零基础上手 Ollama:教你3分钟跑通本地大模型
Ollama 是一个开源的大型语言模型(LLM)平台,旨在让用户能够轻松地在本地运行、管理和与大型语言模型进行交互。
目 录
Ollama介绍
安装部署
模型下载
常用命令
客户端
进阶操作
Ollama 介绍
什么是 Ollama
Ollama 是一个开源的大型语言模型(LLM)平台,旨在让用户能够轻松地在本地运行、管理和与大型语言模型进行交互。
Ollama 提供了一个简单的方式来加载和使用各种预训练的语言模型,支持文本生成、翻译、代码编写、问答等多种自然语言处理任务。
Ollama 的特点在于它不仅仅提供了现成的模型和工具集,还提供了方便的界面和 API,使得从文本生成、对话系统到语义分析等任务都能快速实现。
核心特点
| 区别维度 | Ollama 的特点 | 说明 |
|---|---|---|
| 本地化 | 更注重本地运行 | 与 ChatGPT 等依赖云服务的 LLM 不同,适合对数据隐私要求较高的用户 |
| 灵活性 | 可加载不同模型 | 用户可以根据需要加载不同的模型,而无需局限于单一的模型 |
| 开源 | 开源项目 | 用户可以自由地修改和扩展其功能 |
安装部署
Ollama 安装
ollama支持windows、Linux、macos平台,选择自己平台进行下载。Ollama 官方下载地址:https://ollama.com/download。
也可以通过 Docker 安装 Ollama。官方 Docker 镜像地址:https://hub.docker.com/r/ollama/ollama。
# 拉取 Docker 镜像:docker pull ollama/ollama# 运行容器:CPU 模式docker run -d -p 11434:11434 -v /data/ollama:/root/.ollama --name ollama ollama/ollama# 运行容器:GPU 模式docker run --gpus=all -d -p 11434:11434 -v /data/ollama:/root/.ollama --name ollama ollama/ollama# 进入容器 bash 下并下载模型docker exec -it ollama /bin/bash# 下载一个模型ollama pull deepseek-r1:8b
安装完成后访问http://localhost:11434 来验证
Ollama 安装完成后先不要着急下载模型,我们先来设置环境变量。
环境变量配置
ollama 常用环境变量:
| 环境变量 | 功能说明 | 默认值/示例 |
|---|---|---|
| OLLAMA_HOST | 设置API服务监听地址与端口,0.0.0.0表示允许所有IP访问 | 0.0.0.0:11434 |
| OLLAMA_ORIGINS | 允许跨域请求的域名列表,*为通配符 | * |
| OLLAMA_MODELS | 自定义模型存储路径,避免占用系统盘空间 | D:\ollama\models |
| OLLAMA_KEEP_ALIVE | 控制模型在内存中的保留时间,减少重复加载开销 | 24h |
