Spring AI MCP实战(3)实现RAG知识库,读取pdf并拆分存入向量库
/ MySQL 配置// PGVector 配置// MySQL 数据源@Bean@Primary// 连接池配置// 其他优化配置// 泄漏检测阈值 60秒// PGVector 数据源@Bean// 连接池配置// PGVector 特定配置// 其他优化配置// 泄漏检测阈值 30秒@Bean// 可选:配置JdbcTemplate// 查询超时30秒。
前言
前面我们实现了function calling和mcp,这一节我们来实现RAG知识库
引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.27</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store</artifactId>
</dependency>
<!-- 包含QuestionAnswerAdvisor-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
<version>1.0.0</version>
</dependency>前面两个是用来读取pdf的,如果想要自己处理pdf的截取的话,建议还是使用第二个依赖,因为spring ai对pdf的处理只有分页和分段截取,对于大多数中文文档的话,分段截取也是识别不了的
第三个就是我们要使用的pgvector的向量库的依赖,我们要把划分好的文档通过向量工具向量化,再存入pgvector中
最后一个是因为我们要使用QuestionAnswerAdvisor去给大模型注册知识库并能够调用,具体的流程如下:

然后因为我们需要同时使用mysql和pgvector数据库,默认的连接方法就不行了,需要修改一下配置文件和自己创建配置类:
配置文件修改:
Spring:
datasource:
mysql:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://your_server:3306/weather_city?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8&allowPublicKeyRetrieval=true
username: root
password: 123456
# 连接池配置(可选)
hikari:
maximum-pool-size: 20
minimum-idle: 5
connection-timeout: 30000
idle-timeout: 600000
max-lifetime: 1800000
pgvector:
driver-class-name: org.postgresql.Driver
username: postgres
password: postgres
url: jdbc:postgresql://your_server:15432/ai_rag_knowledge
type: com.zaxxer.hikari.HikariDataSource
hikari:
maximum-pool-size: 5
minimum-idle: 2
idle-timeout: 30000
connection-timeout: 30000
table:
parameter:
dimension: 1536
distance_type: COSINE_DISTANCE
initial: true自定义数据库的配置类:
package com.hyk.mcpclient.config;
import com.zaxxer.hikari.HikariDataSource;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.jdbc.core.JdbcTemplate;
import javax.sql.DataSource;
@Configuration
public class DataSourceConfig {
// MySQL 配置
@Value("${spring.datasource.mysql.url}")
private String mysqlUrl;
@Value("${spring.datasource.mysql.username}")
private String mysqlUsername;
@Value("${spring.datasource.mysql.password}")
private String mysqlPassword;
@Value("${spring.datasource.mysql.hikari.maximum-pool-size:20}")
private int mysqlMaxPoolSize;
@Value("${spring.datasource.mysql.hikari.minimum-idle:5}")
private int mysqlMinIdle;
@Value("${spring.datasource.mysql.hikari.connection-timeout:30000}")
private long mysqlConnectionTimeout;
@Value("${spring.datasource.mysql.hikari.idle-timeout:600000}")
private long mysqlIdleTimeout;
@Value("${spring.datasource.mysql.hikari.max-lifetime:1800000}")
private long mysqlMaxLifetime;
// PGVector 配置
@Value("${spring.datasource.pgvector.url}")
private String pgVectorUrl;
@Value("${spring.datasource.pgvector.username}")
