[LLM Post-training] 在线强化学习Online RL - Task04
一、理论
在线强化学习(OnlineRL)
概念
当我们提到 “在线强化学习(Online RL)”时,通常指的是 在在线学习场景中应用的强化学习方法。
在线强化学习是指模型在生成新响应的过程中实时地接收反馈并更新参数,即模型一边推理一边学习。
它与“离线强化学习(Offline RL)”的区别在于:
- Online RL:模型在训练过程中不断生成新的响应、计算奖励、更新参数;
- Offline RL:模型仅从预收集的 (prompt, response, reward) 数据集中学习,不再生成新响应。
与 SFT(监督微调)或 DPO(偏好优化)不同,RL 需要学习或定义一个奖励函数(Reward Function),让模型能够自主探索和优化自身行为。
工作机制
在线强化学习通常让模型自主探索更好的响应。 其典型流程如下:
- 准备一批 Prompt(输入提示);
- 将这些 Prompt 输入语言模型;
- 模型生成对应的 Response;
- 将 (prompt, response) 对送入 奖励函数(Reward Function);
- 奖励函数为每对 (prompt, response) 打分;
- 获得 (prompt, response, reward) 三元组;
- 使用这些数据来更新语言模型。
奖励函数
在在线强化学习中,奖励函数的设计至关重要。常见有两种类型:
1. 训练好的奖励模型(Reward Model)
- 数据来源:人类偏好标注,形成对比样本 (better vs worse responses)。
- 奖励模型训练目标:
L=log(σ(rj−rk))L = \log(\sigma(r_j - r_k))L=log(σ(rj−rk))
若人类认为响应 j 优于 k,则鼓励模型提升rjr_jrj,降低rkr_krk。
特点:
- 通常基于已有的 Instruct 模型初始化;
- 可适用于开放式任务(如对话、价值对齐、安全性优化);
- 通过大规模人类或机器生成偏好数据训练;
- 但在“正确性导向”的任务(如代码、数学、函数调用)中可能不够精确。
2. 可验证奖励(Verifiable Reward)
在“正确性导向”场景中,更推荐使用可验证奖励:
- 数学任务:验证模型输出是否与标准答案匹配。
- 编程任务:通过 单元测试(Unit Tests) 检验代码执行结果是否正确。
特点:
- 需提前准备真值(Ground Truth)或测试集;
- 准备成本较高,但奖励信号更精确可靠;
- 更适合训练推理类模型(Reasoning Models),如代码、数学领域。
两种奖励函数的主要区别是:
- 在开放式任务上,我们使用Reward Model,而在正确性导向的任务上,我们使用可验证奖励
两种主流在线强化学习算法
1. 近端策略优化-PPO(Proximal Policy Optimization)
第一代 ChatGPT 所采用的 Online RL 算法。
基本思想:
- 限制策略更新幅度(通过 KL 散度约束),防止模型偏离原始分布;
- 引入价值模型 (Value Model / Critic) 评估每个 token 的价值;
- 使用**广义优势估计(GAE)**计算每个 token 的优势AtA_tAt。
工作流程:
- 输入一组查询(queries) ( qqq );
- 通过 策略模型(Policy Model)(即语言模型本身)生成响应;
- 响应被送入以下模块:
-
参考模型(Reference Model)(原始模型副本):计算 KL 散度,限制模型不偏离原始分布;
-
奖励模型(Reward Model):计算奖励;
-
价值模型(Value Model) 或 评论者模型(Critic Model):为每个 Token 分配价值。
- 使用 广义优势估计(Generalized Advantage Estimation, GAE)
来计算每个 Token 的 优势函数(Advantage),反映该 Token 的贡献。
PPO 的目标函数:
JPPO(θ)=Eq∼P(Q),o∼πθold(O∣q)[1∣o∣∑t=1∣o∣min[πθ(ot∣q,o<t)πθold(ot∣q,o<t)At,clip(πθ(ot∣q,o<t)πθold(ot∣q,o<t),1−ε,1+ε)At]]\mathcal{J}_{PPO}(\theta) = \mathbb{E}_{q \sim P(Q), o \sim \pi_{\theta_{\text{old}}}(O|q)} \left[ \frac{1}{|o|} \sum_{t=1}^{|o|} \min \left[ \frac{\pi_{\theta}(o_t|q, o_{<t})}{\pi_{\theta_{\text{old}}}(o_t|q, o_{<t})} A_t, \text{clip} \left( \frac{\pi_{\theta}(o_t|q, o_{<t})}{\pi_{\theta_{\text{old}}}(o_t|q, o_{<t})}, 1 - \varepsilon, 1 + \varepsilon \right) A_t \right] \right]JPPO(θ)=Eq∼P(Q),o∼πθold(O∣q) ∣o∣1t=1∑∣o∣min[πθold(ot∣q,o<t)πθ(ot∣q,o<t)At,clip(πθold(ot∣q,o<t)πθ(ot∣q,o<t),1−ε,1+ε)At]