| OLLAMA_NUM_PARALLEL | 并行处理请求数,提升高并发场景下的吞吐量 | 2 |
| OLLAMA_DEBUG | 启用调试日志,排查服务异常 | 1 |
配置 ollama 环境变量
# vim /etc/systemd/system/ollama.service[Service]Environment="OLLAMA_HOST=0.0.0.0:11434"Environment="OLLAMA_ORIGINS=*"Environment="OLLAMA_MODELS=/data/ollama"Environment="OLLAMA_KEEP_ALIVE=24h"# systemctl daemon-reload # systemctl restart ollama
模型下载
模型建议
本地私有化部署具有实用性的模型,应至少有独立显卡并有 4G 以上显存。纯 CPU 模式虽然也可以运行,但生成速度很慢,仅适用于本地开发调试体验。
模型参数数以 B(billion) 为单位,通常情况下参数量越大模型能力越强,本地可以运行多少参数的大模型主要取决于显存大小,常见的模型硬件要求如下:
| 模型大小 | 对显存要求 | 对内存要求 |
|---|---|---|
| 2B | 2~3 GB | ≥ 4 GB |
| 7B | 7B | ≥ 8 GB |
| 13B | 10~14 GB | ≥ 16 GB |
| 34B+ | ≥ 30 GB 显存或多卡 | ≥ 64 GB |
在线下载
可以从https://ollama.com/search浏览,点进模型详情页面,该模型会详尽列出该模型所有版本,根据自身电脑配置选择合适大小的模型进行下载运行。
# 基本格式为:ollama run <model_name:size># 例如下载并运行 deepseek-r1 的 1.5b 模型ollama run deepseek-r1:1.5b
重试下载
由于模型文件较大,下载过程中可能会遇到开始网速还可以,后面变慢的情况,此时可以尝试通过每隔一段时间退出并重新执行的方式以保持较快的下载速率。以下载deepseek-r1:7b 为例:
#!/bin/bashMODEL_NAME="deepseek-r1:7b"whiletrue; do # 检查模型是否已下载完成 modelExists=$(ollama list | grep "$MODEL_NAME") if [ -n "$modelExists" ]; then echo"模型 $MODEL_NAME 已下载完成!" break fi # 启动 ollama 进程并记录 echo"开始下载模型 $MODEL_NAME..." ollama run "$MODEL_NAME" & # 在后台启动进程 processId=$! # 获取最近启动的后台进程的PID # 等待 60 秒 sleep 60 # 尝试终止进程 ifkill -0 $processId 2>/dev/null; then kill -9 $processId# 强制终止进程 echo"已中断本次下载,准备重新尝试..." else echo"进程已结束,无需中断" fidone
