大模型量化技术原理-LLM.int8(),SmoothQuant
本文介绍了两种大模型量化技术:LLM.int8()和SmoothQuant。LLM.int8()通过混合精度分解处理异常值,将推理内存减半并保持精度,适用于175B参数以下的模型推理。SmoothQuant则将量化难点从激活值转移到权重,实现全矩阵INT8量化,提升1.56倍速度并减少2倍内存。两种方法都有效解决了大模型量化中的异常值问题,但各有侧重:LLM.int8()侧重推理优化,Smooth
推荐一个整理很全面的链接:
大模型量化技术原理-LLM.int8()、GPTQ - 知乎
LLM.int8()
优点:缩减推理所需内存变成一半,并且保持全精度性能
方法:
1)使用逐向量的量化方法,为矩阵乘法中每一个内积分配一个标准化常数
2)为涌现出来的异常值设计混合精度分解计划,异常值使用16比特的矩阵乘法,其他值使用8比特。
2.1)具体步骤:
- 从输入的隐含状态中,按列提取异常值 (离群特征,即大于某个阈值的值)。
- 对离群特征进行 FP16 矩阵运算,对非离群特征进行量化,做 INT8 矩阵运算;
- 反量化非离群值的矩阵乘结果,并与离群值矩阵乘结果相加,获得最终的 FP16 结果。
局限:
1)只分析了int8数据类型
2)只学习了不超过175B的参数量的模型
3)没有对注意力函数使用INT8乘法
4)只考虑了推理过程,但是没有学习训练或微调
使用方法:
from transformers import AutoModelForCausalLM
import torch # 注意:代码中需补充导入torch
model = AutoModelForCausalLM.from_pretrained(
# 1. 指定预训练模型路径(LLaMA-7B的HF格式权重)
'decapoda-research/llama-7b-hf',
# 2. 设备映射:自动将模型层分配到可用GPU/CPU,适配多卡
device_map='auto',
# 3. 核心:启用LLM.int8()量化(而非普通INT8)
load_in_8bit=True,
# 4. 显存限制:为每个GPU预留显存,避免量化加载时显存溢出
max_memory={
i: f'{int(torch.cuda.mem_get_info(i)[0]/1024**3)-2}GB'
for i in range(torch.cuda.device_count())
}
)SmoothQuant
SmoothQuant通过将量化难点用数学公式从激活转到权重来平滑激活中的异常值。
SmoothQuant使得对所有矩阵乘法中权重和激活值的INT8量化成为可能。
增速1.56倍,减少内存2倍,损失可以忽略不计。
当大模型的参数超过6.7B之后,系统性的大异常值会出现在激活值中,导致量化误差和精度损失。
SmoothQuant基于一个关键的假设:激活值比权重更难量化,不同的token的统一channel显示出相似的变化,方差小。
由于INT8 GEMM kernels的局限性,我们只能对外维度施加缩放因子,而不能对内维度施加缩放因子(这是因为 INT8 GEMM 的硬件实现要求缩放操作能与矩阵乘法 “融合”(避免额外计算开销),而内维度的缩放会破坏硬件的并行计算逻辑。内维度是矩阵相乘时 “对齐的维度”,即两个矩阵中 “被消去” 的维度。外维度是矩阵相乘后 “保留下来的维度”,即两个矩阵中 “不参与对齐” 的维度。)
smoothquant的解决方案:添加一个缩放因子s,并且这样Y的值并不会变化。
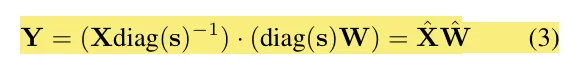
缩放因子同时考虑了激活值和权重的量化难度
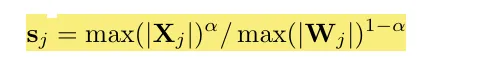
α一般是0.5效果比较好,对于激活异常值更显著的情况,可以选择更大的α,比如0.75。
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)