(1) 比率项的设计动机 —— 重要性采样修正分布偏差
在强化学习中,我们的目标是最大化新策略πθ\pi_\thetaπθ 下的期望回报:
J(θ)=Eτ∼πθ[R(τ)]J(\theta) = \mathbb{E}{\tau \sim \pi\theta}[R(\tau)]J(θ)=Eτ∼πθ[R(τ)]
然而,直接在新策略下重新采样轨迹代价高昂,因此 PPO 采用旧策略πθold\pi_{\theta_{\text{old}}}πθold收集样本,并通过 重要性采样 修正分布偏差:
rt(θ)=πθ(at∣st)πθold(at∣st)r_t(\theta) = \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)}rt(θ)=πθold(at∣st)πθ(at∣st)
该比率衡量当前策略相对于旧策略在某一动作上的“倾向变化”:
- 若rt>1r_t > 1rt>1:说明新策略更倾向该动作,应强化;
- 若rt<1r_t < 1rt<1:说明新策略更少选择该动作,应抑制。
这种设计使模型能够在复用旧数据的同时,近似优化新策略的目标,兼顾样本效率与分布一致性。
(2) 裁剪项的设计动机 —— 稳定更新与防止过拟合
在实际训练中,如果策略更新过大(即rtr_trt远离 1),可能导致:
- 模型概率分布发生剧烈漂移;
- 梯度方差爆炸或崩溃;
- 性能出现“灾难性遗忘”。
为此,PPO 引入裁剪操作:
clip(rt,1−ε,1+ε)\text{clip}(r_t, 1 - \varepsilon, 1 + \varepsilon)clip(rt,1−ε,1+ε)
限制单步更新幅度不超过 ±ε(通常 ε=0.1~0.2)。
通过取两者的最小值:
min(rtAt,clip(rt,1−ε,1+ε)At)\min \big(r_t A_t, \text{clip}(r_t, 1 - \varepsilon, 1 + \varepsilon) A_t \big)min(rtAt,clip(rt,1−ε,1+ε)At)
实现如下效果:
- 若更新幅度合理,使用原始rtAtr_tA_trtAt;
- 若更新过大,采用裁剪值,防止模型偏离旧策略;
- 在保证奖励提升的同时,保持训练过程稳定。
这种机制是对 TRPO (PPO 的核心思想其实源自 TRPO(Trust Region Policy Optimization))的 KL约束 的一种高效近似,使 PPO 兼具理论稳健性与计算效率。
总结:
- 每个 Token 拥有独立的优势值;
- 反馈粒度更细;
- 但需额外训练价值模型 → 占用更多 GPU 内存。
2. 分组相对策略优化-GRPO(Group Relative Policy Optimization)
DeepSeek 提出,用于优化大型语言模型的推理能力。
基本思想:
- 对每个 Prompt 生成多个响应;
- 计算每个响应的 Reward 与 KL;
- 以组为单位计算相对奖励(Relative Reward);
- 整个响应共享一个优势值(无需 Critic)。
工作流程:
- 对每个 Prompt,模型生成多个响应 ( O1,O2,...,OgO_1, O_2, ..., O_gO1,O2,...,Og );
- 对每个响应计算:
- 奖励(Reward)
- 与参考模型的 KL 散度;
- 对同一组(Group)响应计算相对奖励(Relative Reward);
- 将相对奖励作为整个响应的优势值;
- 使用此优势更新策略模型。
损失函数
GRPO与PPO采用相同的优化目标,只是优势函数的计算不同
主要区别:
- 生成多个响应;
- 不再需要价值模型(Value Model) → 显存占用低;
- 所有 Token 在同一响应中共享相同优势值,优势估计粒度较粗;
- 特别适合“可验证奖励”场景,如数学、代码。
4.1.5 PPO 与 GRPO 的比较总结
| 特征 | PPO | GRPO |
|---|---|---|
| 优势估计 | 基于价值模型 (Value Model) 的精细估计 | 基于响应组的相对奖励 (Relative Reward) |
| 计算粒度 | 每个 Token 拥有独立优势 | 整个响应共享同一优势 |
| 显存需求 | 较高(需训练 Critic) | 较低(无 Critic) |
| 样本效率 | 高(样本利用率好) | 较低(需更多样本) |
| 奖励适配 | 适合连续或模型化奖励 | 适合二元/可验证奖励 |
| 应用场景 | 聊天、对齐、安全优化 | 数学、代码、推理任务 |
小结
- Online vs Offline RL:前者实时生成与更新,后者基于静态数据。
- Reward Function 两类:
- 学习型(Reward Model) → 模仿人类偏好;