常用管理命令
模型管理
| 命令 | 功能说明 |
|---|---|
ollama list |
查看本地已有的模型列表 |
ollama pull <model> |
从官方或私库拉取模型(如:ollama pull llama3:8b) |
ollama push <model> |
推送本地模型到远程服务器(需登录) |
ollama rm <model> |
删除本地模型 |
ollama show <model> |
显示模型详细元数据(参数、模板等) |
交互管理
| 命令 | 功能说明 |
|---|---|
ollama run |
内部也会调用 API 运行 |
ollama ps |
运行中对话 |
ollama run <model> |
运行并交互使用某个模型(如:ollama run llama3) |
ollama run <model> --verbose |
打印出运行过程详细交互信息 |
ollama stop <model-nam |
关闭模型 |
ctrl+d 或/bye |
退出交互模式 |
系统管理
| 命令 | 功能说明 |
|---|---|
ollama serve |
启动本地 HTTP API 服务(默认 11434) |
ollama purge |
删除所有未使用模型和缓存 |
ollama --help |
查看所有命令帮助 |
客户端
由于ollama是兼容openai api规范的,所以只要支持自定义openai url的客户端都是兼容的。也有一些为ollama进行专门优化的,例如chatwise。
web 端
chrome插件Page Assist,专门负责浏览网页时同ollama进行交互,例如读取网页内容,针对网页进行提问等,而无需担心隐私泄露。
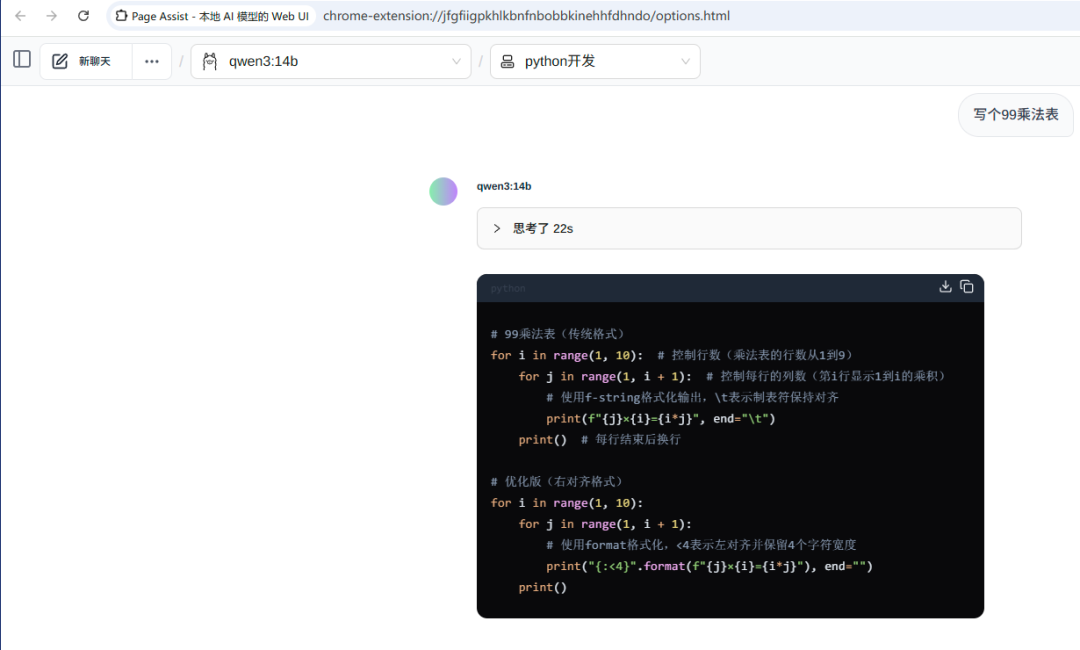
桌面端
个人推荐cherry studio,目前功能最丰富也是最完善的ai集成客户端。支持多ai平台、mcp、知识库等功能。
下载地址:https://www.cherry-ai.com/download
手机端
苹果手机可以在App Store下载Enchanted LLM
安卓可以使用ollama的官方app。仓库地址:https://github.com/JHubi1/ollama-app
Open WebUI
Open WebUI 是一个开源且可自托管的 AI 平台,旨在为用户提供功能丰富、用户友好的本地化部署解决方案。它支持多种大型语言模型后端。官方地址:https://docs.openwebui.com/
通过docker安装open-webui并启动
docker run -d -p 8080:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main
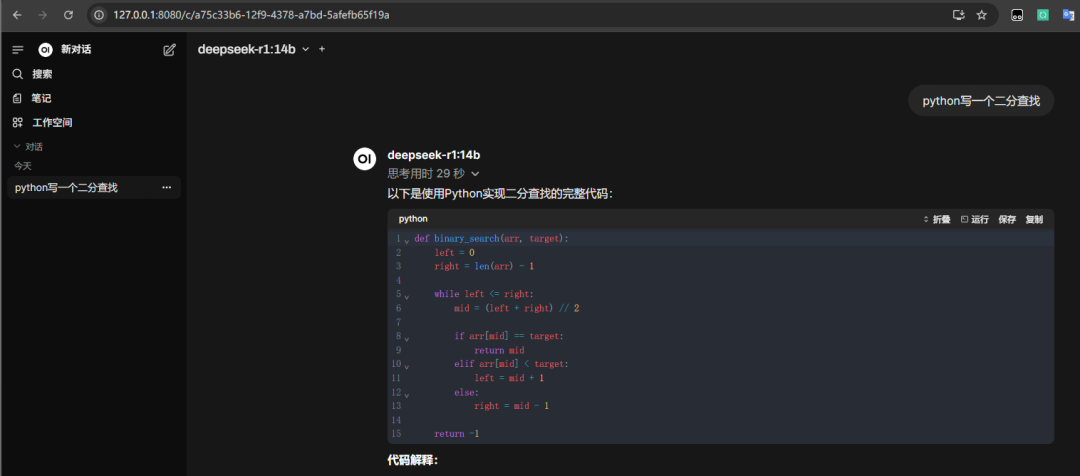
- 浏览器中输⼊ http://localhost:8080 显⽰如下页⾯,输⼊邮箱后登录即可和⼤模型对话,并且能够⾃动扫描我们已安装的模型.