private String pgVectorUsername;
@Value("${spring.datasource.pgvector.password}")
private String pgVectorPassword;
@Value("${spring.datasource.pgvector.hikari.maximum-pool-size:5}")
private int pgVectorMaxPoolSize;
@Value("${spring.datasource.pgvector.hikari.minimum-idle:2}")
private int pgVectorMinIdle;
@Value("${spring.datasource.pgvector.hikari.connection-timeout:30000}")
private long pgVectorConnectionTimeout;
@Value("${spring.datasource.pgvector.hikari.idle-timeout:30000}")
private long pgVectorIdleTimeout;
// MySQL 数据源
@Bean
@Primary
public DataSource mysqlDataSource() {
HikariDataSource dataSource = new HikariDataSource();
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setJdbcUrl(mysqlUrl);
dataSource.setUsername(mysqlUsername);
dataSource.setPassword(mysqlPassword);
// 连接池配置
dataSource.setMaximumPoolSize(mysqlMaxPoolSize);
dataSource.setMinimumIdle(mysqlMinIdle);
dataSource.setConnectionTimeout(mysqlConnectionTimeout);
dataSource.setIdleTimeout(mysqlIdleTimeout);
dataSource.setMaxLifetime(mysqlMaxLifetime);
dataSource.setPoolName("MySQL-HikariPool");
// 其他优化配置
dataSource.setLeakDetectionThreshold(60000); // 泄漏检测阈值 60秒
dataSource.setConnectionTestQuery("SELECT 1");
dataSource.setValidationTimeout(5000);
return dataSource;
}
// PGVector 数据源
@Bean
public DataSource pgVectorDataSource() {
HikariDataSource dataSource = new HikariDataSource();
dataSource.setDriverClassName("org.postgresql.Driver");
dataSource.setJdbcUrl(pgVectorUrl);
dataSource.setUsername(pgVectorUsername);
dataSource.setPassword(pgVectorPassword);
// 连接池配置
dataSource.setMaximumPoolSize(pgVectorMaxPoolSize);
dataSource.setMinimumIdle(pgVectorMinIdle);
dataSource.setConnectionTimeout(pgVectorConnectionTimeout);
dataSource.setIdleTimeout(pgVectorIdleTimeout);
dataSource.setPoolName("PGVector-HikariPool");
// PGVector 特定配置
dataSource.setConnectionInitSql("CREATE EXTENSION IF NOT EXISTS vector");
// 其他优化配置
dataSource.setLeakDetectionThreshold(30000); // 泄漏检测阈值 30秒
dataSource.setConnectionTestQuery("SELECT 1");
dataSource.setValidationTimeout(5000);
return dataSource;
}
// MySQL JdbcTemplate
@Bean
public JdbcTemplate mysqlJdbcTemplate() {
JdbcTemplate jdbcTemplate = new JdbcTemplate(mysqlDataSource());
// 可选:配置JdbcTemplate
jdbcTemplate.setQueryTimeout(30); // 查询超时30秒
return jdbcTemplate;
}
// PGVector JdbcTemplate
@Bean
public JdbcTemplate pgVectorJdbcTemplate() {
JdbcTemplate jdbcTemplate = new JdbcTemplate(pgVectorDataSource());
// 可选:配置JdbcTemplate
jdbcTemplate.setQueryTimeout(30); // 查询超时30秒
return jdbcTemplate;
}
}我们的mybatis plus由于设置了mysql source是primary的,所以不用改
配置Pgvector:
package com.hyk.mcpclient.config;