- 可验证型(Verifiable Reward) → 基于真值校验。
- 核心算法对比:
- PPO → 精细 token 级优化,适合开放式任务;
- GRPO → 高效响应级优化,适合推理任务。
实践
实现奖励函数
只看最终结果,当结果匹配时给与正向分数,否则为0
def reward_func(completions, ground_truth, **kwargs):
# Regular expression to capture content inside \boxed{}
matches = [re.search(r"\\boxed\{(.*?)\}", completion[0]['content']) for completion in completions]
contents = [match.group(1) if match else "" for match in matches]
# Reward 1 if the content is the same as the ground truth, 0 otherwise
return [1.0 if c == gt else 0.0 for c, gt in zip(contents, ground_truth)]
在生成模型的回应时,我们同样需要让模型在给出最终结果时以r"\\boxed\{(.*?)\}"的形式给出以便于我们使用正则表达式提取最终计算结果。
可以测试一下reward的工作结果:
# 正确的样例
sample_pred = [[{"role": "assistant",
"content": r"...Calculating the answer. \boxed{72}"}]]
ground_truth = ["72"]
reward = reward_func(sample_pred, ground_truth)
print(f"Positive Sample Reward: {reward}")
# 错误的样例
sample_pred = [[{"role": "assistant",
"content": r"...Calculating the answer \boxed{71}"}]]
ground_truth = ["72"]
reward = reward_func(sample_pred, ground_truth)
print(f"Negative Sample Reward: {reward}")
加载数据集
这次使用的是huggingface上一个数学数据集openai/gsm8k:
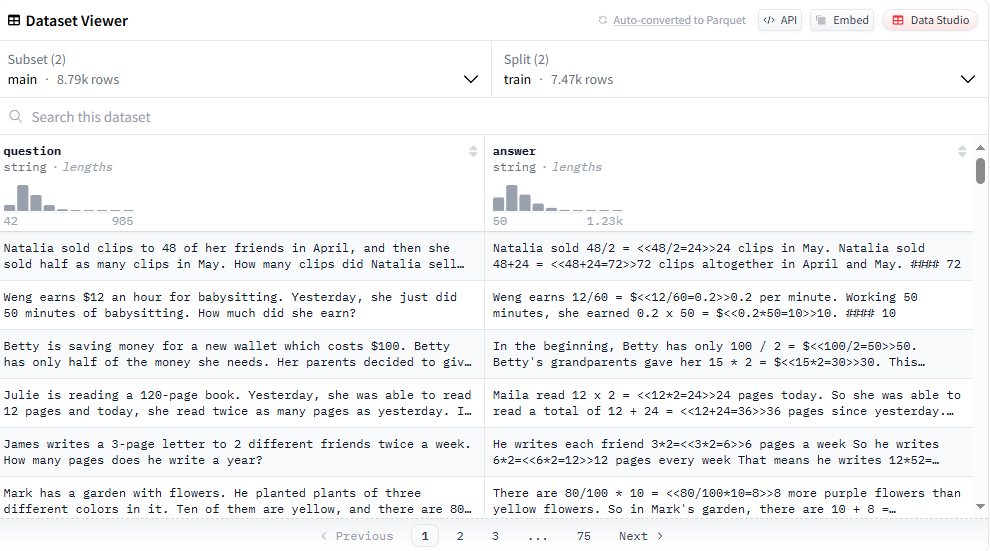
eval_dataset = load_dataset("openai/gsm8k", "main")["test"]
sample_df = eval_dataset.to_pandas()
display(sample_df)
我们需要对数据集进行一些处理,因为我们这里只需要模型的最终计算结果ground_truth和prompt:
def post_processing(example):
match = re.search(r"####\s*(-?\d+)", example["answer"])
example["ground_truth"] = match.group(1) if match else None
example["prompt"] = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": example["question"]}
]
return example
eval_dataset = eval_dataset.map(post_processing).remove_columns(["question", "answer"])

加载训练数据集时同样:
dataset = load_dataset("openai/gsm8k", "main")
train_dataset = dataset["train"]
# Apply to dataset
train_dataset = train_dataset.map(post_processing)
train_dataset = train_dataset.remove_columns(["question", "answer"])
if not USE_GPU:
train_dataset = train_dataset.select(range(10))
print(train_dataset[0])
加载模型和Tokenizer
与SFT与DPO相同的流程
model, tokenizer = load_model_and_tokenizer("./models/Qwen/Qwen2.5-0.5B-Instruct", USE_GPU)
依然是测试一下原始没有微调过的模型的效果:
# Store predictions and ground truths
all_preds = []
all_labels = []
for example in tqdm(eval_dataset):