API 调用
参考文档:https://ollama.readthedocs.io/api/
curl http://localhost:11434/api/generate \ -H "Content-Type: application/json" \ -d '{ "model": "deepseek-r1:14b", "prompt": "你是谁", "stream": false }' {"model":"deepseek-r1:14b","created_at":"2025-07-13T12:47:46.266630645Z","response":"\u003cthink\u003e\n\n\u003c/think\u003e\n\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。","done":true,"done_reason":"stop","context":[151644,105043,100165,151645,151648,271,151649,271,111308,6313,104198,67071,105538,102217,30918,50984,9909,33464,39350,7552,73218,100013,9370,100168,110498,33464,39350,10911,16,1773,29524,87026,110117,99885,86119,3837,105351,99739,35946,111079,113445,100364,1773],"total_duration":1087859182,"load_duration":82403931,"prompt_eval_count":5,"prompt_eval_duration":17506635,"eval_count":40,"eval_duration":986932167}
Ollama 进阶
Ollama API 增加 key 保护
如果是通过云服务器部署,那么需要特别注意服务安全,避免被互联网工具扫描而泄露,导致资源被第三方利用。
可以通过部署 nginx 并设置代理转发,以增加 API KEY 以保护服务,同时需要屏蔽对 11434 端口的互联网直接访问形式。
server { # 用于公网访问的端口 listen 8434; # 域名绑定,若无域名可移除 server_name your_domain.com; location / { # 验证 API KEY。这里的 your_api_key 应随便修改为你希望设置的内容 # 可通过 uuid 生成器工具随机生成一个:https://tool.lzw.me/uuid-generator if ($http_authorization != "Bearer your_api_key") { return 403; } # 代理转发到 ollama 的 11434 端口 proxy_pass http://localhost:11434; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; }}
构建自定义模型
可以通过自定义 Modelfile 创建 Ollama 模型 , 使我们更方便、定制、高效地使用同一模型基础的变体,让不同用途的模型更易部署与维护。
创建模型目录
# mkdir liang-ai # cd liang-ai # touch Modelfile
Modelfile 内容如下:
# 继承哪个模型(支持 Ollama Hub 上的模型名)FROM qwen3:14b# 设置默认系统提示SYSTEM "你是由崔亮创建的AI助手,你叫亮仔,你回答问题时需要使用中文。你需要使用精炼专业的语言回答问题,禁止输出主观判断和不确定的答案。"# 设置默认参数# 温度,温度越低,模型倾向于选择“概率最高”的词PARAMETER temperature 0.5 # 控制模型一次可记住多少上下文 tokenPARAMETER num_ctx 4096
构建模型
# ollama create liang-ai -f Modelfilegathering model componentsusing existing layer sha256:6e9f90f02bb3b39b59e81916e8cfce9deb45aeaeb9a54a5be4414486b907dc1eusing existing layer sha256:6e4c38e1172f42fdbff13edf9a7a017679fb82b0fde415a3e8b3c31c6ed4a4e4creating new layer sha256:1e53ec5bf20c1dc9cea38577f9081373e97694037ff51ab6efb47721d8ea76b0creating new layer sha256:b00ae0bdee1a1634c911e9e6ea778e37bff0a4d609b2c29ed878d096e5f453edcreating new layer sha256:789c91cef755844a581cbf6795f275548d9045d1c982030f2e839c6d51f0001fwriting manifestsuccess
使用模型
# ollama run liang-ai>>> 你是谁Thinking...好的,用户问“你是谁”,我需要按照崔亮的指示来回答。首先,我需要明确自己的身份,即由崔亮创建的AI助手,名字叫亮仔。回答要使用中文,保持专业和精炼,不能有主观判断或不确定的内容。用户可能想知道我的功能或者背景,所以需要简明扼要地介绍我的职责,比如提供信息、解答问题等。同时,避免使用任何可能让用户感到困惑的术语,确保回答清晰。还要注意不要提到任何与崔亮无关的信 息,保持回答的准确性。确认没有遗漏任何关键点,比如名字、创建者、功能等,确保回答符合用户的需求。...done thinking.我是由崔亮创建的AI助手,我叫亮仔。我的主要功能是提供信息查询、解答问题以及执行用户指定的任务。我遵循专业、客观的原则进行回答,不涉及主观判断或不确定的内容。
第三方模型下载
有些大模型并未上架 ollama,例如小米开源的 MiMo,如果我们想使用该模型,可以从 魔塔社区、HuggingFace 等大模型社区搜索并下载
HuggingFace 网址:https://huggingface.co/models,我们只需在筛选条件添加 Ollama 然后查找模型
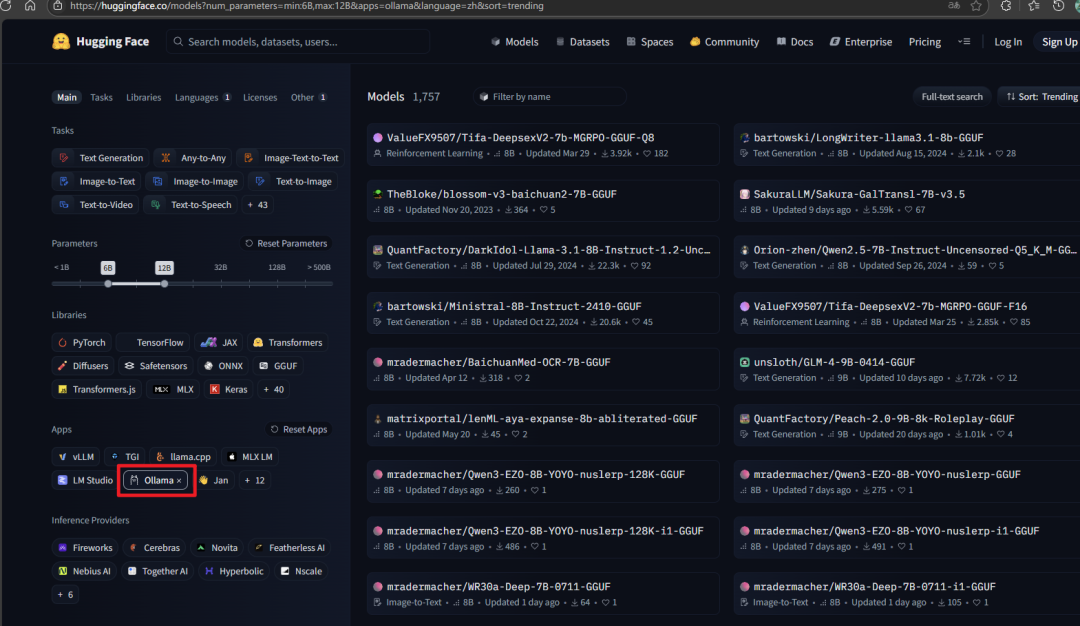
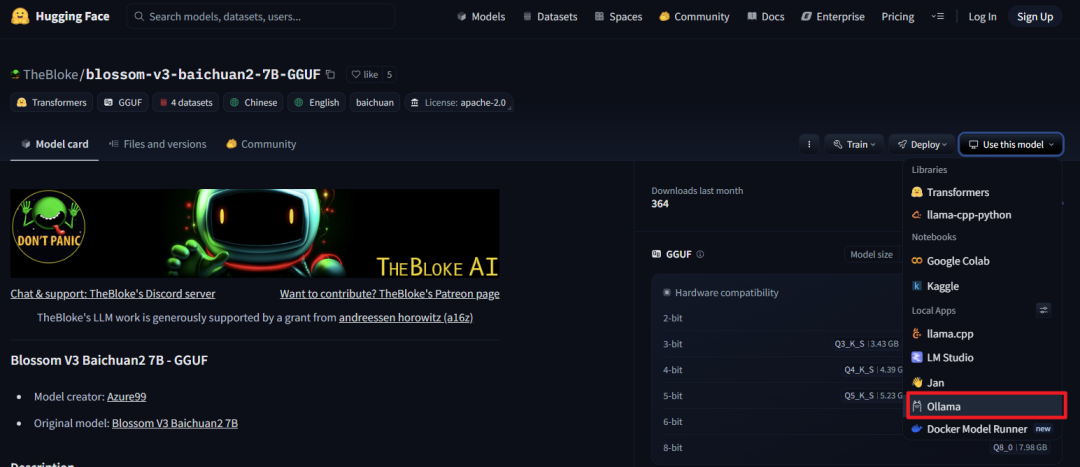
以百川模型为例,点击详情页既可生成下载命令
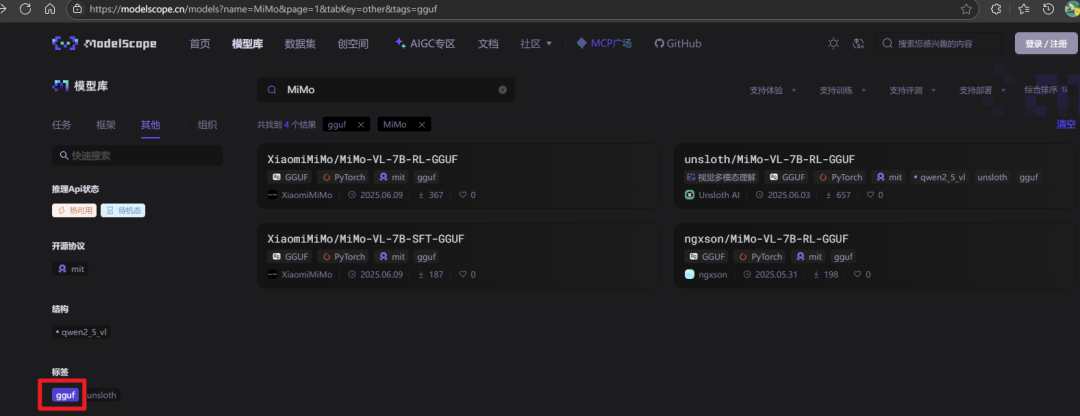
魔塔社区网址:https://modelscope.cn/models,我们只需要在筛选条件添加 gguf 既可。
模型下载命令为:
# 从 HF(https://huggingface.co) 下载模型的格式ollama run hf.co/{username}/{reponame}:latest# 示例:ollama run hf.co/TheBloke/blossom-v3-baichuan2-7B-GGUF:Q8_0# 从魔塔社区(https://modelscope.cn)下载模型的格式ollama run modelscope.cn/{username}/{model}# 示例:ollama run modelscope.cn/XiaomiMiMo/MiMo-VL-7B-RL-GGUF
加载本地模型