import jakarta.annotation.Resource;
import org.springframework.ai.openai.OpenAiEmbeddingModel;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.pgvector.PgVectorStore;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import javax.sql.DataSource;
@Configuration
public class VectorStroreConfig {
@Value("${spring.datasource.pgvector.table.parameter.dimension}")
String dimensions;
@Value("${spring.datasource.pgvector.table.parameter.distance_type}")
String distanceType;
@Value("${spring.datasource.pgvector.table.parameter.initial}")
String initializeSchema;
@Resource
public OpenAiEmbeddingModel openAiEmbeddingModel;
@Bean
public VectorStore vectorStore(@Qualifier("pgVectorJdbcTemplate") JdbcTemplate pgVectorJdbcTemplate) {
// 使用 PgVectorStore 的构造函数来创建实例
return PgVectorStore.builder(pgVectorJdbcTemplate, openAiEmbeddingModel)
.dimensions(Integer.valueOf(dimensions)) // 传入向量维度
.distanceType(PgVectorStore.PgDistanceType.valueOf(distanceType)) // 传入距离类型
.initializeSchema(Boolean.valueOf(initializeSchema)) // 是否初始化表
.indexType(PgVectorStore.PgIndexType.HNSW) // 传入索引类型
.build(); // 构建最终的 PgVectorStore 对象
}
}
然后我们去新建RAG ChatClient:
package com.hyk.mcpclient.client;
import com.hyk.mcpclient.common.prompt;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.client.advisor.vectorstore.QuestionAnswerAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.openai.OpenAiChatModel;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RAGChatClientConfig {
@Resource
private ChatMemory myAgentChatMemory;
@Bean("ragChatClient")
public ChatClient ragChatClient(OpenAiChatModel openAiChatModel, VectorStore vectorStore){
return ChatClient.builder(openAiChatModel)
.defaultSystem(prompt.PROMPT_RAG)
.defaultAdvisors(QuestionAnswerAdvisor.builder(vectorStore).build(),
new SimpleLoggerAdvisor(),
MessageChatMemoryAdvisor.builder(myAgentChatMemory).build()
)
.build();
}
}
这里就要加入QuestionAnswerAdvisor
然后是我们的controller:
package com.hyk.mcpclient.controller;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
@Slf4j
@CrossOrigin(origins = "*")
public class RAGChatController {
@Resource
private ChatClient ragChatClient;
@GetMapping(value = "/ai/rag", produces = "text/html; charset=utf-8")
public Flux<String> testRAG(@RequestParam String message, @RequestParam String conversationId) {
return ragChatClient.prompt()
.user(message)
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID, conversationId))
.stream()
.content();
}
}
这样我们的大模型就能够从向量数据库中查询最相似的向量了
额外:对pdf文本的拆分处理:
笔者感觉对每个不同的pdf要根据内容进行处理,我使用的例子是一个包含了166道选择题目的文本,我的分割依据就是 “本题答案” 这几个字,因为这几个字会固定出现在每一题的最后,这样文本的分割是最好的
我的文本分割代码:
package com.hyk.mcpclient;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import org.junit.jupiter.api.Test;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import java.util.ArrayList;
import java.util.List;
@SpringBootTest
public class PDFReaderTest {
@jakarta.annotation.Resource
private VectorStore vetorStore;
Resource resource = new FileSystemResource("E:\\JavaLearning\\code\\mcp-project\\mcp-client\\src\\test\\java\\com\\hyk\\mcpclient\\(更新中)柏浪涛-刑法每日一题(1-166).pdf");
@Test
public void testQuestionExtractionByAnswer() {
try {
try (PDDocument document = PDDocument.load(resource.getInputStream())) {
PDFTextStripper stripper = new PDFTextStripper();
String fullText = stripper.getText(document);
// 使用"本题答案:"作为分割标志
List<Document> questionDocuments = splitByAnswerMarker(fullText);
System.out.println("=== 按答案分割题目 ===");
System.out.println("成功提取题目数: " + questionDocuments.size());
// 显示所有题目的基本信息
for (int i = 0; i < questionDocuments.size(); i++) {
Document doc = questionDocuments.get(i);
String number = (String) doc.getMetadata().get("question_number");
String content = doc.getText();
System.out.println("\n=== 题目 " + number + " (长度: " + content.length() + ") ===");
System.out.println(content);
System.out.println("元数据: " + doc.getMetadata());
System.out.println("-----------------------");
}
// 统计信息
System.out.println("\n=== 提取统计 ===");
System.out.println("总题目数: " + questionDocuments.size());
//存储成向量
vetorStore.add(questionDocuments);
} catch (Exception e) {
e.printStackTrace();
}
} catch (Exception e) {
e.printStackTrace();
}
}
private List<Document> splitByAnswerMarker(String fullText) {
List<Document> documents = new ArrayList<>();
// 按"本题答案:"分割文本,每个题目包含完整的题目+解析+答案
String[] parts = fullText.split("(?=本题答案)");
for (String part : parts) {
if (part.trim().isEmpty()) continue;
// 提取题目编号
String questionNumber = extractQuestionNumberFromPart(part);
if (questionNumber != null && !part.trim().isEmpty()) {
Document document = new Document(part.trim());
document.getMetadata().put("question_number", questionNumber);
document.getMetadata().put("source", "柏浪涛-刑法每日一题");
document.getMetadata().put("type", "question");
documents.add(document);
}
}
return documents;
}
private String extractQuestionNumberFromPart(String part) {
// 从部分文本中提取题目编号
String[] lines = part.split("\n");
// 查找题目编号(通常是第一部分的第一行)
for (String line : lines) {
String trimmedLine = line.trim();
java.util.regex.Matcher matcher = java.util.regex.Pattern.compile("^(\\d+)\\.").matcher(trimmedLine);
if (matcher.find()) {
return matcher.group(1);
}
}
return null;
}
}然后调用vectorStore就可以存入向量数据库了
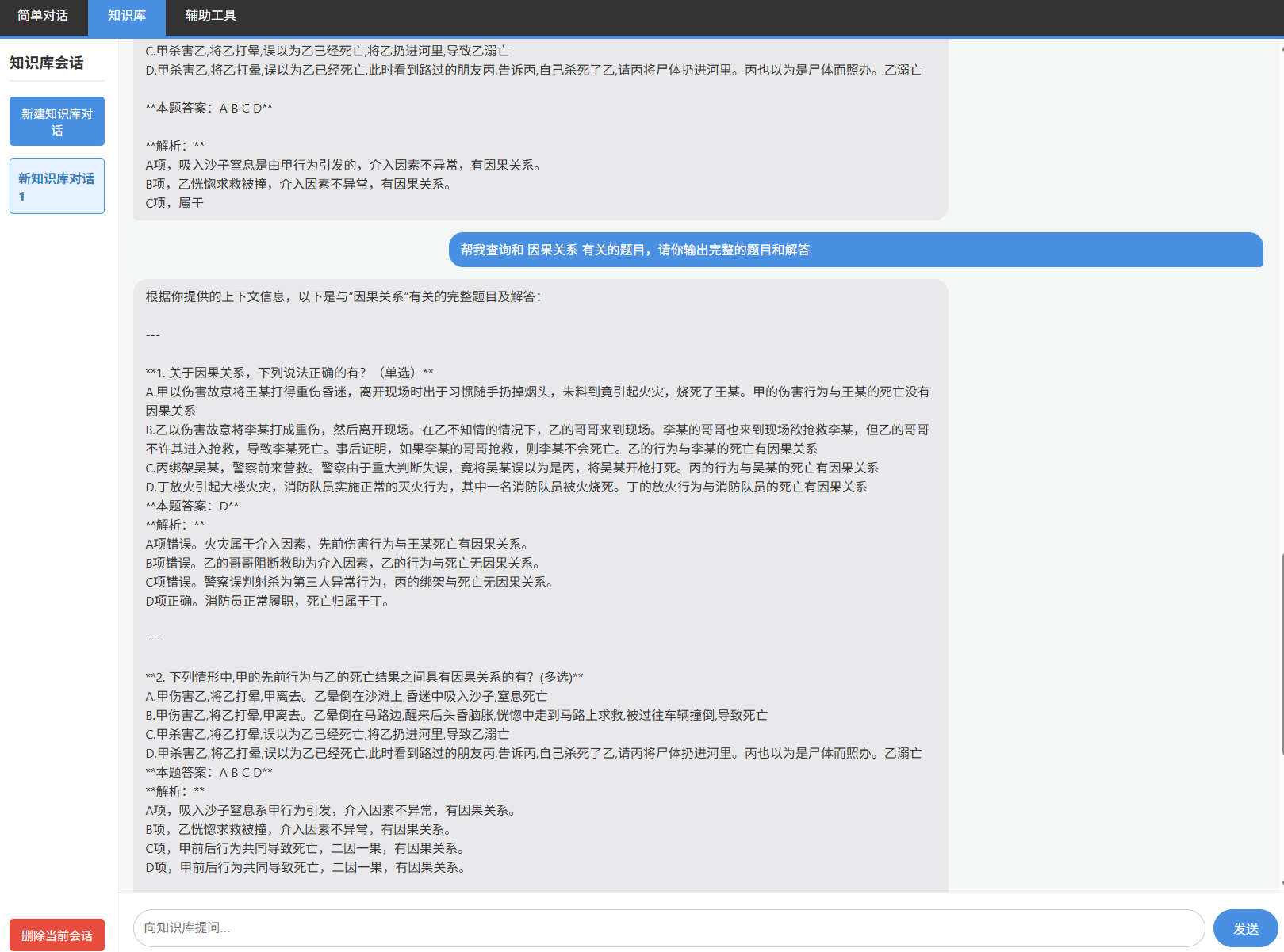
结果展示:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)