input_prompt = example["prompt"]
ground_truth = example["ground_truth"]
# Run the model to generate an answer
with torch.no_grad():
response = generate_responses(model, tokenizer,
full_message = input_prompt)
all_preds.append([{"role": "assistant", "content": response}])
all_labels.append(ground_truth)
print(response)
print("Ground truth: ", ground_truth)
# 3. Evaluate using reward_func
rewards = reward_func(all_preds, all_labels)
# 4. Report accuracy
accuracy = sum(rewards) / len(rewards)
print(f"Evaluation Accuracy: {accuracy:.2%}")
这里我们测试不再是输出回应结果主观评判,而是依据与答案的匹配程度给出准确率,其中可能会有一些意外包括:
- 模型生成的回应由于token限制没有给出最终的计算结果就被截断
- 模型的回应中没有把最终计算结果放在我们规定的格式中,例如
\\boxed{} - 模型没有给出最终计算结果(例如使用小模型的时候模型无法生成准确回应)
配置GRPOConfig和GRPOTrainer
config = GRPOConfig(
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
num_generations=4, # Can set as high as 64 or 128
num_train_epochs=1,
learning_rate=5e-6,
logging_steps=2,
no_cuda= not USE_GPU # keeps the whole run on CPU, incl. MPS
)
grpo_trainer = GRPOTrainer(
model=model,
args=config,
reward_funcs=reward_func,
train_dataset=train_dataset
)
grpo_trainer.train()
测试训练完成后的模型
与测试原始模型一样的流程:
model = grpo_trainer.model
# Store predictions and ground truths
all_preds = []
all_labels = []
for example in tqdm(eval_dataset):
input_prompt = example["prompt"]
ground_truth = example["ground_truth"]
# Run the model to generate an answer
with torch.no_grad():
response = generate_responses(model, tokenizer,
full_message = input_prompt)
all_preds.append([{"role": "assistant", "content": response}])
all_labels.append(ground_truth)
print(response)
print("Ground truth: ", ground_truth)
# 3. Evaluate using reward_func
rewards = reward_func(all_preds, all_labels)
# 4. Report accuracy
accuracy = sum(rewards) / len(rewards)
print(f"Evaluation Accuracy: {accuracy:.2%}")
小结
实现流程上,与SFT和DPO没有太大的区别,总结为:
- 加载数据集
- 加载模型和分词器
- 将数据集处理为合适的形式
- 配置config和trainer并训练
- 测试微调后的模型结果
核心在于数据处理的方式不同:
- 在SFT中,我们想要让模型学会回答,因此我们准备的语料是QA(问题与回复)形式的,并且需要为Qwen提供ChatML格式的数据(即role,content格式,这个根据模型与分词器的要求各不相同
- 在DPO中,我们要让模型知道哪种回应更好,因此我们需要准备至少两个回应与对应的标签(positive/chosen or negative/rejected)
- 在OnlineRL中,我们需要为不同类型的奖励函数提供不同的处理,在这次的“可验证奖励”中,我们需要准备的数据形式是prompt,ground truth形式,在这项任务中,我们不需要模型的推理过程。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)