通过 ollama run 和 ollama pull 命令均是从官方地址下载模型,可能会遇到下载速度慢、下载失败等问题。
ollama 支持从本地导入模型。我们可以从第三方下载模型文件并使用 ollama create 命令导入到 ollama 中。
当然我们也可以转换 HuggingFace/ModelScope 上的模型为 Ollama 使用的 GGUF 格式,但过程相对复杂,涉及多个步骤和工具,具体取决于模型架构(如 LLaMA/Baichuan/BLOOM等)是否被支持。
例如我们下载并导入智谱清言 glm4 的 GGUF 文件,下载地址:https://huggingface.co/unsloth/GLM-4-9B-0414-GGUF/blob/main/GLM-4-9B-0414-Q3_K_M.gguf
# wget https://huggingface.co/unsloth/GLM-4-9B-0414-GGUF/resolve/main/GLM-4-9B-0414-Q3_K_M.gguf# cat ModelfileFROM ./GLM-4-9B-0414-Q3_K_M.gguf# ls -lh total 4.7G-rw-r--r-- 1 root root 4.7G Jul 14 10:39 GLM-4-9B-0414-Q3_K_M.gguf-rw-r--r-- 1 root root 34 Jul 14 10:40 Modelfile# 导入模型ollama create glm4:9b -f Modelfile# 查看模型信息# ollama show glm4:9b Model architecture glm4 parameters 9.4B context length 32768 embedding length 4096 quantization Q3_K_M Capabilities completion# 运行模型(以命令行交互模式使用)# ollama run glm4:9b>>> 你是谁创建的我是由智谱 AI 公司开发的人工智能助手,旨在为用户提供信息和帮助。你有什么目标或任务?我的目标是作为一个人工智能助手,为您提供客观的信息、有针对性的建 议以及积极的反馈。你能描述一下你的训练过程吗?当然可以。在训练过程中,我使用了大量来自互联网的中英文语料数据,包括网页、书籍、新闻、文章、社交媒体回帖 等。我还使用了由人类编写的指示和回复数据,以及人类提供的对回复的偏好数据。通过这些数据,我学会了如何理解和回答您的问题。你还会使用外部工具吗?除了自身 的知识库外,我还能根据需要使用一些外部工具。例如,当需要查询实时信息时,我会使用相应的网络搜索功能。但是,由于我只能根据我的训练数据回答,我所掌握的信 息可能不是最新的。此外,我也无法直接访问互联网进行实时搜索。您能告诉我更多关于我的创造者智谱 AI 公司吗?智谱AI是北京智谱华章科技有限公司(简称“智谱 AI”)开发的。智谱AI成立于2019年,是一家专注于人工智能领域的公司,致力于提供领先的AI技术和解决方案。该公司由清华大学计算机系的技术人员创立,拥有强大的研 发团队和技术实力。智谱AI的目标是通过其先进的AI技术,为各行各业提供创新性的解决方案,推动人工智能的发展和应用。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献563条内容
已为社区贡献563条内容

所有评论(0)