间的流畅性良好,时间逼真。
按 Enter 键或单击以查看大图
体系结构摘要
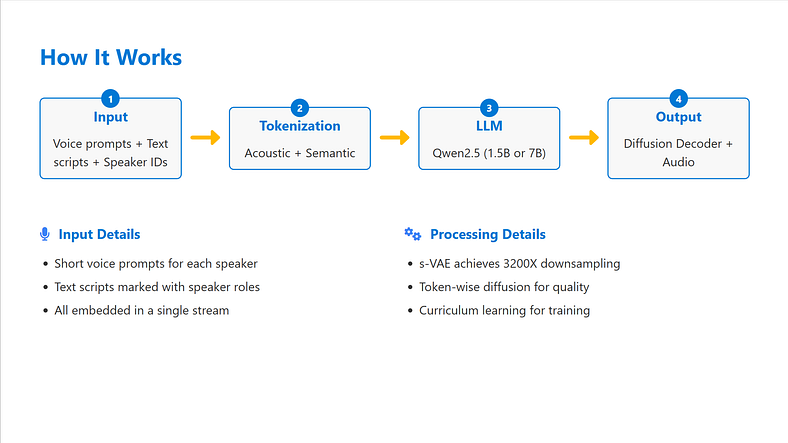
分词器:
- 声学:σ-VAE,基于变压器,3200X 下采样。
- 语义:Transformer 编码器 + ASR 样式解码器(训练后丢弃)。
- 核心模型:预训练的 Qwen2.5 LLM(1.5B 或 7B 参数)
- 解码器:轻量级4层扩散头+VAE解码器。
培训:
- 分词器被冻结。
- 只训练 LLM 和扩散头。
- 使用课程学习(从较短的序列开始,增长到 64K 个令牌)。
- 无分类器指导提高了推理过程中的质量。
基准
按 Enter 键或单击以查看大图
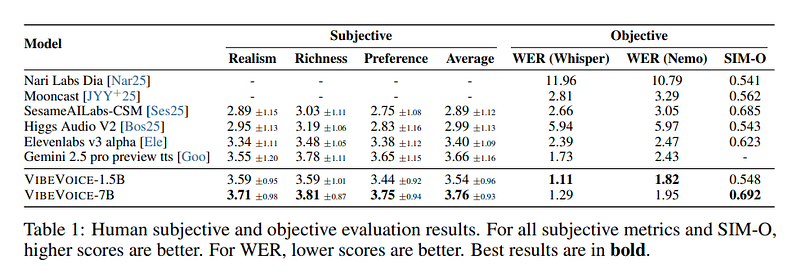
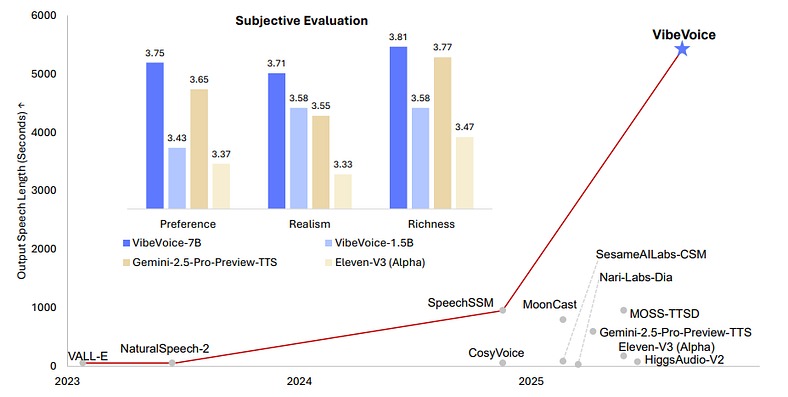
VIBEVOICE 7B 在所有 3 个人工评判类别中都击败了专有和开放系统,如 Gemini 和 ElevenLabs。
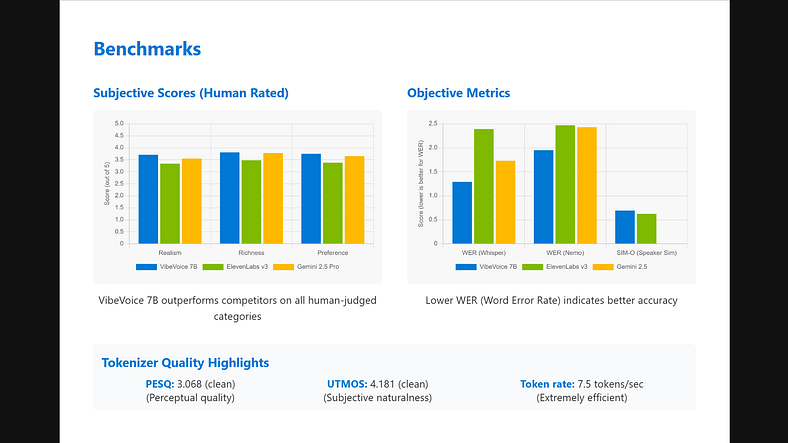
分词器质量(LibriTTS 测试集)
- PESQ(感知质量):3.068(干净),2.848(其他)
- UTMOS(主观自然性):4.181(干净)、3.724(其他)
- 令牌速率:仅 7.5 个令牌/秒
他们以一英里的优势击败了大多数现有的分词器,同时将音频压缩到荒谬的程度。
按 Enter 键或单击以查看大图
主要限制
- 语言:仅支持流利的英语和中文。
- 无背景声音:仅纯语音,无音乐或音效。
- 没有重叠的言论:演讲者不会互相交谈。
- 安全性:深度伪造、冒充的潜在滥用。
Microsoft 明确不鼓励在没有进一步护栏的情况下进行商业部署。
如何免费使用 Vibe Voice?
该模型有 2 个版本,1.5B 和 7B,权重是开源的。
微软/VibeVoice-1.5B ·拥抱脸
我们正在通过开源和开放科学推进人工智能并实现人工智能民主化。
VIBEVOICE 不仅仅是另一种 TTS 模型。它正在突破长篇对话合成的界限,在干净的模块化架构中桥接音频压缩、语言建模和扩散生成。由于 7.5Hz 标记化,它不会使用臃肿的资源。
就缩放和对话质量而言,这可能是目前用于播客、有声读物或合成对话的最佳公开系统。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)